
一种支持海量人脸图片快速检索的索引结构
2015-02-20 08:15冯伟国
计算机工程 2015年3期
汪 昀,朱 明,冯伟国
(中国科学技术大学自动化系,合肥230027)
一种支持海量人脸图片快速检索的索引结构
汪 昀,朱 明,冯伟国
(中国科学技术大学自动化系,合肥230027)
为了在大规模的人脸数据库中准确快速地检索到所需图像,提出一种相似人脸检索方法。提取人脸图片的局部二值模式特征,通过建立投影矩阵将特征从欧几里德空间映射到汉明空间实现降维,再采用改进的多比特编码方法对降维后的特征进行编码,并生成图片签名,以曼哈顿距离取代汉明距离衡量签名之间的相似度,根据图片签名集合构建倒排索引表,通过倒排索引表高效地查找相似图片。包含20万张人脸图片的实验数据集的结果表明,该方法在保证检索精度的前提下,检索时间控制在0.15 s以内,能够满足海量人脸图片检索的准确性与实时性要求。
海量人脸图片;局部二值模式特征;图片签名;多比特编码;倒排索引;快速检索
1 概述
随着互联网的快速发展和实际应用,人类的生产生活已经迈入信息化的时代。互联网应用一方面为人们带来诸多便利,提供大量资讯,另一方面信息化的社会生活正产生指数级的信息量增长。面对互联网信息的爆炸式增长,如何有效、快速地寻找有价值的资讯是目前计算机研究的热点问题。这其中多媒体技术的发展尤为快速,互联网中图像的使用不断在扩大,据统计视觉信息的比重已占到互联网信息的25%以上。图像以其所含有的丰富信息量在日常生活中发挥着无法替代的信息媒介作用,而人脸图片的比重约占所有图片的60%以上[1],面向海量的人脸图片进行快速有效的相似性检索逐渐成为一个研究热点。
本文提出一种支持海量人脸图片快速检索方法。该方法对高维的特征向量进行降维处理,相似的原始特征向量降维之后得到的编码仍能够保持相
似性,通过对降维后的编码建立倒排索引表以供检索,满足检索的实时性要求。
2 背景介绍
人脸图片的检索一般先检测图片中的人脸并进行预处理工作,然后对标准化后的人脸图片提取特征生成特征向量,将相似人脸的检索问题转化为特征向量之间的距离匹配问题。由于图片特征往往是高维向量,计算高维向量之间的距离有着极大的时间复杂度,通常会陷入维度灾难之中,因此需要研究一种快速有效的检索结构避免上述问题。文献[1]采用人物属性编码作为图片的特征,利用人脸图片的低层次特征获取人物的一组属性编码,如性别、肤色、年龄等,并用这些属性构建倒排索引,提高检索效率。然而,从图片的特征获取人物的属性存在较大的不确定性,特别是性别、年龄等属性的判断仍是目前难以解决的问题,属性标记错误直接影响了检索的准确率。文献[2]提出了一种基于身份量化的人脸检索方法,这种方法将人脸关键部位分为175个子块,对每个子块提取局部特征,之后选取若干个人物的图片作为标准字典库,人脸数据库中每张图片的每一个子块用标准字典中最相似的相应子块所属的人物ID表示,图片特征被量化为175个身份ID值,并以身份ID作为索引实现快速检索,同时利用LE方法提取人脸的全局特征并进行哈希获得图片的签名,根据图片签名的汉明距离大小对检索的结果重新排序。该方法虽然实现了海量人脸图片的快速检索,但步骤繁琐、系统复杂,特别是标准字典库更新之后需要重新对人脸数据库的图片进行身份量化,离线操作工作量庞大。文献[3]采用改进的kmeans聚类算法对图片库的图片进行聚类,提出了平均面积直方图和图像密度的概念,增强不相似图片之间的区分度,通过图像密度分布解决聚类初始中心不稳定以及聚类类别数目难以确定的问题,缩小了查询范围,提高检索的速度和精度,不过图片库更新后需要重新进行聚类操作,特别是在图片数据库庞大的情况下聚类操作时间复杂度更高。