
射频识别系统多标签防碰撞算法
2015-02-27 00:55张继荣刘亚丽
西安邮电大学学报 2015年6期
张继荣, 江 驰, 刘亚丽
(西安邮电大学 通信与信息工程学院, 陕西 西安 710121)
射频识别系统多标签防碰撞算法
张继荣, 江 驰, 刘亚丽
(西安邮电大学 通信与信息工程学院, 陕西 西安 710121)
为提升射频识别(RFID)系统中单阅读器多标签环境的识别效率,给出一种在标签编码前缀相同条件下使用的混合算法。先通过Q算法调整帧长,使之与待识别标签总数近似相等,以达到最大识别效率,并给未识别的碰撞标签标记分组号,再对已分组的碰撞标签使用反向查询树算法(QTR)一一识别。根据EPCC1G1标准,在单阅读器多标签的系统环境下,选取标签编码长度为96位,分别在标签编码完全随机与标签编码前60位相同两种情况下进行仿真,结果表明在标签编码前缀相同时,较之QT算法、Q算法,混合算法可提高系统吞吐率,降低阅读器发送总时隙数。
多标签防碰撞;混合算法;反向查询树;吞吐率
射频识别技术(radio frequency identification, RFID)是一种非接触式的识别技术,也被称为电子标签技术[1]。RFID系统包括识别目标对象的阅读器以及附着在识别对象上的电子标签。
当多个标签在同一时间向阅读器发送数据时,信号在阅读器接收端发生干扰,引起数据的碰撞(collison),这样就会导致标签识别和数据传送失败[2]。协调标签和阅读器之间的通信,建立能够准确识别多个标签的防碰撞算法是RFID系统付诸于应用的关键技术。
防碰撞算法可以被分为两大类:基于Aloha协议的概率性防碰撞算法和基于树协议的确定性防碰撞算法。概率性算法有纯Aloha算法,时隙Aloha算法、帧时隙Aloha算法(FSA)和动态帧时隙Aloha算法(DFSA)等[3-5]。确定性算法有查询树算法(QT)、二叉树搜索(BT)和二进制搜索算法(BS)等[4-5]。
