
基于累积运动能量图像的人体动作识别
2016-04-22 00:54谌先敢刘海华高智勇
中南民族大学学报(自然科学版) 2016年1期
关键词:支持向量机
谌先敢, 刘海华, 高智勇
(1中南民族大学 生物医学工程学院, 武汉 430074;2 中南民族大学 医学信息分析及肿瘤诊疗 湖北省重点实验室, 武汉 430074)
基于累积运动能量图像的人体动作识别
谌先敢1,2, 刘海华1,2, 高智勇1,2
(1中南民族大学 生物医学工程学院, 武汉 430074;2 中南民族大学 医学信息分析及肿瘤诊疗 湖北省重点实验室, 武汉 430074)
摘要指出了动作识别中的最大困难是难以提取有效的特征来准确描述人体的动作,动作模板是众多方法中的一种简单有效的方法,用来描述动作特征的经典动作模板是运动历史图像.由于受噪声的干扰,用运动历史图像描述复杂环境下的人体动作并不十分理想.为了得到比运动历史图像更加有效的动作模板,提出了将视频序列中的运动能量信息用一张图描述出来,称之为累积运动能量图像,提取其直方图特征来表征人体动作.经YouTube数据集上的实验表明: 该累积运动能量图像的识别率比同类方法高.
关键词动作识别;累积运动能量图像;方向梯度直方图;支持向量机
Recognizing Human Actions Using Accumulative Motion Energy Image
ChenXian-gan1,2,LiuHaihua1,2,GaoZhiyong1,2
(1 College of Biomedical Engineering, South-Central University for Nationalities, Wuhan 430074,China;2 Hubei Key Laboratory of Medical Information Analysis and Tumor Diagnosis & Treatment,South-Central University for Nationalities, Wuhan 430074,China)
AbstractThis paper points that very difficult to extract effective feature for describing the action of the human body in action recognition. Action template is a simple and effective method to describe the motion characteristics, in which motion history image is classic method. It isn′t satisfactory using motion history image to describe the human action in complex environment due to noise. In order to obtain more effective action template, this paper presents to use an image to describe motion energy in the video sequence, which is called accumulative motion energy image. The histograms extracted from the image are used to represent human action. Experiments on YouTube datasets show that accumulative motion energy image exceed to similar methods in recognition rate.
Keywordsaction recognition; accumulative motion energy image (AMI); histograms of orientation gradients (HOG); support vector machine (SVM)
从视频中识别出人体动作在视频监控、视频检索和人机交互中有广泛的应用,已经成为计算机视觉领域的热点问题.人体动作识别是指用计算机从视频序列中检测、跟踪、识别出人体,并对其行为进行描述和理解.目前,动作识别中的最大困难就是难以准确描述人体的动作.由于个体的差异,同样的动作变化较大,而且人体进行动作时所处的环境也十分复杂,动作本身的速度或者被记录速度也可能是不一样的,所以准确描述人体的动作是十分困难的.这三个因素都会导致同样的动作产生不一样的图像序列,有效的特征提取方法可处理这些因素带来的影响.
目前的动作识别方法有全局方法和局部方法[1],全局方法中有基于动作模板的方法[2]和基于特征空间的方法[3].在众多方法中,动作模板是一类简单有效的方法,其中的经典方法就是运动历史图像(MHI)[2],该方法最明显的优势是能直接整合有力的静态分类器,如支持向量机(SVM)或Adaboost.运动历史图像的思想是将视频序列的帧差信息累积到一帧图像中.帧差包含一定的运动信息,但并未包含运动人体的形状信息,而且也容易受环境噪声的干扰,在现实的复杂环境中并不能非常准确地描述人体的运动.后来,文献[4]提出累积边缘图像的概念,在运动人体的形状边缘上提取信息,来表征人体的动作.但是该方法提取的是视频中的静态边缘信息,用来表征人体的动作也并不完善.
