
基于样例的面部表情基生成
2015-02-20 08:15高娅莉谭光华郭松睿范晓伟
计算机工程 2015年3期
高娅莉,谭光华,郭松睿,范晓伟
(湖南大学信息科学与工程学院,长沙410082)
基于样例的面部表情基生成
高娅莉,谭光华,郭松睿,范晓伟
(湖南大学信息科学与工程学院,长沙410082)
针对现有blendshape表情基的生成多依赖手工建模和微调的问题,提出一种基于样例的表情基自动生成方法。以一组通用的面部模型为先验模型,实现每个blendshape的表情语义逐步求精。通过该方法生成的blendshape表情基能够将通用模型的表情语义和表情动态映射到目标模型上,从而实现模型在应用上的可扩展性,使用户能够按照自身需求逐步计算出更为丰富的面部表情模型。实验结果表明,在梯度空间建立形变约束,并将其转化为一个关于blendshape的优化问题,能更加有效地控制blendshape表情基的变化趋势,并且计算时间更短,真实感更强。
blendshape表情基;基于样例;迭代优化;梯度空间;真实感;表情动画
1 概述
人脸模型参数化是特效电影和计算机游戏中构建虚拟角色的一项重要工作。基于blendshape的动画技术能够逼真地创建出各种虚拟角色的表情动画。由于其直观的控制方式,深受动画师们喜爱。然而,为了追求高度的真实感,动画师即使已经最大限度地控制了一个特定面部的各种细微变化,也还需要调整数百个blendshape表情基。例如,电影《指环王》中的Gollum模型总共用了946个blendshapes[1]。因此,需要动画师既要高效地建立一组个性化的面部表情基又能够使其自动调整以匹配表演者的面部表情。
文献[2-5]使用多线性的主成份分析(Principal Component Analysis,PCA)模型,提出了面部表情基的自动创建方法,然而最终的线性表情基对于表情动画的控制并没有直观上的意义,导致动画师无法直接使用。文献[6]提出一种基于非线性联合学习的三维人脸表情合成方法,该方法的表情重定向合成结果较好,但通过系数插值合成表情时可能产生由于过度变形导致的扭曲表情。文献[7]提出了一种通用的面部表情模拟技术,该方法能有效地对3D
模型或2D图像进行表情转移,但该方法计算效率不高且真实感不够好。
本文提出一种基于样例的blendshape表情基自动生成方法。该方法利用一组通用的面部模型作为先验模型,与新创建的目标模型作为输入,将模板模型的表情动态映射到目标网格上[8],最终采用迭代优化算法求解最优blendshape表情基及对应的混合权重。该方法摒弃了每一个blendshape必须与一个精确表情对应的限制,而只需要一组数量较少的样例模型及满足粗略初始猜想的混合权重即可。
2 基于样例的blendshape表情基自动生成
2.1问题描述
基于样例的表情基生成问题可描述为:给定已知样例人脸模型S和S′,如何根据目标人脸模型T生成T′。
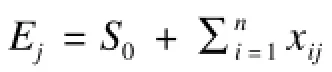
创建新的目标模型(其中包括自然表情和m个其他表情)作为输入。根据非刚性匹配算法[10]将通用模型的自然表情S0与目标模型对齐,产生一组网格集合T={T1,T2,…,Tm}作为训练表情。本文的目的是计算一组新的blendshape表情基B={B0,B1,…,Bn},使之能够最大程度匹配表演者的面部外观特征和运动特征。因此,需要求解出目标blendshape表情基Bi以及对应的权重xij,使得表情基的线性组合与训练表情的误差最小,即:

