
基于多特征的视频中单人行为识别
2015-01-04 08:51胡兴旺祁云嵩袁玉龙
电子设计工程 2015年12期
胡兴旺,祁云嵩,袁玉龙
(江苏科技大学 计算机科学与工程学院 江苏 镇江 212003)
人体行为识别技术主要包括人体目标识别、人体跟踪与行为识别三个方面。其中,行为识别是基于前两者的更高级别的计算机视觉部分。研究出一种健壮的行为识别算法具有重要的理论意义与广泛的应用前景,其中包括智能视频监控、视频检索、人机交互等领域,因此行为识别领域受到广泛学者的关注[1-3]。而研究的难点主要体现在运动背景复杂、行为多变、数据量大、实时性要求高等方面。行为识别流程包括了人体的检测与跟踪、特征提取和行为识别三个重要环节。本文通过提取属性,得到动作单元,用这些动作单元的序列组成动作。本文仅仅找了一个方法在一个视频集上将这些动作区分开了,并没有到动作理解的层次。同时很难运用到现实中的异常行为检测方面。
1 前景提取
1.1 相邻帧差法
该方法是从第二帧开始,将当前帧减去前一帧得到前景(如图1)。由于帧差法是相邻两帧想减,易产生空穴。并且当前景静止的时候,很容易导致前景消失[4]。
1.2 混合高斯模型
背景建模过程如下:
1)高斯分布模型匹配
2)高斯分布模型的更新
在处理前L个样本的时候,使用以下的更新方程:

当达到L个样本的时候使用以下的更新方程:
如果 ωk是第一个满足的高斯分布,p^(ωk|Xt+1)=1,否则p^(ωk|Xt+1)=0。
3)生成背景模型
重新对混合高斯分布按优先级ρi,t由大到小排列,取前B个高斯分布联机的生成背景:

4)阴影去除
1.3 平均背景法提取前景(AVG)
前景提取[5-6]:
1)将前景图像减去背景图像。
如果亮度或色度分别大于一定的阈值则认为他们属于前景部分否则为阴影部分。
3)在将之前的HSV空间的图像转到RGB空间diffRGB

图1 视频前景提取对比图Fig.1 Video prospects extract comparison chart
2 前景处理
为了得到较好的连通的前景又不引入过多的噪声,将FD、MOG、AVG三者得到的前景做相应的处理后相加,然后再进行滤波、去噪等一系列的操作。将过小的以及过大的连通区域去除,并将连通区域过多的帧去除。为了得到整个人体的属性,需要将人进入视频以及离开视频时导致不完整人体的视频帧去掉。对处理过后的视频将前面以及后面空的视频帧去除。
3 属性提取
在处理后的视频上提取时空属性、姿势属性等十个属性。提取的属性以及属性的组合有:1)pos(位置分布)2)size(大小分布)3)maindir(由边缘方向直方图得到的主方向)4)maindirSD (主方向的标准差)5)speed(速度)6) 速度方差(speedSD)7)hchange(高度变化)8)hchangeSD(高度变化标准差)9)wchange(宽度变化)10)wchangeSD(宽度变化标准差)
视频采样集合 VSample={f1,f2,…,fT},第 t个视频采样帧ft中的连通域集合为CASet(t)={ca(t)1,ca(t)2,…,ca(t)nt}
1)pos属性的提取
pos属性的求取如下:①初始化pos矩阵,pos=[0]height*width.
②对于新的视频采样帧,计算其质心 CEN(CASet(t))=[y(t)c,y(t)c],并更新pos矩阵。
2)size属性的提取
对于新的采样视频计算其前景大小BOX(CASet(t))=[x1(t)b,y1(t)b,x2(t)b,y2(t)b],并更新size矩阵。
3)maindir属性的提取
每一个视频采样帧的maindir属性是该视频中的前景轮廓的边缘方向的加权和。视频采样集的maindir属性该集合中所有视频帧的maindir的平均值。
4)maindirSD属性的提取 maindirSD 取 maindir(fi)的标准差
5)speed 属性的提取
设t时刻视频采样帧的质心为CEN(CASet(t))=[x(t)c,y(t)c],t-1时刻的质心为CEN(CASet(t-1))=[x(t-1)c,y(t-1)c],则视频采样集的speed属性是相邻两个视频采样帧之间质心速度的平均值。
6)speedSD 属性的提取 speedSD 取 speed( ftft-1)的标准差
7)hchange属性的提取
设t时刻的包围盒为BOX(CASet(t))=[x1(t)b,y1(t)b,x2(t)b,y2(t)b],t-1时刻的包围盒为BOX(CASet(t-1)=[x1(t-1)b,y1(t-1)b,x2(t-1)b,y2(t-1)b]),则视频采样集的hchange属性是相邻两个视频采样帧中前景包围盒高度差的平均值。
8)hchangeSD 属性的提取 hchangeSD 取 hchange( ftft-1)的标准差
9)wchange属性的提取
10)wchangeSD 属性的提 wchangeSD 取 wchange( ftft-1)的标准差
经过以上10种属性的提取,可以将每一个视频表征为一个属性向量 F=[pos,size,md,mdSD,s,sSD,hc,hcSD,wc,wcSD]
4 分 类
将视频集分为两部分,一部分用于训练,一部分用于测试。第i类的特征平均值表示如下:
根据十种属性定义一下13种距离。
测试集中的第j个视频到第i类的pos距离:
测试集中的第j个视频到第i类的size距离为:

