
融合句义结构模型的微博话题摘要算法
2015-07-11 10:10罗森林贾丛飞原玉娇潘丽敏
浙江大学学报(工学版) 2015年12期
林 萌,罗森林,贾丛飞,韩 磊,原玉娇,潘丽敏
(北京理工大学 信息与电子学院,北京100081)
微博的出现深刻改变了人们的信息交流方式.以新浪微博为例,截至2014年6月,微博月均活跃用户数为1.565 亿人,微博平均日活跃用户数为6970万人[1].热门话题是微博中正在热议的新鲜话题,用户查询一个热门话题,得到的是按照热门程度或发表时间排序的所有相关微博.然而,由于微博数量庞大,用户得到的信息经常是不完整的,甚至是不相关的或者是重复的,信息获取的效率很低,对微博进行摘要能大大提高信息获取的效率.
多文档自动摘要技术其处理对象为结构完整、书写规范、条理清楚的长文本.微博篇幅短小(140字以内),用词不规范,缺失长文档的结构信息,并包含大量垃圾内容和垃圾用户.直接利用已有的多文档摘要技术对其摘要存在严重的特征稀疏和结构缺失问题.这些问题导致抽取特征不足以准确描述文本内容,抽取的句子与话题的中心发生漂移,生成的摘要与主题相关度下降,大大影响摘要生成的效果[2-4].提高生成摘要与话题的相关度问题具有十分重要的意义.
1 相关工作
多文档自动文摘技术经过多年发展已经出现了很多方法和技术.具有代表性的方法有基于词频的方法(如:SumBasic[5]和MEAD[6])、基于概率浅层语 义 分 析(probabilistic latent semantic analysis,PLSA)[7]和浅层狄利克雷分布(latent Dirichlet allocation,LDA)[8-9]的方法、基于图的方法(如:Lex-PageRank[10]算法,这种方法已经成功应用到了Google PageRank中)以及基于其他机器学习[11-12]的方法等.
然而,这些方法大都是针对长文本的词项特征进行统计分析处理.微博篇幅短小,单条微博的关键词一般只有十几个甚至几个,关键词特征稀疏.单条微博内关键词的重复率不明显,缺失长文档的结构信息.因此,传统自动摘要技术将失去原有效果,需要结合微博特性与传统自动摘要技术的优点来进行微博话题摘要.
近年来,以Twitter[13-15]为代表的英文社会化短文本摘要逐渐获得科研人员的关注.2010 年Sharifi等[16]提出将包含主题词的最常使用词汇链作为摘要,这种方法获得的摘要只是包含主题词的一句话,信息并不全面.2011年,Harabagiu等[17]通过构建复杂事件的发展结构模型和用户行为模型来生成微博复杂事件的摘要.Chakrabrti[18]使用隐马尔可夫模型学习微博事件的隐藏状态,对高度结构化重复出现的话题(如:运动赛事)进行摘要.Inouye等[19]在文献[16]的基础上提出一种基于聚类的Hybird TF-IDF摘要方法.这种方法计算词的TF(term frequency)值是该词在语料库中出现的次数与语料库中出现的词数的比值,而在计算IDF(inverse document frequency)值时,又将每篇微博作为一个单独的文档对待,计算方法为出现该词的微博总篇数除以语料中的微博总数.实验证明,Hybrid TF-IDF取得的效果优于一些主流的摘要方法(如:MEAD、LexRank[20]、TextRank[21]).中文的微博摘要处于刚刚起步阶段,可以查阅的资料较少.2011年,武汉大学的何炎祥[2]等提出一种轻巧新颖的LN 算法(light N-tree algorithm),以树的形式将话题以摘要的方式展现给用户,但不能形成可读性文摘.2013年,Bian等[22]引入微博文本的配图作为新的特征,提出一种新的概率生成模型MMLDA(multimodal LDA)来发现微博话题的子主题并进行摘要.
目前的研究大多基于词形、词频等统计信息进行特征抽取,忽略了句子的句义成分以及成分之间的关系特征,对微博内容挖掘深度不够,导致仅仅基于词形匹配的相似度计算方法无法准确计算句子的内容相似.同时,在选择句子时,没有抽取句子之间的隐藏语义联系,未充分利用句子所处的子主题信息,导致抽取的句子与主题的相关性较差.本文针对以上问题提出融合句义结构模型[23]的微博话题摘要方法.
2 句义结构模型及句义分析
句义结构模型以现代汉语语义学为基础,是从句义角度研究句子的成分以及成分之间关系的句义结构化表示模型.句义结构分为句型层、描述层、对象层和细节层4个层次,包含的句义成分有句义类型、话题、述题、谓词和项等.其中,项又分为基本项与一般项,项的功能用语义格表示,一共有7个基本格和12个一般格.句义结构模型的基本形式[24]如图1所示.
句义分析是由句义结构模型分析得到句子的结构信息和语义信息.其具体方法是根据句义结构模型基本框架,分别处理不同语义格的对象成分以及语义格结构信息,主要语义格类型说明如表1所示.