该问题是一个双线性问题,它的求解存在2个主要问题:(1)在训练表情很少(m<n)的情况下,如何计算目标表情基Bi;(2)在相同权重设置下,如何确保模板模型和目标模型之间的表情语义距离最小。
为了解决上述问题,本文采用了如下迭代优化方法交替迭代进行求解,其步骤如下:(1)保持混合权重xij不变,优化blendshape表情基;(2)保持blendshape表情基不变,优化混合权重。为了提高计算速度,用户需选择适当的混合权重合成一个初略的表情Ej,使其与训练表情Tj大致对应,从而产生逼近的权重,为步骤(1)提供初始值,为步骤(2)提供表情的语义约束。开始训练表情基时,只需设定几个足够表现力的表情的混合权重即可,通常不超过4个,即m≤4。
2.2 目标blendshape模型的重构
在明确问题之后,首先需要将形式化的问题与实际网格模型建立起联系,即:为了实现模板模型的表情能映射到目标模型上,需要对各个模型的网格进行操作,假设源模型和目标模型都是由三角网格构成,则可以针对网格中任意一个由顶点v1,v2,v3构成的三角形r,定义一个3×3的矩阵Ar=[v3-v1,v2-v1,n],n=(v3-v1)×(v2-v1)为三角形的法向量。这里将源三角形r到目标三角形d的变形梯度定义为Hr→d=Ad·Ar-1。其次,在梯度空间建立约束形成优化问题,求解这个优化问题便能重构出最终的blendshape表情基。
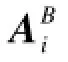
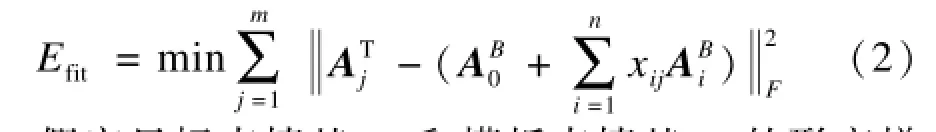
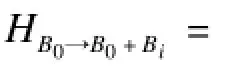
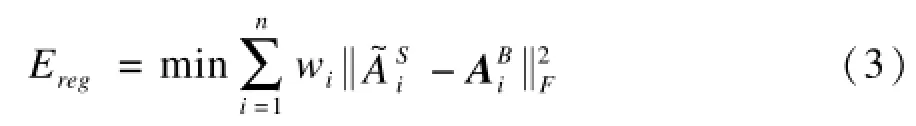

2.3 优化混合权重
给定blendshape表情基集合B,就能求出最优的混合权重xij,使用最小二乘拟合算法重构训练表情Tj。定义如下公式求解xij:
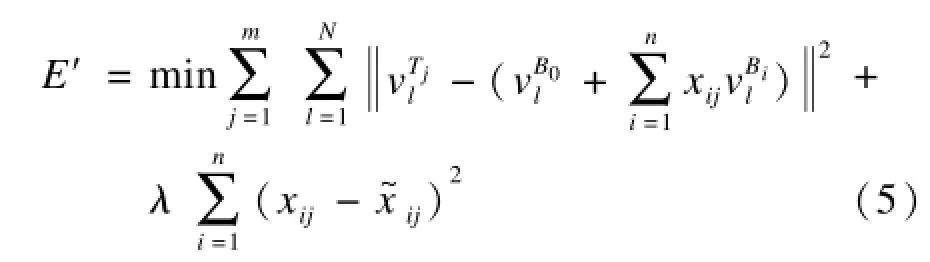
3 实验结果与分析
首先,选用文献[8]中的面部网格作为模板模型S。其次,创建目标模型作为训练表情集合T。模板模型中包括10种基本表情,分别是自然表情、生气、哭泣、暴怒、露齿笑、嘲笑、愤怒、悲伤、微笑、惊讶。
每次设置中,主要控制参数α和λ,便能调整输出最优的blendshape表情基。当α≫1时,输出的blendshape模型接近于直接进行变形传输后产生的结果。在这种情况下,即便λ=0,实验中也观察不到明显的变化。当α接近于0.1时,输出的blendshape有可能组合后逼近训练表情,但其变化可能比α≪0.1时更敏感。所有的实验中,仅使用了10次交替迭代,其中第一次迭代时α=0.5,λ=100。最后一次迭代时权重逐渐减小到α=0.1,λ=10。
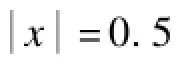
ij增加随机变量x后对模型的影响。

图1 初始混合权重的变化对模型拟合效果的影响
图2显示了参数α对式(4)中E的影响。它有效地控制了通用模型和目标模型之间的映射。当其减小到0.05时出现过拟合现象,在重构blendshape表情基时导致失真。实验发现α=0.1时折中地满足了精度和鲁棒性的要求。
