
文本流多粒度主题结构建模研究
2015-04-25 09:56王素格
中文信息学报 2015年1期
陈 千,郭 鑫,王素格,张 虎
(山西大学 计算机与信息技术学院,山西 太原 030006)
文本流多粒度主题结构建模研究
陈 千,郭 鑫,王素格,张 虎
(山西大学 计算机与信息技术学院,山西 太原 030006)
主题检测近年来在文本挖掘和自然语言处理领域得到了广泛的应用,对主题进行结构建模是主题检测的基础。为了对文本流中的多粒度主题进行建模,提出一种基于语义层次树的主题结构模型。该模型利用领域本体的特点,将主题同本体作一一映射,结合概率理论,将概念集里的概念用主题树的叶子节点表示,每一层中的节点均是下一层节点的多项分布,使之更适合描述文本流中多粒度的主题结构。为了便于构建主题的空间结构,提出主题的相似度和事件相关度计算方法。该文结尾设计了实验构造真实新闻文本流数据上的主题树。实验结果表明,该结构模型能够体现主题丰富的多粒度空间语义特征。
主题检测;多粒度主题建模;文本流
1 引言
随着计算机技术和互联网技术的飞速发展,大数据和流数据的普遍存在,利用计算机对海量文本数据进行自动主题检测在舆情监测、邮件档案整理、情报科学分类和Web日志访问挖掘[1]等领域有着广泛的应用前景。主题检测的主要任务是对主题进行识别,对主题进行结构化建模是主题检测的基础工作,包括主题的定义、描述以及结构设计。随着主题的抽象程度不同,主题宏观上体现了一定的层次粒度性,因此如何对主题进行层次粒度建模,是难点之一;文本流中的主题并不是相互独立的,可能存在相互关系,如何表达这种相互关系是主题建模难点之二。由于主题检测需要识别出与某个主题相关的事件,因此,主题建模涉及到多个对象,包括事件等,它体现了主题的时间特性,具有一定的多元性。因此,这些问题给主题建模带来诸多挑战。
目前国内外对主题还尚未有统一的定义。一般来说,话题检测和跟踪国际会议(Topic Detection and Tracking,TDT)将主题定义为一个核心事件或活动以及与之直接相关的事件或活动[2]。近年来,采用概率统计学对主题进行建模诞生了概率主题模型,该模型假设存在这样一种隐含变量,该变量用于表示和被观测文本文档相联系的主题,且该变量和单词的使用模式具有某种关系。Blei 提出的潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)模型[3]未考虑主题的层次性问题和相关性问题。Wei Li等人提出了一种有向无环图结构的弹球分配模型[4](Pachinko allocation model,PAM)来表达主题间的相关性,但未涉及到主题的时间特征。Berendt提出一种基于单边路径聚类的方法进行主题检测[5],没有考虑到主题的粒度问题。权小军等人提出一种基于概率主题模型的层次文本分类方法[6],但主要面向分类问题。陈千[7]等人提出一种文本流层次主题检测技术,但文中讨论不够细节,本文是对文献[7]中提到的主题树展开深入探讨。
本文首先介绍多粒度主题的研究背景,然后提出一种基于语义层次本体树的主题结构模型。为了进行推理,本文将主题树同概率论结合,将概念集里的概念用主题树的叶子节点表示,本体树每一层中的节点均是下一层节点的多项分布,使之更适应于描述文本流中真实的多粒度主题结构。实验表明该结构模型能够体现主题丰富的多粒度语义特征。
2 文本流多粒度主题结构建模
2.1 多粒度主题
本文将文本流看成是一系列具有动态性、周期性、潜在无限性、以时间先后顺序连续到达的文本数据记录。这些文本流中蕴含着多个主题,我们认为主题是概念空间中一系列概念按照某种规律组合在一起的集合,文本流是主题的载体。同时,主题又是一个个事件的载体,即事件可以被看成是一个或多个主题的实例。从抽象的程度角度看,主题具有多粒度特征,其中事件是一种特殊的主题,其抽象程度最低。
正如现实世界中一样,“球类运动”这一主题可以具体为“羽毛球运动”和“篮球运动”等,文本流中所讨论的主题同样具有一定大小的粒度。例如,报道奥运会的新闻和奥运会“游泳比赛”的新闻,这两个主题就具有简单的多粒度父子层级关系。经典的主题模型将所有主题都看成扁平结构的,这很大程度上忽视了文本流中主题的这种层次语义结构,因此对文本流中的多粒度主题检测具有广泛的现实应用背景。本文主要关注文本流中主题的多粒度结构建模问题。
2.2 主题结构建模与本体
一般来讲,本体可以表示为一个五元组集合:O={C,R,P,I,A},其中C表示概念集合;R表示概念之间关系的集合;P表示概念的属性集合,包括属性所属的概念,属性名以及属性值;I表示概念相关的实例集合;A表示本体中的公理集。借鉴本体的五元组理论,针对主题的结构模式进行深入研究,提出一种主题层次结构模型,研究对象同本体以及主题所涉及到的研究领域对应关系如图1所示。
模型利用领域本体的特点,将主题同本体作一一映射,即主题对应概念、主题属性对应概念的属性、事件对应实例、主题层次关系对应概念间关系。这四个核心概念分别对应着文本流主题检测框架的四个主要研究任务,本文主要侧重于主题结构建模研究。
2.3 基本概念
定义1 概念表(Concept List)。概念表是某个特定类型语料库的本体概念集按照索引进行顺序标识所构成的概念列表。
概念表中的所有概念均来自领域本体中的概念,它们是一一对应的。一个概念表构成了一个概念空间,以后提到概念空间,若未做特殊说明,均表示由概念表构成的空间。假设概念表中包含概念的个数为V,则概念表CL可以表示为CL={t1,t2,...,tv,...,tV},其中tv是概念表中索引位置为v的概念词汇。

