
基于支持向量机的炒作微博识别方法
2015-02-20 08:15董雨辰罗军勇
计算机工程 2015年3期
董雨辰,刘 琰,罗军勇,张 进
(数学工程与先进计算国家重点实验室,郑州450001)
基于支持向量机的炒作微博识别方法
董雨辰,刘 琰,罗军勇,张 进
(数学工程与先进计算国家重点实验室,郑州450001)
微博是舆论传播的中心和渠道,同时参与舆论的形成、发展与引导过程,其自媒体发布、意见领袖参与等因素在一定程度上造成了微博谣言、虚假炒作、社会动员等现象。针对炒作微博的传播特点,分析其群体的隐蔽策划现象,挖掘出普通微博和炒作微博在传播网络结构、转发增量统计等方面的差异。通过社交网站的应用程序接口对目标微博的所有评论、转发和点赞用户进行信息获取,构建该微博的传播网络,利用社团模块度、平均最短路径和网络直径这3个属性度量该网络的紧密程度,基于支持向量机对所抽取的微博进行分类,进而识别出炒作微博。实验结果表明,该方法对微博传播用户的属性信息依赖小以及传播网络结构特征敏感,并且具有较高的炒作微博识别准确率。
社交网络;炒作群体;炒作微博;社团模块度;网络直径;平均最短路径;支持向量机
1 概述
随着移动终端的大规模普及,微博、Twitter、Facebook等社交网站迅速地融入到人们的日常生活中。微博传播是一把双刃剑,一方面,为突发事件中的信息公开提供了一个快速响应平台,在一定程度上弥补了传统媒体和其他网络的不足。另一方面,由于微博新闻的发布真实性无法得到保证,可能会被利用成为谣言传播的载体和不满情绪的导火索,甚至给国家和社会稳定造成严重的后果。显示社交网络能量的一个标志性事件是2008年奥巴马的公关团队娴熟地运用Facebook,Twitter,YouTube和Flickr等平台,为奥巴马的成功竞选起到关键作用,在此之后的2010年“茉莉花事件”、2011年的伦敦
骚乱以及2011年和2013年埃及的2次政变等事件,都能看到社交网站在背后推波助澜的痕迹。研究发现,热门微博传播中人为操纵的虚假信息转发量极大,1%的垃圾消息发送者创造了49%的转发量[1]。出现在互联网上的“网络水军”、“网络推手”等利用社会媒体散布谣言和虚假信息,开展不正当商业竞争,买卖粉丝,操控网络舆论,这些网络公关行为,严重干扰了正常网络舆论秩序[2]。
社交网站上的热门微博按转发、评论、点赞数量以及在一定时间内被转发和评论的频率等一系列参数综合计算排出。这样就使得一些个体或商家甚至不法分子为了达到某种宣传作用,不惜借助微博营销公司,雇佣草根大号、名人微博,乃至于雇佣控制大量僵尸粉丝的黑客对自身的博文进行广泛传播,在短时间内造成热门微博的假象,以此挤进社交网站的热门微博榜单,然后信息就像被吹开的蒲公英,向不同方向进行扩散,属于典型的蒲公英式传播模型,也称之为裂变式传播或爆炸式传播。简单来说,蒲公英效应就是以一个动作为出发点,最终达到多重效果。事实上,在微博营销中存在大量蒲公英效应。
本文对炒作微博的转发、评论行为进行有效预测和识别,并挖掘出起到重要传播作用的关键节点,提出基于支持向量机(Support Vector Machine, SVM)的炒作微博识别方法。在微博传播网络中使用模块度峰值、平均最短路径和网络直径作为传播网络结构度量的主要参数,基于SVM综合多种参数进行分析,进而识别炒作微博。
2 相关工作
