
基于非限制MIDAS模型的GDP增长研究
2015-01-22 10:34柏久麟
产业与科技论坛 2015年7期
□柏久麟
宏观经济中有许多能反映当前宏观经济状态和未来宏观经济走势的经济数据,如季度GDP数据、月度CPI和PPI数据等。这些数据受到经济个体、企业、组织和国家,国际社会的广泛关注,人们使用不同的数据处理方法和构建各种模型从这些纷繁复杂的数据中提取信息,以便能够得出当期宏观经济的准确预报和未来一段时间内宏观经济走势的精确预测。然而,在构建宏观经济模型时却由于种种原因经常出现数据抽样的频率高低有别的问题,而大多数宏观经济模型都要求模型等式两边的数据频率是一致的,因此要想利用传统宏观经济模型去估计、预报和预测宏观经济的话就必须对混频数据进行处理。
最初,国内外对于混合频率数据的处理方法是将高频数据处理为低频数据(Silvestrini和Veredas,2008),而其他的则是采用插值法将低频数据处理为高频数据(Chow和Lin,1971、1976;赵进文和薛艳,2009)。但是这两种处理方法有着显而易见的缺陷,将高频数据处理为低频数据处理过程中忽视了高频数据中部分样本信息,抹杀了高频数据的波动,在一定程度上人为地减少了样本信息,但是由于该方法使用上较为简单,所以在实际应用中这种方法较为流行;而插值法在应用上相对较少,但对该方法的研究却相当多。虽然插值法能获得高频数据,但是这种高频数据存在着明显的人造数据的嫌疑,其结果的真实性往往值得怀疑,这也是该方法在实际应用中使用较少的重要原因。
混频数据模型的理论优势在于不对混频数据做任何处理,而是利用原始数据的信息构建数据模型。当前处理混频数据的模型主要有以下两种:混合频率数据抽样(MIDAS,MIxedDAta Sampling)模型和混合频率向量自回归(MFVAR)模型。MIDAS模型是Ghysels等人(Ghysels,Santa-Clara和Valkanov,2004)在分布滞后模型的基础上提出来的混合频率数据抽样。Clements、Galv~ao(2005)开始将MIDAS模型应用于宏观经济领域的理论研究,Marcellino、Schumacher(2007)将因子模型引入到MIDAS模型,模型的预测结果显示MIDAS模型在短期预测中表现较为优秀,且非限制的U-MIDAS模型在很多实际预测中具有最佳的预测效果。
一、MIDAS回归模型以及U-MIDAS回归模型
(一)MIDAS模型。单变量的MIDAS模型是由Ghysel(2004)等基于分布滞后模型提出的,此模型最初提出时,运用了一个参数化的权重多项式,直接利用高频数据与低频数据构建模型,此模型的估计方法一般为非线性的最小二乘法进行估计。
单变量MIDAS回归模型如下:
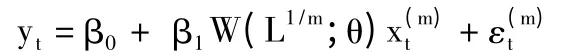
其中,yt是低频因变量变量是高频自变量。m代表高频数据和低频数据之间的倍率。如果yt是季度数据是月度数据,那么m=3。W(L1/m;θ)为滞后权重多项式,相应表达式如下为高频滞后算子,我们有。其中,K为滞后权重多项式的阶数。
当K=3时,MIDAS模型可以携程如下形式
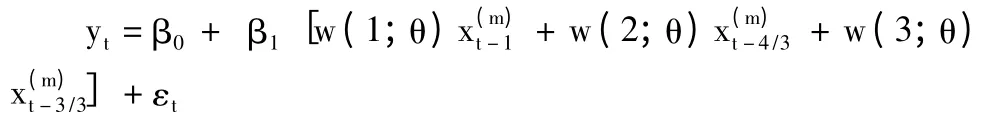
