
局部保持“字典对”学习算法及其应用
2015-11-21 05:37郭艳卿王久君
信息安全研究 2015年1期
郭艳卿 王久君 郭 君
(大连理工大学信息与通信工程学院 大连 116024)
局部保持“字典对”学习算法及其应用
郭艳卿 王久君 郭 君
(大连理工大学信息与通信工程学院 大连 116024)
(guoyq@dlut.edu.cn)
字典学习(DL)方法近年来被广泛应用于解决各种计算机视觉领域的问题.现有的大部分字典学习算法均旨在学习一个综合型字典来表示输入信号,并使表示系数或表示误差具有一定的判别能力.这些字典学习算法大都需要对稀疏表示系数采用l0或者l1范数的约束,所以学习过程比较耗时.解析型字典学习的提出较为有效地解决了字典学习算法效率低的问题.在分类识别任务中,联合学习一个综合型字典和一个解析型字典正在成为一个热门的研究趋势,这不仅很大程度上降低了学习过程中的计算复杂度,而且在分类识别性能上也能有一定的提升.借鉴了最新提出的“字典对”学习思想,利用训练数据的局部结构信息,提出了局部保持的综合型-解析型“字典对”学习算法.在3个国际公开测试数据库(人脸识别库Extended YaleB、AR和图像分类库Caltech101)上的实验结果表明,局部保持的综合型-解析型“字典对”学习算法在准确率和效率方面都具有很好的性能.
字典学习;综合型-解析型字典对;局部保持;分类;识别
近年来,基于过完备字典的稀疏模型在图像处理和计算机视觉领域中得到了广泛的应用.该模型的核心就是利用过完备字典中的少量原子的线性组合尽量精确地描述信号[1].这种能够描述信号的字典又被称为综合型字典.最初提出的传统字典模型并不是应用于分类识别的,而是用于解决信号重构的相关问题.为了试图利用字典学习来解决分类识别问题,研究者们提出了多种方法,这些方法可以将传统的字典学习修正为比较适合于分类识别任务的监督字典学习.典型的基于字典学习的分类识别方法大致可以分为2类:一类是直接学习具有判别力的字典,利用表示误差来进行最终的判决,其中具有代表性的方法有Meta-face学习[2]和结构不相干的字典学习(DLSI)[3];另一类是稀疏化系数,使得到的字典更具可判别力,利用稀疏系数作为新的用于分类识别的表示特征,该类别中具有代表性的方法有监督字典学习[4]、判决KSVD(D-KSVD)字典学习[5]、标签一致的KSVD[6]和基于Fisher准则的字典学习(FDDL)[7].
在传统的基于字典学习的分类识别方法中,通常都是利用综合型字典和稀疏系数来表示一个信号,因此需要对编码系数增加lp范数的约束(其中p≤1),而这种范数约束的特点是计算复杂度较高.又因为稀疏编码系数越稀疏分类识别结果越准确,所以在大部分的字典学习算法中,正则化稀疏表示系数均采用l0或者l1范数约束.易知,在字典学习的迭代过程中通常含有稀疏编码的步骤,即每次迭代都需要处理编码系数的l0或者l1范数,因此,这类算法的计算量都比较大,样本训练和测试的效率都比较低.
在字典学习算法的效率提升研究方面,解析型字典学习逐渐引起广大学者的关注.它是综合型字典学习的对偶形式,核心思想是学习一个映射矩阵,使得信号在新的映射空间进行表示时能够具有稀疏性.目前,这种模型还没有较多地应用到分类识别问题.最初,Gu等人[1]提出了DPL(dictionary pair learning)算法,该算法同时学习一个综合型字典和解析型字典.其中,训练得到的综合型字典用来实现特定类别的判别重构,而训练得到的解析型字典通过对原始数据样本进行线性映射来产生编码系数,因而通过对解析型字典的约束就可以取代对稀疏编码系数的l0或者l1范数约束,进而提升算法的效率.然而,DPL算法虽然提高了算法的整体运行效率,在准确率上也有很好的竞争力,但是该算法忽略了训练数据的局部特征对于分类识别的意义,本文在此基础上提出了局部保持的综合型-解析型字典对学习算法.该算法将字典对和训练样本的局部结构信息融合在一个学习框架内,既提升了算法的分类识别准确率,也保证了算法的高效性.本文在3个国际公开测试图像库上验证了本文所提出算法的性能.
