
一种基于复杂网络的短文本语义相似度计算
2016-05-03 13:01詹志建杨小平
中文信息学报 2016年4期
詹志建,杨小平
(中国人民大学 信息学院,北京 100872)
一种基于复杂网络的短文本语义相似度计算
詹志建,杨小平
(中国人民大学 信息学院,北京 100872)
将传统的文本相似度量方法直接移植到短文本时,由于短文本内容简短的特性会导致数据稀疏而造成计算结果出现偏差。该文通过使用复杂网络表征短文本,提出了一种新的短文本相似度量方法。该方法首先对短文本进行预处理,然后对短文本建立复杂网络模型,计算短文本词语的复杂网络特征值,再借助外部工具计算短文本词语之间的语义相似度,然后结合短文本语义相似度定义计算短文本之间的相似度。最后在基准数据集上进行聚类实验,验证本文提出的短文本相似度计算方法在基于F-度量值标准上,优于传统的TF-IDF方法和另一种基于词项语义相似度的计算方法。
复杂网络;综合特征值;短文本;语义相似度
1 引言
文本聚类(Document clustering, or Text clustering)是指自动地将大规模数据集分组为多个类别,并使同一个类别中的文本信息之间具有较高的相似度,而不同类别之间的相似度较低[1]。作为文本挖掘的基础研究课题,文本聚类算法近年来得到系统研究及开发,并取得了一些良好的效果。文本聚类过程中有几个关键问题: 如何确定文本聚类的数目?如何计算文本之间的相似度?如何评价文本聚类?在这些问题当中,如何计算文本之间的相似度是文本聚类的核心问题。
随着互联网的飞速发展,微博、短消息、即时通讯消息等短文本在人们的日常生活和工作当中占据着越来越重要的地位。短文本是相对长文本而言的,包含的信息量少,通常情况下不超过200字。但短文本一般都有明确的主题,表达了作者的意图。传统的文本相似度计算方法通过统计文本间共有的词语信息得到文本间的相似度。对于长文本来说,它所包含的词语数量多,文本相似度可以通过共有词语信息计算得出。但对于短文本来说,由于只包含很少数量的词语,短文本之间可能就没有共同的词语。如果此时再用长文本的相似度计算方法来计算的话,会得到偏差较大的结果。例如,有两个短文本: “如何从互联网上下载电影”和“怎么将视频传到电脑里”。如果单单统计共有词语信息,这两句话没有任何相同词语。但事实上这两句话具有很高的相似度。
短文本相似度计算在许多领域有着广泛的应用: 在信息检索中,短文本相似度计算被认为是改进检索效果最好的方法之一[2];在邮件信息处理中,利用短文本相似度计算可以更快地实现邮件分类[3];在数据库自然语言接口开发中,可以利用短文本相似度扩展查询接口[4];此外,在其它研究领域,包括健康咨询对话系统[5]、房地产销售[6]、电话销售[7]和智能导游[8]等领域,短文本相似度计算也有着非常重要的应用。
将传统的文本相似度量方法(例如,广泛使用的向量空间相似度量方法)直接移植到短文本相似度计算上,往往得不到正确的结果。因为传统的文本相似度量方法大都将文本看作一组词语的集合,通过计算词语在文本中出现的次数以及在文本集中出现的次数对文本建立特征向量,再利用向量之间的余弦相似度或Jaccard相似度等计算文本间的相似度[9]。由于短文本字数少,内容简短,该方法忽略了短文本中词语的语义信息,也忽略了词语的顺序信息和语法信息,并且建立的向量空间维度非常高,数据稀疏问题不可避免,最终计算效率低下。
针对上述方法存在的缺陷,本文提出了一种既能有效表示短文本的特征模型,又能结合短文本中词语的语义信息进行相似度计算的方法。给定两个短文本,通过本文提出的算法,能够高效、快速的计算出两个短文本在语义层次上的相似度,而且能够应用在较为广泛的领域。
2 相关工作
随着互联网的快速发展,网络上的文本资源急剧膨胀。事实上网络上80%的资源是文本资源。在过去的几十年中,有关电子文本资源的自动化处理成为研究人员的关注焦点。网络上的文本资源范围广泛,包括网页文本、电子邮件、新闻组消息、网络新闻等。面对浩如烟海的网络文本,如何挖掘出人们所需要的信息,是文本处理的主要研究方向[10]。在二十世纪80年代,关于文本处理的应用主要是知识工程领域的文本分类,事先由专家人工定义规则知识库,然后判断将文本归结到哪个分类底下[11]。为了避免人工过多参与规则库的编写造成效率低下问题,在90年代的时候研究人员又提出了许多改进的方法,其中包括基于机器学习的规则库构建方法。基于机器学习的规则库构建方法达到的效果不亚于人工专家手工构造的效果,而且在很大程度上解放了人力资源,提高了效率[12]。
