
基于多准则的组合预测模型权重研究及其应用
2015-10-10 07:54黄仁东张海彬杨志辉周扬张攀
中南大学学报(自然科学版) 2015年5期
黄仁东,张海彬,杨志辉,周扬,张攀
基于多准则的组合预测模型权重研究及其应用
黄仁东1,张海彬1,杨志辉2,周扬1,张攀1
(1. 中南大学资源与安全工程学院,湖南长沙,410083;2. 中南大学冶金与环境学院,湖南长沙,410083)
针对传统组合预测模型大多是通过建立单一准则方程进行优化,而没有更好地考虑各单一模型之间互支持信息带来的不确定性问题,建立基于多准则的组合预测模型权重确定算法。首先,通过建立区间数模型构建样本区间距离并进行相关折算归一化生成样本的基本概率分布BPA(basic probability assignment),作为单一预测模型的初级权重;然后,通过对D-S证据理论进行改进,建立证据可信度、证据精度和证据自冲突系数3个准则分别用于评价单一模型自身精度及其之间互相支持信息,通过对3个准则排序得到综合排序值作为单一模型初级权重的权重调整系数;最后,综合多时刻数据归一化后确定单一模型的最终权重用于组合预测。研究结果表明:经过权重调整后的组合预测精度得到显著提高,且经过调整系数调整后的不变权组合预测模型最优。
组合预测;证据理论;权重调整系数;可信度;证据精度;自冲突系数
预测是随着社会发展而产生的,随着人们对生产和生活要求的提高,传统的单一预测模型自身存在的局限性显得愈明显。任何事物通常都是与周围多种事物相互影响、相互制约的,而传统的单一预测模型通常是在一定的假设条件下进行,这也就使得单一模型不能全面反映事物的信息。信息的缺失造成预测结果出现误差,而这些误差常常会给问题决策带来严重的影响。为了解决单一模型误差大的问题,Bates等[1]提出将多种单一模型结合起来的组合预测模型。组合预测方法是通过建立多种不同的单一预测模型,然后通过对各单一模型的预测结果进行一定加权组合得到最终预测结果。组合预测模型的研究重点在于单一模型权重的确定,目前大多是通过建立一定的目标准则而对组合模型进行优化确定权重。不同的准则可以得到不同的权重分配结果。然而,不同的准则都存在相应的缺陷,如预测误差平方和准则作为判定模型预测精度的重要指标常常会因异常数据造成较大的偏差。针对不确定性误差问题,出现了多种理论如证据理论、灰色理论、模糊理论、粗糙集理论等[2]。其中,证据理论由于满足比概率论更弱的先验概率要求,在模式识别、决策分析以及趋势分析等多源信息融合领域得到广泛应用。而传统的证据理论在确定组合预测权重时通常是通过目标准则计算权重,然后,将权重迭代融合得到最终权重[3]。这种单一的迭代融合在一定程度上有效,然而,由于其很少考虑模型权重之间互相影响的因素,在面对有冲突的证据体时效果不是很好。为了解决这些问题,本文作者采用证据理论建立基于多准则排序证据组合预测模型权重确定算法,通过对证据体建立多准则评价,综合考虑多种数据源自身信息以及相互之间的互支持信息,确定模型的调整系数,对模型初级权重进行调整,利用多时刻数据确定模型的最终权重,最后根据确定的权重与单一模型预测值确定最终组合预测值。该算法不仅可以用于权重的确定,而且可以作为挑选单一模型的依据。
1 组合预测模型原理
本文组合预测模型原理见图1。预测模型可以分为4部分,预测基本流程如下。
第1步,单一预测模型的选择。确定模型类型及其参数。
第2步,单一预测模型初级权重的生成。利用单一预测模型预测结果与相应时刻训练样本真值区间之间的距离作为度量单一预测模型预测精度的参数,通过相似性转换归一化后作为下一步证据理论要用的基本概率分配BPA,其中BPA矩阵中对于B区间的mass函数值作为单一模型的初级权重。
第3步,计算权重调整系数。利用证据可信度、信任精度和证据自冲突系数3个准则综合评判证据体的优劣,对各准则进行排序融合得到证据体的综合排序值作为单一模型的权重调整系数,以减小证据冲突造成的直觉悖论。
第4步,最终的组合预测。利用第3步中改进的证据理论方法求得的调整系数对第2步BPA矩阵中的单一模型初级权重进行调整,确定最终单一模型权重,并进行预测。

图1 基于多准则排序证据组合预测模型流程图
2 理论基础
2.1 组合预测模型
组合预测模型[4]是通过将多个单一预测模型的预测值进行适当加权平均得到最终组合预测结果。
假设种单一预测模型个时刻的预测矩阵为
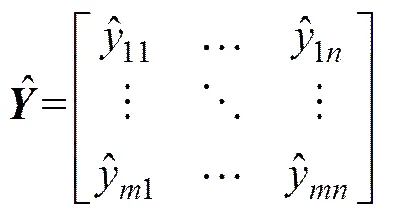