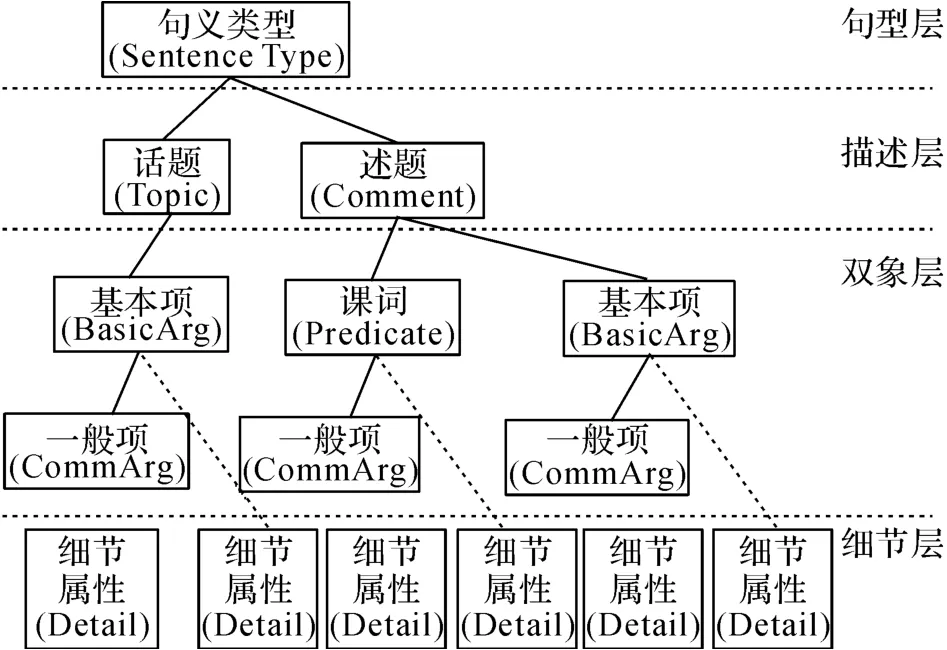
图1 句义结构模型的基本形式Fig.1 Basic form of sentential semantic model

表1 主要语义格类型说明Tab.1 Description of main semantic cases
3 算法原理
针对现有方法生成摘要内容冗余度高的问题,本文从准确计算句子内容相似性的角度出发,利用句义结构模型分析语义项和项之间的依存关系抽取句子的句义特征,扩充句子的语义维度,利用句义特征准确表达语句信息及句子内容的相似性,抽取句子时根据句子内容相似性有效控制文摘冗余度.针对现有摘要方法抽取的句子与子主题相关性差的问题,本文从挖掘句子之间的隐藏语义联系及子主题信息的角度出发,提出抽取句子关联特征的方法.关联特征表示句子与话题的语义联系度,利用关联特征增强相似语句的语义联系.综合加权句子的语义特征和关联特征,抽取子主题内的关键句子,得到话题的摘要.
本方法将文档集合分句,句子清洗,分词和词性标注得到预处理结果,对预处理结果分别计算语义权值和关联权值.在计算语义权值时,统计预处理结果中所有实词出现的句子频率,按句子频率从大到小排序,选择前N 个词作为主题词的种子词,加入哈工大同义词林扩展版(HIT IR-Lab Tongyici Cilin(Extended))进行扩展,得到扩展后的主题词表.结合主题词表分析句子的语义特征,包括词性词法特征和句义结构特征,对各个特征线性加权,得到句子的语义权值.在计算关联权值时,需要先对预处理结果进行句子相似度计算,得到句子两两之间的语义相似值,构建相似度矩阵,划分子主题类.利用句子两两之间的语义相似值,计算句子与类内及类外其他句子的语义相似度,得到句子的关联权值.最后对句子的语义权值和关联权值综合加权,得到句子的最终权值.最后依次选择子主题内权重最大的句子作为文摘句.所提出算法的原理图如图2所示.
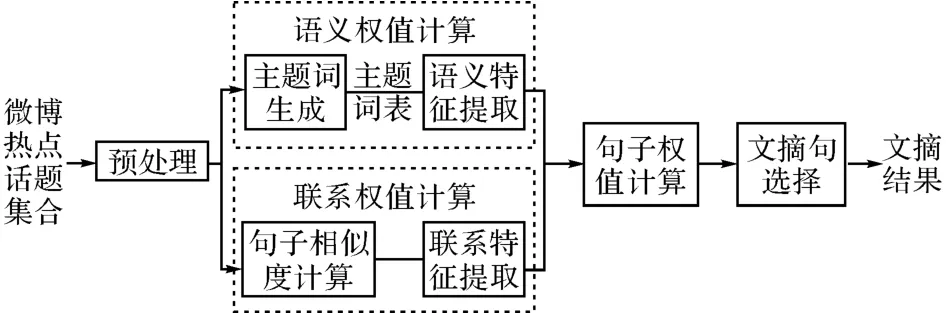
图2 所提出算法的原理图Fig.2 Schematic diagram of proposed algorithm
3.1 预处理
分句、句子清洗是预处理的第一步.将微博中内嵌链接URL、表情符号和@后的用户名从原始语料库中删除.采用中科院提供的中文分词软件“ICTCLAS”[24],按照北京大学词性标注规范对数据集进行分词.将有效词(名词、动词、形容词、数词、时间词等实词)数量小于4 的句子去除.预处理原理图如图3所示.
3.2 语义权值计算
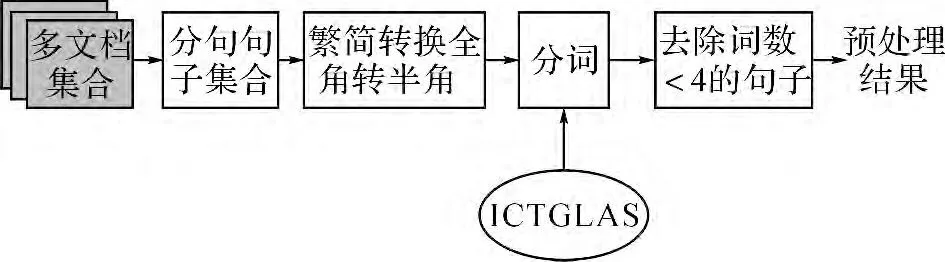
图3 预处理原理图Fig.3 Schematic diagram of preprocessing
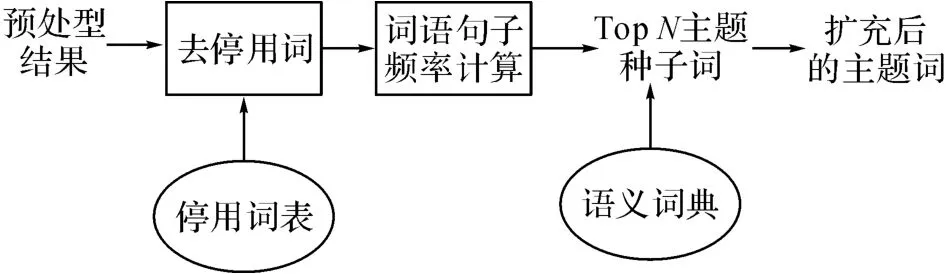
图4 主题词生成原理图Fig.4 Schematic diagram of topic generation module
3.2.1 主题词生成 主题词生成原理图如图4所示.将所有实词按句子频率从大到小排序,选择前N 个词作为主题词的种子词,加入哈尔滨工业大学同义词林扩展版进行扩展,得到扩展后的种子词.扩展版的同义词林包含77 343条词语,按照五层树形结构组织到一起.对词义进行有效扩展,或者对关键词做同义词替换可以明显改善信息检索、文本分类和自动问答系统的性能.本文利用第5级分类对种子词进行扩展分别按照词义相等和词义相关2大类别扩展种子词.