不仅文本挖掘领域中需要用到文本处理,在数据挖掘、机器学习、模式识别、人工智能、统计学、计算机语言学、计算机网络技术、信息学等领域,对文本的处理也提出了相应的要求。网络上的文本资源是海量的、异构的、分布广泛的。文本内容又都是人类自然语言,无法为计算机直接所理解。传统的计算机处理的数据都是结构化的,而文本是半结构或无结构的,尤其短文本的内容更少,可能是几句话,一句话或几个单词,甚至只有一个单词。所以,文本处理的首要问题是如何在计算机中有效地表示文本[13],使之能够反映文本的特征。
近年来关于复杂网络的研究引起了研究人员的极大关注。复杂网络在我们的生活中几乎无处不在,复杂网络模型广泛应用在生命科学领域[14]、应激介质[15]、神经网络[16]、时空博奕[17]、基因控制网络[18]和其它自组织系统中。复杂网络系统是由节点和连边组成的,包括可视和不可视的系统。例如,电话网络和油气传输系统是可见的,有着实体的节点和连边,而人际关系网络、社会工作合作关系网络等是不可见的。复杂网络的拓扑图一般情况下要么是完全规则的,要么是完全随机的,但许多生物网络、技术网络和社会网络却介于这两者之间[19]。
研究表明,人类语言也具有小世界复杂网络特性[20]。以人们平常使用的词语为节点,词语间的语义关系为边可以建立人类语言的复杂网络。基于这种思路,我们可以对文本建立语言复杂网络,然后通过计算语言复杂网络中各个节点的特征值,给出各个词语的权重及词语的语义信息。而要作为能够表示文本意思的词语,必须具备以下四点特性。
1) 词语能够明确表示文本内容;
2) 词语具有明确的区分能力,能将文本的意思与其他文本意思区分开来;
3) 词语的数量不能过多;
4) 抽取词语的算法不能过于复杂。
对于长文本来说,一般内容较多,词语数量也多,从而计算复杂度较高。而对于短文本来说,由于内容简短,表达主题明确,词语的数量不会过多。因此,本文经过比较,选择复杂网络来表征短文本。在对短文本建立复杂网络模型之后,我们通过研究短文本词语之间的关系来计算短文本相似度。Harris认为短文本之所能能够计算相似度,是因为构成短文本的基础元素词语在相似的短文本中表达了类似的意思[21]。Harris的观点得到了Firth的验证。Firth认为,在任何语言中,相关的词总是结伴出现[22]。Miller进一步验证了只要文本相似,文本中的词语在一定程度上也是相似的[23]。因此,我们可以总结出这么一个结论: 相似词语表达了相似的主题,由相似词语按照一定结构组成的短文本,表达了相似的内容。
目前国内外已有多种方法用于短文本相似度计算,如张奇提出了一种句子相似度度量的方法,考虑句子中的uni-gram、bi-gram和tri-gram,通过回归方法将这几种相似度结果综合起来[24]。王荣波提出了一种通过比较两个句子的词类信息串,进行最优匹配,得到汉语句子结构相似性的计算方法[25]。熊大平提出了一种基于LDA的匹配框架来解决相似问句的匹配问题,分别从问句的统计信息、语义信息和主题信息三个方面来计算问句相似度,综合得到整体相似度[26]。车万翔提出一种基于改进的编辑距离方法主要思想是通过“插入”、“删除”和“替换”等操作,将字符串替换为另一个字符串所采取的最小编辑操作代价[27]。秦兵等人采用TF-IDF方法和基于语义的方法,面向常见问题集计算问句之间的相似度[28]。穗志方和俞士汶在研究机器翻译的基础上,面向语法结构提出了基于骨架依存树的语句相似度计算方法[29]。赵妍妍等人通过深入分析句子,结合句子的词语特征、语义特征以及句法特征,提出了一种基于多特征融合的句子相似度计算方法,并通过对不同的特征权重调节从而使计算结果最优[30]。Lin提出的基于词共现的方法通过建立文本词库,将短文本映射为词语向量表示,通过向量相似度表示短文本相似度[31]。Islam和Inkpen提出一种结合字符串相似度、词语语义相似度和顺序相似度的短文本相似度计算方法[32],首先利用字符串表示方法将短文本表示成字符串集合,再利用求最长公共子串的方法得到字符串之间的相似度,然后利用WordNet计算词之间的语义相似度,并按词在短文本中出现的顺序计算顺序相似度,最后将三者相似度综合加权得到短文本的相似度。上述方法只注重短文本词语之间的相似度,通过词语相似度加权得到短文本相似度,忽略了短文本中词语之间的内在逻辑关系和权重关系。而通过复杂网络建模,可以将短文本中起到关键作用的词语清楚表示出来,为短文本的相似度计算打下良好表征基础。