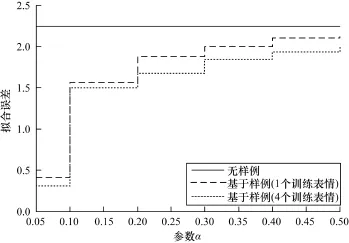
图2 参数α对误差E的影响
本文应用的方法主要针对非标记面部表情动画。实验表明很少的训练表情(4个)便足以精确地表达一个密集的表情空间。如果没有基于样例进行优化,blendshape表情基模型将不具备足够的表现力。
本文与3种具有代表性的方法:基于主成份分析(PCA)的方法[5]、面部表情模拟(Facial Expression Analogy,FEA)方法[6]和非线性协同学习(Nonlinear Co-learning,NCL)方法[7]进行比较。不同表情基生成方法对比如图3所示。从表1可以看出,对于4个训练表情,进行优化的实验大约需要81 s,约等于分别进行blendshape优化、重构和参数优化所用的时间总和。

图3 不同表情基生成方法对比

表1 4种方法消耗时间比较s
本文方法假定训练样例对应有效的表情blendshape组合。例如,使用先验模型无法表达鼓嘴吹气的表情。然而,通过验证E是否超过某一阈值就可以检测出模型中的表情是否丢失。因此,需增加语义不同的表情补充表情基空间。输入其他模型产生的效果如图4所示。目前,算法的交互速率还不够快。算法的复杂度为O(a(m+N)),非线性求解部分的复杂度为O(n3)。
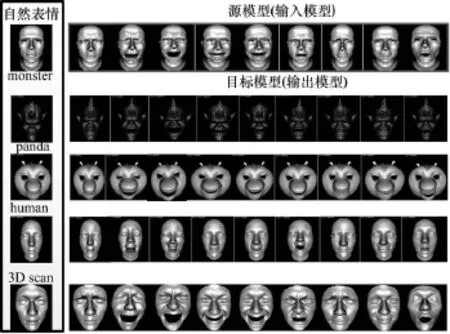
图4 输入其他模型产生的效果
4 结束语
本文从自动生成个性化的blendshape表情基入手,根据样例表情迭代地优化表情基和混合权重,从而达到提高动画师工作效率,甚至让非专业用户也能很快地生成个性化的blendshape模型的目的。相较于单纯依赖手工建模并微调每个blendshape模型的方式,本文方法更方便快捷且具有可扩展性。从实验结果可以看出,本文方法是可行的,真实感高,能够生成高质量、个性化的blendshape模型。下一步工作将尝试如何使用较少的样例实现与更多的表情基自动建立对应关系,同时,进一步提高表情映射的精度。
[1]Lewis J P,Mooser J,Deng Zhigang,et al.Reducing Blendshape Interference by Selected Motion Attenuation[C]//Proceedings of Symposium on Interactive 3D Graphics and Games.Washington D.C.,USA:[s.n.], 2005:25-29.
[2]Blanz V,Vetter T.A Morphable Model for the Synthesis of 3d Faces[C]//Proceedings of the 26th Annual ConferenceonComputerGraphicsandInteractive Techniques.NewYork,USA:ACMPress,1999: 187-194.
[3]Blanz V,Basso C,Poggio T,et al.Reanimating Faces in Images and Video[J].Computer Graphics Forum,2003, 22(3):641-650.