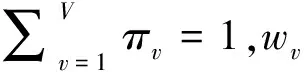

图1 多粒度主题建模涉及到的研究对象
事件主要描述的是在某个时间、某个地点涉及到某些对象(包括某人或物)发生的某个动作行为或一系列动作行为的总称,它是一个或多个主题的实例,即主题的具体实现。因此事件由两个部分构成,其一是包含具体时间、地点、 人物、 动作的元数据集合,其二是概念表上的概率分布。若事件E发生的时间是time,地点是location,参与的对象是object,行为是action,则E可表示为E=[Em,Ed],其中Em表示事件的元数据metadata信息,且Ed表示事件的概念空间上的概率分布信息,则有式(2)。

我们将事件看成是一个或多个主题的实例。事件中的元数据信息均同领域本体中的概念进行匹配。另外,事件主要针对新闻、博客类型的文本流,对于科技文献而言,意义不是很大,因为科技文献主要探讨各种科学技术理论以及应用。一个事件可以属于一个或多个主题,这在真实世界中非常常见,例如,“日本2011.3.11大地震”是主题“地震”的一个实例,同时也是主题“日本”的一个实例。需要注意的是,有时候事件和主题的界限很模糊,即对于某个事件,它也可以被看成是一个主题。事件与主题之间的关系是多对多关系,为了便于分析,假设任何一个主题可对应多个事件,且不同主题对应的事件集合之间是不相容的。
定义2 主题属性。主题属性是与领域相关的,表示主题某种统计特征的对象,它具有属性名和属性值。设属性名为Pname,主题属性函数用TPname(.)表示,它是一个值函数,TPname:N,T→R,其中N表示时间索引上的正整数空间,R是实数集,T表示主题空间。主题属性值也可以归一化,从而使得属性值在0和1之间。主题属性值与主题和时间有关,涉及到主题的演化模式。虽然主题属性概念是主题结构的组成部分,但基于主题属性的生命周期等演化模式亦不在本文的讨论范畴。
主题是本文最核心的研究对象。首先,主题之间具有层次性特点,每个主题可能有若干个子主题或者一个父主题,从而构建出主题的树状结构,且与主题相关的主题属性和事件这三个核心对象之间还存在空间结构关系,这是结构层面。其次从时间层面讨论演化问题,它体现了主题在时间上的特征: (1)一个主题对应多个事件实例,文本流事件集合中的事件之间在时间上还存在某种潜在的转移规律,从而体现了主题的演化特性;(2)主题具有特征属性,对于不同的文本流,主题可能具有不同的主题属性,且每个主题均具有若干属性,这种属性是一种与主题相关的属性,主题不同,其属性对应的属性值不同,而且随着时间的推移其属性值相应发生变化,从而从侧面体现了主题的周期特性。
因此总的来说,主题具有两个方面的潜在语义模式: 演化模式(与时间相关的)和结构模式(与空间相关的),本文主要关注于后者。本小节结合本体论,提出一种主题树模型,该模型包含三个核心对象,以及三个对象之间的内在关系。接下来给出主题树结构模型的相关定义和描述。