带着以上问题,本文在综合分析复杂网络的特征后,提出了一种新的基于复杂网络的短文本相似度计算方法。本文的贡献主要有以下几个方面: 首先应用复杂网络对短文本进行建模,为短文本的语义相似度计算提供一个合适的表征模型。然后结合复杂网络的重要特征和词语语义信息,给出了短文本相似度计算方法。最后通过几种主流的短文本聚类实验,验证本文提出的短文本相似度计算方法是否有效。实验对比了传统的TF-IDF相似度度量方法和文献[33]提出的文本相似度度量方法,结果表明,我们的方法在F-度量指标上优于这两种方法。
3 基于复杂网络的短文本相似度计算
3.1 复杂网络重要特征
为了能够用数学语言对复杂网络建立模型,根据业界普遍认可的复杂网络的重要特征,我们给出复杂网络的图定义。
定义1(复杂网络): 设复杂网络G=(V,E,W)是以V为节点集合,以E为边集合,以W为权重集合的图,其中V={v1,vi……vn}为复杂网络节点集合,E={(vi,vj),vi∈V,vj∈V}为复杂网络的连边集合,W={wij|(vi,vj)∈E}为复杂网络的权重集合。下面我们分别给出复杂网络的重要特征公式。
1) 节点vi的度Di定义为:
(1)
在复杂网络图中,Di表示与节点vi有连边的节点数。度分布反映了节点与其它节点的连接情况。
2) 节点vi的聚集度Ki定义为:

(2)
在复杂网络图中,聚集度Ki表示以节点vi为中心的节点间的连接情况,反映了局部范围内节点聚集情况。
3) 节点vi的聚集系数Ci定义为:
(3)
聚集系数Ci定义公式的分子表示节点vi的聚集度,分母表示完全连通时的度分布统计。
4) 节点vi的权重度WDi定义为:
(4)
节点vi权重度WDi由所有连接vi的边的权重相加而得。
5) 节点vi的权重聚集度WKi定义为:
(5)
节点vi权重聚集度WKi由所有以节点vi以中心的边的权重相加而得。
6) 节点vi的聚集综合度WCi定义为:
(6)
节点vi的聚集综合度WCi与节点的权重聚集度和聚集系数成正比,与节点vi的权重度成反比。
7) 节点vi的聚类系数BCi定义为:
(7)
其中ljk(i)表示节点vj和节点vk之间经过节点vi的最短路径的长度,ljk表示节点vj和节点vk之间的所有可能最短路径。
节点vi的聚类系数BCi具有很强的现实意义,反映了节点vi对复杂网络的信息流动影响。研究表明,复杂网络可看作由一系列子网络连接而成。处于子网络连接点的那些节点起到了关键作用,是连接各个子网络的关键节点。所以对于求不同子网络节点之间的最短路径,都会通过节点vi。
8) 节点vi路径系数BPi定义为:
(8)
提出节点vi的路径系数定义是为了解决聚类系数可能出现0值的情况。因为当有关键节点不处于最短路径时,聚类系数BCi=0。而事实上这些节点是复杂网络中的关键节点。而且聚类系数强调的是局部的连通性,所以引进路径系数BPi是为了增加全局连通性的考虑。
9) 节点vi的复杂网络综合特征值Zi定义为:
(9)
其中根据不同的应用,调节因子α、β和η取不同的数值。
3.2 短文本预处理
尽管短文本字数较少,内容简短,但目前的自然语言处理技术也无法完全处理文本信息。因此,在对短文本建立特征模型之前,对短文本的预处理是必要的,主要包括分词、去除停用词、取词根和词性标注等。对于英文文本,单词间由空格或明显的标点符号分隔,分词可以根据此标志快速实现。而中文文本中词语之间没有明显的边界,因此我们需要通过算法对中文文本进行分词。中文分词是中文信息处理的重要基础,分词结果好坏对应用效果有着非常大的影响。例如,“网球拍卖完了”,可以分词为“网球拍/ 卖/ 完了”,也可以分词为“网球/ 拍卖 /完了”。具体分词算法需要结合具体的语境上下文才能取得更好的效果。
在对短文本分词之后,需要去除停用词。停用词是指那些对文本表示影响可以忽略不计,不包含对文本处理有任何价值的词语,例如,英文的“the、a、of、for、in”,中文的“的、地、得”等。去除停用词最常用的方法是维护一个停用词列表,当文本分词后的词语出现在停用词列表中,就去除掉。停用词一般跟领域有关,不同的领域可能会有不同的停用词列表。
由于本文提出的方法需要对短文本进行语义分析,分词后除了删除停用词外,还需要进行以下两个步骤:
1) 将短文本中的人名、地名和组织机构名等特殊词语进行处理,采用命名实体识别技术统一替换为特定的字符串,其中人名替换为PEO,地名替换为ADD,组织机构名替换为COM。
2) 对短文本中的词语进行词性标注。词语根据不同的性质和用途可以分为不同的类型,最能表征短文本含义的主要是实词,因此需要区分词语是名词、动词、形容词还是副词。
3.3 复杂网络构建