组合预测模型的重点在于计算各个单一模型分配的权重,目前主要有2种方法:第1种是通过拟合实际值分配权重使得加权后预测值与实际值拟合残差最小,此法只针对所建的目标准则进行评价,不够全面;另一种是通过对各个单一模型评价综合信息得到权重。本文基于第2种方法通过不同指标对单一模型进行评价,再分析相互之间影响,以综合确定最终单一模型权重。
2.2 证据理论
D−S理论[5]用一个具有互斥和可穷举元素的集合作为它的识别框架(也称为论域),通常用表示,记为:。在识别框架上的BPA是1个的函数,称为mass函数,并且满足且。对于,上的个mass函数1,2, …,m的Dempster合成规则为
其中:为归一化常数,其作用是为了避免在合成时将非零概率赋给空集[6]。
证据理论的关键在于基本概率分配的准确性和证据合成规则的合理性2个方面,本文基于这2点分别采用区间数基本概率指派生成方法提高BPA的准确性,减小传统专家法带来的高冲突问题;同时,利用多指标排序融合方法改进Dempster组合规则,以减小证据组合规则自身存在的问题。
3 新型组合预测模型的建立
3.1 单一模型的选择
从组合预测模型的组成可以看出组合模型包括2个方面:一个是单一预测模型,另一个是相应的权重系数。这2个元素的选择都与最终预测结果直接相关,好的单一模型和合适的权重分配非常重要。
单一模型的选择主要是从模型精度、模型的相关度以及模型的数量3方面综合考虑。好的模型精度对于结果的预测至关重要,较小的模型之间预测误差相关性可以减少组合误差,同时模型的数量过多造成计算量大,而预测结果精度随模型数量的增多可能提高并不大,数量少可能造成预测效果不好。
基于以上考虑,结合软件EViews[7]和Matlab[8]进行优化,本文选择ARMA(2,2),Holt-Winter-No seasonal(=1,=0)指数平滑法和G(1,1)模型作为单一预测模型。ARMA模型对于模型线性部分有很好的分析效果,指数平滑法主要分析模型的非线性部分产生的影响,灰色模型则是针对整个模型进行整体分析。
3.2 单一模型初级权重的确定
3.2.1 样本数据的三区间划分
为了分析单一预测模型与真值样本的相似性,需确定单一模型的预测值与真值的偏差。本文将真值样本按照
进行分解,这样将每一时刻的真值样本分解成1个以真值为中心点向两边扩散的3个区间识别框架,通过计算单一模型预测值落在每个区间的平均距离用于度量单一预测模型的精度,并经过折算生成证据理论的BPA。根据模型权重与基本概率分配的相似性,以最接近样本真值的B区间的mass函数值(B)作为单一模型的初级权重,通过多种准则对,和3个区间相互之间的关系进行综合评价,求单一模型的权重调整系数,以×调整模型初级权重,归一化后作为单一模型最终权重。
3.2.2 区间数基本概率指派生成
应用证据理论的第1步就是确定证据的基本概率分配,这也是证据理论中最重要的一步。据基本概率分配的准确度直接确定下一步证据合成结果。目前确定基本概率分配的方法一般分为两大类:第1类主要是根据专家经验主观确定基本概率分配;第2类主要是根据已知条件自动生成基本概率分配。为了减小专家因个人经验问题带来的冲突,本文采用智能化区间数模型生成基本概率分配BPA。区间数只要求给定上、下限2个数据, 建模简单易行,除了可以减少专家打分法带来的高冲突问题外,还可以很好地描述信息缺乏不确定度高的应用场合[9]。
应用区间数模型建立单一模型初步权重的步骤如下。
第1步:建立区间数模型。按照式(3)将真值样本进行区间分割,每一时刻的数据分为3个区间,作为测度单一模型准确度的度量区间。
第2步:计算单一模型预测值与区间数模型之间的距离。根据文献[10]可利用

第3步:计算单一模型预测值与区间数模型之间的相似性。根据文献[11]定义区间数相似度为
利用式(6)将得到的距离矩阵转化为相似度矩阵。
第4步:归一化处理得到基本概率分配BPA矩阵。对第3步中得到的相似度矩阵按照式(7)进行归一化处理,得到相应的BPA矩阵。
其中:=,,。
根据BPA与权重的相似性,本文将得到的BPA矩阵作为单一模型时刻点的初级权重,用于后续融合,确定最终权重。
3.3 权重调整系数的确定
证据理论在信息融合领域中具有重要地位,而传统的Dempster组合规则在遇到冲突证据时常常出现一些违背直觉的悖论,如冲突悖论[12]、信任偏移悖论、证据吸收悖论和焦元基模糊悖论等。对于这些冲突问题,主要有2种改进思路:一种是对证据组合规则进行改进,Florea等提出了一种鲁棒的证据组合规则,将交运算和并运算结合起来[13];另一种是对证据体进行改进,通常先对证据进行预处理,再进行证据组合,代表性的研究成果有Murphy等的研究[13−14]。