同本体类似,主题树也是一个五元组集合,其中,主题对应于本体中的概念,主题层次关系对应于本体中的关系。根据主题是否是最上层或最下层,主题分为根主题、叶子主题和中间主题。根据主题的父子层关系又分为父主题和子主题。例如,一个四层结构的主题树,包括文档层、根主题层、叶子主题层、概念层。文档层只有一个根节点,根主题层是一系列根主题节点,即对于每一篇文档而言,可以看成是根主题按照一定比例的混合,因此,一篇文档可以用在根主题空间上的多项分布来表示;叶子主题层由一系列叶子主题构成,依此类推,每一个根主题可以表示成叶子主题上的多项分布,因此每一个根主题是叶子主题层中所有的节点按照一定比例的混合。所有的叶子主题均是概念层中所有概念上的多项分布。叶子主题层是最为关键的一层,只有该层节点才能具有事件实例。
主题树的根结点为文本流,我们对主题树做了进一步限制,假设主题树中的节点有明显的层数,即任意两个不相邻层节点是不允许有链接的,使得主题树具有明显的层次关系。对于主题树中的主题,它可以用概念空间上的多项分布来表示,由于概念空间的维度一般很大,在实验中为了便于展示,一般选取Top k个关键的概念来代表该主题。由于概念完全来自于领域本体中的概念集合,为了体现语义的特点,利用本体论中的概念扩展,将一定范围内与该主题的概念相关的概念进行相似度和概念方法匹配,匹配的方法是基于领域本体中概念之间的关系,得到匹配程度较高的若干概念,并将它们一起加入到主题树的主题概念中,实现了语义扩展,从而在一定程度上增强了主题的语义表达能力。
需要注意的是,主题树可以在根主题层和叶子主题层加入任意多层中间主题,其中每个父主题层中的任意节点是相邻下一层的子主题上的多项分布。由于从Dirichlet分布抽样得到的样本是多项分布,因此从根主题层到叶子主题层,每一层逐层都可以用一个Dirichlet分布来表示,其中每一个父节点均是该Dirichlet分布的一个样本。事实上,用有向无环图来描述该主题树结构更为确切,这里所谓的方向一般是从高层次节点到低层次节点。其次,为了便于推理,假设主题树中的节点有明显的层数。根据上面的定义,一个主题是在概念词汇表上的一种多项分布,同时也可以看成是V维概念词汇空间中的一个向量,有利于进行主题结构模型的推理。
3 基于主题树的推理研究
本节主要给出主题树基础上的主题推理方法,主要包括主题层次推理、主题相似度计算和事件转移度计算,它们构成了主题树构建和推理的过程。其中,主题层次推理能将任何层次上的主题表示成概念空间上的多项分布,它和上一小节给出的主题树结构模型是密不可分的,共同构成了多粒度主题模型。
3.1 主题层次推理
主题可表示成行向量,即V维概念空间中处于单型区域的点,根据主题树的定义,只有叶子节点才能表示成概念集上的多项分布,因此需要将主题树中上层节点主题转换成概念空间上的多项分布。本小节主要讨论给定主题树中层与层间的多项分布关系,如何将任意给定主题映射到概念空间上,即主题的层次推理。由于主题树是针对某个具体的文本流而言的,也即一个文本流对应一个主题树结构,我们对该文本流构建领域本体,概念表则由所有的本体概念构成。

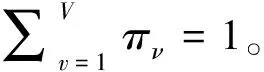
定义5 主题层矩阵(Topic Lever Matrix,TLM)。若主题树的第i层主题个数为Ni,其下一层子主题个数为Ni+1,i层主题层中的所有主题都可以用下一层主题的多项分布表示或向量表示,从而i层主题层中的所有主题构成了一个Ni×Ni+1矩阵,我们称之为主题层矩阵,表示为式(5)。
其中第j个行向量[ρj1,ρj2,...,ρjNi+1]表示第i层主题层的第j个主题在其子主题空间上的权重分配情况,则我们有引理1。