人类语言区别于其他生物交流语言的一个重要特点是拥有数量庞大的词汇。人们可以在不超过100ms的时间内判断一个字或词的组合是否正确或合理。研究表明,人类之所以具有这种识字本领,是因为人类语言之间存在着千丝万缕的内部联系。人类语言具有小世界网络特性,人类语言文本中的词语并不是随机乱序的,而是按词间关系表达了特定的主题。词语数量有限,但不同的词语排列组成成千上万的意思。文本主要由段落和句子组成,句子的基本组成元素是词语,以词语作为节点,词语之间的关系作为连边,可以将文本构建成复杂网络。文本语言复杂网络构建的思路是以每个词语作为节点,词语在同一个句子中出现作为连边建立网络。不同的词语出现在同一个句子中,说明词语之间存在语法关系。所以紧邻的词语之间必然存在连边。但是非紧邻的词语之间是否存在语法关系,以及如何确定多长距离之内的词语具有连边关系?连边的收集,若只采集两个紧邻的词语之间的联系,则可能会丢失一些长程的关联,同时却提高某些无用词在网络中的重要性。因而需要确定词语在句子中的关联跨度。若跨度太短,很多重要的关联无法记录;若跨度太大,可能产生许多冗余信息。本文采用文献[20]中所遵循的规则,即取关联跨度最大为2进行研究,因为这种长度的关联在语言复杂网络中最为常见和重要。例如,对于句子“文本相似度计算过程”,通过分词产生“文本”、“相似度”、“计算”、“过程”,从而可以建立如图1所示的语言网络。对于整个文本语言复杂网络的构建,则可以通过合并各个句子语言复杂网络中相同的节点与连边来产生。

图1 一个句子的语言复杂网络
3.4 短文本相似度计算
构建完短文本的语言复杂网络后,我们就可以利用式(9)计算各个词语节点的综合特征值,并将短文本中各个词语的综合特征值表示为向量权重,以此计算短文本之间的相似度。由于短文本字数少,内容简短,预处理后产生的词语个数也不会太多,因此这个向量的维度通常不会太高。在得到了短文本的特征向量之后,接下来要考虑的就是如何计算短文本之间的相似度。由于短文本词语代表了短文本的信息,因此短文本的相似度就可以转化为向量间的相似度。另外,由于每篇短文本长短不一,因而表征每篇短文本词语向量的维度也不一样,本文必须消除这种影响,使得特征向量间的相似度满足基本的相似度量标准。
设vi和vj是两篇不同短文本X和Y的特征向量,其中vi=(wi1,wi2,……wim),vj=(wj1,wj2,……wjn)。定义短文本之间的相似度为:
(10)
其中cf表示短文本特征向量vi和vj之间相似度的加权因子,VectSim(vi,vj)表示特征向量vi和vj之间的相似度。短文本中词语的复杂网络综合特征值越高,表明该词语在短文本的复杂网络中处于越重要的位置,即表示该词语越能代表短文本的主题。同时,如果两篇短文本中彼此相似的词语越多,说明短文本的主题越相似。因此,根据词语的复杂网络特征值和词语间的相似度值,我们首先找出满足词语相似度阀值条件的特征词语,再计算这些特征词语的复杂网络综合特征值之和,最后求出上述结果值占整篇短文本特征值总和的比例,具体的加权因子计算公式由式(11)给出。
(11)
其中Zik表示词语wik的语言复杂网络综合特征值,左端项分子部分表示满足相似度阀值条件的词语的综合特征值之和,分母部分表示所有词语综合特征值之和。式(11)中的集合Λi和Λj定义如下:
(12)
(13)
其中sim(wjl,wik)表示词语wjl和wik之间的语义相似度。由于词语相似度不在本文讨论范围,所以我们直接引用文献[23]和文献[34]中的词语相似度计算方法。如果特征向量vi中的某个词语wik与另一个特征向量vj中的词语wjl(l=1,2……n)的相度阀值超过用户设定的相似度阀值,则将该词语wik放入到集合Λi中。集合Λj包含的元素依据集合Λi的方法对特征向量vj中的词语进行选择。|Λi|、|Λj|分别表示集合Λi和Λj的元素个数。集合元素越多,说明满足相似度阀值条件的词语个数越多,对相似度的影响越大。

(14)
特征向量vi和vj之间的相似度VectSim(vi,vj)由向量vi和vj中所包含的词语相似度和向量之间的余弦相似度决定。相似的短文本必然由相似的词语组成,相似词语组成的短文本表达了相似的意思。
3.5 算法流程
输入: 两篇短文本X和Y,词语相似度阀值μ
输出: 短文本X和Y的相似度值STSim
step1 对短文本X和Y进行预处理,建立相应的复杂网络,根据式(3)—式(9)计算复杂网络中各个节点的综合特征值Z;
step2 将文本X和Y建模为特征向量vi=(wi1,wi2,……wim)和vj=(wj1,wj2,……wjn),其中各个词语的权重为复杂网络综合特征值;
step3 从向量vi的词语wi1开始,寻找向量vj中与wi1相似度最高的词语wjk,记录wi1和wjk之间的相似度值θ,并判断θ与μ大小。如果θ>μ,则将wi1放入到集合Λi中;
step4 重复step3的过程,直至向量vi中所有的词语都在向量vj中找到各自相似度最大的词语,同时记录相似度值并调整集合Λi;