为了得到比运动历史图像和累积边缘图像更加有效的动作模板,本文提出一种有效的运动特征提取方法来表征人体的动作.其基本思想是:将视频序列中的运动信息用一张图描述出来.具体过程如下:使用4个不同方向的时空Gabor滤波器提取运动能量,得到视频中每一帧的运动能量图像,将该运动能量图累积到一帧图像中,将该图像称为累积运动能量图像(AMI),接着,在累积运动能量图像上计算基于网格的方向梯度直方图(HOG),将由这4个不同方向的时空Gabor滤波器得到的累积运动能量图像的HOG特征向量串联起来,形成一个特征向量来表征人体的动作.最后,将该特征向量送入分类器进行分类,识别出人体动作.
1时空Gabor滤波器
Gabor滤波器是20世纪40年代由Dennis Gabor提出来的,它是一个空间滤波器,只考虑某时刻的信息,因此无法实现运动分析.与之相比,一个时空滤波器的显著优点是能用来进行运动分析.
时空3DGabor滤波器[5]能较好地表达初级视觉皮层中V1区的简单细胞对速度和方向具有选择性这一特性,可以被用来进行运动分析.式(1)给出的时空3DGabor滤波器与视频序列进行卷积的数学公式.其中gv,θ,φ(x,y,t) 为时空3DGabor滤波器的核函数,I(x,y,t)为输入的视频序列.
rv,θ,φ(x,y,t)=I(x,y,t)gv,θ,φ(x,y,t).
(1)
时空3DGabor滤波器利用如式(2)的核函数构造而成:



(2)

2基于累积运动能量图像的人体动作识别
本文的特征提取过程全貌如图1所示.首先,使用4个不同方向的时空Gabor滤波器提取运动能量,得到视频中每一帧的运动能量图像.其次,将视频中每一帧的运动能量图累积到一帧中,称之为累积运动能量图像,接着,在累积运动能量图像上计算基于网格的方向梯度直方图(HOG),将这4个不同方向的时空3DGabor滤波器形成的累积运动能量图像的HOG特征向量串联起来,形成一个特征向量来表征人体的动作.最后,将该特征向量送入分类器进行分类,识别出人体动作.
2.1运动能量
时空滤波器一般用于运动分析,仅用于处理一些模拟的运动信号,还未用到人体动作识别中,更未用到复杂的现实环境下的人体动作识别中.视频序列中的人体动作是x-y-t三维时空立体,时空滤波器正适合处理x-y-t三维时空序列中的信息.用来感知运动的时空能量模型是在文献[6]中提出的,文中给出了运动能量的计算方法,运动能量Eν,θ(x,y,t)可作为视觉皮层中复杂细胞的响应模型,通过两个相位相互正交的滤波器响应的平方和表示,数学公式如下:

(3)
其中,rν,θ,φ(x,y,t)为时空滤波器与视频序列进行卷积得到的响应,由公式(1)得到,表示时空3D Gabor滤波器对视频进行处理得到的序列图像中的运动信息.
