
基于Word2vec的短信向量化算法
2016-05-10 03:27王贵新郑孝宗张浩然张小川
电子科技 2016年4期
王贵新,郑孝宗,张浩然,张小川
(1.重庆工程学院 软件学院,重庆 402260;2.重庆理工大学 计算机学院,重庆 400054)
基于Word2vec的短信向量化算法
王贵新1,郑孝宗1,张浩然1,张小川2
(1.重庆工程学院 软件学院,重庆402260;2.重庆理工大学 计算机学院,重庆400054)
摘要针对目前垃圾短信过滤效果有待提高的问题,提出一种新的短信特征提取方法。该方法采用了建立在深度学习理论基础上的最新成果和Word2vec工具。基于中文短信的内容和结构特点,利用该工具设计了一个短信向量化算法。该算法能有效地将每条短信与一个向量对应,在深度置信网络上利用该算法对垃圾短信进行分类实验。实验结果表明,推广性能比已有报道结果提高了约5%。
关键词深度置信网络;深度学习;短信;向量化
目前垃圾短信治理主要采用软件自动过滤和人工干预[1-5]。但这些学习和过滤算法目前已经不能很好适应机器学习环境,特别是深度学习算法理论的完善和应用发展,为机器学习提供了广阔空间[6]。
垃圾短信的自动过滤系统,一般采用多分类器的组合,使得分类效果更佳。在这过程中,短信特征的分析和提取是非常重要的环节[5]。本文将利用深度学习的理论工具Word2vec,研究短信特征提取的新算法,并将该算法采用深度置信网络(DBN)进行了验证,取得了较好的分类效果。
实验样本来源于以前所做垃圾短信智能分类系统项目所收集的大约有三百万条短信。处于保护个人隐私目的,该样本内容没有主、被叫号码、短信时间等信息。
1短信向量化算法过程
按照有关规定,短信类别有:敏感政治信息、黄色信息、商业广告信息、违法犯罪信息、诈骗信息、正常信息等6大类(分别用zp、ss、sv、sh、sp、qt字母组合表示类名)。分类结果除了正常信息外,其余信息需要过滤和提交不同部门处理。短信向量化算法过程,主要从3个步骤了解:(1)短信预处理;(2)短信分词;(3)短信向量化算法。
1.1预处理
主要包括非正规字词替换。比如短信:“公$$司*開發@PIAO,酒折优惠,欢迎拨打:139XXXXXXXX,或访问www.XXX.com,也可邮件到XXX@sina.com”。系统需要根据预先设置的谐音库、拼音库、繁体库、连词介词库、特殊符号库等标准库的比较进行内容转换。同时剔除内容里面不相关的符号。结果这条短信就是“公司开发票,9折优惠,欢迎拨打:139XXXXXXXX,访问www.XXX.com,可邮件到XXX@sina.com”。
假设所有的短信集合记为S,记预处理过程对应的函数为f1,经过预处理后的短信集合记为G,则∀s∈S,f1(s)=G。
1.2分词
为提高分类效果,对特殊内容进行了替换。例如,预处理后的短信“公司开发票,9折优惠,欢迎拨打:139XXXXXXXX,访问www.XXX.com,可邮件到XXX@sina.com”,替换后的结果是:“公司开发票,AA折优惠,欢迎拨打:BB,访问BB,可邮件到BB”。
然后采用中国科学院计算技术研究所ICTCLAS系统,完成短信的分词。比如,上述短信分词结果是:“公司 开 发票 AA 折 优惠 欢迎 拨打 BB 访问 可 邮件 到”。