随着Web2.0的发展,社交类网站的影响能力和辐射人群日益壮大,消息的真伪以及是否存在人为的操控言论的走向,逐渐成为网络舆情研究的新热点。文献[3]运用基于关键词的信息监视器,收集数据自动评估信息的新闻价值的方法,对Twitter的信息可信度进行评估。文献[4]提出基于事件图表优化的可信度分析方法。文献[5]提出社会性网络信息传播模式下的网络议题升级模型,从受众升级、媒体升级、舆情升级3个方面剖析议题的发展趋势。在传播时间上,文献[6]将网络媒体按信息来源进行区分,发现网络论坛信息传播随时间变化的相似性与论坛作者在发表量上的不平等特征。一些学者利用传染病传播模型对舆情传播进行研究。文献[7]把传染病模型应用在媒体环境下,利用免疫的舆情传播模型对信息的传播进行控制。网络结构对社会网络信息的传播有很大影响,利用复杂网络方法对网络传播动力机制进行分析开辟了舆情信息传播的新领域。文献[8]通过研究发现规则网络比小世界网络中信息传播的范围更大,速度也更快。文献[9]认为网络信息传播不仅依赖于小世界网络中的最短路径,还与网络行为的多次社会性强化有关。意见领袖在信息传播中充当了重要的角色,影响力和感召力大的名人,可以影响人们的购买行为和政治观点。文献[10-11]使用粉丝数量和微博转发数量对用户影响力进行衡量,结果表明粉丝数量多的用户微博不一定会得到很多的转发或者评论。文献[12]借鉴PageRank算法的思想,设计了TwitterRank算法来衡量一个用户在某一主题内的影响力,主要思想是给定一个主题,用户的影响力定义为他的所有粉丝的影响力之和。
上述学者对于微博的可信度和用户的影响力的研究,基本上解决了有关键用户且由其引起的信息传播的微博舆情分析。实际上网络炒作中还有一种情况是其传播的主体为数量庞大的水军;这些水军由网络公关公司雇佣的大批社会闲散人员组成,并由公关公司挑选出来的组长负责管理,统一行动[13]。有的组长是网络红人或微博草根大号,炒作的行为是有组织、有计划、有目的的群体策划。本文将针对此类炒作微博,在真实的社交网络环境中,分析其传播模式,研究其特殊的成员组成结构,梳理出其炒作目标,寻找出其隐含的炒作痕迹。然后运用社团模块度、平均最短路径、网络直径和基于支持向量机挖掘炒作团体的潜在属性,识别出炒作微博。
3 炒作微博及传播节点分析
3.1 炒作微博的群体策划现象
炒作社团组成结构紧密且封闭,从炒作微博单位时间内的转发量(某化妆品炒作广告转发量见图1)上看也异于热门微博的单位时间内的转发量(2013年4月20日四川雅安地震一条微博转发量见图2)。可以看出,一条热门微博的产生到其传播量的爆发经历了一定的潜伏期,并逐渐成指数型增长,在增长到一定数量级后,呈现平衡状态,随着时间的增加,逐步衰减消亡。
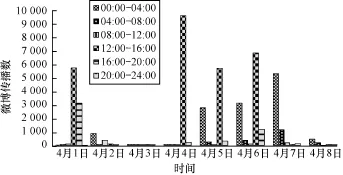
图1 某炒作微博单位时间内的转发量
炒作微博单位时间内的转发量生成图并没有出现潜伏期和成长期,而是直接在经过几个数据量低的时间片后,传播量飙升到爆发状态,紧接着便迅速衰落至初始状态,在随后的时间片内呈现出极低的传播量,直至死亡,或者再出现几次这种规律性的爆发,这是由于博主在付费给水军客服后,水军客服安排炒作团体为指定的微博进行转发和评论;然后博主对效果进行评估,选择是否继续雇佣水军为其博文进行后续炒作,所以炒作微博的转发图会呈现出特殊的传播走势。
图3(a)展示了一个典型蒲公英式的热门微博传播图,体现出核爆式一二三级冲击波和大小V(指在微博上十分活跃、又有着大群粉丝的公众人物。通常把粉丝在5×105以上的称为网络大V)转发的典型传播方式。图3(b)是一条典型的炒作微博信息传播,其传播过程中充斥着大量的炒作团体,少有离散节点的信息传播,主要是依附于大V下的粉丝在扩撒信息。

图3 典型热门微博和炒作微博的信息传播结构
3.2 微博传播网络