单纯的改进证据组合规则或者改进证据体都存在一定缺陷,单一的准则往往只能反映证据体的不同侧面,不能全面反映证据体的优劣。为了有效地解决证据冲突问题,本文综合采用证据可信度、证据精度[14]和证据自冲突系数[15]这3种指标对不同证据进行测度,并排序融合作为权重调整系数[13]。
衡量证据之间冲突主要是通过证据距离来衡量,目前主要的证据距离公式有欧氏距离、马氏距离和余弦距离。这些距离没有考虑基本概率分配函数包含的信息量即“势”对信息提取的影响[16],本文采用Jousselme等[17]提出的可以解决上述问题的证据距离算法,通过将证据体视作向量来表示证据体之间的距离:
利用式(8)的证据距离定义证据体被支持程度为

经综合考虑,认为证据的受支持程度越高,可信度越大。定义证据体的证据可信度为
证据可信度描述了证据体之间相互支持的程度。为了描述证据自身的不确定性,定义证据精度为
Dempster合成规则中为归一化常数,而将1−视作证据冲突项,与式(7)的Jousselme距离一样描述证据冲突,但是并不能全面描述。本文采用文献[14]中的证据自冲突系数表征证据体的自冲突程度。
其中:m为单点焦元函数,且;系数2的作用是为了使自冲突系数的取值范围为[0,1]。
本文综合采用式(11),(12)和(13)的证据可信度、证据精度和证据自冲突系数来综合评价证据体,参考文献[15]并按照式(14)进行排序。
将所得的排序序列按照加权求和作为证据时刻点综合排序值,以此综合排序值作为模型的权重调整 系数:
利用式(7)计算的区间基本概率分布与式(15)计算的证据权重调整系数按照下式归一化计算求得不同单一模型的最终权重:
3.4 最终融合预测
将按照式(16)求得的不同单一模型最终权重代入式(1)进行组合预测并分析。
4 实例分析
选用2011−06—2013−01的金属镧月平均价格作样本数据,根据模型选择原则,结合EViews和Matlab软件进行优选,最终选择ARMA(2,2),Holt-Winter-No seasonal(=1,=0)指数平滑法和G(1,1)模型作为单一预测模型。
式(3)将真值样本时刻点数据分解为以3个区间数为元素的识别框架,所以,式(8)中的为×矩阵,经计算可得对称矩阵为
为评价预测模型的效果,分别选择平均绝对百分比误差(MAPE)、均方根误差(RMSE)和均方百分比误差(MSPE)这3个指对模型进行评价。单一预测模型预测结果见表1。

表1 金属镧价格预测及分析结果
从表1可以看出:G(1,1)模型预测效果最优,ARMA(2,2)效果相对最差,而Holt-Winter-No seasonal (=1,=0)指数平滑法预测效果中等。
针对样本数据,本文研究调整系数、区间划分以及权重是否变化对组合预测结果的影响。
当没有调整系数时,直接以(B)作为单一预测模型最终权重,结果指标见表2。从表2可以看出:可变权模型预测效果要优于不变权模型的可变权模型预测效果。

表2 无调整系数组合预测结果
为了分析式(15)调整系数的合理性,根据证据体证据信任度和证据精度与融合结果正相关,而证据自冲突系数与融合结果反相关,另外定义第2种调整系数为
区间的划分也会对最终结果产生影响,不同的区间会产生不同的(B),本文分2种情况探讨等区间划分和不等区间划分。
对不同区间划分和调整系数组合方式进行组合预测,不变权组合预测模型权重见表3,预测结果评价指标见表4~5。

表3 不变权组合模型权重

表4 区间划分(a)组合预测分析结果

表5 区间划分(b)组合预测分析结果
从表4~5可以看出:可变权组合模型的预测结果要优于不变权组合模型预测结果。分别对比表4和表5发现:采用可变权组合模型时,调整系数比调整系数有更好的效果;当采用不变权组合模型时,利用调整系数比调整系数有更好的效果。不等区间划分的比等区间划分效果较好。这是因为中间不等区间划分时,区间的划分更集中于样本真值,具有更好的单一模型初级权重(B)。
虽然可变权组合模型的预测效果要优于不变权模型的预测效果,但在实际使用过程中,由于可变权重是随时间变化的,对于后期的预测还需要提前预测权重,这就增加了模型的不确定性,所以,在实际中采用不变权组合模型更加实用。对比表2~5中不变权可以发现:经过调整系数处理后的预测结果要明显优于调整系数和无调整系数处理过的结果,这也证明了本文权重调整方法的优越性。