step5 统计step3和step4的相似度值总和,除以向量vi中词语的数量,以此作为向量vi对vj的相似度值Sim(vi,vj);
step6 同理求得Λj和Sim(vj,vi);
step7 根据step5和step6的计算结果,再根据式(3-14)求得VectSim(vi,vj);
step8 计算集合Λi中所有词语的综合特征值总和,以及集合Λj中所有词项的综合特征值总和,并根据式(3-11)计算加权因子cf;
step9 根据step7和step8和计算结果,再结合式(3-10)求得文本X和Y的相似度值STSim。
4 实验
本文实验数据选用业界广泛使用的BBC数据集*BBC Dataset, Machine Learning Group. http://mlg.ucd.ie和复旦大学自然语言处理小组收集与整理的文本语料库*http://www.nlp.org.cn/docs/doclist.php?cat_id=16&type=15。这些数据集中的聚类数目、文本大小以及文本分布都有着显著的差异,本文挑选其中不超过200字的短文本作为基准数据集,分别选取两个文本集合中各四个文本子集用于本文实验,即BBC1、BBC2、BBC3、BBC4和FUDAN1、FUDAN2、FUDAN3、FUDAN4。每篇短文本预先被划分到一个或多个类别中,各个数据子集的特点如表1所示。
该语料库中各个类别的子类别可以作为各个文本集的标准聚类结果。实验首先采用LingPipe*LingPipe, Alias-I, Inc. http://www.alias-i.com对

表1 实验数据摘要
BBC数据集进行预处理,采用中国科学院分词软件ICTCLAS*ICTCLAS汉语分词系统. http://www.ictclas.org/对FUDAN数据集进行预处理,然后建立短文本语言复杂网络,计算各个分词的综合特征值Z,并以此特征值作为短文本词语向量权重。短文本词语之间的相似度计算采用文献[23]和文献[34]的方法,再结合本文提出的短文本相似度计算方法,对短文本数据集进行相似度计算,得到短文本相似度矩阵。
为了验证本文算法的有效性,本文同时实现了基于TF-IDF方法的短文本相似度[10]、文献[18]提出的结合词项语义信息的文本相似度计算方法TSemSim以及文献[35]提出的基于子树匹配的文本相似度算法SubTSim,进行聚类结果的比较。本文采用CLUTO工具包*Karypis G. CLUTO-A clustering toolkit. Department of Computer Science, University of Minnesota. http://www.cs.umn.edu/~karypis/cluoto进行聚类实验,并实现了CLUTO工具包中K-均值(DKM)、二分K-均值(BKM)和凝聚K-均值(AKM)的聚类算法。
本文实验采用F-度量值来衡量短文本相似度计算结果。F-度量值是根据准确率P(Precision)和召回率R(Recall)给出的一个综合的评价指标,其定义如式(15)—式(17)所示。
(15)
(16)
(17)
其中,ni表示类别i的短文本数量,nj是聚类j的短文本数量,nij表示聚类j中应属于类别i的短文本数量。
全局聚类的F-度量值定义如式(18)所示。
(18)
式(18)中,ni表示各个子类别的文本数目,n表示所有文本数量,j表示计算的聚类结果。F值越大,聚类结果越好。
实验首先要确定词语相似度阀值μ的大小对聚类结果的影响。为了客观体现本文算法的真实性,选取CLUTO工具包中最直接的DKM算法进行聚类。图2给出了在利用DKM聚类算法进行计算时,同一聚类中的词语相似度阀值μ的大小对聚类结果的影响。随着短文本之间词语相似度阀值μ的逐渐升高,聚类效果也逐步提升。这是因为随着阀值的提升,短文本之间的区分度也越来越大,因此聚类效果也越来越好。从图中可以看出,当μ落值在区间[0.65,0.75]之间时,达到最好的聚类效果。而当μ值超过0.75时,F-度量值急剧下降,这是因为本文选取的词语相似度算法对于短文本之间词语的相似度计算较少有超过0.75值,导致短文本相似度加权因子下降,因而在整体上降低F-度量值。

图2 词语相似度阀值μ对聚类结果的影响