3.2.2 语义特征提取 分析句子的语义特征,是计算句子内容重要性的关键步骤.现有研究一般只用到句子的词法特征和句法特征,对句子内容的挖掘仅限于词、句法层次.本研究不仅使用传统的词法句法特征,并加入句子的句义结构特征.句义结构特征可以增加句子的分析深度,能够更好地表达句子的深层含义,对更有效地挖掘句子内容.
句义结构模型是对句子语义层次的分析,是句义的形式化表达.句义结构模型中的话题、谓词、述题等信息可以体现一个句子的核心内容,此外句义结构模型中各个句义成分之间的关系对句子的语义表达也很有意义.本文使用的语义特征如表2所示.
特征项F1及F2为句子有效词的统计特征.一般认为名词(noun)、动词(verb)比其他词性更重要,赋权重为2,其余词性权重为1.话题、谓词、述题特征是句子的核心内容,若该句的以上特征在主题词表内,则说明该句的核心内容跟主题相关,出现的词数越多则该句与主题的联系越紧密,越能表达主题中心的意义.一般项的句义功能是描述基本项和谓词,对其表达的内容作进一步说明和补充.将句子一般格中包含的主题词选为特征,作为对一般项和谓词的补充.句子的语义权重值计算方法如下.
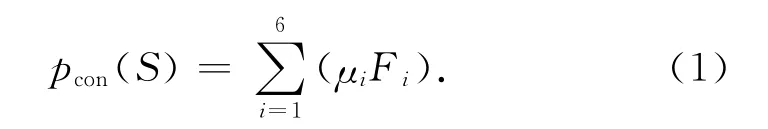
式中:pcon(S)是句子S 的语义权重值,Fi和μi 分别代表语义特征的值和该特征的加权系数.

表2 句子语义特征Tab.2 Semantic features of sentences
3.3 联系权值计算
3.3.1 句子相似度计算 由于句子长度的限制,单个句子的关键词一般只有几个,特征尤其稀疏,仅仅基于词形匹配的方法无法准确衡量句子内容的相似度.在句义结构的基础上,使用LDA 主题模型,对单个句子的关键词进行扩充,从而解决由于句子长度限制特征严重缺失所带来的无法计算句子相似度的问题,并在句义层面计算句子的内容相似度.
句子相似度计算的原理图如图5所示.输入是预处理后的所有句子,输出是句子两两之间的相似值.其中,句义结构分析模块利用BFS-CSA[23]分析句子得到句义结构;划分词语模块是根据句义结构中的成分,将词语划分成基本格、一般格和谓词;LDA 分析模块通过计算划分好的语义格得到知识库;扩充句子维度模块通过使用知识库的信息对句子中的格进行扩充,得到新的表示向量;句子相似度计算模块通过计算扩充后的句子向量的余弦相似度,得到2个句子间的相似值.
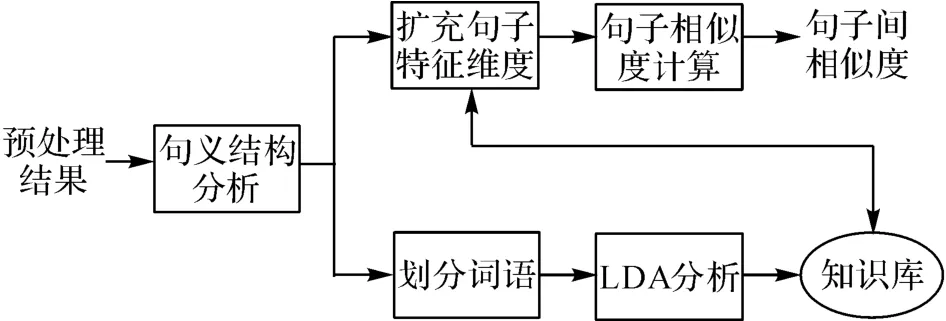
图5 句子相似度计算原理图Fig.5 Schematic diagram of sentence similarity calculation
根据句义结构理论,句义包括话题和述题.话题是被描述的成分;述题是语义表达的描述成分,同时考虑句子的主干(基本格)和修饰成分(一般格).本研究将知识库分为3类:话题(基本格)知识库、述题(基本格和谓词)知识库和一般格知识库.话题知识库中的词语来源于文集中句子话题下的基本格,用于对句子中话题下的基本格词语进行扩充,述题知识库中的词语来源于文本集中句子述题下的基本格和谓词,用于对述题下的基本格词语和谓词进行扩充,一般格知识库中的词语来源于句子中的一般格,用于对句子中所有一般格词语进行扩充.
按照Blei[26]提出的理论,使用LDA 主题模型计算得到同一主题(Topic)下的词语具有相似的属性或意义,因此,本文利用LDA 对3组不同的词语集合分别计算不同主题下的概率,最后将句子中话题(基本格)、述题(基本格和谓词)和一般格下的词语分别选择对应知识库所在主题下的其他词语作为特征向量上该词的维度扩充,扩充维度的取值计算公式如下:

式中:V 为扩充词语的取值,n 为待扩充词在句子中出现的次数,w 为待扩充词在相应主题下的概率取值.
对句子的话题和述题分别进行扩充,得到句子的话题向量和述题向量,分别计算句子的话题相似度和述题相似度,对2个相似度进行加权得到最终的句子相似度:
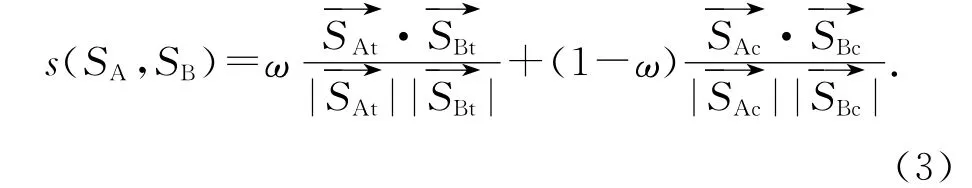
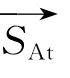
以0.1为步进值调整ω,得到摘要的ROUGE评价指标如表3所示.由表3可得,当ω=0.5时,即当话题和述题的权重相等时,ROUGE 评价指标得分最高.以ROUGE-1 指标为例,当ω 从0.5 开始向0(1)方向减小(增大)时,ROUGE-1指标为逐步减小的趋势(见图6),说明话题和述题是综合衡量句子意义的2个方面,偏向于任何一方,句子相似度的计算值都不能完全表达句子的意义.由实验结果可知,ω 的最佳取值为0.5.
