
生物医药领域专利申请决策模型构建方法研讨
2014-12-16 08:22葛云鹏李岚邹龙王斌王军文
生物技术世界 2014年7期
葛云鹏 李岚 邹龙 王斌 王军文
(湖南中医药大学 湖南长沙 410208)
《中华人民共和国专利法》第九条规定:两个以上的申请人分别就同样的发明创造申请专利的,专利权授予最先申请的人。它确立了我国专利授权中的“先申请原则”。
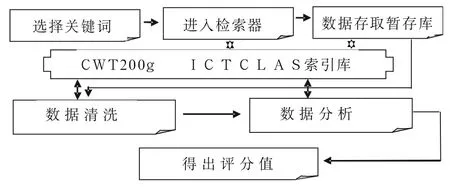
图1 专利申请授权可能性分析系统工作流程图
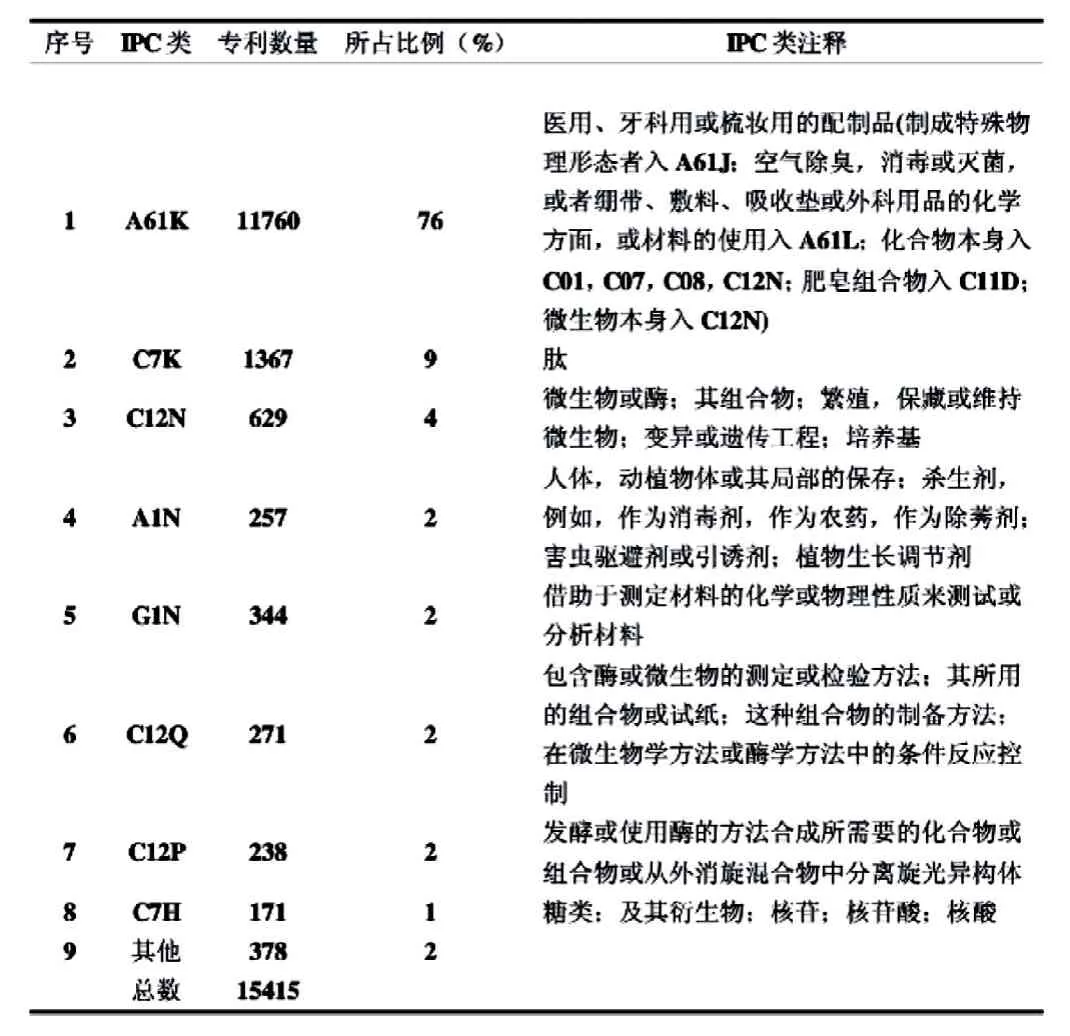
表1 ICP分类中生物医药领域专利分布情况
由于我国发明专利的审查必须经过实质审查,因此,相同或相似主题专利申请时,在后申请专利经常因为缺乏实质性要件而驳回,这是由于在后申请不具备专利三性之“新颖性”和“创造性”。由此可见,我国专利申请过程中,申请前检索工作非常重要,现今的专利申请前检索目标一般集中于国家知识产权局专利检索系统,中国知识产权出版社(CNIPR)中外数据库服务平台,和US,DE,EP,GB,JP,F R,WIPO等主要专利授权机构[1],以及中国知网(CNKI),百度或谷歌等网络搜索引擎。检索途径一般为专利发明人或申请人自行检索、发明人或申请人所在单位专利管理人员检索和专利代理机构检索三种,由于检索目标较广,专利和文献量巨大,普遍存在检索工作量大,人工处理数据工作繁重、检索成本高、费时耗力等问题,而且在信息检索过程中,检索人员往往习惯于从某一特定的概念入手,在检索专利信息时也不例外。由于专利文献中往往存在一些繁复晦涩、意义含混的专用术语或法律术语,其与一般科技文献中的通用技术用词不同,因此使用主题词进行检索时,由于主题词标引的不规范以及对主题词的不同理解,很可能造成漏检[2]。且由于缺乏明确的检索后各指标量化评价体系,检索者出具的报告个人主观性较强,普遍存在缺检漏检等现象,令申请者因授权可能性不确定,而无所适从等一系列问题。
本文旨在通过拟申报专利主题的关键词、ICP分类号等方式结合,从原始专利数据库提取专利数据,将提取出的专利数据进行清洗后,对入选专利文本化处理,进行格式化二次加工,用选定的数学统计模型对单篇专利主题、文摘、主权项分别评分,计算全部入选专利平均评分后,给予申请人或发明人明确的授权可能性评估结果。