文献[4]提出了扩展的位置敏感哈希(Locality Sensitive Hashing,LSH)算法投影高维的图片特征向量,该投影空间具有更高的局部敏感性以提高图片的匹配度和检索性能。文献[5]采用了反馈学习的方法,首先建立LSH索引结构对输入的图片进行检索获得初步结果,之后用户根据结果标记出检索正确与检索错误的图片,通过用户的反馈信息训练支持向量机分类器生成符合用户期望的新的检索结果。文献[6]阐述了二值模式特征(Local Binary Pattern,LBP)不能准确反映图片内容的空间信息的问题,改用局部灰度变化共生矩阵描述了每个像素点周边4个不同方向上相邻像素点的灰度变化信息,考虑了空间分布信息,提高了特征描述的准确性。文献[7]综合考虑了图像的颜色、纹理、形状特征。将它们结合起来作为图像的整体特征表示,这种从多方面描述图像的方法更细致地表达了图像的信息,保证了检索的高效性。
3 索引结构原理
3.1 索引结构框架
本文提出的海量人脸图片快速检索系统分为离线操作和在线操作2个流程。离线操作中,首先提取人脸库中图片的二值模式特征(LBP),然后按照投影方法对特征向量进行降维编码,最后依据整个人脸库各张图片编码特征构建倒排索引;在线操作过程也即图片检索过程如下:对输入的查询图片提取LBP特征并降维编码后通过倒排索引结构获得最相似的TOP-K张人脸图片。
3.2 图片特征表示方法
本文采用LBP[8]描述人脸图片,LBP特征是一种局部二值模型特征,它是一种用来描述图像局部纹理特征的算子,具有旋转不变性和灰度不变性的优点,且计算简单、纹理判别能力强,已经广泛用于图像检索领域之中。
首先将人脸划分成若干个小区域,对每个区域统计出LBP直方图,最后将所有区域的LBP直方图进行拼接后生成人脸的LBP特征。
LBP直方图计算方法如下:对于人脸的灰度图片,选取其中某一像素点为圆心,以r为半径画圆,并在圆周上等间隔选取k个像素点,分别计算出圆心处的像素点和圆周上k个像素点的灰度值,将圆周上的k个像素点的灰度值依次与圆心处像素点的灰度值比较,若圆周上的像素点灰度值大于等于圆心处像素点的灰度值,则将圆周上该处标记为1,否则标记为0,如图1所示。
图1 LBP算子示意图
以圆周上的某一像素点为起点,以顺时针或逆时针将经过0和1标记后的圆周上的k个像素点的标记值串接在一起,本例中取最上方的点为起点,顺时针将这些值串接在一起得到11101010,需要注意的是起点和方向的选取是任意的,但要保证对所有
的人脸图片的每一个采样像素点都采取相同的起点和方向。将串接后的值转换为十进制数值,得到中心像素点处的LBP值。对人脸各个分块区域中的每一个采样点做上述处理,得到各个分块区域的LBP直方图,将各个区域的LBP直方图进行拼接之后生成整个人脸图片的LBP特征。
LBP算法复杂度低,消耗内存小,原理简单,适用于需要快速提取特征及检索的场合。
3.3 特征降维编码
对高维特征向量进行直接检索通常会面临维度灾难[9]的问题而导致检索速度过慢,无法满足检索的实时性要求,通过将高维特征向量从欧几里德空间映射到汉明空间中可以有效地实现特征的降维,降低检索的时间复杂度。为了保证在欧几里德空间中距离相近的高维向量在投影到汉明空间后仍保持距离的相近,本文借鉴文献[10]中的映射投影方法对生成的高维图片特征向量作如下处理:
(1)假设原始图片特征xi为1×d维(本文实验中d=1 770),投影后的特征zi为1×dp维且dp≪d(本文实验中dp=64)。随机生成d×d维的矩阵G,G中的每一个元素取自随机变量Y,Y服从期望μ= 0,方差σ2=1的高斯分布。