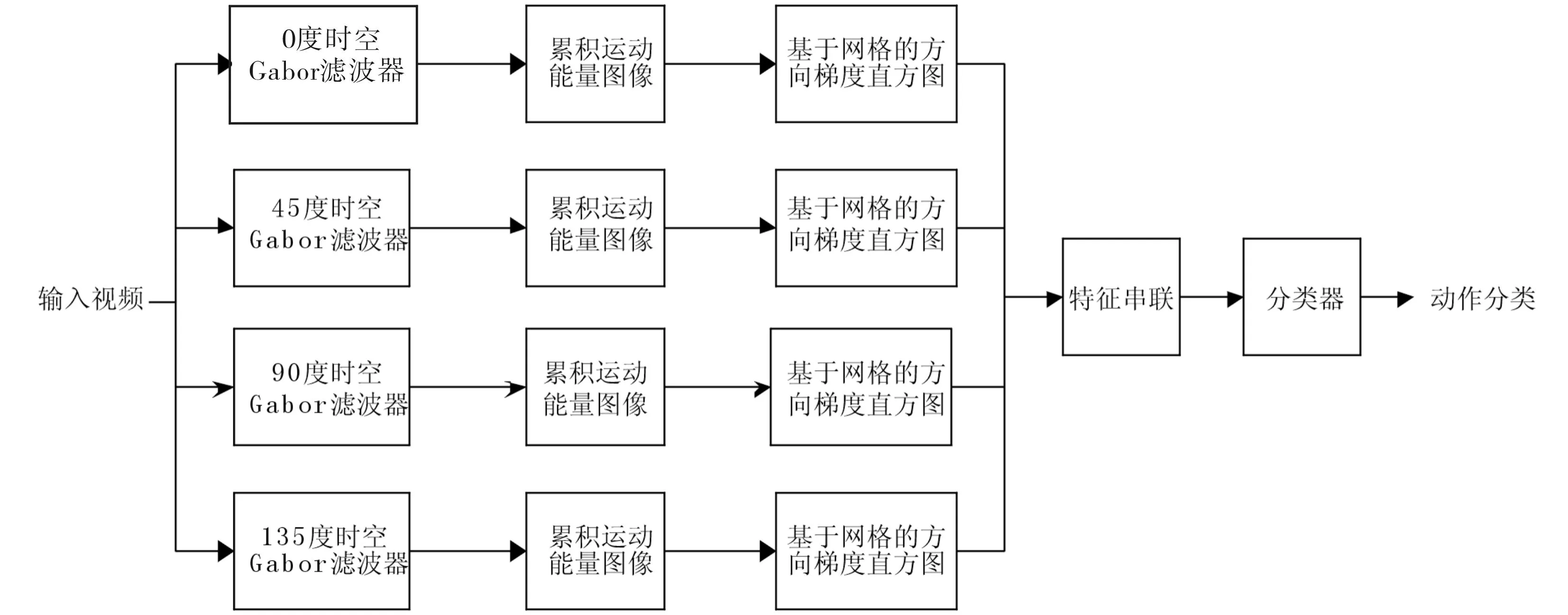
图1 特征提取过程Fig.1 The chain of feature extraction
图2的第1行和第2行分别显示了来自YouTube数据集中的6类不同动作的样本帧和其对应的经过时空3D Gabor滤波器处理后的图像.可以清楚地看到,通过3D Gabor滤波器的处理,原始视频中的运动信息被提取出来,本文认为这些运动信息足够用来进行动作识别.第3行是对应的累积运动能量图像.

图2 来自YouTube人体动作数据集的样本帧(第1行)及其对应的时空3D Gabor滤波器处理的图像(第2行)和累积运动能量图像(第3行)Fig.2 Sample frames from the YouTube dataset (first row), the corresponding images processed by 3G Gabor (second row) and accumulative motion energy images (last row)
2.2累积运动能量图像
个体差异、环境的影响和动作本身的速度或者被记录的速度的不同,都会导致同一动作产生不同的序列图像,这样提取的特征会有一定的差异.为了处理这些差异,本文的构思是:将视频序列中的运动信息累积到一帧图像中,在一帧图像上记录某一时间段内的运动信息,构建累积运动能量图像,提取累积运动能量图像的特征来表征人体的动作. 在(x,y)点处,t时刻的累积运动能量图像由以下公式得到:
H(x,y,t)=max(H(x,y,t-1),E(x,y));
(4)
其中E(x,y)表示由公式(3)得到的运动能量图像,H(x,y,t)表示t时刻的累积运动能量图像,尺寸与E(x,y)大小相等,生成H(x,y,t)的思路是将视频中某一时间窗口上的全部E(x,y)累积到一幅图像上.
累积运动能量图像的计算原理如图3所示.累积运动能量图像上每一点的像素值,是视频中所提取的全部运动能量图像对应位置中数值最大的值.图3中最右边的网格代表累积运动能量图像,该网格左边的网格分别代表视频的第1帧至第n帧.图中的线条表示累积运动能量图像某一个位置的像素值是其对应运动能量图像中的第1帧至第n帧中数值最大的那个值.该计算原理也可以由公式(4)所描述.