综上所述可知:选用不变权、以为单一模型权重调整系数且识别框架中间区间越趋近于真值样本的模型,最后的组合预测结果效果更实用、更精确。
5 结论
1) 本文通过优选利用ARMA(2,2),Holt-Winter- No seasonal(=1,=0)指数平滑法和G(1,1)模型对金属镧月平均价格进行训练预测,然后通过区间数模型处理预测数据生成证据理论所需的BPA,以基于样本时刻点数据的BPA值作为单一模型的初级权重,再利用证据可信度、证据精度和证据自冲突系数这3个准则分析BPA矩阵各证据体之间的互支持信息对单一模型进行综合评价,对最终的指标排序值进行处理生成单一模型的权重调整系数,最终经过归一化处理得出各组合预测模型最终权重,并进行预测。
2) 通过考虑单一模型之间的互支持信息对模型初级权重进行调整,并且选择合适的调整系数,区间划分方式都将对组合预测结果产生明显影响。本文提出的基于多准则排序证据组合预测模型权重确定算法可以显著提高组合预测模型预测精度。
[1] Bates J M, Granger C W J. The combination of forecasts[J]. Operational Research Society, 1969, 20(4): 451−468.
[2] 邱望仁, 刘晓东. 基于证据理论的模糊时间序列预测模型[J]. 控制与决策, 2012, 27(1): 99−103. QIU Wangren, LIU Xiaodong. Fuzzy time series model for forecasting based on Dempster-Shafer theory[J]. Control and Decision, 2012, 27(1): 99−103.
[3] 吴京秋, 孙奇, 杨伟, 等. 基于D−S证据理论的短期负荷预测模型融合[J]. 电力自动化设备, 2009, 29(4): 66−70. WU Jingqiu, SUN Qi, YANG Wei, et al. The short-term load forecasting based on D−S evidential theory[J]. Electric Power Automation Equipment, 2009, 29(4): 66−70.
[4] 戴华娟. 组合预测模型及其应用研究[D]. 长沙: 中南大学数学与统计学院, 2007: 6−24.. DAI Huajuan. Research on combination forecast and its application[D]. Changsha: Central South University. School of Mathematics and Statistics, 2007: 6−24.
[5] 韩崇昭, 朱洪艳, 段战胜, 等. 多源信息融合[M]. 2版. 北京: 清华大学出版社, 2010: 82−92. HAN Chongzhao, ZHU Hongyan, DUAN Zhansheng, et al. Multi-source information fusion[M]. 2nd ed. Beijing: Tsinghua University Press, 2010: 82−92.
[6] 叶清, 吴晓平, 宋业新. 基于权重系数与冲突概率重新分配的证据合成方法[J]. 系统工程与电子技术, 2006, 28(7): 1014−1016, 1081. YE Qing, WU Xiaoping, SONG Yexin. Evidence combination method based on the weight coefficients and the confliction probability distribution[J]. Systems Engineering and Electronics, 2006, 28(7): 1014−1016, 1081.
[7] 易丹辉. 数据分析与EViews应用[M]. 北京: 中国人民大学出版社, 2009: 98−148. YI Danhui. Data analysis and application of reviews[M]. Beijing: Renmin University of China Press, 2009: 98−148.