(2)对矩阵G做QR分解,满足QR=G,QTQ=I且R为上三角矩阵,得到d×d维的Q矩阵。
(3)取Q矩阵的前dp行构成dp×d维投影矩阵P,对原始图片特征xi进行投影得到降维后的特征zi,其中,zi=xiPT=(zi1,zi2,…,zidp)。
传统方法对降维后的特征进行量化编码一般采用如下方法:获取投影后的特征集合每一维的中值为mj,j∈[1,dp],按式(1)进行中值量化[11]得到二值编码的结果为bi=(bi1,bi2,…,bidp),以下称该结果为图片的签名,利用不同图片签名之间的汉明距离衡量图片的相似度,2张图片签名的汉明距离越小则说明这2张图片越相似,反之越不相似。

这种将降维后的特征量化为二值编码并利用汉明距离衡量相似度的方法存在精度不高的缺点,例如中值为50,极为相近的2个数值49和51被量化成不同的值0和1,而距离较大的2个数值1和99也被量化为0和1,这2组数值经量化后的汉明距离均为1,但原始数值之间的距离却相差甚远,这就引入了很大的量化误差。本文对量化过程做出改进,并采用曼哈顿距离[12]代替汉明距离作为衡量相似度的标准:
(1)确定投影后向量的每一维zij量化结果比特数q,得到2q个可选量化值,q=1时等同于式(1)中的二值量化,q=2时量化可选结果为00,01,10,11,以此类推。
(2)根据选择的q,将降维后的特征集合的各维按升序排列,平均分为2q等份,得到2q-1个分隔值,用mkj表示第j维的第k个分隔值,k∈[1,2q-1],j∈[1,dp]。
(3)按式(2)进行量化得到编码结果为bi= (bi1,bi2,…,bidp),即图片的签名。
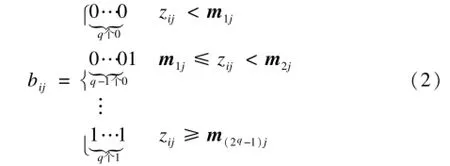
采用曼哈顿距离代替汉明距离衡量签名之间的距离,曼哈顿距离定义如下:对每一维为qbit的签名b1=(b11,b12,…,b1dp)和签名b2=(b21,b22,…,b2dp),对应维如b11和b21的曼哈顿距离为:
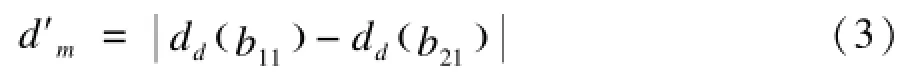
其中,dd(b11)和dd(b21)分别表示b11和b21的十进制值。按此定义,b1和b2这2个签名的曼哈顿距离为:
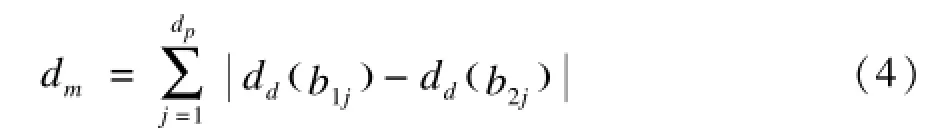
2张图片的曼哈顿距离越小代表这2张图片越相似,反之越不相似。上述处理避免了量化误差过大的情况出现,以q=2为例,此时有3个量化分隔值,假设分别为25,50,75,那么数值49和51分别被量化为01和10,数值1和99分别被量化为00和11,这2组数值经量化后的曼哈顿距离分别为1和3,相比采用前述式(1)的量化方法及汉明距离衡量相似度,曼哈顿距离具有更好的区分度,减小了量化误差,且q越大,量化的结果越精确。当q=1时,式(2)等价于式(1),曼哈顿距离退化为汉明距离。
3.4 索引构建
依次计算查询图片和海量库中各图片签名距离的时间复杂度过高,检索的实时性差,因此,需要一种有效的索引结构实现相似人脸图片的快速检索。图片签名有dp维,每一维有qbit,故每个图片签名bi=(bi1,bi2,…,bidp)可视为由dp个单词组成,本文以图片签名的各单词构建索引,实现快速检索。根据签名的单词数dp,生成dp个索引表,分别由签名集合的第1维~第dp维对应的单词构建,索引表的单词后排列出包含该单词的图片序号,如图2示意了q=2时的索引表集合。