根据以上实验结果,本文选取词语相似度阀值μ为0.7,采用本文算法与TF-IDF、TSemSim算法、SubTSim算法进行比较,比较结果如图3所示。从图中可以看出,无论是BBC数据集,还是FUDAN数据集,在DKM算法、BKM算法和AKM算法中,本文算法的F-度量值都要高于其它算法。这与本文算法既考虑了短文本的文本信息量少、用复杂网络表示词语之间的联系有关,也与考虑了词语之间的语义信息有关。传统的TF-IDF方法在短文本相似度计算中的F-度量值最低,这是因为TF-IDF方法只考虑词语的TF-IDF值,而未考虑其它因素。TSemSim算法和SubTSim算法主要着眼于长文本的相似度计算,在长文本方面相似度计算方面有着比较好的优势,其中TSemSim算法也考虑了词语之间的语义信息,SubTSim算法还借助子树计算文本相似度。但对于短文本相似度的计算,上述两种算法对短文本的文本特征表示不够到位,故最终得出的F-度量值低于本文算法。
为了进一步证明本文算法的优异性,根据实验结果,选择双样本等方差假设进行两两比较,即首先对DKM算法中的STSim和TF-IDF方法作显著性检验分析,选取显著性水平α=0.05。再对STSim和TSemSim作显著性检验,依次类推,分析结果如表2—表4所示。

表2 DKM算法的显著性检验结果

续表

图3 本文算法STSim、TF-IDF算法、TsemSim、SubTSim算法在聚类算法上的F-度量值比较

STSimTF-IDFSTSimTSemSimSTSimSubTSim平均0.6286250.566750.6286250.5753750.6286250.587875方差0.0005351250.0014839290.0005350.0016610.0005350.001689观测值888888合并方差0.0010095270.0010980.001112假设平均差000

续表
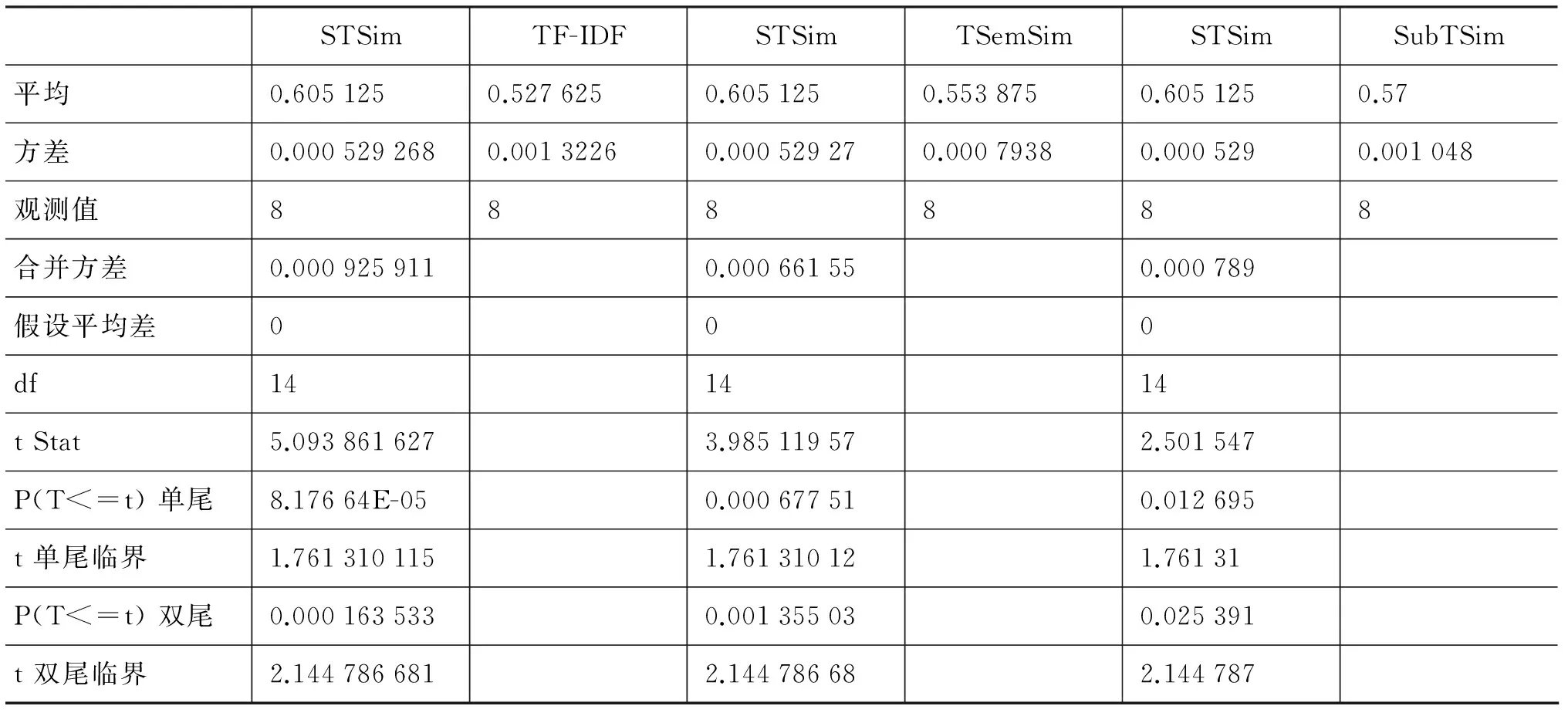
表4 AKM算法的显著性检验结果
从表2—表4可以看出P(T<=t)双尾均小于0.05,说明本文算法与TF-IDF、TSemSim算法和SubTSim算法有着显著的差异,效果优于这些算法。
5 结论
本文首先通过分析已有的文本相似度计算方法移植到短文本时会出现的偏差问题,然后根据复杂网络的重要特征以及人类语言所具有的小世界复杂网络特性,提出了一种新的基于复杂网络的短文本相似度计算方法。与现有的短文本相似度计算方法相比,本文提出的算法既能够有效表示短文本的语义信息,又结合词语间的语义相似度计算短文本间的相似度。并通过经典的聚类算法实验,验证了本文算法的有效性。本文的后续工作将在现有语言复杂网络和词语语义信息分析的基础上,进一步深入分析短文本中不同位置、不同权重的词语对短文本相似度计算结果的影响,综合考虑短文本中词语的位置权重、文本结构等信息,更好地提高短文本相似度计算精度。
[1] BCM Fung, K Wang, M Ester. Hierarchical document clustering[J]. The Encyclopedia of Data Warehousing and Ming, Idea Group, 2005:970-975.
[2] Mihai Lintean, Vasile Rus. Measuring Semantic Similarity in Short Texts through Greedy Pairing and Word Semantics[C]//Proceedings of the 25th International Florida Artificial Intelligence Research Society Conference, 2012: 244-249.
[3] Luc Lamontagne, Guy Lapalme. Textual Reuse for Email Response[J]. Lecture Notes in Computer Science, 2004(3155):242-256.
[4] James Glass, Eugene Weinstein, Scott Cyphers. A Framework for Developing Conversational User Interfaces[C]//Proceedings of the Fourth International Conference on Computer-Aided Design of User Interfaces, Funchal, Isle of Madeira, Portugal 2005:349-360.
[5] Timothy Bickmore, Toni Giorgino. Health dialog systems for patients and consumers[J]. Journal of Biomedical Informatics, 2006(39): 556-571.