一般来说MIDAS模型最为常用的滞后权重多项式为指数Almon滞后多项式。基由次权重多项式可以构建出多种不同的权重多项式。一般来说,宏观经济学中常用两参数的Almon指数多项式,并且限定θ1≤300,θ2<0的条件。如此,即可得到满足一般宏观经济预测所需要的权重形式。(Clements,2008)
(二)U-MIDAS模型。在一般情况下,我们可以看到,MIDAS模型在估计之前都要对滞后权重多项式进行限定。是在某些情况下,我们会发现,对于事前假定滞后权重多项式的设定常常是不客观的。基于这种情况,Foroni,Marcellino,and Schumacher(2011)对原始的MIDAS模型进行改进。取消了模型中的滞后权重多项式的限定。这样的模型被称为非限定的MIDAS模型,即U-MIDAS模型。
一般来说,U-MIDAS模型的具体形式如下:
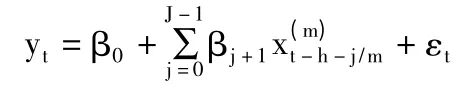
其中J为回归模型中解释变量的滞后阶数。模型中的其余的参数均与一般的MIDAS模型一致。
二、实证分析
本文将采用2000年1季度至2013年4季度的GDP同比增长率yt,月度固定次产投资的同比增长率,月度社会消费品零售总额同比增长率,以及月度出口总额的同比增长率分别构建MIDAS模型以及非限制性MIDAS模型。
对于模型的检验主要有两个方面,第一是模型在样本内的拟合精度,通常的衡量标准为拟合优度。第二是模型在样本外的预测精度,通常衡量的方法是建立损失函数。在预测模型时,建立不同的损失函数就会衍生出不同的预测结果。本文将用比较常见的误差均方根(RMSE)来评价模型的预测精度。本文的模型预测与检验均采用matlab进行编程。
我们用以上GDP,月度固定次产投资,月度社会消费品零售总额,月度社会消费品零售总额分别采用MIDAS模型与U-MIDAS模型进行模拟。对于我国的国情来讲,通常来说,一个完整的经济周期为12个月。这里我们可以先行假设模型的滞后权重为12。在模拟MIDAS模型时,我们所采用的滞后权重多项式为最常用的Almon滞后多项式。
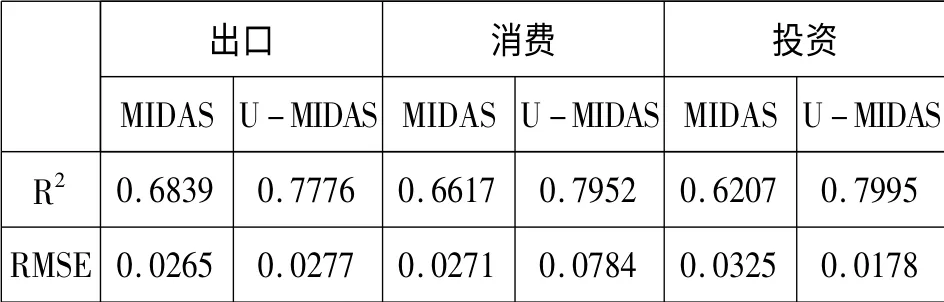
表1 MIDAS模型与U-MIDAS模型估计结果
由表1我们可以看出,在拟合优度方面,U-MIDAS模型全面优于一般的MIDAS模型。这里可以看出,由于去掉了滞后权重多项式的限制,使得非限制性的MIDAS模型具有了更高的灵活性,使得拟合精度大大提高。
另一方面,在预测精度上面,出口与消费部分U-MIDAS模型则预测效果不佳。调整了相关的滞后权重后我们得到了出口与消费的误差均方根表。
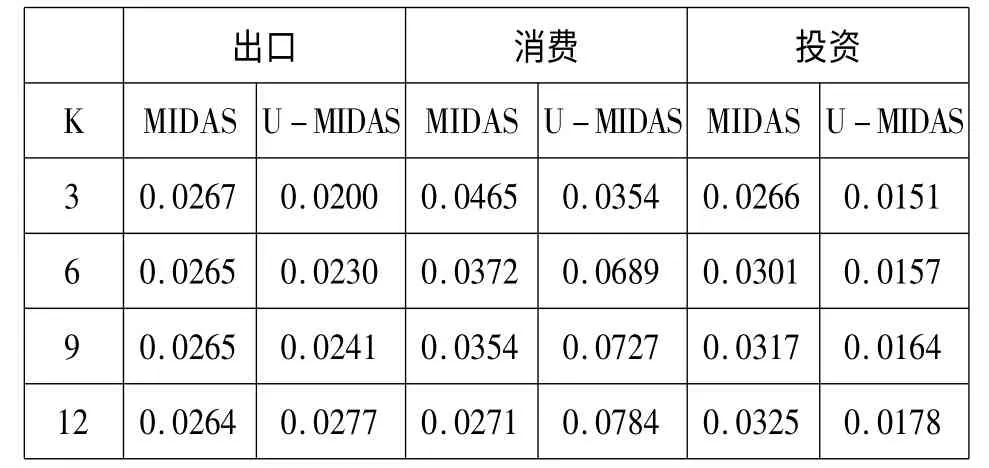
表2 不同滞后阶数下三个因子的RMSE变化
三、模型预测结果与评价
经过上面的拟合结果分析可以得到如下三点结论:第一,由于U-MIDAS模型取消了滞后权重多项式限定时的模型的灵活度大大提升,这使得模型的拟合精度相对于一般MIDAS模型具有明显优势。第二,U-MIDAS模型由于取消了滞后权重多项式的限定,随着滞后阶数的增加——这直接导致模型需要估计的参数大量增加——模型的稳定性迅速下降。这是在使用U-MIDAS模型进行预测时值得注意的问题。第三,就我们研究的这个问题看来。消费,出口,投资对于GDP有着不同的影响力,我们可以看到,中国GDP的波动与出口的波动最为相关。这也是中国作为一个出口为主的国家的基本国情决定的。