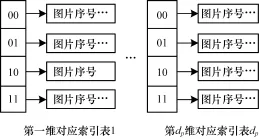
图2 q=2时索引表集合示意图
结合前述曼哈顿距离的概念,这里使用距离阈值T来表示与签名的某一单词bij曼哈顿距离不大于T的单词具有相似性,也可理解为考虑到量化误差的存在,签名的单词bij也可量化[bij–T,bij+T]范围内的各单词。此时,对于图片i的签名bi= (bi1,bi2,…,bidp),将图片的序号i分别插入第1个索引表的[bi1–T,bi1+T]范围内的各个单词后、第2个索引表的[bi2–T,bi2+T]范围内的各个单词后,以此类推,直到插入第dp个索引表的[bidp–T,bidp+T]范围内的各个单词后。对图片库所有图片签名做相同的插入操作之后便完成了索引构建。采用本文的索引构建方法的优点在于:当图片库更新之后,只需将更新的图片签名插入索引表或从索引表中删除即可完成索引表更新操作,简单快速。
3.5 查询方法
对查询图片i的签名bi=(bi1,bi2,…,bidp),分别于索引表1,2,…,dp中查找单词bi1,bi2,…,bidp,获取图片序号的集合,统计集合中各个图片序号的出现次数,设序号为j的图片在集合中出现了y次,则图片i和j的相似度由式(5)确定:

按降序排列图片i和库中各图片的相似度值,输出最相似的Top-K张图片。实验表明,该索引结构能够迅速返回查找结果,满足检索对实时性的要求。
4 实验结果与分析
为了验证本文提出方法的有效性,以YouTube Faces人脸数据库作为数据源,该数据库的人脸图片提取自YouTube视频网站上的1 595个不同人物的3 425个视频之中,选取其中的200 000张人脸图片进行实验,实验硬件环境为Intel Core i3-2120 3.30 GHz CPU,4 GB内存。测试时随机从库中选取1 000张图片作为查询图片,分别对T=0,q取不同值的情况下,图片库大小为50 000,100 000, 150 000,200 000张时的检索时间做了测试,求出平均的检索时间,实验结果如图3所示。
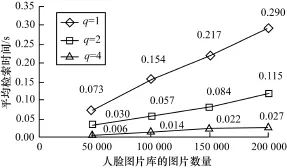
图3 不同q及人脸库规模下的平均检索时间
实验结果表明,采用本文的索引结构,在20万张图片库中检索一次的最大时间不超过0.3 s,且q越大,检索速度越快,q=4时的检索时间仅为0.027 s,即在本文的索引结构之上采用多比特量化的方法可以有效地提升检索速度。当q增大时,索引单词项增多,使得其后的图片编号数量减少,从而减少了在索引表中进行一次查询所得的图片编号数,降低了统计次数,提高了检索速度。但是由于人脸图片受光照、角度、姿态等影响,相同的人在这些不同环境下的图片提取出的原始特征本身会存在差异,导致编码后的特征也存在差异。此时,若选取T=0,会造成相似判断条件过为苛刻,准确率会有所下降。通过提高T的值,弥补准确率降低的缺点,虽然一定程度上增加了索引单词后的图片编号数造成检索时间稍有增加,但仍快于q=1,T=0时的传统汉明距离检索方法。实验统计如下:在图片库为200 000张的情形下,随机选取1 000张图片作为查询图片,分别对q=4,T取不同值的情况做检索,对前10张检索结果的平均准确率及检索时间做出统计并与q=1,T=0时的平均准确率和检索时间做出对比,如表1所示。
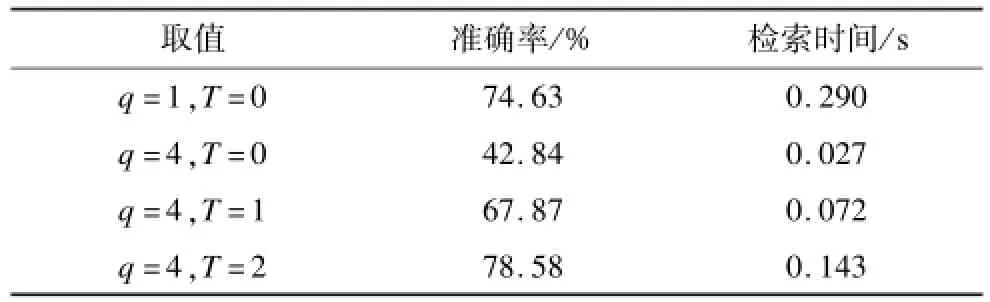
表1 准确率和检索时间对比