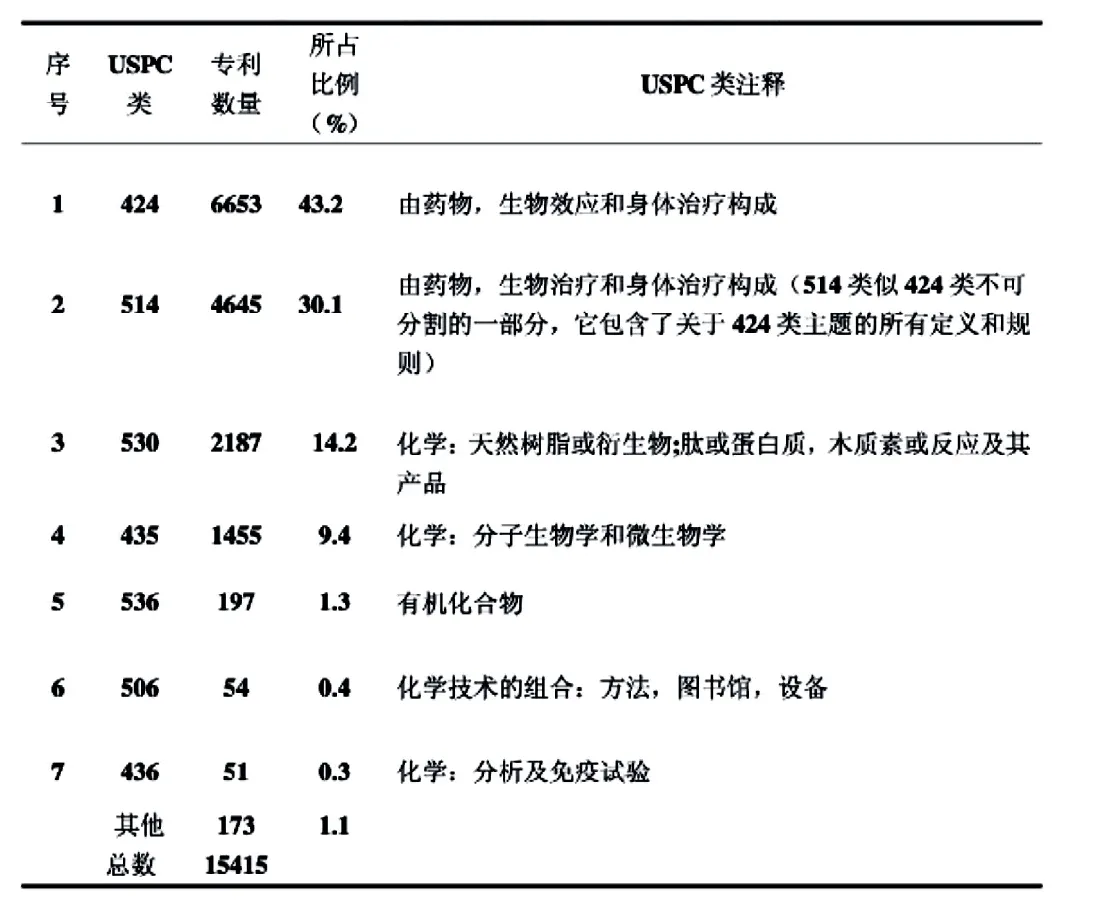
表2 USPC分类中生物医药领域专利分布情况
1 本模型基本工作流程
(图1)
2 本模型具体工作方法
(1)确定专利检索目标库。当今网络上免费专利数据库纷繁复杂,各具特色,本项目初步选定由中国知网开发并维护的中国专利数据库(知网版)和海外专利数据库(知网版)进行原始数据获取。该专利库原始数据来源为国家知识产权局知识产权出版社,中国专利库双周更新,海外库每月更新,相对更新频率较快,能准确反映拟申请主体国内外申请现状和趋势,而且检索结果创造性的融入该专利相关的文献、成果等信息等,数据来源于CNKI各大数据库,信息量大而全面,非常适合专利申请授权可能性评价。
(2)设计检索器。为解决专利文献书写中上下位词汇及常见俚语、术语混合等现象,本项目于检索入口构建基于北大天网推出的“中文Web测试集CWT200g”模块,设立关键词分散聚合标识索引库,解决检索用户选用关键词不能全面描述检索意图的问题,最大限度保障专利主体检索意图实现。
(3)设计检索数据暂存库。将检索器获得的原始专利数据按:名称、申请日、公开日、申请人、发明人、摘要、主权项、专利分类号、相关科技成果、相关中外标准、发明人发表文献、所涉核心技术研究动态12个字段分别存储,并于名称、专利分类号、相关科技成果、相关中外标准、发明人发表文献、所涉核心技术研究动态6个字段设置相应的CNKI数据读取URL链接关联字段。处理完成后对照检索器词汇数据库,集合中国科学院计算技术研究所的汉语词法分析系统ICTCLAS模块,对名称、摘要、主权项3个字段进行切词处理,去掉虚词、助词、停用词、标点后分别合并存贮。
(4)设计检索数据清洗模块。由于专利申请名称确定的重复性,模糊性及不确定性定因素,通常导致检索使用关键词的关联词、同义词、俗语、俚语、专业区别性词语所得出的检索结果存在很大程序的重复性和不相关性。