[6] Cassell Justine. Embodied Conversational Agents[C]//Proceedings of the Encyclopedia of the Sciences of Learning, 2000.
[7] AL Gorin,G Riccardi,JH Wright. How I help you? Speech Communication [J]. Speech Computication, 1997,(23):113-127.
[8] AC Graesser, P Chipman, BC Haynes, A Olney. AutoTutor: An Intelligent Tutoring System With Mixed Initiative Dialogue[C]//Proceedings of the IEEE Transactions on Education 2005,48(4): 612-618.
[9] Salton G. The SMART Retrieval System-Experiments in Automatic Document Processing[C]//Proceedings of the Englewood Cliffs, New Jersey: Prentice Hall Inc, 1971.
[10] R Dinesh, BS Harish, DS Guru, et al. Concept of Status Matrix in Text Classification[C]//Proceedings of Indian International Conference on Artificial Intelligence, Tumkur, India. 2009:2071-2079.
[11] V Mitra, CJ Wang, S Banerjee. Text Classification: A least square support vector machine approach[J]. Journal of Applied Soft Computing. 2007,(7):908-914.
[12] GPC Fung, JX Yu,H Lu, PS Yu. Text classification without negative example revisit[C]//Proceedings of the IEEE Transactions on Knowledge and Data Engineering. 2006,(18): 23-47.
[13] Aliaksei S., Massimo N., Alessandro M. Learning Semantic Textual Similarity with Structural Representations[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 2013:714-718.
[14] SH Strogatz, I Stewart. Coupled oscillators and biological synchronization[J]. Sci. Am. 1993, 269(6):102-109.
[15] Martin Gerhardt, Heike Schuster, John J Tyson. A cellular automaton model of excitable media including curvature and dispersion[J]. Science. 1990(247): 1563-1566.
[16] John J Hopfield, Andreas V M Herz. Rapid local synchronization of action potentials: Toward computation with coupled integrate-and-fire neurons[C]//Proceedings of the Natl Acad. Sci. USA,1995(92):6655-6662.
[17] Martin A. Nowak, Robert M. May. Evolutionary games and spatial chaos[J]. Nature. 1992,(359):826-829.