在实际应用中,概率性算法会出现“标签饥饿”问题,即标签的相互碰撞可能导致某个标签永远无法被识别,确定性算法虽然能够准确识别出每一个标签,但当待识别标签过多时会造成识别时间较长。
在EPC C1G2标准[6]中使用Q算法(Adaptive Slot-Count(Q) algorithm)[7]作为防碰撞算法,该算法通过参数Q及调整步长C来自适应地调整帧长以达到最优,但该算法对于碰撞的解决机制不够完好,频繁的调整Q值也增加了系统的通信时间,并且因为属于概率性算法也会出现“标签饥饿”的问题。
反向查询树算法(QTR)是对查询树算法(QT)的变型[8],此算法使用阅读器广播查询前缀,标签判断查询前缀和自身标签码的匹配与否来选择是否发送自己的数据。QTR算法属于确定性算法实现简单,可以排除“标签饥饿”现象,但当标签数量过大时,阅读器向标签的发送查询前缀的次数过多,会造成树的深度过大,这样就延长了识别时间,使得系统效率无法稳定维持在较高水平。
本文针对Q算法中Q值改变过多且存在“标签饥饿”的现象,和QTR算法在识别大量标签时效率低下的问题,将Q算法进行变型并融合QTR算法提出一种混合算法,即增强型反向查询树算法(Enhanced Query tree with Reversed IDs by fast grouping, EQR),通过设置边界条件降低Q值改变次数,引入QTR算法识别碰撞标签,并使用快速分组的方法将碰撞标签分组,以提高系统效率。
1 增强型反向查询树算法
EPC码是由标头、厂商识别码、对象分类码以及序列号所组成[9-10],当厂商申请使用EPC编码时会获得全球唯一的厂商识别码,而对于同类型产品,也具有同样的对象分类码,因此,同一厂商物流供应链上的同类型产品EPC编码的前缀是相同的。EQR算法仅在编码前缀相同环境下使用。