如中医常用语中的“发热”,被检索器分类聚合关键词后,通常被分解为医药领域的“热证”“热症”“体温高”也可以分解为机械领域的“热阈高”“温度高”“热值高”等,所以检索结果既可以检索到医药领域中关于“发热退烧药”也可以检索到机械领域的“导电性发热材料”。这就是数据挖掘中“啤酒与尿布”的经典案例重现,为了解决关键词聚合产生的此类问题,结合本项目采用的中医药行业专利授权可能性预测,故本模块拟采用定向分析方法进行数据清洗,定量分析的数据清洗方式多具有明显的专题性,具体讲定向专利分析的专题可能是针对某一专业领域的宏观分析。[3]基于本理论,本模块设计采用国际专利分类表(IPC分类)对初检专利数据源进行专业领域分类,由于美国专利分类法采用ICP分类整理并不全面,所以附加美国专利分类法USPC辅助确定行业领域。如表1、表2可见ICP和USPC分类中生物医药领域专利分布情况。根据暂存库中专利分类号字段与表1、表2所列专利号进行对比,标记非对应字段的专利数据,并用检索器中文本词库对照,剔除即不在选定字段下,其名称、摘要、主权项不包含检索器中文本词库某一单一词汇的专利数据。
(5)设计分析模型。众所周知,我国专利法对发明实用新型专利的授权条件“新颖性”做了区别于“现有技术”的规定,而大多数国家的专利法则是通过区别“现有技术”界定“新颖性”的概念。所以本分析模型的设计目标就是:通过对经过清洗的专利文本化数据进行分析,从中抽取与本专利相关的“现有技术”,采用Meta分析常用的RCT分布评分法,进行专利文献评分,Meta分析是对具有相同研究目的的多个独立研究结果进行系统的、定量的统计学综合分析与综合评价的一种研究方法[4-6]。
具体评分标准共有2种评分方式,分别为关键词与干扰词对照比较评分法和文本相似度计算评分法,本文详细介绍文本相似度计算评分法。目前,文本相似度检测算法常用的方法有agglomerative算法[7]、增量聚类算法[8]、增量K-means算法[9]、基于主题模型算法[10]等。相似度计算的方法常采用余弦夹角、 雅各比公式、OKA_PI公式、Clarity、Tanimoto、Hellin ger公式等[11-12]。随着自然语言处理技术的发展,基于语义相似度的相似度模型也开始流行。这些相似度计算方法各有利弊。通过初步的对比分析,结合专利文献严谨、细致、格式化强的特点,项目组拟采用基于知网HowNet常识知识库的文本相似度分析系统,其基本理念是,一段文字中,概念是由若干义原按照一定知识表述形式描述的。义原是用于描述一个概念的最小意义单位,不可再分,是知网层次结构上的一个节点。知网系统一共采用了1500基本义原,这些义原相互组合来表示成千上万的词语。