图2的第3行是对应的累积运动能量图像,可以看出,与第2行图像相比,在累积运动能量图像中人体的运动信息得到增强,累积运动能量图像中的信息量超过了对应的经过时空3D Gabor滤波器处理后的结果图像.
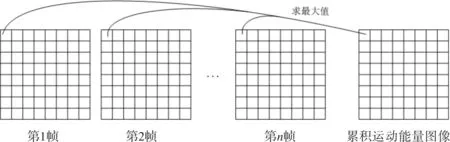
图3 累积运动能量图像的计算原理Fig.3 The computation of accumulative motion energy images
2.3基于网格的方向梯度直方图
本文提取的特征是基于网格的方向梯度直方图(HOG),该方法的思路与方向梯度直方图金字塔(PHOG)[7]比较接近.不同之处有两点,其一是,PHOG首先提取图像中目标的边缘,然后在边缘点上计算不同尺度的HOG,本文中由于累积运动能量图像已经包含了多帧图像的运动信息信息,所以直接在累积运动能量图像的每一点上计算HOG.其二是,PHOG中图像被依次划分成2i×2i个区域,联合若干尺度的特征,而本方法中图像被划分成i×i个区域,仅取其中一个尺度的特征作为动作的特征.
基于网格的HOG是一个空间形状描述子,具有目标的梯度统计特性,通过将图像i×i分成个区域得到空间布局,并在每个区域内计算梯度方向的分布得到局部形状.具体过程如下:在累积运动能量图像上的每个点上计算方向梯度, HOG向量被离散化成K个方向柱(bin),根据每个轮廓点上的梯度值来进行投票.累积运动能量图像被分成i×i个空间网格,在每个网格上计算HOG向量.这里的i取值范围为[3,9],其中计算HOG时方向柱数目K的取值范围为[16,25].思路如图4所示,计算基于网格的方向梯度直方图算法的流程如下:
输入:某一视频的累积运动能量图像H(x,y,t),i代表图像被划分成网格的行列数目,取值范围为[3,9]
输出:基于网格的方向梯度直方图特征f
第1步:f置为空;
第2步:将累积运动能量图像划分成i×i个区域;
第3步:依次计算其中每个区域的方向梯度直方图;
第4步: 将每个区域的方向梯度直方图串联成一个特征向量累计添加到f.

图4 基于网格的方向梯度直方图Fig.4 Grid-based histograms of orientation gradients
2.4分类器
得到每个视频的动作特征之后,本文使用SVM作为分类器对YouTube数据集中的11类动作进行分类,在实验中使用的工具包是osusvm,经过在数据集上反复测试,采样核函数采取径向基核函数,参数C和Gamma分别取9和100.
3实验与分析
本文在YouTube数据集上测试该方法的效果,YouTube数据集的细节在下面给出.本文研究了如下几个问题.为了得到最佳的识别率,测试了该方法的最佳配置:视频序列中时间窗口的帧数,方向梯度直方图中方向柱的数目和图像被划分成网格的数目.最后,将本方法与同类方法进行了比较分析.
3.1数据集
YouTube数据集有如下性质:1)摄像机稳定或者晃动;2)背景混乱;3)人体尺度变化;4)视角变化;5)光照变化;6)分辨率低;7)视频中包含1个或多个人体的动作.这些性质导致了在该数据集上进行人体动作识别非常具有挑战性.该数据集包含11类人体动作:骑自行车、跳水、打高尔夫球、接球、跳床、骑马、投篮、扣球、荡秋千、打网球、遛狗.数据集中的每类动作被分成25个相对独立的组,每组中的视频是在不同的环境下或者由不同的人拍摄,包含4~8个视频.本文只选择每组中的01至04号视频作为总样本.
本文实验中所有的评估都采用10倍交叉验证,即数据集被随机划分成10份,其中的9份用来作为训练数据,1份用来作为测试数据.对训练集和测试集进行10次轮换,取这10次结果的平均值作为这次划分的结果.为了消除随机划分带来的不确定性,将这种随机划分重复做10次,取这10次划分的实验结果的平均值作为最终的识别率.该方法在同样参数下运行,每次得到的识别率有少许不同,但偏差一般不超过0.3%.