证明: 将MC写成列向量形式,列向量中的每一个元素看成是一个行向量。拆开分析得式(7)。
因父主题是各个子主题的比例混合,因此有式(8)。

从上述引理1可知,任何一个主题均可以表示成该主题在其子主题层的多项分布向量与主题层矩阵的乘积。下面的定理告诉我们如何用概念空间的一个向量来表示任意层主题。若从下往上数,叶子主题层被称为第一层,则叶子主题的父主题层被称为第二层,依此类推。
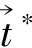
其中M的右下标为该矩阵的大小。
证明: 采用数学归纳法证明。
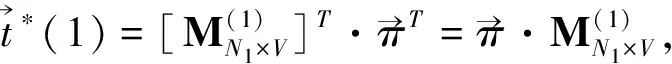
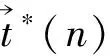
则根据引理1,第n+ 1层某个主题为
对于任意n,均成立,因此,命题得证□
从定理1可知,我们将所有的主题全部映射到概念空间,即任意层主题都可表示成V维向量空间中的向量,很容易证明向量的元素之和为1。则每个主题均可表示成概念集合上的多项分布,即概念集合的线性组合。这在语义上很容易解释,更容易在计算机上进行推理和计算,主题的层次关系则用主题树来刻画。
需要注意,主题树中的概念表是语料库相关的,本文拟采用自动抽取方法对语料库进行概念表的自动构建。构建质量的好坏对主题检测以及主题演化任务的结果有着直接的影响。一般来说,对语料库首先采用分词,然后进行去停用词操作。根据停用词表中去除各种常见的停用词,剩下的一些词语基本构成了概念表中的主要概念,为了确保质量,有时候需要领域专家参与决策。
本小节同主题树中的主题一起构成了本文提出的基于主题树的主题语义描述方法。下面将针对另外两个推理任务进行研究,包括主题的相似度计算和主题事件的转移度计算。而这两个计算方法构成了图1显示的文本流主题检测框架中3大研究任务的基础。
3.2 主题相似度计算
主题相似度计算对于主题树的层次结构具有一定的指导作用,主要探究主题与主题之间的潜在空间语义关系。由于主题是采用分布来表示的,为了计算主题之间的相似度,传统方法采用KL散度。主题p到q的相似度度量方法如式(10)所示。
另外一种做法是通过计算向量的夹角余弦得到两个主题的相似度。前者是非对称的度量,从主题Tp到Tq的度量并不等于从主题Tq到Tp的度量。文献[7]采用对称的测度sym-KL如式(11)所示。
当构造好一棵主题树,也可以根据树节点之间的最短路径距离结合之前的相似度结果进行加权求和来计算主题的最终相似度,我们称之为sim散度,其计算公式为式(12)。
其中shortest(p,q)表示两个节点之间的最短路径长度,all(T)表示两个节点的所有出入度总和。
3.3 事件转移度计算
事件转移度计算用于进行基于事件的时间演化模式推理,它主要研究两个事件之间的潜在时间语义关系。
定义8: 事件转移度(event transition)。事件转移描述的是从一个事件到另一个事件之间的因果依赖程度或相关性,也即,起始事件导致后续事件发生的原因程度大小。采用条件概率ET(estart,eend)=p(eend|estart)来表示,其中ET(estart,eend)∈[0,1]。
事件转移度可以看成一个二元函数,描述的是始发事件引起后续事件的成因大小,由于时间的不可逆性,事件转移度也是不可逆的。另外结合事件的时间、人物、对象等元数据信息和事件的多项分布,则事件et1(loc1,obj1,p)到事件et2(loc2,obj2,q)的转移度ET(et1,et2)如式(13)所示。
其中,dice(X,Y)为戴斯函数,如式(14)所示。
事件转移度一般用来描述起始事件到后续事件的转移程度,即起始事件引起后续事件发生的程度大小。
主题相似度计算和事件转移度计算分别揭示了文本流中主题的潜在空间结构特征和潜在时间演化特征,是文本流中主题检测和演化研究的基础。
4 实验设计与结果分析
4.1 数据集准备
本小节对主题树结构模型在真实新闻文本流数据上进行实验验证。为了获得真实的新闻报道数据集,采用开源网络爬虫工具Heritrix 1.14.0,自行设计的抽取器和过滤器从雅虎英语官方网址中抽取新闻报道。通过该工具获得26 578篇有效的页面文档,时间跨度从2011年三月份到2011年五月份。实验语料库所包含的主要主题事件如表1所示。将雅虎门户网站主题分类浏览的类别信息作为评测的基准,考虑多粒度主题的层次性问题,结合专家人工分类和整理的方法,结合以上两种方式得到主题和事件的baseline,同该基准对比用于评测计算方法的准确性。