与人人网、QQ好友等传统的社交网络不同,微博的用户与用户之间以一种“弱关系”的形式存在的,用户关注某人成为其粉丝也只需要单方面的认可,人与人之间并不存在太多的感情联系[14]。图4(a)是从人人网中提取的一个基于强关系的社交网络结构,网络中的节点呈现出同构的特性。图4(b)为新浪微博的一个弱关系社交网络结构,其中,黑点是用户节点;白点是粉丝节点;实线为关注关系;虚线是信息的传播关系。正是这种微博用户彼此间“弱关系”的存在,促使信息不断地向外扩散,以及不同影响力的节点对信息传播的强弱起到了关键性作用,组成了微博特殊的传播方式。由于微博用户的社会地位与公众认知度的不同,使得其在信息传播的影响力度方面也有天壤之别。因此,若能找出个人或者团体在微博信息传播中的影响范围或者说在微博传播节点存在社团(群体策划行为)的可能性,是预防与识别网络恶意炒作、煽动的关键[15]。
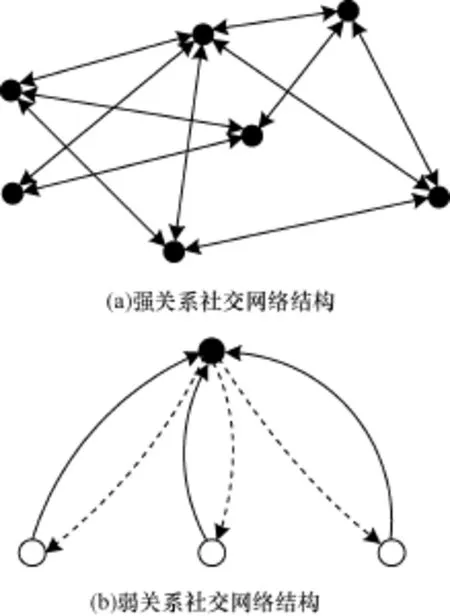
图4 典型强弱关系社交网络结构
微博用户间存在关注关系和传播关系的双重特征,以图4(b)所示微博关注网络为例,用户A关注了用户D,A与D之间存在关注关系A→D;当用户D发表一条微博M时,A会收到微博M(D的所有粉丝A,B和C都会收到该微博),A与D之间又存在传播关系D→A;这样用户A与D之间同时存在A→D表示的关注关系以及D→A表示的传播关系。若用A↔D统一表示用户间的这种复合关系,可以定义微博传播网络G=(V,E),其中,V为微博用户集合;∀v∈V表示微博中的一个用户;E={eij|∀vi,vj∈V,vi关注vj或vj关注vi}为微博中用户间的传播路径集合,∀eij∈E为无向边,表示用户间的关注关系和传播关系。
3.3 传播节点的重要性
在微博的传播中,关键节点(网络大V、名人、不同领域的意见领袖)的转发起到了重要作用[16]。关键节点是指在信息传递和人际互动过程中具有影响
力和活动力的少数人[17],这些关键节点在某种程度上引导人们的消费、言论和政治观点。使用粉丝数和转发数对用户影响力进行研究,发现粉丝数多的用户微博不一定会有很多的转发及评论数[11]。由于炒作微博是为了进入运营商的热门微博榜单,进而被更广泛的传播。
4 基于群体策划现象的炒作微博识别方法
4.1 微博传播网络的参数度量与选择
微博前期的炒作行为伴随着大量的刻意转发和评论,这都需要巨大的人力资源投入。为了达到数量上的要求,炒作用户一般会聚集为一个个团体,听从某些关键人物的领导,对指定微博进行转发和评论。微博传播过程中,传播节点的聚集程度是本文研究和识别炒作微博的关键问题。
4.1.1 社团模块度
微博的传播网络符合社团网络的无向图结构,为了判断传播节点的聚集程度,引入社团模块度的概念,用一个模块函数[18]来模拟、判定社团的紧密程度,定量地描述网络中社团存在的可能性,并衡量网络社团结构的划分。模块度是指网络中连接社团结构内部顶点的边所占的比例与另外一个随机网络中连接社团结构内部顶点的边所占比例的期望值相减得到的差值。这个随机网络的构造方法为:保持每个顶点的社团属性不变,顶点间的边根据顶点的度随机连接。利用函数Q定量描述社团划分的模块化水平:
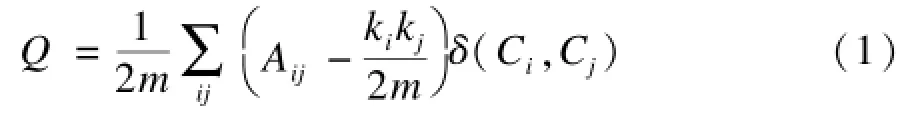
其中,ki和kj是节点的度值;Ci是节点i所属社团;m是网络总边数。当Ci=Cj时,δ(Ci,Cj)=1,否则为0;Q值在0~1之间,一般以Q=0.3作为网络具有明显社团结构的下限。如果社团内部顶点间的边没有随机连接得到的边多,则Q函数的值为负数。相反地,当Q函数的值接近1时,表明相应的社团结构其内部联系高度紧密。在实际网络中,Q存在峰值,模块度越接近峰值,社团结构越明显,峰值常位于0.3~0.7之间。