[18] Kauffman S A. Metabolic stability and epigenesis in randomly constructed genetic nets[J]. Journal of Theoretical Biology. 1969,(22):437-467.
[19] Duncan Watts, Steven Strogatz. Collective dynamics of ‘small-world’ networks[J]. Nature. 1998,(393): 440-442.
[20] Ferreri Cancho R. Sole R V. The small world of human language[J]. Biological Sciences, 2011,268(1482):2261-2265.
[21] Harris, Z. Distributional Structure[J]. Word, 1954(10):146-162.
[22] Firth J R. A Synopsis of Linguistic Theory, 1930-1957[J]. In Special volume of the Philological Society. Oxford: Blackwell, 1957.
[23] Miller G, Harles W. Contextual Correlates of Semantic Similarity[C]//Proceedings of the Language and Cognitive Processes,1991,(6): 1-28.
[24] Zhang Qi, Huang Xuanjing, Wu Li-de. A New Method for Calculating Similarity Between Sentences and Application on Automatic Text Summarization[J]. Journal Of Chinese Information Processing, 2005,19(2):60-68.
[25] Wang Rongbo, Chi Zheru. A Similarity Measure Method of Chinese Sentence Structures[J]. Journal Of Chinese Information Processing, 2005, 19(1):21-29.
[26] Xiong Daping, Wang Jian, Lin Hongfei. An LDA-based Approach to Finding Similar Questions for Community Question Answer[J]. Journal Of Chinese Information Processing, 2012, 26(5):40-45.
[27] Wanxiang Che, Ting Liu, Bin Qin. Similar sentence retrieval based on improved edit distance Chinese[J]. High Technology Letters,2004,(7):15-19.
[28] Bin Qin, Ting Liu, Yang Wang. Research on question answering system based on frequently asked question set Chinese[J]. Journal of Harbin Institute Technology. 2003,35(10):1179-1182.
[29] Zhifang Sui, Shiwen Yu. The calculation model of sentence similarity based on skeleton dependency tree[C]//Proceedings of the International Conference On Chinese Computing,1998.
[30] Yanyan Zhao, Bin Qin, Ting Liu. Sentence similarity computing based on multi features fusion[C]//Proceedings of the Joint Conference on Computational Linguistics’2005, Nanjing,2005:168-174.
[31] Lin C, Hovy E. Automatic evaluation of summaries using n-gram co-occurrence statistics[C]//Proceedings of the Human Language Technology Conference. 2003.
[32] Islam A. Inkpen D. Semantic Text Similarity using Corpus-based Word Similarity and String Similarity[C]//Proceedings of the ACM Transactions on Knowledge Discovery from Data. 2008.
[33] Yuhua Li, David McLean, Zuhair A. Bandar, et al. Sentence Similarity Based on Semantic Nets and Corpus Statistics[J]. IEEE Transactions on Knowledge and Data Engineering, 2006,18(8):1138-1150.
[34] Zhijian Z., Lina L., Xiaoping Y. Word Similarity Measurement Based on BaiduBaike[J]. Computer Science. 2013,40(6):199-202.
[35] Zhang Peiyun,Chen Chuanming, Huang Bo. Texts Similarity Algorithm Based on Subtrees Matching[J]. Pattern Recognition and Artificial Intelligence,2014,27(3):226-234.
Measuring Semantic Similarity in Short Texts Through Complex Network
ZHAN Zhijian, YANG Xiaoping
(School of Information, Renmin University of China, Beijing 100872, China)
Traditional methods of text similarity measure will cause erroneous results when applied in short texts, because most of them treat texts as a set of words. Due to the very brief content of short texts, those methods not only ignore the semantics information of the words but also the order information and grammar information. This paper proposes a new semantic similarity measurement between short texts, based on the complex network. This approach first pre-processes short text, and uses the complex network to model short text. With the definition of short text semantic similarity, this paper resolves the semantic information of terms in short text. Finally, several K-Means clustering methods are used for evaluating performance of the new short text similarity measurement. By comparing with TF-IDF and another semantic information method, the results show that it can promote the evaluation metrics of F-Measure.
complex network; comprehensive eigenvalue; short text; semantic similarity

詹志建(1982-),博士,主要研究领域为信息系统工程。E-mail:zhanzj@ruc.edu.cn杨小平(1956-),博士,教授,主要研究领域为信息系统工程。E-mail:yang@ruc.edu.cn
1003-0077(2016)04-0071-10
2014-07-08 定稿日期: 2015-02-10
国家自然科学基金(70871115)
TP391
A
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学物理学报(2021年6期)2021-12-21
数学物理学报(2021年5期)2021-11-19
数学物理学报(2021年3期)2021-07-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
时代英语·高二(2018年7期)2018-12-03
中国诗歌(2018年6期)2018-11-14
时代英语·高二(2018年3期)2018-06-06