[1]Andreou,E.,Ghysels E.,and A.Kourtellos,2010,Regression models with mixed sampling frequencies[J].Journal of Econometrics,doi:10.1016/j.jeconom,2010,1:4
[2]Clements,M.P.,and A.B.Galvo,2005,Macroeconomic forecasting with mixed-frequency data:Forecasting US output growth administration,Warwick working paper
[3]Ghysels,E.,A.Sinko,and R.Valkanov.MIDAS regressions:Further results and new directions[J].Econometric Reviews,2007,26(1):53~90
[4]Ghysels,E.,Santa-Clara,P.and R.Valkanov.The MIDAS touch:Mixed data sampling regressions[J].mimeo,Chapel Hill,N.C,2004
[5]Marcellino,M.,andC.Schumacher,Factor nowcasting of German GDP with ragged-edge data.A model comparison using MIDAS projections,Bundesbank Discussion Paper,2004,1(34)
[6]VladimirKuzin,MassimilianoMarcellino,Christian Schumacher.MIDAS versus mixed-frequency VAR:nowcasting GDP in the euro area[J].International Journal of Forecasting,2011,2(27):529~542
[7]刘汉.中国宏观经济混频数据模型的应用与研究[D].吉林大学,2013
[8]陈浩东.基于混频数据模型对通货膨胀与经济增长影响的实证研究[D].吉林大学,2012
[9]刘金全,刘汉,印重.中国宏观经济混频数据模型应用[J].经济科学,2010
[10]耿鹏,齐红倩.我国季度GDP实时数据预测与评价[J].统计研究,2012
[11]赵进文,薛艳.我国分季度GDP估算方法的研究[J].统计研究,2009
[12]龚玉婷,陈强,郑旭.基于混频模型的CPI短期预测研究[J].统计研究,2014
猜你喜欢
英语文摘(2022年3期)2022-04-19
中国外汇(2019年12期)2019-10-10
中国外汇(2019年23期)2019-05-25
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
管理现代化(2016年3期)2016-02-06
学习月刊(2015年15期)2015-07-09
中国记者(2015年8期)2015-05-09
中国记者(2014年4期)2014-05-14
中国记者(2014年9期)2014-03-01
中国记者(2014年6期)2014-03-01