4.1.2 平均最短路径
最短路径是指在一个赋权图的2个节点间找出一条最小权的路径,平均最短路径是指一个网络中两点之间最短路径的平均值。而社交网络拓扑特征则体现了现实网络中最短路径的一些内在规律。不同于随机网络,社交网络中的大部分节点多在小范围内相互连接,呈现出一定的高聚集系数特性,也不同于规则网络,社交网络结构中任意两点间的距离都较短,其原因在于一些连接不同簇的“长边”。文献[19]提出弱连接,认为弱连接比强连接更能穿越不同的群体,因此能触及更多的人,穿过更大的社会距离。从这个角度出发,解释了小团体内部的互动如何汇聚成了大规模的结构形态。因此,弱联结理论将微观的和宏观的社会网模型联系在一起。在此利用最短路径来识别微博的扩散范围。如果2条微博的传播数目相同,而传播节点间的平均最短路径差距较大,便认为平均最短路径值大的微博,其传播层数多,影响力大,而平均最短路径小的微博,传播多集中在某个或几个转发者的粉丝间传递,以致于传播层数少,影响力弱。通过计算微博传播中节点平均最短路径,判断节点间的紧密程度,以此识别出炒作微博。本文先使用Floyd[20]算法求解出微博传播图中所有节点之间的最短距离,再求距离的平均值得出平均最短路径长度。主要思想是从任意2个顶点vi到vj距离的带权邻接矩阵开始,依次插入一个顶点vk,然后将vi到vj间的已知最短路径与插入顶点vk后可能产生的vi到vj的距离比较,取两者之间的较小值,得到新的距离矩阵。通过循环迭代,得到的最后带权邻接矩阵Dn就反映了所有顶点对之间的最短距离信息。算法具体描述如下:
(1)定义初始的距离矩阵D0:

(2)根据以下公式构造迭代矩阵Dk:
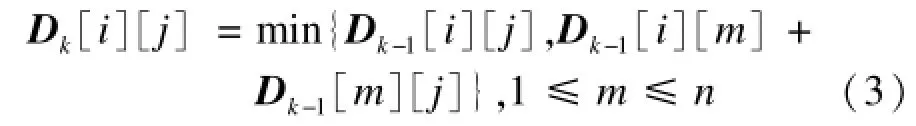
(3)当Dk=Dk+1,终止算法;否则,重复步骤(2)。
4.1.3 网络直径
网络直径是指网络中任意节点间距离的最大值,一般用链路数来度量。网络直径能在一定方面反映社交网络中信息的传播广度,对于传播节点相同的微博信息传播网络来说,网络直径越长,传播的广度越大。本文用网络直径来表示微博信息传播的广度。由于炒作微博大多是由水军团体传播的,其传播范围也仅限于几个水军群体之间。而热门微博符合蒲公英的传播方式,扩散范围广、受众人群多、网络直径大。本文使用网络直径来判断微博传播的范围。
4.2 基于SVM的炒作微博识别方法描述
支持向量机的主要思想是:对给定有限数量的训练样本的机器学习,通过在原空间或投影后的高维空间中构造最佳超平面,将2种类别的训练样本
线性可分,再使用线性可分的原理判断分类边界。在高维空间中,它是一种线性划分,而在原有数据空间中,它是一种非线性划分。
首先考虑炒作微博和正常微博的分类问题,设置模式样本点(xi,yi)服从样本空间X×Y上的某个未知概率分布P(x,y),其中,X代表二维向量(x1表示平均最短路径,x2表示微博传播网络直径);Y为模块度(x1∈(1,+∞),x2∈(1,+∞),y∈(0,1))。目的是寻找一个超平面将数据划分开。本文使用最大间隔法,分类边界是值从分类面分别向2个类的点平移,直到遇到第1个数据点,2个类的分类边界的距离就是分类间隔。
分类平面表示为(w·x)+b=0,其中,x是多维向量。分类间隔的倒数为:。所以,该最优化问题表示为:
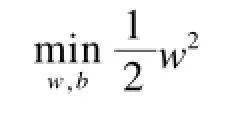
s.t.yi((w·xi)+b)+1)≥1,i=1,2,…,l(4)其中,约束要求各数据点(xi,yi)到分类面的距离大于等于1,yi为数据分类。
4.3 基于SVM的炒作微博识别框架