表1 特殊内容替换要求
1.3短信向量化算法
谷歌推出了将词语转换成词向量的工具Word2vec (https://code.google.com/p/word2vec/)。工具的主要原理是Bengio模型[7]的一个改进和应用,Bengio模型主要原理是:设某语句依次由一系列关键词w1,w2,…,wt组成,其中任意关键词向量化的过程可用三层的神经网络[7]表示。关键词序列前面的n-1个词可预测下一个词出现的概率。用C(w)表示词w所对应的词向量,网络第一层输入是将C(wt-n+1)、…、C(wt-2)、C(wt-1)这n-1个向量首尾相连接,构成一个(n-1)×m维向量。
Word2vec的Log-Bilinear模型包括CBOW和Skip-gram两种。本文实验采用Skip-gram模型。短信向量化算法描述如下:
(1)短信预处理。每类按照一定比例取出约21 280个训练样本。然后按照上述方法将每个短信预处理。
(2)分词。按照上述方法把预处理后的短信进行分词,并形成如下的7个文本文件:rubbish.txt(所有样本的分词文件);zp.txt、ss.txt、sy.txt、sh.txt、sp.txt、qt.txt分别是敏感政治信息、黄色信息、商业广告信息、违法犯罪信息、诈骗信息、正常信息等6大类训练样本对应的分词文件。
(3)词语向量化。对rubbish.txt、zp.txt、ss.txt、sy.txt、sh.txt、sp.txt、qt.txt,分别执行word2vec指令(格式:word2vec -train 分词文件名-output 向量化结果文件名-cbow 0 -size 5 -window 10 -negative 0 -hs 1 -sample 1e-3 -threads 2 -binary 0),分别得到向量化结果文件rubbish.out、zp.out、ss.out、sy.out、sh.out、sp.out、qt.out。参数设置是在考虑短信特点时,多次实验测试的结果。
向量化结果文件的每行是一个词语向量。形如:担保:0.097 318 0.062 329 -0.068 594 0.087 311 -0.023 715。
(4)取每类的主关键词。垃圾短信的每个类别有其显著的关键词。比如“商业广告”类中,“出租”、“销售”、“打折”等词语。记wi=(wi1,wi2,…,wim)、wj=(wj1,wj2,…,wjm)分别是词语wi、wj按照算法步骤(3)得到的向量化结果(以后将词语和其对应的向量化结果记为同一符号),定义两个词语向量wi、wj相似性dis(wi,wj)按照下式计算
(1)
按照式(1)在zp.out、ss.out、sy.out、sh.out、sp.out、qt.out 每个文件中只保留相似性数值大的前20的关键词(不包括“AA”、“BB”、“CC”、“DD”、“NN”)的词语向量,其余删除。选择的这20个关键词,称为主关键词。之所以只选择20个,是因为大多数情况下可代表该类,同时考虑到短信的特征维数不宜过大。为弥补特殊情况下主关键词数量的不足,后面增加了短信的字结构特征。