1.1 最佳帧长的判断
假设一帧有L个时隙,n个待识别标签。标签在各时隙相互对立地发送数据,即各时隙得到标签的概率相等,故m个标签在某时隙内发送碰撞的概率pm满足二项分布[11],即
m个标签在某时隙内发送数据的数学期望为
在某时隙有且只有一个标签被成功识别的期望是
定义RFID系统的效率公式为
当标签数为n时,为使效率最高,应使
由此可以推知,当标签数与时隙数相同时,系统效率最高。
1.2 边界条件的设定
要使得时隙数L近似等于待识别标签数n,碰撞时隙数Nc,空闲时隙数Ne和识别时隙数Ni应该满足[12]
通过三种时隙的数量对比,判断时隙数L和待识别标签n之间的关系。当L与n相等时,应有
从而可得边界条件
为避免频繁调整Q值,当边界条件得到满足时,算法不再进行帧长调整,而是直接转入碰撞标签识别。
1.3 快速分组的实现
各标签随机地从区域(0,2Q-1)内选择一个随机数,作为自身发送数据所选择的时隙号。使用计数器备份此随机数,作为该标签的分组号。当阅读器侦测到碰撞发生,即有多个标签选择了同一时隙号,此时应将所备份的分组号存入阅读器存储分组号的栈内,留待下一阶段使用,由此可将发生碰撞的标签分成若干组。各标签随机选择时隙数,选择相同的标签可通过分组的方式被离散开来,所以,算法效率相对稳定。
1.4 算法流程
EQR算法中,标签有两个计数器C1和C2,阅读器中有计数器Cq,存储分组号的栈S1和存储查询前缀的栈S2。
算法流程如图1所示。
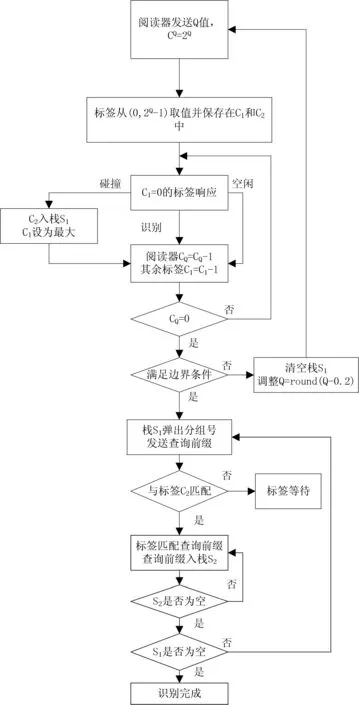
图1 EQR算法流程
EQR算法的具体步骤可描述如下。
步骤1阅读器发送初始化Q值给标签,并在Cq中保存这个值。
步骤2标签随机地从(0,2Q-1)中选择一个值,并且保存于C1和C2中。