基于SVM的炒作微博识别框架主要由数据预处理器、SVM分类器、SVM训练和决策响应等主要部分组成,如图5所示。
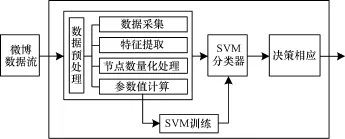
图5 基于SVM的炒作微博识别框架
其中,数据预处理是对大量微博数据流进行获取、分类和提取,包括数据采集、特征提取、节点数向量化处理、参数值计算功能。数据采集是通过API对微博社交网站运营商服务器上的数据进行采集。特征提取是对传播微博的用户ID及传播路径进行提取。节点数据量化处理是对这些TXT文本数据按照微博信息传递的路径和向量的指向性质,对其扩散指向进行量化,映射出整条微博的传递方向。参数值计算是计算社团模块度和最短路径。SVM分类器是对这些参数进行分类后把结果输入相应单元进行最后决策。
整个过程由2个阶段完成,即训练阶段和测试阶段。首先把训练数据(例如,某冷饮厂商在一时间段的全部微博数据,包括炒作微博和正常微博)通过数据转换转化为SVM分类器可识别的数据。在训练阶段,利用训练数据训练SVM对炒作微博进行分类,分析训练结果。在测试阶段,将未知的测试数据进行数据预处理,得到判断参数,进行炒作微博的识别。最后对检测结果进行人工识别,给出识别准确率,并对识别误差进行分析。
5 实验结果与分析
5.1 训练数据集的选取与采集
本文的训练数据集采自于2013年5月-10月人工识别某冷饮厂家雇佣水军炒作传播数在10 000以上的数据以及微博风云榜上的热门微博。提取单条微博的传播路径和节点信息,对传播节点进行分析,获取其粉丝和关注者的数据,用于计算单条微博传播节点间的紧密程度以及判断是否有社团存在的可能性。
在对炒作微博的传播路径节点信息进行分析后,发现炒作微博的社团模块度峰值Q都超过了0.8,模块度峰值最高的是某冷饮厂商雇佣水军诋毁竞争对手的微博,2天传播30 883条,模块度峰值Q=0.903,并且出现微博评论数接近转发数的状况。对其官方微博进行分析,其拥有百万粉丝量,日均微博数4.79条,发布微博分为4类:(1)产品宣传; (2)别人对其的炒作,官方进行转发;(3)贬低竞争对手;(4)原创或转发的一般微博。经对其半年官方微博进行跟踪发现,对自己产品进行宣传促销和诋毁直接竞争对手这2类微博,转发数和评论数超过其发布的原创微博和转发微博几十个数量级。在对其历史微博数据和粉丝数目演化进行还原,存在明显买粉丝情况,在个别时期达到50%(25.6×104)的增长量(图6),而平时仅百余人的粉丝增长数目。对粉丝质量进行分析可见,在大规模粉丝增长的情况下,粉丝明显呈现出僵尸粉丝和水军的特性(注册时间集中、评论及转发内容多是广告和诋毁性质的博文)。在与对手竞争最激烈的2013年5月-6月,其雇佣的大量水军对其博文进行转发与评论(图7),造成了极大的社会影响力。
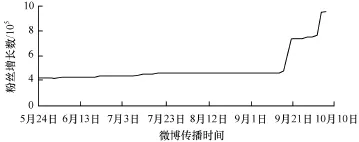
图6 某冷饮微博粉丝增长趋势
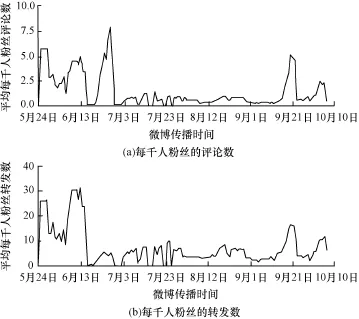
图7 某冷饮微博每千人粉丝的评论与转发量
5.2 结果分析
在对某冷饮厂家传播量超10 000的微博数据进行分析后,再与之前获取的热门微博数据进行对比分析,通过SVM分类器对2种类型的微博数据进行分类(图8),可以看出两者存在明显区别,炒作微博的模块度峰值远超出正常社团的0.3~0.7的区域,并且平均最短路径为3.395,也明显背离六度分隔理论,最长网络直径在7以内,与传播数相同的热门微博最长网络直径23相比,存在明显差距。对已识别出疑似的炒作微博进行传播节点的出度分析(一个节点被直接转发一次,称其出度值为1)。按节点出度大小进行排列后,可知出度大的节点与出度小的节点存在指数倍差距(图9)。