表1 实验语料包含的叶子主题事件
4.2 实验设计
本实验主要目的是通过实例说明并验证主题树相比较于已有的主题层次模型能表达更丰富的语义结构和概念。在验证结构之前,实验对提出的基于sim散度的相似度计算方法跟已有的KL散度等计算方法进行对比,从而评测各种计算方法的准确性。采用F-score指标来评测主题相似度计算方法的准确度。其中,F-score综合了precision和recall,用来评测模型或计算方法的性能。由于新闻语料的precision比recall更重要一些,设λ=0.6。如式(15)所示。
为了验证和构建这样一个主题树结构,需要抽取事件、主题,并通过计算主题之间的相似度来构建这些对象之间的关联。本实验采用Thomas Hofmann的概率潜在语义分析pLSA模型[8]对概念和主题进行抽取。为更好地获取文本流事件,根据文本流新闻的规范化结构,提取了新闻中的元数据,包括新闻时间、主要关键字,对于难以提取的地点和人物对象等元数据,我们采用与领域本体中的概念相匹配的方法,因此能较好地捕获地点、人物和对象等元数据信息。
为了模拟真实的文本流环境,采用Heritrix从网络上抓取和抽取过滤文件,按5天的时间跨度来分批次执行pLSA。同时,在每个时间块上进一步执行pLSA算法,最后得到两层主题层次结构,我们将抽取的主题进行主题相似度计算,从而构造出各个主题之间的相似度链接。当相似度达到某个阈值,将该链接加入到主题树中。
4.3 结果分析
本实验对3种主题相似度计算公式在语料库的baseline基础上进行了实验对比,采用F-score评测我们提出的sim散度同cosine夹角余弦、KL散度和sym-KL这3种主题相似度计算方法的准确度,得到的结果对比表如表2所示。
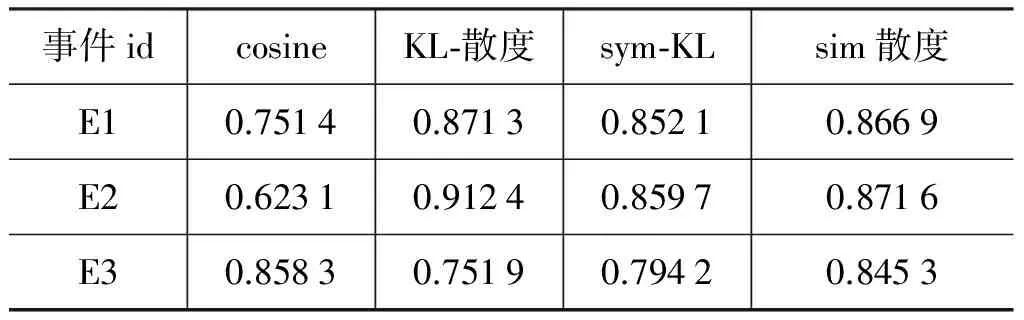
表2 夹角余弦、KL散度、对称散度和sim散度的F-score
从上面的数据显示来看,我们提出的sim散度相对于其他度量的效果平均略高,但优势不明显。另外,由于E1主题本身具有更大的辨识度,因此,其F-score值相比较于其他两个根主题而言略显优势。
本实验只基于sim散度构建主题树,效果如图2所示。对于新闻文本流数据考虑两种属性,影响力和关注度,因此图2只体现了这两种属性,本文只讨论主题上的空间语义结构模式,对于属性的时间演化模式不在本文讨论范围。图2没有显示概念层是因为系统抽取了top 10概念词作为子主题的语义表示,为方便起见,只显示前3、4个概念词。

图2 采用pLSA对新闻文本流抽取的主题树结构效果图
本文提出的基于主题树的主题结构模型不仅包含了主题之间的层次关系,也包含了每个叶子节点的事件对象, 且在每个主题上均具有属性,如图2,这种丰富的主题结构比简单的层次主题结构更能深层刻画文本流主题语义特征。