步骤3阅读器发送查询命令,C1=0的标签响应。若没有响应则为空闲时隙;若有多个标签响应则为碰撞时隙,将碰撞标签计数器C1值设为最大2Q,C2值不变且入栈做为第二阶段的查询碰撞标签的分组号;若只有一个标签响应,则为成功识别并将该标签标记为已识别状态不再响应查询。
步骤4阅读器Cq减1,未响应标签C1减1。
步骤5判断Cq是否为零,若为零,则一帧结束。判断这一帧中空闲、碰撞、识别时隙的比例关系,若满足边界条件,则清空栈,重新调整
Q= round (Q-0.2),
转到步骤1;若不满足边界条件,则进入下一阶段,即使用QTR算法识别碰撞标签,此时所有标签初始选择的时隙数值保存在标签自己的C2中作为第二阶段的分组号,栈S1中存储了所有的分组号。
步骤6从栈S1中弹出分组号并发送查询前缀给所有标签。
步骤7标签中C2值等于S1弹出的分组号的标签进行响应,使用QTR算法将自身标签码与查询前缀匹配并将查询前缀压入栈S2。
步骤8判断匹配前缀栈S2是否为空,若不为空则返回步骤6。
步骤9判断栈S1是否为空,若不为空则返回步骤6;若为空则表示所有碰撞标签被成功识别。
2 性能分析与仿真
衡量RFID系统防碰撞算法性能的指标有两个,即吞吐率和系统时间复杂度[13]。吞吐率定义为待识别标签总数和总时隙数的比值;系统时间复杂度即识别过程所需总时隙数。
2.1 算法性能分析
对于Q算法,根据二项分布,同一时隙只有一个标签的概率
每帧内可识别的标签数
故Q算法的吞吐率为
当L=n时,求得吞吐率的最大值
若N≥25,则
ηQ,max≤0.375,
故总时隙数
对于QT算法,根据查询前缀与标签码的碰撞位后一位进行0和1的分组,当待识别标签总数n≫2时,吞吐率可近似为[14]
当n≥25时,则
ηQT≤0.41,
故总时隙数近似为
对于EQR算法,根据边界条件要求,若成立比例关系