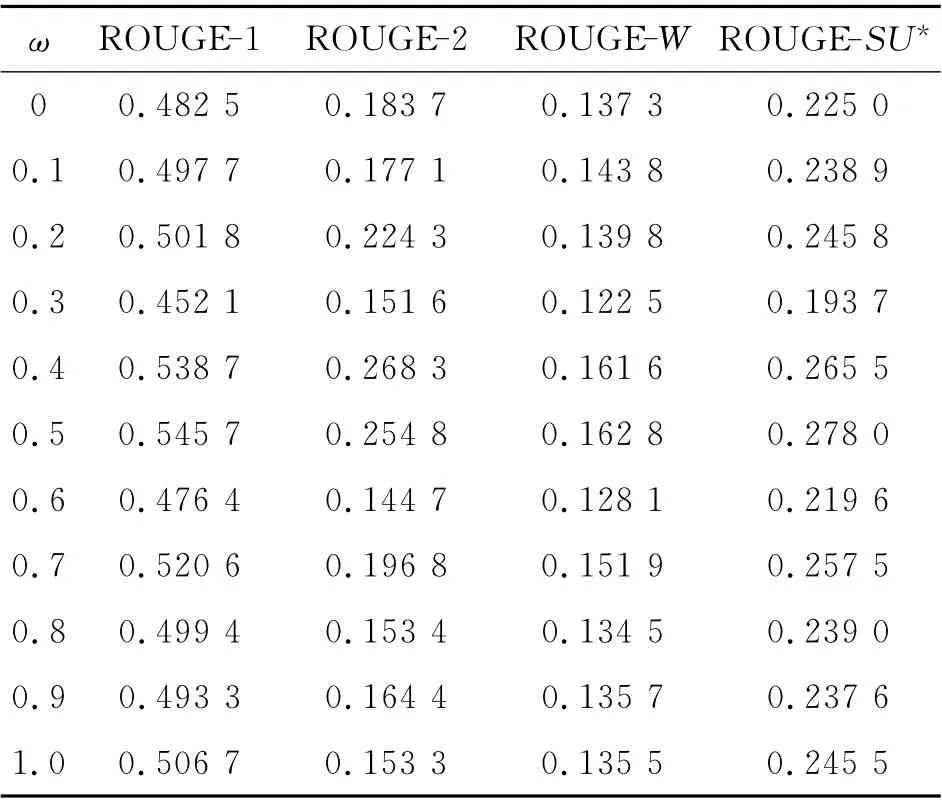
表3 参数ω 的选择实验结果Tab.3 Results of parameter selection experiments ofω
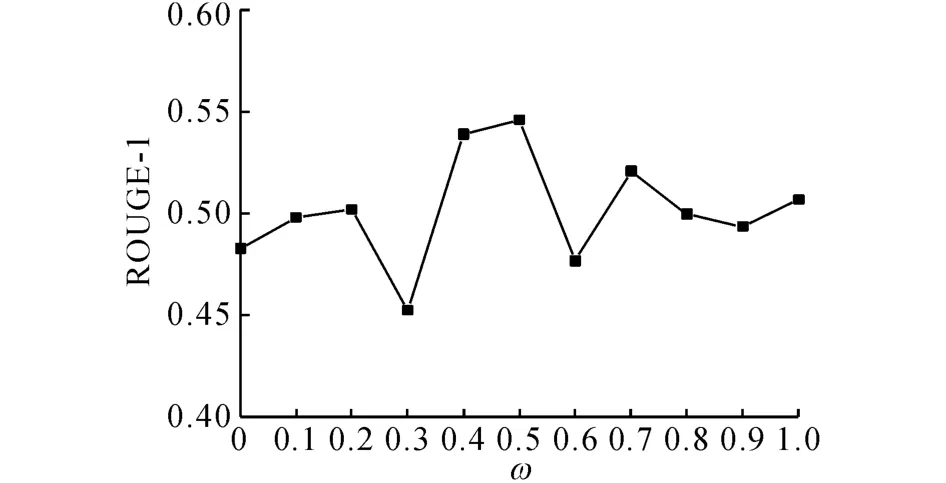
图6 ROUGE-1值随ω的变化趋势图Fig.6 Diagram ofω-changing trend of ROUGE-1
3.3.2 关联特征提取 通过句子相似度计算出句子两两之间的语义相似值,构建句子的n 维空间向量表示:
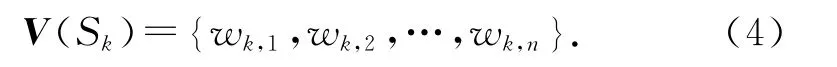
式中:空间中的每一维wk,j是句子Sk对Sj的相似度值,j=1,2,…,n.子主题是围绕中心主题发生的现象、后果以及原因等的说明,是对中心主题不同侧面的描述.利用构建的句子特征空间对语料中所有的句子进行K-means聚类,划分子主题.对于本文所使用的语料库,每一个话题下的子主题数目一般不多于10个.因此,设定初始聚类中心为10,并将类内句子数量小于总量5%的类作为噪音去除,剩余的类作为子主题划分结果.
句子的关联特征表示句子与话题的语义联系度,可以通过加权计算该句与不同子主题中其他句子的语义重合度得出.句子Sk对Sj的语义重合度R(Sk,Sj)定义为句子Sj的语义权重值Pcon(Sj)与Sj对Sk的句子相似度值s(Sk,Sj)的乘积:
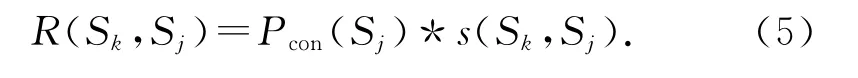
构建无向图G(S,E),图中的每个节点S 对应一个语句,边E(Si,Sk)表示语句Si与Sk的句子相似度值.节点S 的度d 是与S 相连的边的数目,反映了S 包含信息的重要程度:d 越大,则对应语句所关联的语句数目越多,那么这个句子所包含的信息越重要;反之亦成立.如果一个节点的度比较大,那么与之相关联的语句也相应地比较重要.令节点S的初始值为句子的内容权重值,通过计算其他句子对该句的语义重合度得到句子的联系权重值.考虑到同一个子主题下句子联系紧密,设加权系数为1,不同子主题下句子的加权系数由子主题的平均句子内容权重得出
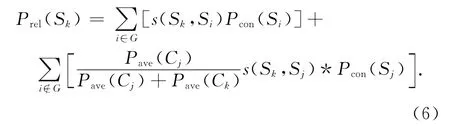
式中:Prel(Sk)为句子Sk的关联权重值.若Sk和Si属于同一个子主题(i∈G),则加权系数为1;若Sk和Sj分属不同子主题(i∉G),加权系数为Pave(Cj)/(Pave(Cj)+Pave(Ck)).其中Pave(Cj)、Pave(Ck)分别为句子所属子主题的句子平均语义权重值.