1 相关的字典学习算法
本节将介绍几种相关的字典学习算法.
1.1 综合型字典学习算法
最初提出的DL模型并非应用于分类识别,而是应用于解决信号重构的相关问题.学习一个自适应的过完备字典,就是提供一个基本的集合,利用这个集合中的少量原子的线性组合可以近似描述一个输入信号.
设一个样本集合为X=[x1,…,xi,…,xN],其中xi是样本集中的第i个样本.解析型字典学习方法旨在得到一个综合型字典D和编码系数A对样本进行重构表示,其过程可由式(1)实现:
(1)
其中,编码系数矩阵A=[a1,…,aN],ai是矩阵A的第i个列向量.矩阵A的1范数等价于A的各个列向量的1范数之和.
上述的传统的综合型DL方法并不是应用于分类识别的,所以其在处理分类识别问题时产生的结果并不理想.为了专门解决分类识别问题,科研工作者们提出了有判别力的字典学习算法.
设X=[X1,…,Xk,…,XK]是所有类别的训练样本的集合,每个样本均是p维的特征,一共K个类别,Xk∈p×n是第k个类别的训练样本的集合,n是每个类别中训练样本的数量.利用训练数据的类别信息可以提升综合型字典D的判别能力,进而改善传统算法的分类识别性能,其表现在目标函数中是对D增加一个约束,可表示为式(2)模型:
(2)
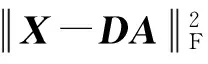
上面已经提到,基于综合型DL的分类识别方法大致可以分为2类:一类是直接学习具有判别力的字典,利用各自的重构误差即可进行分类识别;另一类是通过提升稀疏表示系数的判别力来增强字典的判别力,并利用稀疏系数作为分类识别的新特征.无论是哪一类方法都需要对编码系数矩阵A增加l0或者l1范数的稀疏正则项约束,进而导致算法的计算量较大,效率过低.
为了解决上述由于l0或者l1范数的稀疏正则项而产生的效率过低问题,解析型字典学习应运而生.它通过学习一个映射矩阵,使得信号在新的映射空间具有稀疏的特性.这种模型还没有较多地应用到分类识别问题.Gu等人[1]提出了DPL模型,联合学习综合型字典D和解析型字典P.在DPL模型中,由于编码系数可以由解析型字典P映射得到,于是系数矩阵A的l0或者l1范数约束就可以被忽略.实验证明,DPL模型明显地提高了训练样本和测试样本的编码效率,同时仍然保持着较高的分类识别准确率.
1.2 DPL算法的基本原理
结构化的综合型字典D=[D1,…,Dk,…,DK],结构化的解析型字典P=[P1;…;Pk;…;PK],则第k类样本集合对应的子字典对为{Dk∈p×m,Pk∈m×p},这种字典对也叫作综合型-解析型字典对.稀疏子空间聚类[8]的相关研究已经证明,如果输入数据满足特定的不相干条件,则不同类别的样本可以由它相应的字典表示.由于解析型字典P是结构化的,所以我们希望解析型子字典Pk对类别i(i≠k)中样本的映射集合近似为空集合,即
PkXi≈0,∀k≠i.
(3)
由式(3)可知,系数矩阵PX是分块对角矩阵.此外,结构化的综合型字典D的子字典Dk可以通过映射得到的系数矩阵PkXk重构数据矩阵Xk.由综合型-解析型字典对表示的重构误差的最小化公式可表示为
(4)
继而得到下面的映射字典对模型:
(5)

Gu等人[1]已经证明,基于DPL算法的分类识别方法不仅有较高的分类识别准确率,还有非常高的运行效率.
2 局部保持“字典对”学习算法
为了提升传统的有判别力的DL算法的分类识别准确率和运行效率,本文提出了局部保持的综合型-解析型字典对学习算法,这个新提出的算法将高效的综合型-解析型字典对学习算法与训练数据的局部结构信息紧密地结合在一起.