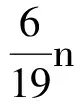
据此,当N≥25时,有
η≤0.513,
总时隙数近似为
2.2 算法仿真
参照EPCC1G2标准,针对多标签单阅读器识别系统,标签数量从0到500,标签编码长度为96位,分别在标签编码完全随机与标签编码前缀60位相同这两种情况下进行仿真比较,结果如图2和图3所示。
由图2可见,当标签编码前缀相同时,EQR算法显著的提高了吞吐率。由于采用了标签分组策略,解决碰撞标签时的吞吐率始终保持在一个较高水平。
阅读所发送的总时隙数可以反应出该系统时间复杂度。由图3可见,在标签编码前缀相同这个特定的应用环境下,EQR算法要明显优于Q算法及QT算法,发送的通信总时隙数要小于后两种,这说明EQR算法可缩短标签识别时间,提高系统识别效率。
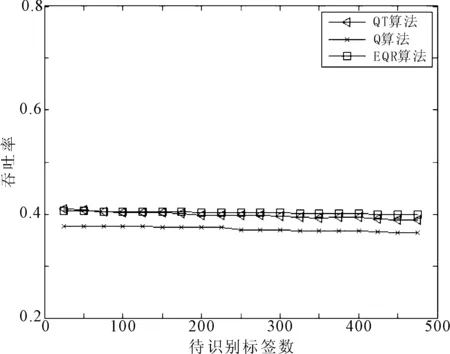
(a) 编码随机
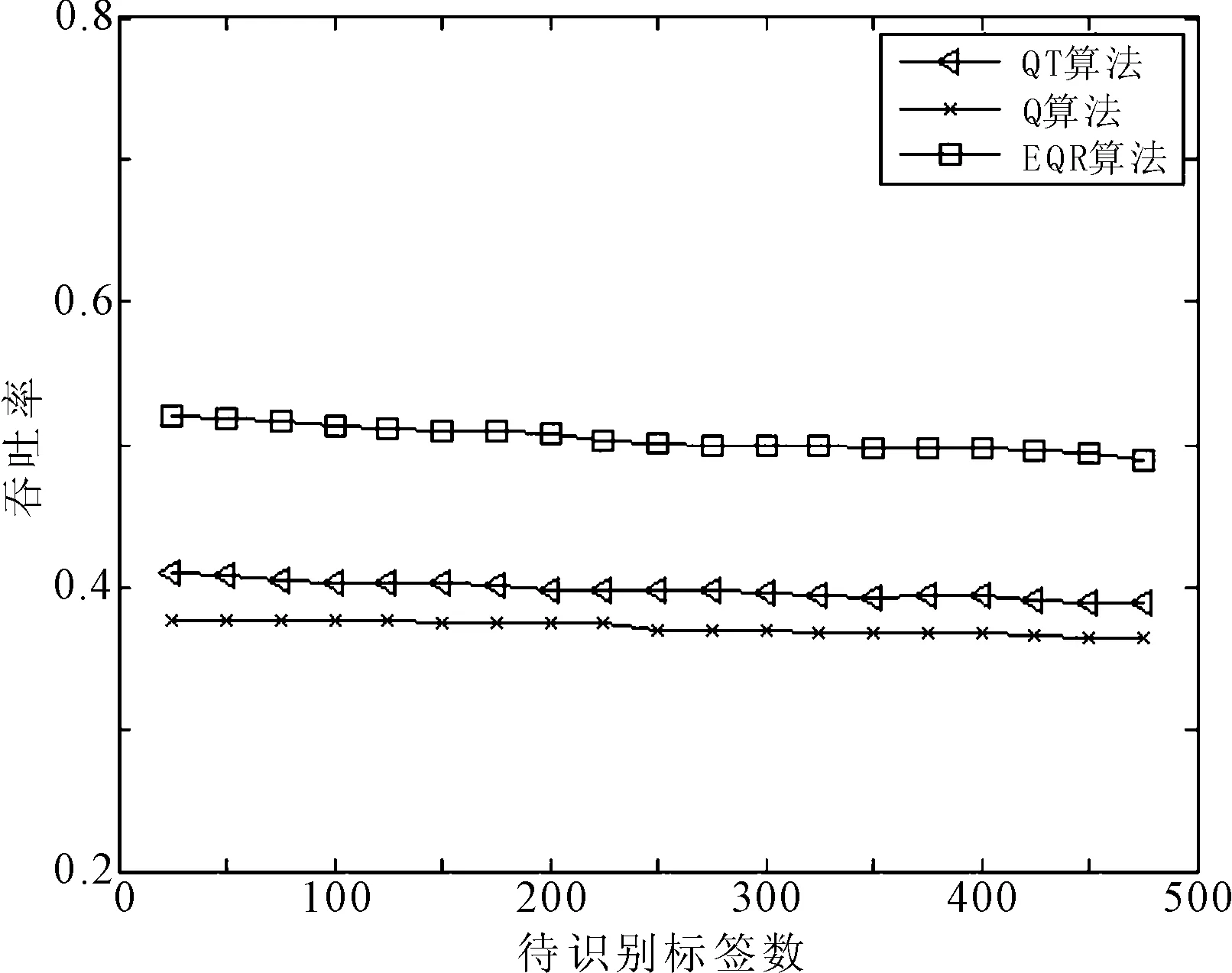
(b) 编码前缀相同
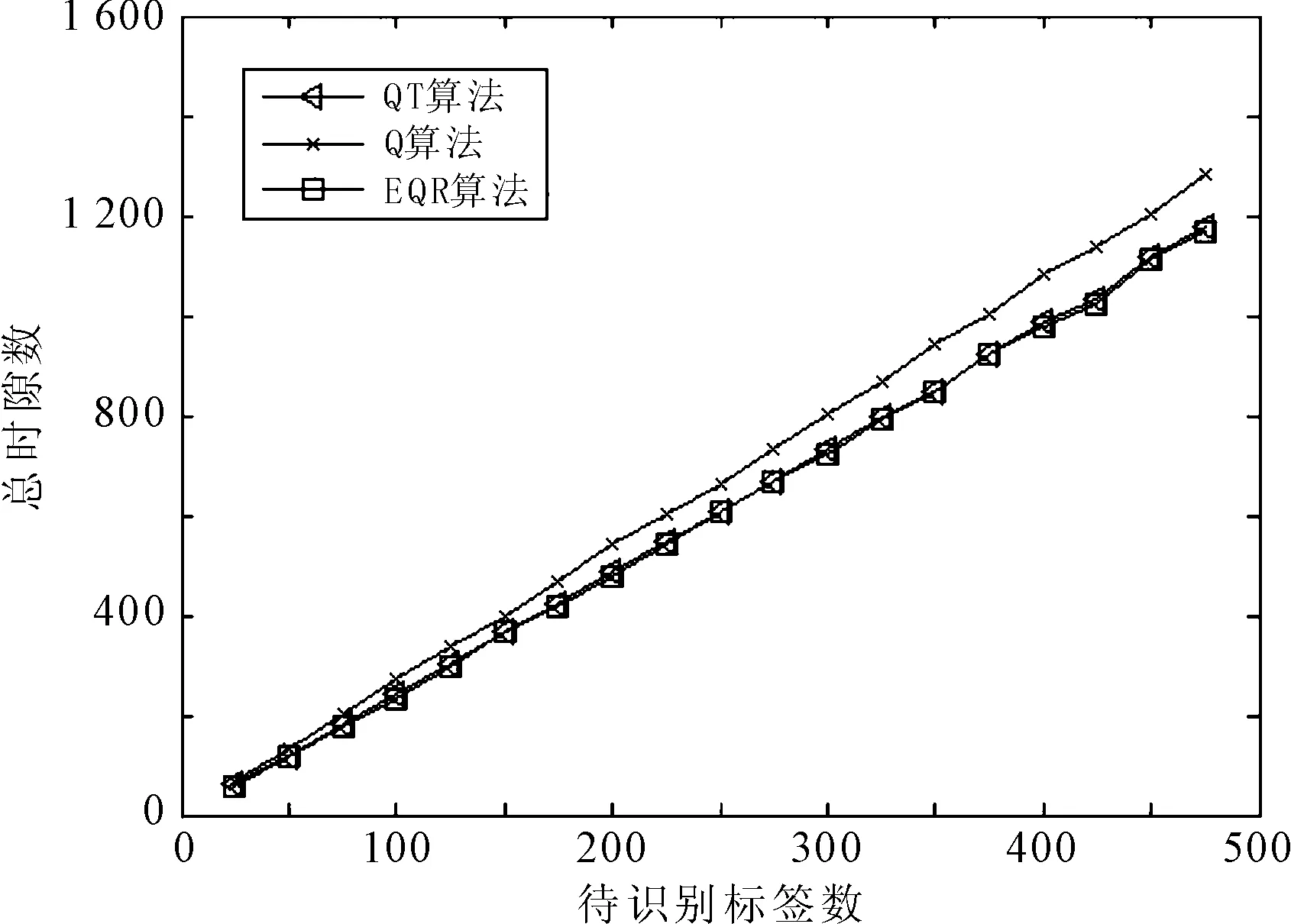
(a) 编码随机
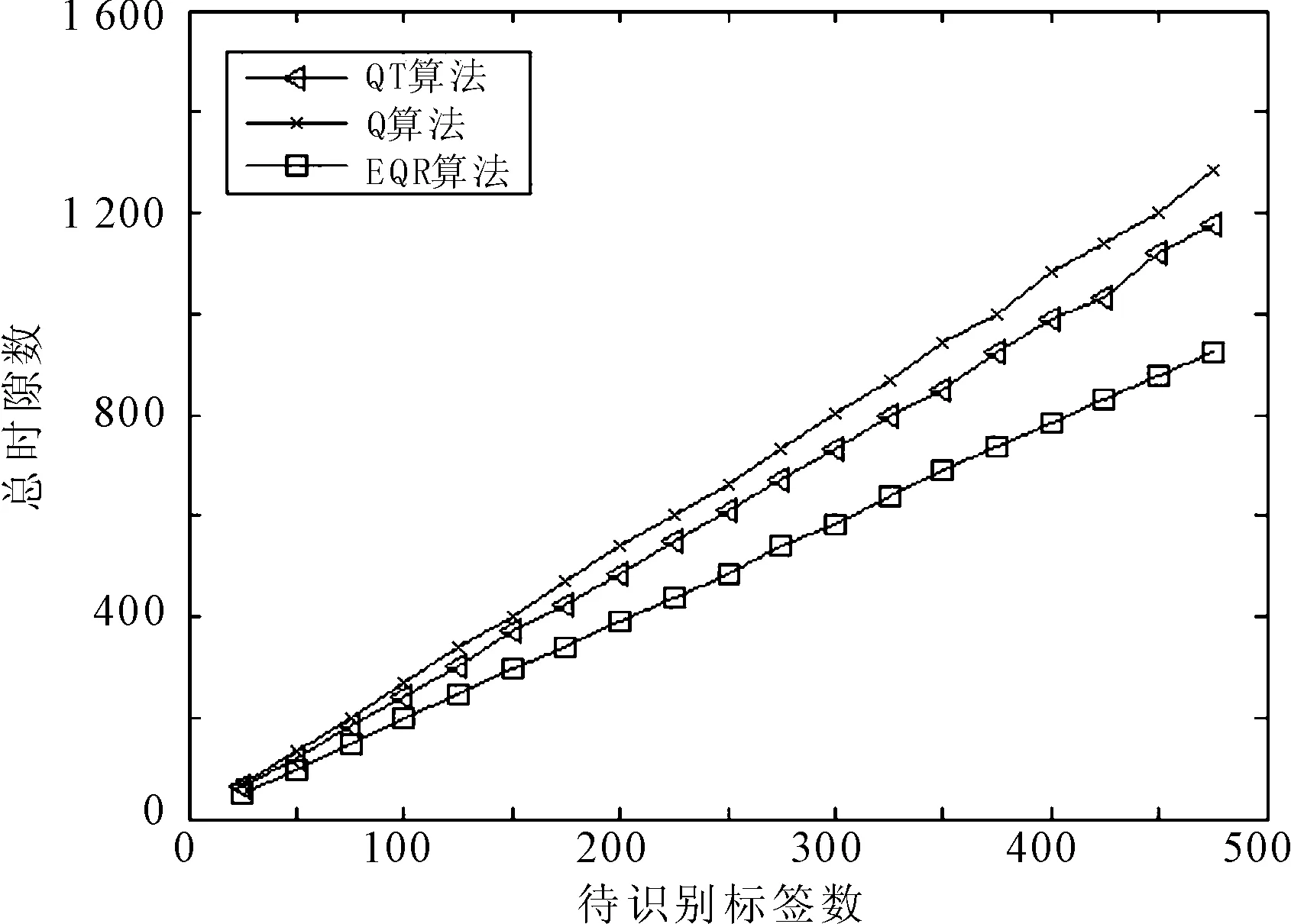
(b) 编码前缀相同
3 结束语
EQR算法使用设定边界条件和融合QTR算法的方法,能克服Q算法“标签饥饿”和帧长调整频繁的问题,使用快速分组的策略可弥补QTR算法在识别大量标签时效率较低的缺点。仿真验证表明,EQR算法可提高系统吞吐率,降低通信总时隙数。
[1]AtzoriL,IeraA,GiacomoM.Intheinternetofthings:asurver[J].ComputerNetworks, 2010,54(3):2785-2885.
[2]MobahatH.AuthenticationandlighrweigthcyptographyinlowcostRFID[C]//The2ndInternationalConferenceonSoftwareTechnologyandEngineer.SanJuan:IEEE,2010:123-129.
[3]VogtH.EfficientobjectidentificationwithpassiveRFIDtags[C]//ProceedingsofIEEEInternationalConferenceonPervasiveComputing.Zurich:Springer-Verlag, 2002:98-113.
[4]MyungJ,LeeW,SrivastavaJ,etal.Tag-splitting:adaptivecollisionprotocolsforRFIDtagidentification[J].IEEETransactionsonParallelandDistribbutedSystems, 2007,18(6):763-775.
[5] 周晓光.射频识别技术原理与应用实例[M].北京:人民邮电出版社,2006:134-138.
[6] 中国物联网.详解全球三大RFID产业标准体系对比分析[EB/OL].(2010-10-28)[2014-12-19].Http://info.secu.hc360.com/2010/10/281356403021.html.
[7]LeeS,JooSD,LEECW.AnenhanceddynamicframedslottedalohaalogrithmforRFIDtagidentification[C]//Proceedingsofmobiquitous.Orlando:IEEE,2005:166-172.
