
基于T-Graph算法的链接和内容相结合的聚焦爬虫模型
2016-04-20 02:50南京航空航天大学
电子世界 2016年6期
南京航空航天大学 周 萍
基于T-Graph算法的链接和内容相结合的聚焦爬虫模型
南京航空航天大学 周 萍
【摘要】聚焦网络爬虫的两大重要目标就是寻找主题相关的网页,并优先下载主题相关度高的网页。首先,读取并分析网页的有效HTML元素,并根据高准确率来预测和抽取每个未被访问的网页的主题内容。然后,根据T-Graph来计算URLs的主题相关度,并按照相关度大小进行排序。本文提出的基于T-Graph的算法综合了多方面的元素,通过实验得到了较高的查准率和查全率,因此,该算法具有重要的意义。
【关键词】聚焦网络爬虫;T-Graph;HTML元素;信息检索;搜索引擎
0 引言
网络爬虫的主要任务是从Web上获取网页文档,并为这些数据创建索引,索引的更新是通过分布式爬行实现的。传统的网络爬虫并不能轻松地扩展爬行,因为Web是不受人为控制的。而且,传统的爬虫也不能根据特定的主题目标建立正确的索引,索引库因此也得不到及时的更新。为了解决这些弊端,具有重要意义的聚焦爬虫应运而生[1]。
1 基于T-Graph算法的聚焦爬虫模型的设计
聚焦爬虫模型的设计主要涉及两个问题,第一个问题就是在下载网页内容之前预估未被爬行的网页的主题目标。本文通过把父网页的HTML标签元素和锚文本想结合,来预测未被访问的链接的主题相关性。第二个问题就是将链接库的URLs按照主题相关度进行排序。本文通过T-Graph(Treasure Graph)来评估URLs的主题优先级,并假定T-Graph的结构是自顶向下的。
1.1 主题相关度的计算
通过数据挖掘来获取主题关键词的方法很多,本文采用了一种既简单又有效的方法,该方法需要综合考虑三个因素。第一,单词的数量决定了主题的重要程度。第二,D-number (Dewey system,杜威十进分类法)的长度决定了主题的精确性。第三,锚文本中的关键词有更高的主题相关性。以上三种因素的影响力比普通文本高40%[2]。
分块计算主题权重的方法相对于同时计算结点的个数、D-number的长度以及锚文本的主题关键词的方法来说,具有重要的意义。而且,相对于异常值检测法来说,该方法能够降低整个系统的计算负担,因为计算过程只是通过简单的字符串过滤来实现的[3]。
如果未被访问的链接具有主题相关性,那么该链接可以利用T-Graph来计算主题相关性。否则,该链接就被赋予较低的优先级。只有这样,主题爬虫才能尽可能多地访问主题相关的网页。
1.2 基于T-Graph算法的聚焦爬虫的框架结构
如图1.1所示,本文提出的Treasure-Crawler系统中,T-Graph的每个节点分别对应着五大模块。其中,Web网页的HTML属性所包含的五大模块如下所示:
(1)简短小节标题(immediate sub-section heading,ISH)。
(2)包含ISH的小节标题(section heading,SH)。
(3)主标题(main heading,MH)。
(4)链接附近的文本数据模块(data component,DC)。
(5)主题信息模块(destination information component,DIC)。
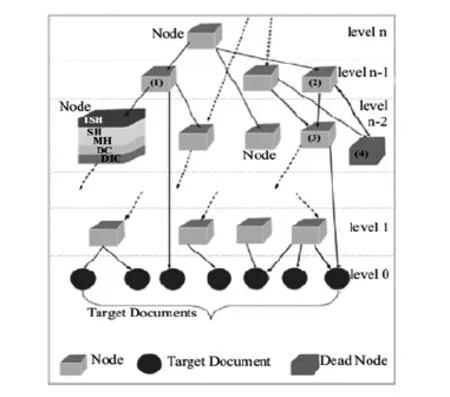
图1.1 T-Graph的分层结构
1.3 链接URLs优先级的计算
爬虫抓取到网页之后,需要对网页的优先级进行计算。评估网页优先级的方法是,根据相似性算法把网页的HTML元素和所有的T-Graph结点作比较。其中,通过使用HTML语法解析器来准确地获取网页的HTML元素。
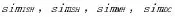
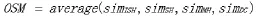
如果节点的OSM值在临界值(设为0.05)之上,那么URL的优先级如下所示:
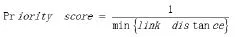
如果节点的OSM值在临界值(设为0.05)之下,那么URL的优先级如下所示:
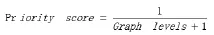
2 系统测试和验证
为了验证系统结构的实用性,根据初始网页建立了T-Graph,并向数据库中输入了相关数据。经过测试和验证,本文提出的Treasure-Crawler系统满足了基本需求,并且具有功能性和实用性。图2.1展示了T-Graph和Context-Graph在召回率方面的对比结果。其中T-Graph(T)表示主题T-Graph,T-Graph(G)表示通用T-Graph。观察曲线图可发现,T-Graph(T)具有较高的召回率。
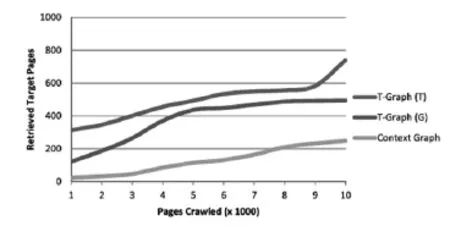
图2.1 网页的召回率(0.5)的增长趋势
3 结论
本文提出的Treasure-Crawler系统架构满足了聚焦网络爬虫的需求,并能够保持系统结构和模型的稳定性。其中,未被访问的URLs的优先级是通过T-Graph的分层结构计算出来的,然后爬虫根据URLs的优先级来确定下一个待访问的URL。
参考文献
[1]季春,姜琴,吴铮悦.垂直搜索引擎关键技术研究综述[J].情报探索,2013(10):91-93.
[2]Jamali M,Sayyadi H,Hariri B B,et al.A Method for Focused Crawling Using Combination of Link Structure and Content Similarity[C]//2006 IEEE/WIC/ACM International Conference on Web Intelligence(WI 2006),18-22 December 2006,Hong Kong, China.2006:753-756.
[3]Wang W,Chen X,Zou Y,et al.A Focused Crawler Based on Naive Bayes Classifier[C]//Proceedings of the 2010 Third International Symposium on Intelligent Information Technology and Security Informatics.IEEE Computer Society,2010:517-521.
[4]Patel A.An Adaptive Updating Topic Specific Web Search System Using T-Graph[J].Journal of Computer Science,2010,79(4):1-4.
[5]Diligenti M,Coetzee F,Lawrence S,et al.Focused Crawling Using Context Graphs[C]//Proceedings of the 26th International Conference on Very Large Data Bases. Morgan Kaufmann Publishers Inc.,2000:527-534.
[6]Passerini A,Frasconi P,Soda G Evaluation Methods for Focused Crawling[C]//Proceedings of the 7th Congress of the Italian Association for Artificial Intelligence on Advances in Artificial Intelligence. Springer-Verlag,2001:33-39.
猜你喜欢
计算机与网络(2022年2期)2022-03-17
科教导刊·电子版(2021年30期)2021-01-03
疯狂英语·新阅版(2020年11期)2020-12-21
山西青年(2018年5期)2018-01-25
新闻传播(2016年18期)2016-07-19
新闻传播(2016年11期)2016-07-10
现代计算机(2016年11期)2016-02-28
中国卫生(2015年12期)2015-11-10
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
科学导报·学术论坛(2013年5期)2013-06-26