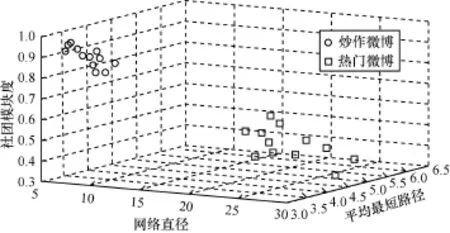
图8 炒作微博与热门微博的SVM分类
图9 炒作微博中的大V参与程度
某些出度较大的节点在此冷饮厂商的多条炒作微博中重复出现,而该厂家正常的微博转发节点并没有这些大V参与。
对这些疑似炒作微博中的大V进行分析,提取大V的用户名,在国内某水军炒作网站上进行查询,如图10的博主列表,在某冷饮厂商的炒作及抨击竞争对手的博文中,参与转发的大V,有93%的炒作大号存在于此网站的列表中。
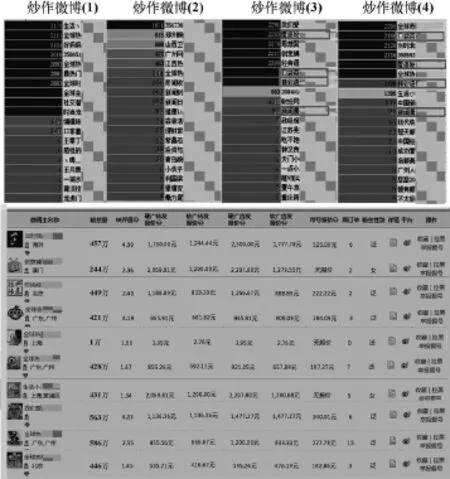
图10 参与炒作的大V及其报价表
不同的粉丝量、转评值(一条微博中进行转发和评论数目的比值)决定了其不同的定价,并且每个炒作大V都表明了硬广转发报价、软广转发报价、硬广直发报价、软文直发报价和炒作平台等信息,甲方可根据自己的需求和传播量进行选择。本文所选取的炒作微博厂家为了得到更好的传播效果和影响力,每次发布产品宣传和诋毁竞争对手的博文,都会雇佣多个炒作大号对其博文进行传播。如果把其雇佣炒作团体进行转发与评论的微博从炒作账号的出度删除后,炒作微博的平均转发数目为116.45条,与其正常微博平均转发数的61.48条相比,炒作微博的影响力并没有得到有效提升。
图11反映了图10中炒作微博(1)的传播路径图。图10中显示了此条炒作微博包含了10个出度在2 000以上的大V账号ID、出度为347和247的2个较小账号ID以及其余的出度在10以内的账号ID。展现了10个大V和2个较小账号的微博传播消息结构。

图11 对应图10炒作微博(1)的微博信息传播结构
5.3 测试数据集的选取与采集
本文选取国内新浪微博2013年7月2日前转发量超过10 000的433条微博数据进行测试实验。通过新浪微博开放API得到相关数据(2013年7月2日API升级后,非授权用户的数据只能通过business API获取)。数据及数据间的关系为:
(1)微博属性:发布时间,转发数,评论数,转发者ID,评论者ID;
(2)用户关系:用户ID,关注用户ID,粉丝ID。
5.4 测试结果误差分析
通过对这433条转发量超过10 000的微博数据进行实验,使用基于SVM的炒作微博识别方法发现疑似炒作微博57条,然后对测试数据进行人工识别,确定为炒作微博的有43条,如表1所示。

表1 基于模块度与最短路径的炒作微博识别
对误判为炒作微博的数据进行分析,发现其主要由三部分组成:(1)大V或名人粉丝之间的口水战;(2)大V或名人重复转发自己的微博;(3)低俗博主的微博。它们的相同特征是在微博的传播过程中,参与的人群相对单一。如图12所示,它的社团模块度峰值Q=0.776,L=3.739,微博是由一网络名人L某评论另一网络名人Z某后,对方回应,而引起的双方粉丝在此条微博的评论中互相攻击。参与传播的人群为双方的粉丝,这是造成了此条微博的模块度增高,最短路径降低的原因。
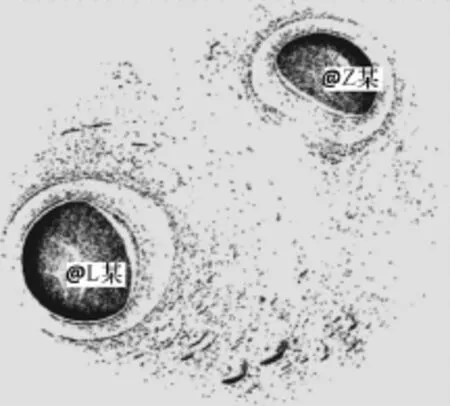
图12 网络名人间口水战的微博信息传播结构
图13 社团模块度峰值Q=0.799,L=3.662,被误判为炒作微博的原因是此大V为了突出这条微博的重要性,不断的重复转发自己的微博,由于在传播过程中,主要是其粉丝团对本条微博进行转发或多次转发,在微博传播过程中呈现出的社团结构单一,而被误判为疑似炒作微博。

图13 大V多次转发迅速扩散的微博信息传播结构