[4]Vlasic D,Brand M,Pfister H,et al.Face Transfer with Multilinear Models[J].ACM Transactions on Graphics, 2005,24(3):426-433.
[5]Weise T,Gool L V,Venue M P,et al.Face/off:Live Facial Puppetry[C]//Proceedings of Symposium on Computer Animation.[S.l.]:ACM Press,2009:7-16.
[6]Song Mingli,Zhao Dong,Theobalt C,et al.A Generic Framework for Efficient 2-D and 3-D Facial Expression Analogy[J].IEEE Transactions on Multimedia,2007, 9(7):1384-1395.
[7]黄晓钦,林裕旭,宋明黎,等.非线性联合学习的三维人脸表情合成方法[J].计算机辅助设计与图形学学报,2011,23(2):363-370.
[8]Sumner R W,Popovic'J.DeformationTransferfor Triangle Meshes[J].ACM Transactions on Graphics, 2004,23(3):399-405.
[9]Liu Xuecheng,Mao Tianlu,Xia Shihong,et al.Facial Animation byOptimizedBlendshapesfromMotion Capture Data[J].Computer Animation and Virtual Worlds,2008,19(3-4):235-245.
[10]Coleman T F,Li Yuying.An Interior Trust Region ApproachforNonlinearMinimizationSubjectto Bounds[J].SIAMJournalonOptimization,1996, 6(2):418-445.
[11]Li Hao,Adams B,Guibas L J,et al.Robust Single-view GeometryandMotionReconstruction[J].ACM Transactions on Graphics,2009,28(5).
[12]马昌凤.最优化方法及其Matlab程序设计[M].北京:科学出版社,2010:166-178.
编辑 顾逸斐
Facial Expression Radical Generation Based on Example
GAO Yali,TAN Guanghua,GUO Songrui,FAN Xiaowei
(College of Information Science and Engineering,Hunan University,Changsha 410082,China)
To solve the problem of blendshapes generation mostly depending on manual modeling and fine-tuning,this paper proposes an automatic generation method about example-based expression blendshapes.Using a set of generic face models as the prior,it makes each generated blendshapes approach to its real semantics.Expression blendshapes generated by this method can map semantics and expression dynamics from the generic model to the target model.The method achieves model’s scalability in application and enables users to gradually calculate more expression models according to their own needs.Experimental results show that the method,constructing a gradient space to optimize blendshapes, outperforms the state-of-the-art methods both in speed and reality.
blendshape expression radical;example-based;iterative optimization;gradient space;reality;facial animation
高娅莉,谭光华,郭松睿,等.基于样例的面部表情基生成[J].计算机工程,2015,41(3):258-261.
英文引用格式:Gao Yali,Tan Guanghua,Guo Songrui,et al.Facial Expression Radical Generation Based on Example[J].Computer Engineering,2015,41(3):258-261.
1000-3428(2015)03-0258-04
:A
:TP391
10.3969/j.issn.1000-3428.2015.03.048
国家科技支撑计划基金资助项目“文化旅游资源挖掘与体验式平台研发与示范”(2014BAK08B00,2014BAK08B01)。
高娅莉(1988-),女,硕士研究生,主研方向:计算机动画,数字图像处理;谭光华,助教、博士;郭松睿,博士研究生;范晓伟,本科生。
2014-04-02
:2014-05-09E-mail:gaoyali2007@163.com
猜你喜欢
心理学探新(2022年1期)2022-06-07
当代陕西(2020年17期)2020-10-28
广东教学报·教育综合(2020年15期)2020-03-23
人大建设(2018年5期)2018-08-16
电信科学(2017年6期)2017-07-01
戏剧之家(2017年7期)2017-05-12
科技与创新(2016年11期)2016-06-28
山东青年(2016年2期)2016-02-28
社会心理科学(2015年6期)2015-02-07
中学教学参考·文综版(2014年1期)2014-03-11