测试集中的第j个视频到第i类的dir距离为:
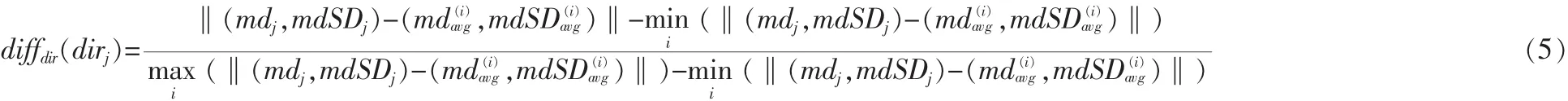
测试集中的第j个视频到第i类的maindir距离为:
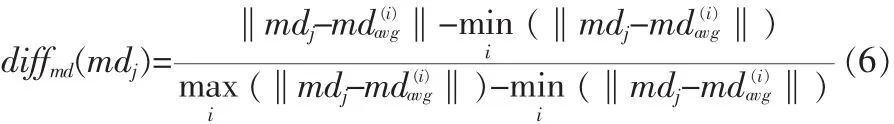
测试集中的第j个视频到第i类的maindirSD距离为:

测试集中的第j个视频到第i类的speed距离为:
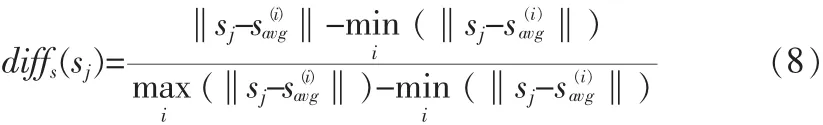
测试集中的第j个视频到第i类的speedSD距离为:

测试集中的第j个视频到第i类的sizechange距离如式(10):
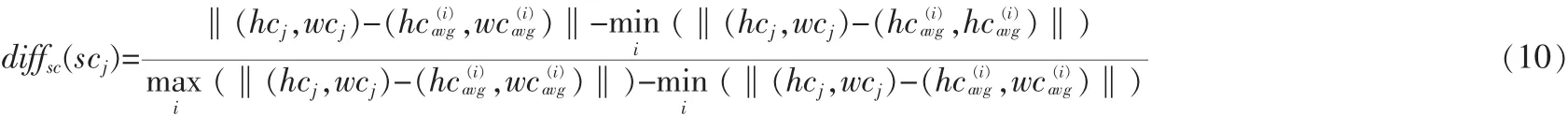
测试集中的第j个视频到第i类的sizechangeSD距离如 式(11):
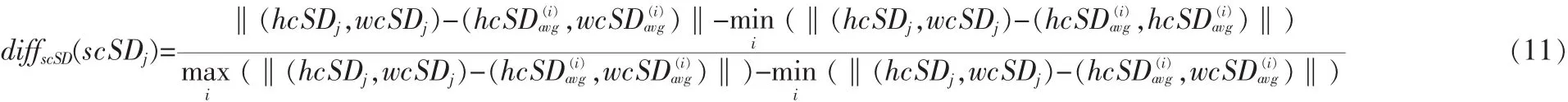
测试集中的第j个视频到第i类的hchange距离为:

测试集中的第j个视频到第i类的hchangeSD距离为:
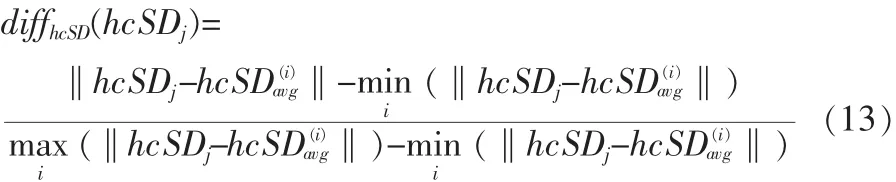
测试集中的第j个视频到第i类的wchange距离为:
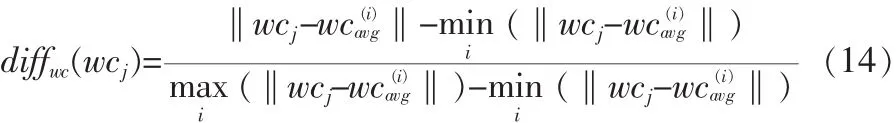
测试集中的第j个视频到第i类的wchangeSD距离为:

分类算法定义如下:
1)单独对各个距离采用最近邻方法进行分类。然后选出识别率大于0.4的距离,并记下它们的识别率。以这些距离的识别率为权重的加权和为分类的距离
2)对测试集中的任意一个视频,计算他们的距离。从这些距离中选出最小的一个,并把该视频分为与之为最小距离的那一类的同类。
5 实 验
在CASIA行为分析数据库上进行了实验。CASIA行为分析 数 据 库 定 义 了 bend、car、crouch、faint、jump、run、walk、wonder8种行为。由于CASIA行为分析数据库中的类别为car的行为样本数太少不具有统计特征,故将其去除。
各个属性在CASIA行为分析数据库上的识别率如下图所示。
如图 2和图3其中识别率大于 0.4的距离有 duffpos、difsize、diffdir、diffs, 他 们 的 识 别 率 分 别 为 49.62% 、63.27% 、45.19%、51.92%。
以此为分类距离的十次分类结果如表1所示。
十次分类的混淆矩阵为:

图2 各距离识别率Fig.2 Each distance recognition rate

图3 加权距离的识别率Fig.3 Recognition rate weighted distance

表1 分类结果Tab.1 Results of Classification
如图 4 所示由于 run、jump、walk 在属性 pos、size、speed、dir上的值相差不大,再加上前景提取的噪声,他们的识别率并不是很高。
6 结 论
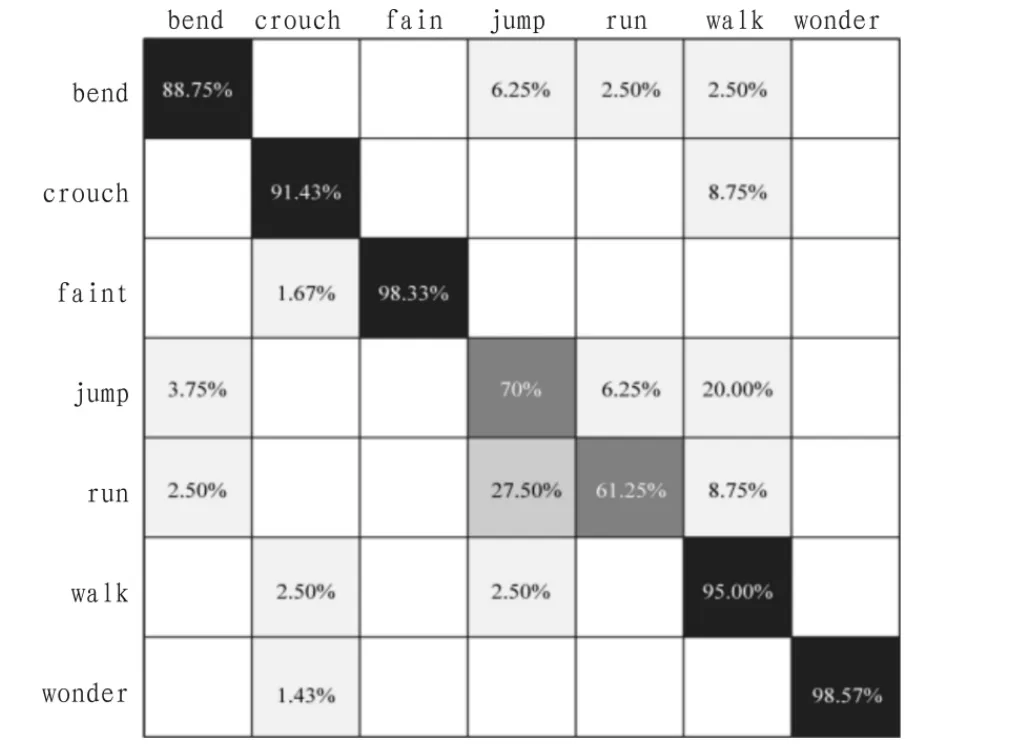
图4 实验结果Fig.4 Result of the experiment
本文本论文围绕智能视频监控相关的关键技术展开研究,研究内容涉及运动目标的检测、人体运动特征的描述和识别方法等。具有一定的理论研究价值和现实的应用意义。通过在视频的基础上提出位置分布图、大小分布图等一系列的属性将单人的行为进行分类。并取得了不错的分类结果。
[1]杜友田,陈峰.基于视觉的人的运动识别综述[J].电子学报,2007,35(1):84-90.DU You-tian,CHEN Feng.Summary of visual recognition based on the movement of people[J].Journal of Electronic,2007,35(1):84-90.
[2]Ronald Poppe.A survey on vision-based human action recognition Image and Vision Computing [J]Computer Engineering and Design,2010,28(6):976-990.
[3]Aggarwal J K,Cai Q.Human motion analysis:A review Computer Vision and Image Understanding[J].Electronic Measurement Technology,1999,73(3):428-440.
[4]Jolly M P D,Lakshmanan S,Jain A K.Vehicle segmentation and classification using deformable templates[J].IEEE Trans.on PAMI,1996,18(3):293-308.
[5]Yilmaz A,Li X,Shah M.Contour-based object tracking with occlusion handling in video acquired using mobile cameras[J].IEEE Trans.on PAMI,2004,26(11):1531-1536.
[6]Marc Niethammer,Allen Tannenbaum,Sigurd Angenent.Dynamic active contours for visual tracking[J].IEEE Trans.on Automatic Control,2006,51(4):562-579.
猜你喜欢
数字通信世界(2021年3期)2021-04-09
湖北理工学院学报(2020年4期)2020-08-22
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
计算机应用与软件(2017年4期)2017-04-24
中国交通信息化(2016年2期)2016-06-06
赤峰学院学报·自然科学版(2015年15期)2015-03-21
医学理论与实践(2014年23期)2014-03-06
医学理论与实践(2012年4期)2012-12-09