从表1可以看出,增大T值有效地提高了准确率,q=4,T=2时的准确率已经高于q=1,T=0时的准确率,且检索时间仅为其一半。综合图3和表1的实验结果,可见本文提出的采用改进的多比特编码方法并利用曼哈顿距离衡量图片相似度的索引结构可以在保证精度的前提下实现快速检索。
下面考虑该索引结构的内存消耗:存储代价主要来源于将索引读入内存,索引表主要存放索引的单词和图片编号,由于图片编号数量远大于索引单词条目,因此索引单词条目占用的内存可以忽略不计,也即在一定范围内增大q并不会带来内存的增
加,消耗内存的大小应与图片数量、T的取值以及索引表数目有关。图片编号若以整形保存,索引表的个数为dp,对于T=0,dp=64时的200 000张图片构建的索引表共消耗内存200 000×4 Byte×64= 48.8 MB,而T=2时最多消耗内存48.8 MB×5= 244 MB,很容易进行分布式扩展,支持百万数量级图片的检索。
最后将本文的索引结构(q=4,T=2)与文献[3]中提出的索引结构进行比较,文献[3]中的聚类索引结构对图片库规模为4 000时的检索时间约为0.09 s,本文对图片库规模为200 000张时的检索时间为0.143 s,图片库规模为文献[3]的20倍而检索时间仅为其1.5倍,并且本文的索引结构可以针对不同需求的情形调节参数,灵活性更强,图片库更新后仅需针对变动的图片对索引表进行插入或删除操作,简单快捷。
综上,本文提出的索引结构在保证准确率的前提下,加快了检索速度,并具有良好的扩展性和灵活性,因此,针对大规模人脸数据库,本文方法有效地实现了海量人脸快速检索。
5 结束语
随着互联网海量人脸图片的出现,快速有效的人脸图片检索方法变得越来越重要。本文提出一种支持海量人脸图片快速检索的索引结构,首先将人脸图片数字化表示为LBP特征,之后对特征进行投影并降维,采用多比特的编码方法生成图片签名,通过签名的曼哈顿距离判别图片的相似度,以签名中的单词构建索引,实现快速检索。在海量人脸数据库上进行的实验结果表明,对于规模为200 000张图片的人脸数据库,在保证检索精度的前提下,检索一次的时间仅需0.143 s,并且具有着良好扩展性,通过调节参数可以适应不同规模数据库下的检索,灵活性强。下一步工作将研究不同光照、姿态、表情下人脸特征的准确表示方法,克服环境变化对相同人物的人脸图片造成的特征提取误差,以求从数据源头提高特征提取的准确性,进一步提高检索的准确率。
[1]Chen Bor-Chun,Chen Yan-Ying,Kuo Yin-Hsi,et al.Scalable Face Image Retrieval Using Attribute-enhanced SparseCodewords[J].IEEETransactionson Multimedia,2013,15(5):1163-1173.
[2]Wu Zhong,Ke Qifa,Sun Jian,et al.Scalable Face Image RetrievalwithIdentity-basedQuantizationand Multireference Reranking[J].IEEE Transactions on PatternAnalysisandMachineIntelligence,2011, 33(10):1991-2001.
[3]史习云,薛安荣,刘艳红.改进k-means聚类算法在图像检索中的应用研究[J].计算机工程与应用,2011, 47(10):193-196.
[4]何周灿,王 庆,杨 恒.一种面向快速图像匹配的扩展LSH算法[J].四川大学学报:自然科学版,2010, 47(2):269-274.