3.4 句子权值计算
在计算句子重要性时,现有方法大都偏重于挖掘句子本身的内容,而忽略了句子所处“环境”的影响.一个好的文摘句,内容上不仅要紧扣主题,同时也应该与语料库中的其他句子联系紧密.本文所用的句子权重计算方法不仅考虑了句子的语义信息同时考虑了句子的关联特征.句子Si的最终权值为:
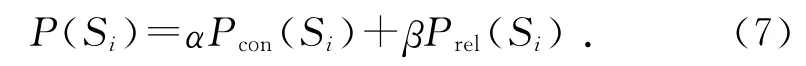
式中:α+β=1,参数α 调整语义权值和联系权值的权重.为了得到选择参数α 的最佳取值,α 从0开始以0.1为步进变化到1,得到当压缩比为1.5%时,ROUGE-1的取值变化如图7所示.由图7可知,当α=0.1时ROUGE-1的取值最高.
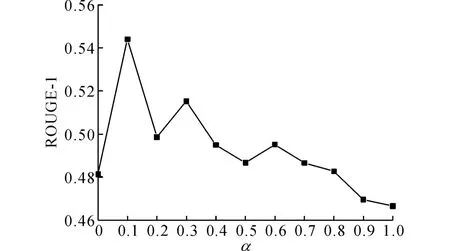
图7 参数α 选择实验Fig.7 Parameter selection experiments ofα
3.5 文摘句选择
句子选择模块根据子主题的重要程度从高到低对子主题排序,确定子主题的抽取顺序和抽取句子数,并根据句子的重要性和冗余度在子主题内抽取文摘句.子主题的重要性与两方面因素有关:1)子主题包含的句子数目,句子数目越多说明该子主题在文档集合中出现的频率越高;2)子主题包含句子的重要程度,子主题中平均句子权重越大,该子主题越重要.子主题打分策略如下:
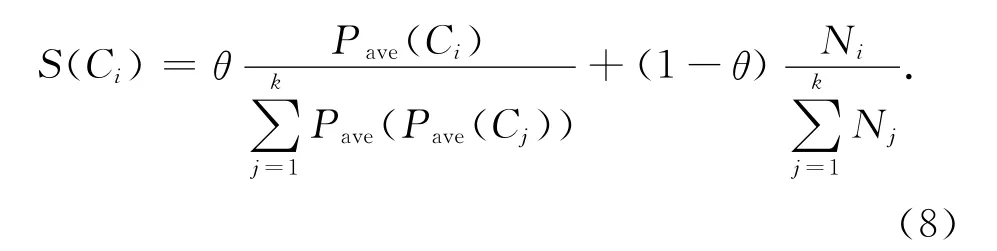
式中:S(Ci)为子主题Ci的得分,Pave(Ci)为子主题Ci的句子平均权值,k 为子主题个数,Ni为子主题Ci包含的句子个数.参数θ用于调整子主题内句子平均权值和句子数目的权重,一般认为两者同样重要,本文取θ=0.5.
根据压缩比,从不同子主题内抽取相应数量的句子生成摘要.子主题句子抽取个数由该子主题的重要程度决定:
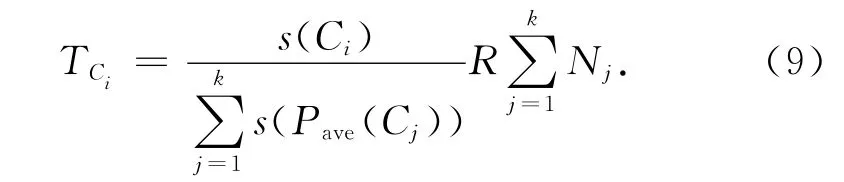
式中:TCi表示子主题Ci的句子抽取个数,R 代表压缩比的值,Nj表示不同子主题内句子的数目.
在选择文摘句时,不仅要保证选择的句子与主题的相关度高,也要保证该句与已选文摘句之间的冗余度尽可能小,从而避免包含同一条重要信息的句子反复出现在文摘里.句子选择的具体过程如下:

4 实验及分析
4.1 数据源
实验数据采用自然语言处理与中文计算会议(NLP&&CC)2013年中文微博观点要素抽取评测语料[27].该语料包含2013年3月的微博话题,实验数据的具体描述如表4所示.