图14 社团模块度峰值Q=0.817,L=3.657被误判为炒作微博是其大V博主的特性决定的,此类博主的粉丝多是占广大网民中基数较大的普通网民,其带有娱乐感的搞笑微博引发粉丝互动带动网民跟风,评论数超过了转发数的2倍以上。微博大V们顾及自己的社会影响力与自身形象往往不会关注与转发此类博主的微博,从而造成此类微博虽然拥有众多转发数,但没有转发深度,只是粉丝们的直接转发,并不能引起深层次的转发效果。

图14 某女星的微博信息传播结构
检测时间为在API获取单条微博全部传播节点后,对数据进行分析的时间。由于新浪微博对不同权限的开发者提供了不同的API调用权限(以Business API为例,作为开发者的最高权限,数据的获取速度仅和带宽有关),因此检测时间并不包括数据获取的时间消耗。实验在CPU为2核、主频2.53 GHz,内存为4 GB的一台笔记本上运行,其结果如表2所示。
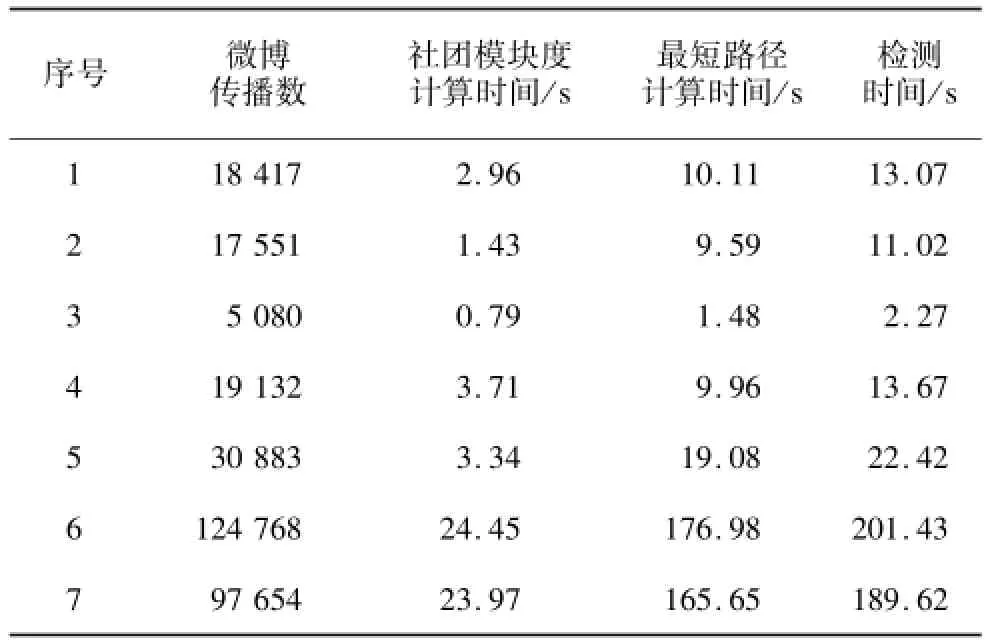
表2 算法检测时间
从表2可以看出,本文算法复杂度是随着微博传播数的增多及传播节点间联系的复杂程度成线性增长。测试数据中最大的传播数为124 768,算法平均消耗时间在3 min以内,其中最快检测时间达到13.07 s,传播数为97 654条的炒作微博进入了当日的热门微博榜单。
6 结束语
在发生有组织的炒作事件后,定位信息发生源和其转发关键用户,对信息进行实时监控预警是防止恶意网络造谣事件发生的关键。本文基于社团模块度与六度分隔理论,设计基于群体策划现象的炒作微博识别方法。实验结果表明,基于模块度与最短路径的炒作微博识别方法,可以有效识别炒作微博,并且具有较高的准确性。通过实验证明了该方法具有一定的合理性和优势,但在今后工作中还将对以下问题展开研究:(1)区分炒作微博的类型以鉴别微博营销的目的,加入情感分析,对于炒作微博的博文情感值和评论的情感值进行分析和判断,建立炒作微博字典,以便能准确地区分炒作微博是自我营销行为还是恶意的诋毁和攻击;(2)对名人或官方微博的影响因子进行细度优化,克服微博名人效应对识别准确率的干扰。
[1]Yu L L,Asur S,Huberman B A.Artificial Inflation:The True Story of Trends in Sina Weibo[C]//Proceedings of 2012 International Conference on Social Computing.Amsterdam,Holland:IEEE Press,2012:514-519.
[2]任一其,王雅雷,王国华,等.微博谣言的演化机理研究[J].情报杂志,2012,31(5):50-54.
[3]Castillo C,MendozaM,PobleteB.Information Credibility on Twitter[C]//Proceedings of WWW’11.New York,USA:ACM Press:[s.n.],2011:675-684.
[4]Gupta M,Zhao Peixiang,Han Jiawei.Evaluating Event Credibility on Twitter[C]//Proceedings of SDM’12.Anaheim,USA:IEEE Press,2012:153-164.
[5]顾明毅,周忍伟.舆情及社会性网络信息传播模式[J].新闻与传播研究,2009,16(5):67-72.
[6]刘 颖,李欲晓.网络舆情传播特征分析[J].北京邮电大学学报:社会科学版,2011,13(4):1-6.
[7]陈 波,于 泠,刘君亭,等.泛在媒体环境下的网络舆情传播控制模型[J].系统工程理论与实践,2011, 31(11):2140-2150.