2.1 局部保持约束
设N(xi)是样本xi的C近邻的集合,并且这C个近邻指选自样本xi所在的类别集合的样本,近邻数量C可以根据需要设定.为了保持训练样本的局部近邻信息,需要样本xi的编码系数ai在空间距离上接近同类别样本的编码系数.又因为任意的样本xj距离样本xi的空间距离越远,则对样本xi的影响越小,即任意2个样本之间的权重函数w(xi,xj)与2个样本向量之间的空间距离成反比,所以我们定义2个样本之间的权重函数为
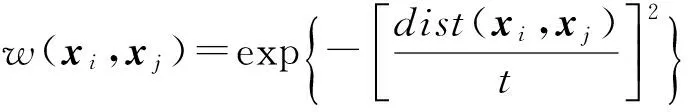
(6)
其中,dist(xi,xj)表示样本xi和样本xj之间的欧氏距离,参数t可以调整权重函数的衰减速度,不失一般性,本文设置t的值为1.
权重矩阵Wi j定义为
(7)
为了能够保持训练样本的局部结构信息,编码系数A应该满足下述的优化目标函数:
(8)
其中,编码系数A=[a1,…,aN].
2.2 局部保持的综合型-解析型字典对学习算法
基于上述的介绍,局部保持的综合型-解析型字典对学习算法的目标函数可以表示为
(9)
其中,lk是第k类的训练样本的个数.
利用图论里关于拉普拉斯矩阵的定义与性质,可以在目标函数(9)中引入拉普拉斯矩阵,得到的化简公式如下:
(10)
其中,Lk为拉普拉斯矩阵,τ,λ和β均为标量参数.这3个参数数值的选择对模型的训练有很直接的影响,后面的实验部分会介绍最终确定的最优参数组合.由于矩阵的迹与矩阵的Frobenious范数在特定条件下可以互相转换,因而式(10)的目标函数很容易求解.首先初始化综合型字典D和解析型字典P,令2个字典的初始矩阵是Frobenious范数等于1的任意矩阵,然后交替更新编码系数矩阵A和综合型-解析型字典对{D,P}.通过交替执行以下步骤即可得到目标函数(10)的最优解.
1) 固定D和P,更新A:
(11)
这是一个标准最小平方问题,可以得到闭式解:
(12)
2) 固定A,更新D和P:
(13)
由式(13)可以得到解析型字典P的闭式解:
(14)
其中γ=10-4是一个比较小的常数,I是单位阵,γI是为了保证求逆运算有解而增加的.求D的最优解相对复杂,引入一个变量S后,D的优化问题可以表示为
(15)
利用ADMM算法可以求得问题(15)的最优解:
(16)
其中,参数ρ可适当进行调整.
综上所述,求解优化函数(10),变量A和P均可得到闭式解,利用ADMM方法求D的优化结果是迅速收敛的.算法1给出了局部保持的综合型-解析型字典对学习算法的实现流程.当相邻两次迭代的结果差值小于0.01时,迭代停止.优化结果输出的解析型字典P和综合型字典D可用于之后分类识别的判决.
算法1. 局部保持的综合型-解析型字典对学习算法.
输入:K个类别的训练样本特征X=[X1,…,Xk,…,XK],参数m,τ,λ,β,C,t;
输出:解析型字典P,综合型字典D.
① 初始化D(0)和P(0),初始为Frobenious范数为1的随机矩阵;
② WHILE 不收敛 DO
③ FORi=1:KDO
④ 根据式(12)更新Ak;
⑤ 根据式(14)更新Pk;
⑥ 根据式(16)更新Dk;
⑦ END FOR
⑧ END WHILE
2.3 分类识别方法的实现

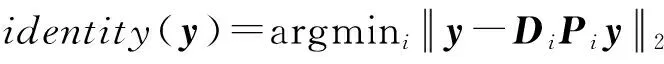
(17)
由式(17)可知,基于局部保持的综合型-解析型字典对学习算法的分类器的参数只需给定综合型字典D和解析型字典P即可,所以在获得各个类别的最优综合型子字典和最优解析型子字典后,就能得到分类器的模型,从而可以对测试图像进行分类识别.
3 实验及结果
3.1 实验设置及比较算法
本文选择3个数据库来评估局部保持的综合型-解析型字典对学习算法的分类识别性能,分别是2个人脸库(Extended YaleB人脸库和AR人脸库),以及一个目标库(Caltech101库).在这3个数据库中,本文将所提出的算法与许多效果较好的分类识别算法进行了比较,包括基本的最近子空间分类器(NSC)、线性支持向量机(SVM)、稀疏表示分类(SRC)和协同表示分类(CRC),以及最先进的DL算法DLSI,FDDL,LC-KSVD.对比内容不仅有分类识别准确率,还有训练时间和测试时间.由文献[1]可知,Gu等人提出的DPL算法具有最高的效率,因此本文提出的算法的效率仅与DPL算法的效率进行比较.对比实验的软硬件环境为:工作频率为2.6 GHz、内存为128 GB的服务器; MATLAB R2013a计算平台.