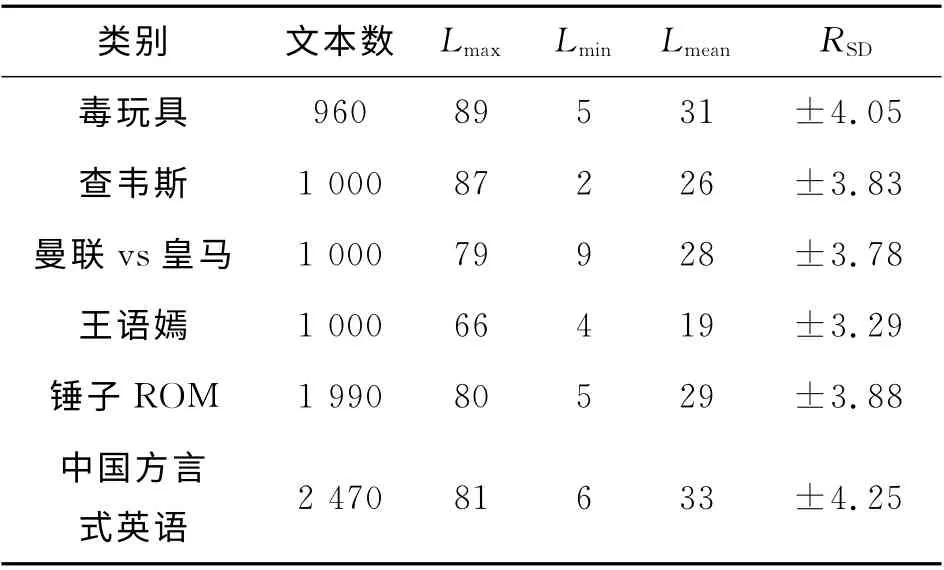
表4 微博摘要实验数据表Tab.4 Experimental data of weibo summarization
表中,文本有效长度是指经过分词去除停用词后,每篇微博包含的词的个数,Lmax为文本有效长度的最大值,Lmin为文本有效长度的最小值,Lmean为文本有效长度的平均值,RSD表示同一类别下句子文本有效长度的标准差.由北京理工大学信息系统及安全对抗实验中心对每个话题生成压缩比为0.5%、1.0%和1.5%的3篇标准摘要.生成过程如下:每3人对同一话题文本集提取不同压缩比的人工摘要,然后由自然语言处理小组的10名博士、硕士对3份人工摘要进行评价并计算平均得分:将平均得分最高的摘要作为标准摘要放入标准摘要集,如果得分相同则都放入标准摘要集中.
4.2 评价方法
本文采用多文档摘要的通用评价方法ROUGE[28]toolkit(版本号v1.5.5)作为评价标准.ROUGE方法通过计算候选摘要与标准摘要的词单元重合度来区分候选摘要的质量,计算的值包括ROUGE-N、ROUGE-W (本 研 究 取W =1.2)和ROUGE-SU*等:
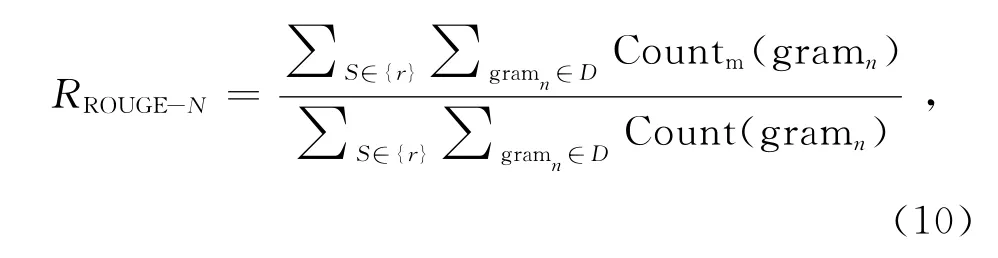
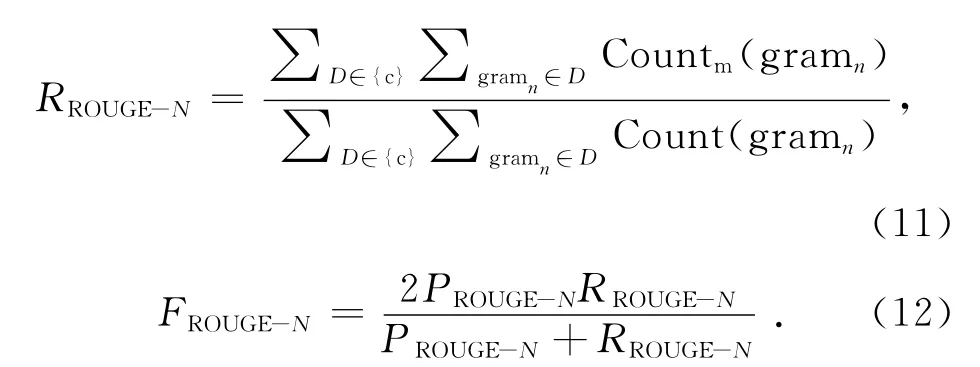
式中:n代表n-gram 的长度,D 表示文档,其中下标r表示文档属于标准摘要,c表示文档属于待评价摘要,Countm(gramn)表示同时出现在待评价摘要和标准摘要的n-gram 的个数,Count(gramn)为标准文摘中的n-gram 个数.
4.3 实验结果及分析
4.3.1 关联特征 为了验证引入句子关联特征对摘要结果的提升,在压缩比为1.5%的条件下,采用单因子变量法,令Pcon(Si)加权系数α=0.1保持不变,β从0开始以0.05 为步进调整,以加权系数的比值β/(α+β)为自变量,得到ROUGE-1的取值变化如图8所示.
由图8所示可知,当β/(α+β)=0时,即不考虑句子的关联权重,只考虑句子本身的语义权重,ROUGE-1为0.466 58,加入句子关联权重特征,ROUGE-1值有明显的改善.当β(α+β)≤0.9 时,ROUGE-1值呈现上升趋势,且均明显优于仅考虑语义权重的ROUGE-1 取值;当β(α+β)>0.9 比时,若继续增加关联权重的值,ROUGE-1值呈现下降趋势,当β(α+β)=1.0时即当关联权重占比远大于语义权重时,ROUGE-1=0.481 25.实验结果说明:所提出的句子权值计算方法,在深入理解句子本身语义的基础上,可以有效量化该句与语料库中其他句子之间的语义联系.综合考虑句子内外部特征的权值计算方法,有利于丰富句子的特征维度,准确描述文本内容与话题的相关度,合理利用句子内外部语义特征,使同类数据内聚性增强、噪音影响减弱,对于选择关键文摘句以及减少文摘的冗余度都很有意义.
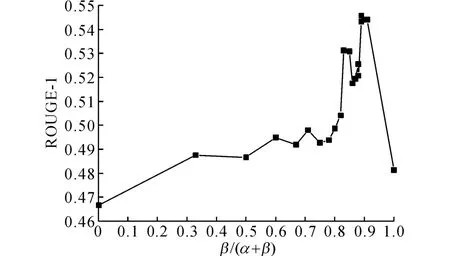
图8 ROUGE-1值随加权系数比值的变化趋势图Fig.8 Curve of ROUGE-1as weighted coefficient ratio changes
4.3.2 对比实验 为了验证所提出方法的有效性,建立了2个对照方法与本文方法进行对比实验.