[8]Centola D.The Spread of Behavior in an Online Social Network Experiment[J].Science,2010,329(5995): 1194-1197.
[9]Lu Linyuan,Chen Duanbing,Zhou Tao.The Small World Yields the Most Effective Information Spreading[J].New Journal of Physics,2011,13(12):1230-1235.
[10]Kwak H,Lee C,Park H,et al.What is Twitter,A Social Network or a News Media?[C]//Proceedings of the 19th International Conference on World Wide Web.New York,USA:ACM Press,2010:591-600.
[11]Meeyoung C C.Measuring User Influence in Twitter: The Million Follower Fallacy[C]//Proceedings of the 4th International AAAI Conference on Weblogs and Social Media.Palo Alto,USA:AAAI Press,2010: 174-179.
[12]Weng J.TwitterRank:Finding Topic-sensitive Influential Twitterers[C]//Proceedingsofthe3rdACM International ConferenceonWebSearchandData Mining.New York,USA:ACM Press,2010:261-270.
[13]丁乙乙,周元英.谁在操控网络舆论?[J].IT时代周刊,2010,(1):5.
[14]Facebook Research Report:TheImportanceofSocial Network of Weak Ties[EB/OL].(2012-05-11).http:// www.sina.com.cn/i/2012-01-18/13286651169.shtml.
[15]Han Yanni,Li Deyi,Wang Teng.Identifying Different Community Members in Complex Networks Based on Topology Potential[J].Frontiers of Computer Science in China,2011,5(1):87-99.
[16]Wang Chenying,Yuan Xiaojie,Wang Xin.An Efficient Numbering Scheme for Dynamic XML Trees[C]// Proceedings of InternationalConference on Computer Science and Software Engineering.Washington D.C.,USA: IEEE Press,2008:704-707.
[17]Lazarsfield P.The People’s Choice[M].New York, USA:Columbia University Press,1948.
[18]Newman M E J,GirvanM.FindingandEvaluating Community Structure in Networks[J].Physical Review E,2004,69(2).
[19]Granovetter M S.The Strength ofWeak Ties[J].American Journal of Sociology,1973,78(6):1360-1380.
[20]Lin S.Computer Solutions of the Traveling Salesman Problem[J].Bell System Technical Journal,1995, 44(10):2245-2269.
编辑 陆燕菲
Hype Microblog Recognition Method Based on Support Vector Machine
DONG Yuchen,LIU Yan,LUO Junyong,ZHANG Jin
(State Key Laboratory of Mathematical Engineering and Advanced Computing,Zhengzhou 450001,China)
Microblog is not only a center or channel of mass media,but also involved in the formation,development and guidance of public opinions.The propagation of speculation microblog which is released from We-media,opinion leaders or some other users,causes microblog rumors,false hype,social mobilization and other problems.This paper analyzes the phenomenon of covert planning,mines the difference of the structure in communication networks and the incremental statistics of forwardings between the ordinary and the speculation.A novel algorithm for hype microblog recognition is proposed in this paper based on Support Vector Machine(SVM)which uses the modularity peak spread and the average diameter of the shortest path in propagation network.The proposed method has advantages of less dependence on user profile information and is sensitive to the structure of propagation networks,and it has higher recognition accuracy.
social network;hype group;hype microblog;community module degree;network diameter;average shortest path;Support Vector Machine(SVM)
董雨辰,刘 琰,罗军勇,等.基于支持向量机的炒作微博识别方法[J].计算机工程,2015,41(3):7-14.
英文引用格式:Dong Yuchen,Liu Yan,Luo Junyong,et al.Hype Microblog Recognition Method Based on Support Vector Machine[J].Computer Engineering,2015,41(3):7-14.
1000-3428(2015)03-0007-08
:A
:TP393
10.3969/j.issn.1000-3428.2015.03.002
国家自然科学基金资助项目(61309007);国家“863”计划基金资助项目(2012AA012902);国家科技支撑计划基金资助项目(2012BAH47B01)。
董雨辰(1988-),男,硕士研究生,主研方向:网络信息安全,网络态势感知;刘 琰(通讯作者),副教授、博士;罗军勇,教授;张 进,硕士研究生。
2014-04-11
:2014-05-19E-mail:ms_dyc39@aliyun.com
猜你喜欢
阅读(中年级)(2022年9期)2022-10-08
机械工业标准化与质量(2022年6期)2022-08-12
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
国际眼科杂志(2021年9期)2021-09-15
装备制造技术(2020年2期)2020-12-14
军事文摘(2017年16期)2018-01-19
中学生(2016年13期)2016-12-01
中国卫生(2015年12期)2015-11-10
汽车与新动力(2012年1期)2012-03-25