[5]Dong Tingting,Zhao Zhicheng.A NovelInteractive Image Retrieval Method Based on LSH and SVM[C]// Proceedings of the 3rd International Conference on Network Infrastructure and Digital Content.Washington D.C.,USA:IEEE Press,2012:482-486.
[6]Farag A A,Yang Jian,Jiao Feng.A New Texture Direction Feature Descriptor and Its Application in Content-based Image Retrieval[C]//Proceedings of the 3rd International Conference on Multimedia Technology.Berlin,Germany:Springer,2014:143-151.
[7]Lande M V,Bhanodiya P,Jain P.An Effective Contentbased Image Retrieval Using Color,Texture and Shape Feature[C]//Proceedings of Conference on Intelligent Computing,Networking,andInformatics.Berlin, Germany:Springer,2014:1163-1170.
[8]Ahonen T,Hadid A,Pietikäinen M.Face Recognition with Local Binary Patterns[C]//Proceedings of IEEE Workshop on Applications of Computer Vision.Berlin, Germany:Springer,2004:469-481.
[9]Hinneburg A,KeimDA.OptimalGrid-clustering: Towards Breaking the Curse of Dimensionality in Highdimensional Clustering[C]//Proceedings of the 25th Conference on Very Large Databases.Berlin,Germany: Springer,1999:506-517.
[10]Jegou H,Douze M,Schmid C.Hamming Embedding and Weak Geometric Consistency forLarge Scale Image Search[C]//Proceedings of the 10th European Conference on Computer Vision.Marseille,France:[s.n.],2008: 304-317.
[11]Naturel X,GrosP.DetectingRepeatsforVideo Structuring[J].Multimedia Tools Applications,2008, 38(2):233-252.
[12]Kong Weihao,Li Wjun,Guo Minyi.Manhattan Hashing for Large-scale Image Retrieval[C]//Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval.[S.l.]: ACM Press,2012:45-54.
编辑 顾逸斐
An Index Structure of Fast Retrieval for Massive Face Image
WANG Yun,ZHU Ming,FENG Weiguo
(Department of Automation,University of Science and Technology of China,Hefei 230027,China)
In order to quickly and correctly retrieve the desired image from massive face image database,this paper proposes an efficient fast method for similar face image retrieval.It extracts Local Binary Pattern(LBP)features of face images and does dimensionality reduction by mapping the features from Euclidean space into Hamming space.A signature for each image is constructed by encoding dimensionality reduced features,using enhanced multi-bit encoding method.The similarity between each signature is judged by Manhattan distance instead of Hamming distance.It constructs inverted indexes from image signatures and fast retrieval is accomplished by using efficient inverted indexes.Experimental results on dataset containing 200 000 face images show that the retrieval time is less than 0.15 s,which satisfies the retrieval precision as well as the accuracy and real-time of large-scale face image retrieval.
massive;Local Binary Pattern(LBP)feature;image signature;multi-bit encoding;inverted index; fast retrieval
汪 昀,朱 明,冯伟国.一种支持海量人脸图片快速检索的索引结构[J].计算机工程,2015, 41(3):186-190.
英文引用格式:Wang Yun,Zhu Ming,Feng Weiguo.An Index Structure of Fast Retrieval for Massive Face Image[J].Computer Engineering,2015,41(3):186-190.
1000-3428(2015)03-0186-05
:A
:TP391.41
10.3969/j.issn.1000-3428.2015.03.036
中国科学院先导专项课题基金资助项目“网络视频传播与控制”(XDA06030900)。
汪 昀(1988-),男,硕士研究生,主研方向:多媒体检索;朱 明,教授、博士;冯伟国,博士研究生。
2014-03-14
:2014-04-17E-mail:shinichi@mail.ustc.edu.cn
猜你喜欢
车主之友(2022年4期)2022-08-27
现代电子技术(2021年1期)2021-01-17
海峡姐妹(2019年12期)2020-01-14
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年11期)2017-04-04
中国铁路文艺(2016年6期)2016-05-14
应用数学与计算数学学报(2014年4期)2014-09-26
计算物理(2014年1期)2014-03-11
燕山大学学报(2014年1期)2014-03-11