Hybird TF-IDF 是Inouye等[19]于2011 年 提出的一种基于聚类的微博话题摘要方法,该方法已被证明比一些主流的多文档摘要方法效果要好.SumBasic[5]是经典的多文档摘要方法,在DUC06测评大会上按代表性指标排序排名第三,并已获得应用.在压缩比分别为0.5%、1.0%、1.5%的条件下,3组系统的FROUGR-N值实验结果如表5、6和7所示.
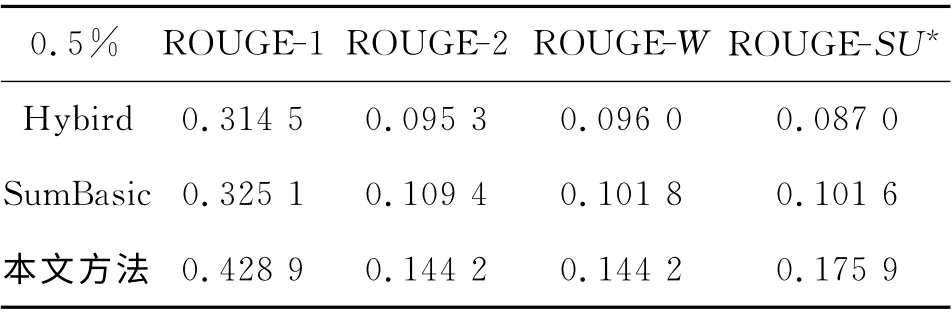
表5 压缩比为0.5%的对比实验结果Tab.5 Contrast experiments results with compress ratio at 0.5%
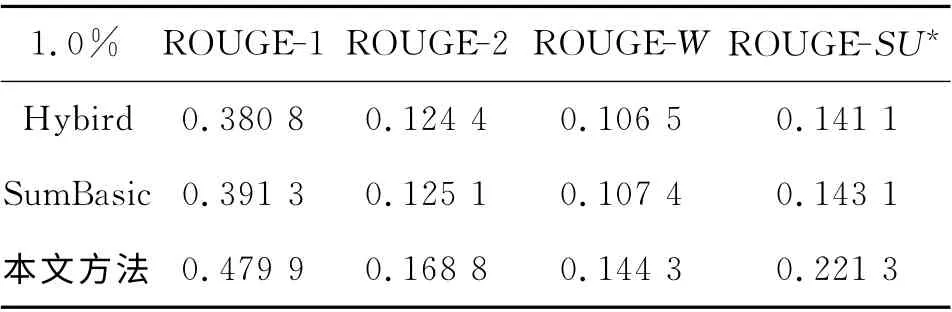
表6 压缩比为1%的对比实验结果Tab.6 Contrast Experiments Results with Compress Ratio at 1.0%

表7 压缩比为1.5%的对比实验结果Tab.7 Contrast experiments results with compress ratio at 1.5%
由表5~7可知,本文提出的微博话题摘要方法在ROUGE-1,ROUGE-2、ROUGE-W、ROUGESU*的评价指标下平均表现最优,4个指标的值与对比方法相比均有明显提高.相比于Hybrid TFIDF、SumBasic等基于词形词频的短文本摘要方法,本文生成的摘要在兼顾冗余度的同时与话题更相关,综合表现ROUGR 值更高.这表明分析句子的句义结构,提取句义特征项和项之间的依存关系可以深入挖掘句子的语义信息,深化了句子分析层次,所提取的句义特征增强了语义特征的表达能力,有效避免了信息丢失;构建相似度矩阵划分子主题的方法使类内语义相关性增大,同类数据内聚性增强,有效降低了噪声的影响;综合考虑句子内部语义特征和外部关联特征的句子权重计算方法,丰富了句子的特征表示,全面考虑句子的语义环境,从而提升了摘要与话题的相关度.
在压缩比为0.5%~1.5%时,压缩比越大,系统的性能越好.这是由于人工抽取标准摘要的随机性比较大,而压缩比提高、数据量变大在一定程度上克服了这种随机性,使得最终得到的摘要更加合理而使评价效果有所提高.
4.3.3 泛化能力实验 当压缩比为0.5%、1.0%和1.5%时,计算系统对不同话题的ROUGE 评价指标.因篇幅所限,图9仅展示压缩比为1.5%的实验结果.

图9 系统泛化能力实验结果Fig.9 System performance on different topics
由图9可知,系统在不同话题下的评价结果存在一定的差异.一方面是由于人工抽取标准摘要的随机性,另一方面是因为不同话题子主题的结构不同.由ROUGE评价指标来看,6个话题的ROUGE-1值 均 在0.45 以 上,ROUGE-2、ROUGE-W 均 在0.10以上,ROUGE-SU*均在0.15以上.因此,本文方法处理不同话题的泛化能力较好,适用范围较广.
4.3.4 实例分析 以话题“查韦斯”为例,分别采用Hybird TF-IDF方法和本文方法进行摘要实验,在压缩比为0.5%的条件下得到摘要结果如表8 所示.可知,Hybird TF-IDF 生成的摘要包含子主题较少,内容较片面,摘要的冗余度也较大.本文方法生成的摘要覆盖了话题的多个子主题,内容较全面,摘要冗余度较小,因而本文方法在语义上生成的摘要效果更优.

表8 2种不同方法得到的“查韦斯”话题摘要结果对比Tab.8 Comparison of generated summaries from topic“Chávez”using two different methods
5 结 论
利用句义结构模型深化了句子分析层次,提取的句义特征增强了语义特征的表达能力,可以有效避免信息丢失.同时,所提出的句子权重计算方法综合考虑了加权句子内部语义特征和外部关联特征,使得同类数据的内聚性增强,语义相关性增大,有效降低了噪声的影响,从而使得生成的摘要与话题相关度更高.此外,本文方法处理不同话题的泛化能力较优,适用范围较广.
下一步研究的重点是引入句子结构项之间的依存关系作为特征,完善句义结构模型的特征体系,提高文摘句抽取效果,从而生成更高质量的微博话题摘要.
(
):
[1]Wikipedia.Sina Weibo[EB/OL].(2014-11-10)[2015-10-20].https:∥en.wikipedia.org/wiki/Sina_Weibo.
[2]HE Y,SU W,TIAN Y,et al.Summarizing microblogs on network hot topics[C]∥Proceedings of the 2011International Conference on Internet Technology and Applications(iTAP 2011).New York:Piscataway,2011:1-4.