在实验中,本文直接利用文献[9]中Jiang等人提取好的特征进行训练和分类识别,各个比较算法中的实验设置均与文献[9]中的设置一致.本文所提出的局部保持的综合型-解析型字典对学习算法在各个图像库中的参数设置如表1所示:

表1 本文算法的主要参数
3.2 分类识别性能的比较结果
3.2.1 Extended YaleB库的实验结果
Extended YaleB数据库中有38人的人脸图像,共2 414张.在每个类别中,随机选择32张人脸图像作为训练样本,剩下的作为测试样本.在其他对比的DL算法中,每个类别的综合型子字典的原子数都设为32.Jiang等人[9]提供的Extended YaleB库的图像特征是504维的.如表2所示,与各个算法相比,在Extended YaleB库中,本文所提出的算法得到了最高的分类识别准确率.表3表明该算法的运行效率与DPL算法相当,且均远高于其他算法.

表2 在3个数据库上的分类识别准确率比较 %
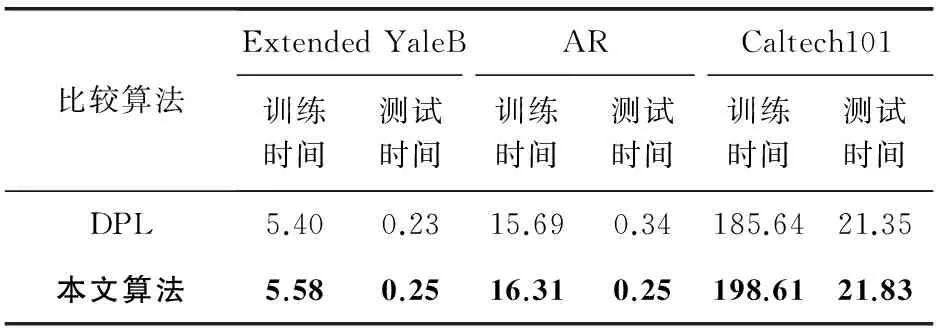
表3 在3个数据库上的运行时间比较 s
3.2.2 AR库的实验结果
AR数据库共有2 600张人脸图像,其中男女各50人,共有100类,每个类别中有26张图像.在每个类别中,随机选择20张图像作为训练样本,剩下的6张图像作为测试样本.在其他对比的DL算法中,每个类别的综合型子字典的原子数设为20.Jiang等人[9]提供的AR库的图像特征是540维的.如表2所示,在AR库中,与其他算法相比,本文提出的算法有最高的分类识别准确率.并且由表3可知,该算法的运行效率与DPL算法的效率非常接近.
3.2.3 Caltech101库的实验结果
Caltech101数据库中共有9 144张图像,分为102个类别(包含101个普通的目标类别和一个背景类别).每个类别中的样本图像数量是不固定的,从31~800不等.在每个类别中随机选择30张图像作为训练样本,剩余图像作为测试样本,在其他对比的DL算法中,每个类别的综合型子字典的原子数设为30.该实验利用标准的词包(BOW)+空间金字塔匹配(SPM)来提取Caltech101库中图像的特征.在3种不同大小的网格中提取SIFT算子来计算SPM特征,3种网格分别是1×1,2×2和4×4的.此外,采用基于编码方式的矢量量化来提取中层特征,并用标准的最大池化方式来建立高维的池化特征.最后,通过主成分分析(PCA)将原始21 504维的高维数据降到3 000维.实验结果如表2、表3所示,本文的方法依然可以达到DPL算法的性能.
4 结 论
本文将高效的综合型-解析型字典对学习算法与训练数据的局部结构信息结合在一个框架内,提出了局部保持的综合型-解析型字典对学习算法,并将其应用在分类识别问题上.局部保持的综合型-解析型字典对学习算法将综合型-解析型字典对学习和训练数据的局部结构关系结合在一起,每一步都能够利用闭式解或快速迭代解,保证了该算法的高效性和准确率.在3个国际公开测试图像库中的分类识别实验充分证明了本文的算法在解决人脸识别和图像分类等问题上具有很好的性能,保持训练样本的局部结构信息可在一定程度上提高分类和识别的准确率.