[8]ChoJ,ShinJD,KimSK.RFIDtaganti-collisionprotocol:querytreewithreversedIDs[C]//InternationalConferenceonAdvancedCommunicationTechnology,KoreaSeoul:IEEE,2008:225-230.
[9] 黄玉兰.射频识别(RFID)核心技术详解[M].北京:人民邮电出版社,2012:370.
[10] 宋红波,答军.一种半有源射频识别标签设计[J].西安邮电大学学报,2014,19(4):90-93.
[11]ZhangYan,YangLT,ChenJiming.RFID与传感器网络:架构、协议、安全与集成[M].谢志军,译.北京:机械工业出版社,2012:87-95.
[12]JiaXiaolin,FengQuanyuan.Aniprovedanti-collsionprotocolforradiofrequencyidentificationtag[J].InternationalJournalofCommunicationSystems,2013,8(6):78-81.
[13]LaPoratT,MaseliG,PetrioliC.Anti-collsionprotocolsforsingle-readerRFIDsystems:temporalanalysisandoptimization[J].IEEETransactionsonMobileComputing,2011,10(2):201-203.
[14]HushDR,WoodC.AnalysisoftreealgorithmsforRFIDarbitration[C]//ProceedingsofIEEESymposiumonInformationTheory,USAMACambridge:IEEE,1998:107-116.
[责任编辑:瑞金]
《西安邮电大学学报》版权声明
为适应我国信息化建设的需要,扩大刊物影响,拓宽信息交流渠道,本刊已加入“中国知网CNKI系列期刊数据库”、“中国核心期刊(遴选)数据库”(万方数据——数字化期刊群)、“中国期刊网”等数据库。本刊已许可以上数据库以数字化方式复制、汇编、发行、信息网络传播本刊所载文章的全文信息。稿件一经刊登,将在本刊稿酬中一次性支付著作权使用报酬(包括印刷版、光盘版和网络版等各种使用方式的报酬)。作者向本刊提交文章的行为即视为同意我刊上述声明。
西安邮电大学学报编辑部
Multi-tags anti-colision algorithms in RFID system
ZHANG Jirong, JIANG Chi, LIU Yali
(School of Communication and Information Engineering, Xi’an University of Posts and Telecommunication, Xi’an 710121, China)
In order to improve the effciency of single reader under multi-tags RFID system, a hybrid algorithm is proposed to use in a particular condition which tags number have the same prefix. In the first step of this algorithm, the Adaptive Slot-Count (Q) algorithm is used to adjust the frame size to approach the number of tags to achieve maximum efficiency and divide the collision tags into group. In the second step, the Query Tree with Reversed IDs (QTR) is used to identify collision tags grouop by group. According to EPC C1G1 Standrad, in the single reader and mulit-tags system enviroment, simulation is carried out with the size of tag number of 96 in two cases: complete random and same prefix of tag number. Result show when the tags number has a same prefix, compared to QT and Q algorithm, the hybrid algorithm could improve the throught rate and reduce the number of slots.
multi-tags anti-colision, hybrid algorithm, query tree with reversed IDs, throught rate
2014-12-16
张继荣(1963-),女,博士,教授,从事现代通信网研究。E-mail:comnet@xupt.edu.cn江驰(1990-),男,硕士研究生,研究方向为现代通信网。E-mail:108182061@qq.com
10.13682/j.issn.2095-6533.2015.06.007
TN92
A
2095-6533(2015)06-0028-05
猜你喜欢
电子设计工程(2022年15期)2022-08-17
应用数学(2020年4期)2020-12-28
数学物理学报(2020年5期)2020-11-26
英语世界(2020年10期)2020-11-06
数学年刊A辑(中文版)(2020年3期)2020-10-27
舰船电子对抗(2020年2期)2020-06-23
英语世界(2020年2期)2020-03-08
经济研究导刊(2018年26期)2018-11-14
铁道通信信号(2018年9期)2018-11-10
作文通讯·高中版(2017年6期)2017-07-10