3 具体实施方式如下
(1)调用拟申请专利文献的标题、摘要、主权项,采用数据清洗器进行切词处理;
(2)切词后,调用检索器中文本数据库进行词意特征扩展,扩展特征的权重与原特征的权重相同。
(3)依次读取清洗后专利暂存库中专利文献向量,采用以下公式计算文本相似度:

其中:|posi∩posj|表示拟申报专利i文本和对比专利j公共特征数量,|posiUposj|表示拟申报专利i文本的不同特征数量。借鉴信息融合中的顺序加权思想,语义相似度的定义如下:
设拟申报专利i文本含有m个关键词,对应的权重为vi1,vi2…,则Posi~[wordi1/vi1,wordi2/vi2,…,wordim/vim]设拟对比专利j文本含有n个关键词,对应的权重为vj1,vj2…,则Posj~[wordj1/vj1,wordj2/vj2,…,wordjn/vjn]
则设拟申报专利i文本与拟对比专利j文本的语义相似度归一化表示如下:
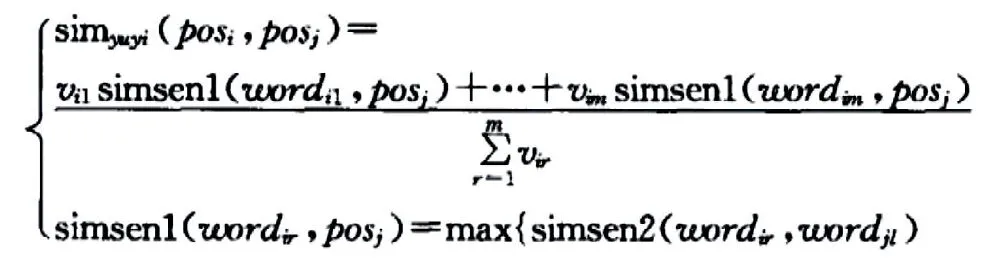
(由于对称性,不妨假设m≥n,反之亦然):
式中,l=1,2,…,n;r=1,2,…,m;simsen2(wordi,wordj)表示词i和词j的相似度;simsenl(wordi,posj)表示词i和拟对比专利j文本的相似度。
4 结语
模型设计过程中发现,评分方式的实现直观而精准,能直接反应新颖性中创新点所在,但计算方式较为粗放,对于专业性质较强,精细度要求较高的专利文献分析对比实践中略有偏差,模型通过中国知网国内外专利数据库进行检索评分,对照国家知识产权局专利法律状态数据库进行对比,得出算法精准度为70%,具体数据获得过程暂不能公布,进行初步预估后,能基本得出“授权可能性大、较大、一般、不建议申报”5级评分结论指标,通过指标评定,对专利申请可能性进行客观指标评分,可以解决检索报告个人主观性较强,缺检漏检等现象得发生。