[1]Gu Shuhang, Zhang Lei, Zuo Wangmeng, et al. Projective dictionary pair learning for pattern classification[C]Advances in Neural Information Processing Systems. Cambridge: MIT Press, 2014: 793-801
[2]Yang M, Zhang L, Yang J, et al. Metaface learning for sparse representation based face recognition[C]Proc of the 17th IEEE Int Conf on Image Processing. Piscataway, NJ: IEEE, 2010: 1601-1604
[3]Ramirez I, Sprechmann P, Sapiro G. Classification and clustering via dictionary learning with structured incoherence and shared features[C]Proc of IEEE CVPR. Piscataway, NJ: IEEE, 2010: 3501-3508
[4]Mairal J, Ponce J, Sapiro G, et al. Supervised dictionary learning[C]Advances in Neural Information Processing Systems. Cambridge: MIT Press, 2009: 1033-1040
[5]Zhang Q, Li B. Discriminative K-SVD for dictionary learning in face recognition[C]Proc of IEEE CVPR. Piscataway, NJ: IEEE, 2010: 2691-2698
[6]Jiang Z, Lin Z, Davis L S. Learning a discriminative dictionary for sparse coding via label consistent K-SVD[C]Proc of IEEE CVPR. Piscataway, NJ: IEEE, 2011: 1697-1704
[7]Yang M, Zhang L, Feng X, et al. Fisher discrimination dictionary learning for sparse representation[C]Proc of IEEE ICCV. Piscataway, NJ: IEEE, 2011: 543-550
[8]Soltanolkotabi M, Elhamifar E, Candes E J. Robust subspace clustering[J]. The Annals of Statistics, 2014, 42(2): 669-699
[9]Jiang Z, Lin Z, Davis L S. Label consistent K-SVD: Learning a discriminative dictionary for recognition[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2013, 35(11): 2651-2664

郭艳卿
博士,副教授,主要研究方向为多媒体信息安全、计算机视觉、模式识别.
guoyq@dlut.edu.cn

王久君
硕士研究生,主要研究方向为图像分类.
jiujun_wang@foxmail.com

郭 君
硕士研究生,主要研究方向为图像分类.
eeguojun@foxmail.com
Locality Preserving Dictionary Pair Learning Algorithm for Classification and Recognition
Guo Yanqing, Wang Jiujun, and Guo Jun
(SchoolofInformationandCommunicationEngineering,DalianUniversityofTechnology,Dalian116024)
Dictionary learning (DL) has been widely applied in various computer vision problems. Most existing DL methods aim to learn a synthesis dictionary to represent the input signal while enforcing the representation coefficients andor representation residuals to be discriminative. However, thel0orl1-norm sparsity constraint on the representation coefficients adopted in most DL methods makes the learning phase time consuming. Hence, a new DL framework, namely analysis dictionary learning, has been proposed to deal with this problem. Besides, jointly learning a synthesis dictionary and an analysis dictionary has also drawn much attention recently, which can not only reduce the time complexity in the learning phase, but also lead to very competitive accuracy in a variety of classification and recognition tasks. This paper is motivated by the recently proposed dictionary pair learning algorithms. Our proposed novel Locality Preserving Discriminative Synthesis-Analysis Dictionary Pair Learning Algorithm integrates the local structure of training data, which is totally ignored in most applications of dictionary pair learning. We evaluate the proposed algorithm on three databases, including two face databases (Extended YaleB and AR) and one image categorization database (Caltech101). Based on the experiment results, we conclude that our algorithm can largely reduce the computational burden and improve the accuracies.
synthesis-analysis dictionary pair learning; Locality preserving; classification; recognition
2015-07-30
国家自然科学基金项目(61402079)
TP391.41
猜你喜欢
家庭影院技术(2020年12期)2021-01-18
中国煤炭工业(2019年3期)2019-08-27
小学阅读指南·低年级版(2019年11期)2019-07-01
民族古籍研究(2018年1期)2018-05-21
小天使·一年级语数英综合(2017年11期)2017-12-05
西夏学(2016年2期)2016-10-26
武昌理工学院学报(2016年2期)2016-10-09
读者(2016年14期)2016-06-29
浙江大学学报(工学版)(2015年1期)2015-03-01
中国工程咨询(2015年5期)2015-02-16