3.2参数取值对性能的影响
为了得到最佳的识别率,该方法的性能在各种不同的配置下被评估.有三个主要因素影响着该方法的性能,第一个是视频序列中子窗口的帧数;第二个是计算方向梯度直方图时方向柱的数目;第三个是图像被划分成网格的数目.帧数决定着视频中包含人体动作信息的多少,方向柱的数目决定计算方向梯度直方图时在多少个方向统计方向梯度的分布,网格的数目决定图像被划分的精细程度.
如果同时调节这三个参数,测试在不同参数下的识别率,那么该算法运行的次数将非常多.为了在算法运行次数不多的情况下得到参数的最佳值,本文采取的方案是:根据经验将其中一个参数固定在一个可能的最佳值,调节其他两个参数的大小,记下识别率最高时这两个参数的值.然后,将这两个识别率最高时的参数固定下来,调节第一个参数的大小,检查其最初设定的值是否为最佳值,即识别率是不是在取该参数值的识别率最佳.
3.2.1视频的帧数
视频序列中每一帧都包含动作的信息,随着视频帧数的增加,动作信息会增加,但多少帧最合适用来进行动作识别,这是一个值得考虑的问题.由于YouTube数据集中各个视频的帧数不一样,其中文件名为v_shooting_24_01的视频只有一帧,因此用v_shooting_24_06替代该视频,这样总样本中帧数最少的视频为53帧.为了得到最佳的识别率,在每个视频中选取总数为160~250帧视频序列来分别测试动作的识别率.因此会出现某视频的帧数少于所选帧数的情况,采取如下方法进行处理:选取160帧时,如果某视频的最大帧数不足160,则选择其视频中的全部帧,其他情况也是如此.
3.2.2方向柱的数目
用方向梯度直方图统计区域内梯度的方向,方向的范围是0~360度,其中每360/K度为一个方向柱,总共K个方向柱,方向柱的数目决定着在多少个方向统计梯度的分布.计算方向梯度直方图时,根据每个轮廓点上的梯度值来进行投票,方向梯度直方图的峰值代表了该区域内梯度的主方向.
3.2.3网格的数目
本方法将图像划分成i×i个空间网格,在每个网格上计算方向梯度直方图,i的取值范围是[3,9],其取值决定图像被划分的精细程度.例如,在图4中,图像被划分成5×5大小的网格区域.然后,在各个区域上计算方向梯度直方图,将全部区域上的方向梯度直方图特征串联在一起,形成一个特征向量,使用该特征向量表征人体动作.
为了得到这三个参数的最佳值.首先将网格数目固定在某个值,调整视频帧数和方向柱的数目.图5是将网格数目固定在4×4大小时的识别率,横坐标表示视频的帧数,数值从160增加到250,纵坐标表示识别率.不同的点线符号图表示不同方向柱数目下的识别率.从图5可以看出,大多数情况下,随着帧数的增加,识别率升高,增加到一个峰值后开始降低.在不同数目的方向柱下,峰值所对应的帧数是不同的.视频帧数为230,方向柱数目为21时,识别率最佳.
图6比较了视频帧数选为230帧,方向柱数目为21时不同网格数目下的识别率,横坐标表示计算方向梯度直方图时,图像被划分成3×3、4×4、5×5、6×6、7×7、8×8、4×4和9×9大小的网格.从图6可以看出,网格数目在4×4时识别率达到峰值,在此之前识别率随着网格数目的增加而增长,在此之后识别率随着网格数目的增加而减少.图像被划分成4×4大小的网格时,识别率最佳.