[1]高立华.汤森路透Aureka的智能检索分析.科技情报开发与经济[J],2012(16):107-108.
[2]马磊等.IPC分类法在科技查新工作中的应用.图书馆学刊[J],2012(3):32-33.
[3]王永红.定量分析的样本选取与数据清洗.情报理论与实践[J],2007(13):93-97.
[4]李良寿.临床医学研究原理与方法.西安:陕西科学技术出版社[M],2000(13):57-72.
[5]徐勇勇.Meta分析:一类综合研究信息的统计方法.上海预防医学[J]1993(5):102-111.
[6]徐勇勇.Meta分析常见资料类型及统计分析方法.中华预防医学杂志[J],1994(28):33-37.
[7]张晓艳等.话题检测与追踪技术研究.计算机研究与探索[J]2009(4):347—357.
[8]席耀一等.基于语义相似度的论坛话题追踪方法.计算机应用[J].2011(31):93—96.
[9]徐建民等.基于查询术语同义词的扩展信念网络检索模型.计算机工程[J],2007(10):28—30.
[10]孙胜平.中文微博客热点话题检测与追踪技术研究.北京:北京交通大学,2011.
[11]刘群等.基于《知网》的词汇语义相似度计算[c]第三届汉语词汇语义学研讨会.台北:2002:59—76.
[12]RangrejA,eta1.Mparative Study of Clustering Techniques for Short Text Documents EC ] WWW2011.Hyderabad,India,2011.
猜你喜欢
水运工程(2022年7期)2022-07-29
农药科学与管理(2019年9期)2019-11-23
传感器世界(2019年4期)2019-06-26
河南科技(2016年8期)2016-09-03
发明与创新(2016年5期)2016-08-21
河南科技(2016年6期)2016-08-13
专利代理(2016年1期)2016-05-17
质量与标准化(2010年5期)2010-05-03
质量与标准化(2010年3期)2010-05-03
轴承(2010年2期)2010-04-04