[8] 张志涌. 精通MATLAB(6.5版)[M]. 北京: 北京航空航天大学出版社, 2006: 27−85. ZHANG Zhiyong. Proficient in MATLAB(Version 6.5)[M]. Beijing: Beihang University Press, 2006: 27−85.
[9] Wan S P. Interval number method for object threat assessment[J]. Computer Engineering and Applications (China), 2009, 45(6): 32−34.
[10] Tran L, Duckstein L. Comparison of fuzzy numbers using a fuzzy distance measure[J]. Fuzzy Sets and Systems, 2002, 130(3): 331−341.
[11] 康兵义, 李娅, 邓勇, 等. 基于区间数的基本概率指派生成方法及应用[J]. 电子学报, 2012, 40(6): 1092−1096. KANG Bingyi, LI Ya, DENG Yong, et al. Determination of basic probability assignment based on interval numbers and its application[J]. Acta Electronica Sinica, 2012, 40(6): 1092−1096.
[12] Zadeh L A. Review of a mathematical theory of evidence[J]. AI Magazine, 1984, 5(3): 81−83.
[13] Powell G, Roberts M. GRP1. A recursive fusion operator for the transferable belief model[C]// Proceedings of the 14th International Conference on Information Fusion. Chicago, USA: IEEE, 2011: 168−175.
[14] Smarandache F, Martin A, Osswald C. Contradiction measures and specialty degrees of basic belief assignments[C]// Proceedings of the 14th International Conference on Information Fusion. Chicago. USA: IEEE, 2011: 475−482.
[15] 杨艺, 韩德强, 韩崇昭. 基于多准则排序融合的证据组合方法[J]. 自动化学报, 2012, 38(5): 823−831. YANG Yi, HAN Deqiang, HAN Chongzhao. Evidence combination based on multi-criteria rank-level fusion[J]. Acta Electronica Sinica, 2012, 38(5): 823−831.
[16] 于东平, 段万春, 孙永河. 基于最优权重的多源证据加权平均合成算法研究[J]. 统计与决策, 2011(10): 16−19. YU Dongping, DUAN Wanchun, SUN Yonghe. Research on weighted average algorithm of multi-source evidence based on optimal weight[J]. Control and Decision, 2011(10): 16−19.
[17] Jousselme A L, Grenier D, Bossé É. A new distance between two bodies of evidence[J]. Information Fusion, 2001, 2(2): 91−101.
Research and application of multi-criteria combination forecast model
HUANG Rendong1, ZHANG Haibin1, YANG Zhihui2, ZHOU Yang1, ZHANG Pan1
(1. School of Resources and Safety Engineering, Central South University, Changsha 410083, China;2. School of Metallurgy and Environment, Central South University, Changsha 410083, China)
Considering that most of traditional combination forecast models are established by criterion of single equation regardless of information between individual model which implicits lots of uncertainty, a weight determination algorithm of combination forecast model was presented based on multi-criteria information. Firstly, interval numbers model was built to getthe sample BPA matrix as the primary weight of the single models by a series of distance calculations between the true data and the predictive value. Then, three criteria, i.e. evidence credibility, evidence precision and evidence contradiction, were set up to evaluate the precision of individual model and information between them. By sequencing the above three criteria, a composite sort value called weight adjustment coefficient was generated to adjust the primary weight of the single models. Finally, the final weight was determined by normalizing the multi-time weight data used for combination forecast. The results show that the precision of the method is high, one fixed weight combination forecast model adjusted by weight adjustment coefficientis the best.
combination forecast; evidence theory; weight adjustment coefficient; credibility; evidence precision; evidence contradiction
10.11817/j.issn.1672-7207.2015.05.028
TD983
A
1672−7207(2015)05−1778−08
2014−06−12;
2014−08−22
国土资源部公益性行业科研专项课题(201211067-3) (Project(201211067-3) supported by Public Service Industry Special Scientific Research of Ministry of Land and Resources)
黄仁东,教授,从事矿产安全开采理论与技术研究;E-mail: hldlb@163.com
(编辑 陈灿华)
猜你喜欢
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
中国注册会计师(2021年10期)2021-11-22
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
中国外汇(2019年13期)2019-10-10
小天使·一年级语数英综合(2019年2期)2019-01-10
消费导刊(2017年24期)2018-01-31
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
共产党员(辽宁)(2015年24期)2015-10-18
消费导刊(2014年12期)2015-02-13