图5 图像被划分成大小时的识别率Fig.5 Classified rate while the grid is 4×4
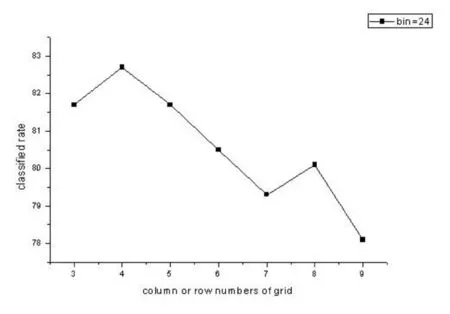
图6 视频选取230帧、方向柱数目为21时的识别率Fig.6 Classifled rate when the frame number is 230 of the videowindows and the number of Bin is 21
3.3与同类方法的比较
与本文提出的累积运动能量图像思想最接近的方法是运动历史图像(MHI)[2]和累积边缘图像(AEI)[4].运动历史图像的思路是将视频中相邻两帧图像的差异累积到一帧图像中,而累积边缘图像是将视频中每一帧的边缘特征累积到一帧图像中.本文是将视频中每一帧运动能量图像累积到一幅图像中,在一张图像上准确地描述了人体运动信息,称之为累积运动能量图像(AMI).
为了比较这些方法的性能,我们设计了3种实验方案:MHI+HOG、AEI+HOG、AMI+HOG作为特征进行人体动作识别.在这三种方案中,除了表征人体动作的特征不同外,其他步骤完全相同.识别率如表1所示,可以看出,累积运动能量图像在YouTube数据集上的识别率比同类方法高.

表1 累积运动能量图像与同类方法的比较
4结语
本文提出了一种可以在真实场景中进行人体动作识别的方法,无需对视频序列中的目标进行跟踪或提取兴趣点这些非常耗时的步骤.本文首先使用4个不同方向的时空Gabor滤波器来提取视频序列的运动信息,然后将某一时间窗口上每一帧的运动能量信息累积到一幅图像中,在该累积运动能量图像上计算基于网格的方向梯度直方图,将这4个不同方向时空Gabor滤波器形成的特征向量串联起来,形成一个特征向量来表征人体的动作.本文的主要贡献是提出累积运动能量图像的概念,用来表征人体动作,进行人体动作识别,在YouTube数据集上的识别率比同类方法高.
参考文献
[1]Poppe R. A survey on vision-based human action recognition[J] .Image and Vision Computing, 2010, 28(6): 976-990.
[2]Bobick A F , Society I C. The recognition of human movement uUsing temporal templates[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(3): 257-267.
[3]赵绚, 彭启民. 基于正弦级数拟合的行为识别方法[J]. 计算机研究与发展, 2013, 50(2):379-386.
[4]谌先敢, 刘娟, 高智勇,等. Recognizing realistic human actions using accumulative edge image[J]. 自动化学报, 2012,38(8):1380-1384.
[5]Petkov N , Subramanian E. Motion detection, noise reduction, texture suppression, and contour enhancement by spatiotemporal Gabor filters with surround inhibition [J]. Biological cybernetics, 2007, 97(5-6):423-439.
[6]Adelson E H , Bergen J R. Spatiotemporal energy models for the perception of motion[J]. Journal of the Optical Society of America A, Optics and Image Science, 1985,2(2): 284-299.
[7]Bosch A, Zisserman A, Munoz X. Representing shape with a spatial pyramid kernel[C] //ACM. Proceedings of the 6th ACM international conference on Image and video retrieval.Amsterdam: CIVR, 2007:401-408.
中图分类号TP391.41
文献标识码A
文章编号1672-4321(2016)01-0108-06
基金项目湖北省自然科学基金计划重点项目(2011CDA078)
作者简介谌先敢(1980-),男,讲师,博士,研究方向:图像处理与识别,E-mail: chenxg@mail.scuec.edu.cn
收稿日期2015-12-25
猜你喜欢
现代电子技术(2016年23期)2017-01-12
现代电子技术(2016年23期)2017-01-12
无线互联科技(2016年13期)2017-01-10
中国水运(2016年11期)2017-01-04
软件导刊(2016年11期)2016-12-22
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
价值工程(2016年29期)2016-11-14
科学与财富(2016年28期)2016-10-14
考试周刊(2016年53期)2016-07-15