[3]LONG R,WANG H F,CHEN Y Q,et al.Towards effective event detection,tracking and summarization on microblog data[M]∥ Web-Age Information Management.Berlin:Springer,2011:652-663.
[4]WILLIAN H,ZHANG Y.Threshold and associative based classification for social spam profile detection on Twitter[C]∥2013 9th International Conference on Semantics,Knowledge and Grids(SKG).New York:Piscataway,2013:113-120.
[5]VANDERWENDE L,SUZUKI H,BROCKETT C,et al.Beyond SumBasic:task-focused summarization with sentence simplification and lexical expansion[J].Information Processing and Management,2007,43(6):1606-1618.
[6]RADEV D R,JING H,STYS M,et al.Centroid-based summarization of multiple documents[J].Information Processing and Management,2004,40(6):919-938.
[7]SINGH M,KHAN F U.Effect of incremental EM on document summarization using probabilistic latent semantic analysis[C]∥Proceedings of the World Congress on Engineering(WCE 2012).Hong Kong:Newswood Limited,2012:2198.
[8]GAO D,LI W,OUYANG Y,et al.LDA-based topic formation and topic-sentence reinforcement for graphbased multi-document summarization[M]∥Information Retrieval Technology.Berlin:Springer,2012:376-385.
[9]ARORA R,RAVINDRAN B.Latent dirichlet allocation based multi-document summarization[C]∥Proceedings of the 2nd Workshop on Analytics for Noisy Unstructured Text Data.Singapore:ACM,2008:91-97.
[10]BINTI ZAHRI N A H,FUKUMOTO F,MATSUY-OSHI S.Link analysis based on rhetorical relations for multi-document summarization[J].IEICE Transactions on Information and Systems,2013,96(5):1182-1191.
[11]SUJATHA C,CHIVATE A R,GANIHAR S A,et al.Time driven video summarization using GMM [C]∥2013 4th National Conference on Computer Vision,Pattern Recognition,Image Processing and Graphics(NCVPRIPG).Piscataway:IEEE,2013:1-4.
[12]OLARIU A.Clustering to improve microblog stream summarization[C]∥2012 14th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing(SYNASC 2012).Timisoara:IEEE,2012:220-226.
[13]ZHANG R,LI W,GAO D,et al.Automatic Twitter topic summarization with speech acts[J].IEEE Transactions on Audio Speech and Language Processing,2013,21(3):649-658.
[14]KHAN M A H,BOLLEGALA D,LIU G,et al.Multitweet summarization of real-time events[C]∥2013International Conference on Social Computing(SocialCom).Washington DC:ASE/IEEE,2013:128-133.
[15]LIU F,LIU Y,WENG F L.Why is“SXSW”trending?Exploring multiple text sources for twitter topic summarization[C]∥Proceedings of the Workshop on Languages in Social Media(LSM 2011).Strasbourg:Association for Computational Linguistics,2011:66-75.
[16]SHARIFI B,HUTTON M,KALITA J.Summarizing microblogs automatically[C]∥2010Human Language Technologies Conference of the North American Chapter of the Association for Computational Linguistics,NAACL HLT 2010.Los Angeles: ACL,2010:685-688.
[17]HARABAGIU S M,HICKL A.Relevance modeling for microblog summarization[C]∥Proceedings of the 5th International Conference on Weblogs and Social Media.Menlo Park:AAAI,2011:514-517.
[18]CHAKRABARTI D,PUNERA K.Event summarization using Tweets[C]∥Proc of the 5th Int AAAI Conference and Social Media (ICWSM’11).Menlo Park:AAAI,2011:66-73.
[19]INOUYE D,KALITA J K.Comparing Twitter Summarization Algorithms for Multiple Post Summaries[C]∥Proceedings of the 2011IEEE Third International Conference on Privacy,Security,Risk and Trust and IEEE Third International Conference on Social Computing(PASSAT/SocialCom 2011).Boston:IEEE,2011:298-306.
[20]ERKAN G,RADEV D R.LexRank:graph-based lexical centrality as salience in text summarization [J].Journal of Artificial Intelligence Research,2004:457-479.
[21]MIHALCEA R,TARAU P.TextRank:bringing order into texts[C]∥Conference on Empirical Methods in Natural Language Processing (EMNLP),2004.Barcelona:ACL,2004:275-279.
[22]BIAN J,YANG Y,CHUA T.Multimedia summarization for trending topics in microblogs[C]∥22nd ACM International Conference on Information and Knowledge Management,CIKM 2013.San Francisco:ACM,2013:1807-1812.
[23]罗森林,韩磊,潘丽敏,等.汉语句义结构模型及其验证[J].北京理工大学学报,2013,33(2):166-171.LUO Sen-lin,HAN Lei,PAN Li-min,et al.Chinese sentential semantic mode and verification[J].Transactions of Beijing Institute of Technology,2013,33(2):166-171.
[24]罗森林,刘盈盈,冯扬,等.BFS-CTC 汉语句义结构标注语料库构建方法[J].北京理工大学学报,2012,32(3):311-315.LUO Sen-lin,LIU Ying-ying,FENG Yang,et al.Method of building BFS-CTC:a Chinese Tagged corpus of sentential semantic structure[J].Transactions of Beijing Institute of Technology,2012,32(3):311-315.
[25]张 华 平.ICTCLAS2013 版 [CP/OL].(2013-11-15)[2015-10-20].http:∥ictclas.nlpir.org/newsdownloads?DocId=352.
[26]BLEI D M,NG A Y,JORDAN M I.Latent dirichlet allocation[J].Journal of Machine Learning Research.2003,3(4/5):993-1022.
[27]中国计算机学会中文信息技术专业委员会.第二届自然语言处理与中文计算会议技术评测结果[CP/OL].(2013-06-15)[2015-10-20].http:∥tcci.ccf.org.cn/conference/2013/pages/page04_evares.html.
[28]LIN C Y.Rouge:apackage for automatic evaluation of summaries[C]∥Text Summarization Branches Out:Proceedings of the ACL-04 Workshop.Barcelona:ACL,2004:74-81.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
成都信息工程大学学报(2022年3期)2022-07-21
软件(2020年3期)2020-04-20
开放教育研究(2020年2期)2020-03-31
计算机与数字工程(2018年5期)2018-05-29
计算机测量与控制(2018年3期)2018-03-27
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
汽车与新动力(2014年6期)2014-02-27
汽车与新动力(2014年5期)2014-02-27