表3 实验语料抽取的事件
5 小结
本文主要描述主题空间结构建模问题,包括主题的表示,主题的结构模型,与主题相关的属性、事件以及关系的描述。该模型利用领域本体的特点,将主题同本体作一一映射,即主题对应概念、主题的属性对应概念的属性、事件对应实例、主题树本身对应关系。在主题的层次关系上能挖掘主题间的相似关联度和主题的抽象粒度,在事件的转移分析上能挖掘主题的转移演化规律,在属性值的计算上能挖掘主题的生命周期规律。其中,后两者是今后的研究重点。在真实新闻语料库上的验证实验结果表明,主题树相比较于其他简单的主题结构模型而言,更能深层次挖掘文本流中主题的潜在空间语义特征,且该结构模型具有的其他核心对象使得主题树结构模型能有效适应于主题的时间和空间挖掘任务,从而更方便挖掘文本流中主题时间和空间语义特征。同时,模型可扩展至无限多层,具有良好的可扩展性。
事件转移度一般是用来描述起始事件到后续事件的转移程度,即起始事件引起后续事件发生的程度大小,上述方法还不能完全表达这种程度的大小,因此在后续工作中将进一步研究事件的转移度,从而方便构建基于事件的主题演化图。
对主题属性开展生命周期研究将有利于突发事件检测,热点问题识别和主题预测,本文对这个问题尚未展开讨论,这些也是我们后续工作的重点。
[1] 方奇,刘奕群,张敏等.基于群体智慧的Web访问日志会话主题识别研究[J]. 中文信息学报,2011,25(1): 35-40.
[2] J Allan, J Carbonell, G Doddington, et al. Topic detection and tracking pilot study: Final report[C]//Proceedings of the DARPA Broadcast News Transcription and Understanding Workshop, 1998: 194-218.
[3] D M Blei, A Y Ng, M I Jordan. Latent Dirichlet Allocation[J]. Journal of Machine Learning Research, 2003, 3: 993-1022.
[4] W Li, A Mccallum, W Cohen. et al. Dag-structured mixture models of topic correlations[C]//Proceedings of International Conference on Machine Learning (ICML’06), 2006: 577-584.
[5] Berendt B, Subasic L. Measuring graph topology for interactive temporal event detection[J]. Kunstliche Intelligenz, 2009, 23(2): 11-17.
[6] 权小军,林洋港,罗奇鸣,等. 基于概率主题的文本层次分类[J]. 中国科学技术大学学报,2009,39(8): 875-879.
[7] 张琪,陈千,郭鑫. 基于主题本体树的文本流层次主题检测技术[J]. 微电子学与计算机,2013,30(7): 60-63.
[8] Thomas Hofmann. Probabilistic Latent Semantic Indexing[C]//Proceedings of the Twenty-Second Annual International SIGIR Conference on Research and Development in Information Retrieval (SIGIR-99), 1999.
Multi- granularity Topic Structure Modeling in Text Stream
CHEN Qian, GUO Xin, WANG Suge, ZHANG Hu
(School of Computer and Information Technology, Shanxi University, Taiyuan, Shanxi 030006, China)
Topic Detection has been widely used in text mining and NLP, while the basis of which is topic structure modeling. In this paper, we propose a semantic hierarchical topic structure model to describe multi-granularity topic structure. This model utilizes the characteristics of domain ontology, with each concept in the ontology mapped to a topic. The concepts in concept list are respresented as topic-tree leaf nodes, and nodes in each layer can be treated as multinomial mixture distribution on the lower layer nodes. This delicate structure is easily adapted to multi-granularity topic structure in real world text stream. Experiment showed that the structure model reflect rich multi-granularity semantic feature of topic.
topic detection; multi-granularity topic modeling; text stream

陈千(1983—),博士,讲师,主要研究领域为机器学习、文本挖掘、主题检测。E⁃Mail:chenqian@sxu.edu.cn郭鑫(1982—),博士,讲师,主要研究领域为机器学习、数据降维、文本挖掘。E⁃mail:guoxinjsj@sxu.edu.cn王素格(1964—),教授,博士,博士生导师,主要研究领域为中文信息处理、文本倾向分析、机器学习。E⁃Mail:wsg@sxu.edu.cn
1003-0077(2015)01-0118-08
2013-06-27 定稿日期: 2014-09-26
国家自然科学基金(61403238,61100138);山西省自然科学基金(2014021022-1,2011011016-2);山西省回国留学人员科研资助项目(2013-022)
TP391
A
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
粉末冶金技术(2021年3期)2021-07-28
哈哈画报(2021年10期)2021-02-28
小型微型计算机系统(2020年10期)2020-10-21
开放教育研究(2020年2期)2020-03-31
制造业自动化(2017年2期)2017-03-20
中国修辞(2017年0期)2017-01-31
浙江大学学报(工学版)(2016年11期)2016-06-05
长江学术(2016年4期)2016-03-11
中国煤层气(2015年3期)2015-08-22