(5)短信向量化。设短信中的某分词,按照步骤(3)得到的词向量为w,称下面的表达式是分词w到敏感政治信息类距离
(2)
令L=60,这样对∀s∈S的一短信,按照式(2)可计算出s中每个分词到敏感政治信息类的距离。假设这些距离从大到小排列,取前L的距离所对应的分词向量分别是w1,w2,…,wL。这样定义该短信在敏感政治信息类的特征是
Vzp=(vzp(w1),vzp(w2),…,vzp(wL))
(3)
采用上面方法和类似记号,同理可得到该短信在其他类上的特征分别是Vss,Vsy,Vsh,Vsp,Vqt。又记称下面的表达式是分词w到1.2节中特殊内容替换后的分词AA的距离
vAA(w)=dis(w,AA)
(4)
同样采用上面方法和类似记号,对∀s∈S的一短信,可计算出s中所有分词到AA的距离。假设这些距离从大到小排列,取前L的距离所对应的分词向量分别是w1,w2,…,wL。得到该短信相对于AA的特征是
VAA=(vAA(w1),vAA(w2),…,vAA(wL))
(5)
同样采用上述方法和类似记号,得到短信s相对1.2节中的特殊内容替换后的分词BB、CC、DD、NN的特征表示为VBB,VCC,VDD,VNN。
取有短信样本中频率最高的前2 100个汉字序列记为CH,chj表示CH的第j个汉字。对于短信s,令
(6)
文中得到该短信相对于CH的字结构特征
Vch=(I(1,s),I(2,s),…,I(2 100,s))
(7)
另外文中记V0是所有分量为0,维数是20的向量(保留20个特征位是应对临时的政策要求)。这样,按照式(1)~式(7),定义短信s的向量化结果V
∀s∈S,f1(s)⟹V=[Vzp,Vss,Vsy,Vsh,Vsp,Vqt,VAA,VBB,VCC,VDD,VNN,Vch,V0]
(8)
从以上定义可知,V的维数是11×60+2 100+20=2 780。词的向量化方法众多[8],本文只针对短信处理提出解决方法。
2深度置信网络(DBN)
深度置信网络(DBN),如图1所示[9],可被看作由许多简单的学习模块构成,每个模块是一个限制型Boltzmann机(RBM)[10-11]。RBM网络由一个可视层和一个隐层构成,层间有连接,层内单元间没有连接。训练隐层单元去获取在可视层表现出来的高阶数据特性,如图2所示。DBNs是一个概率生成模型,其会建立一个观察数据和标签之间的联合分布,同时做P(observation|label)、P(label|observation)两者的概率计算。
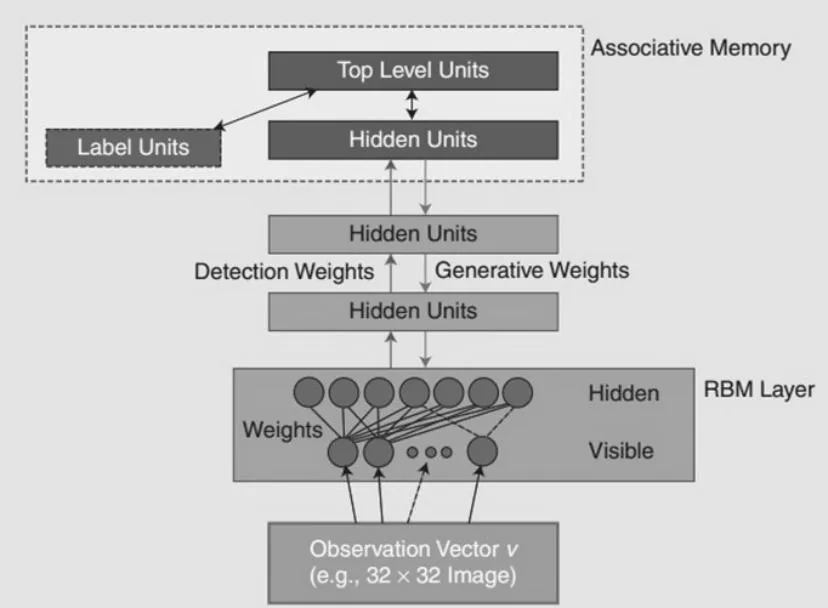
图1 DBN网络模型
DBN中的下层RBM的输出作为上层RBM的输入。每层RBM模型能量的定义
(9)
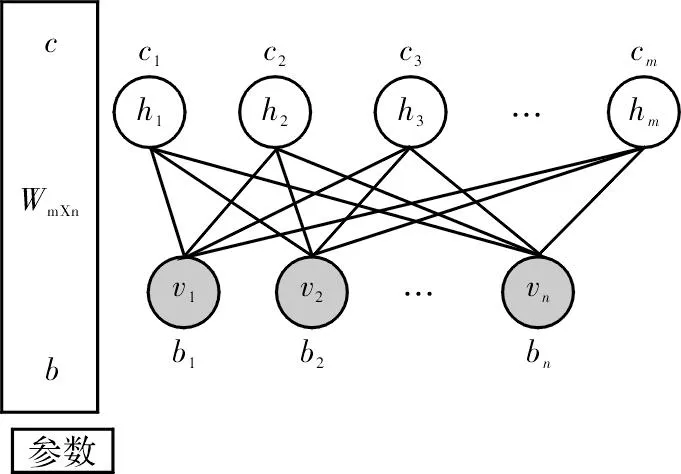
图2 RBM网络模型
首先利用RBM训练算法,依次对各RBM层进行训练。所有RBM训练完后,DBN的顶层然后利用带标签数据用BP算法去对权值进行调整。最后获得一个DBN网络的分类面。理论上DBN性能优于单纯的BP网络。因为DBNs的BP算法只需对权值参数空间进行一个局部的搜索,所以与前向神经网络相比,训练较快。由于第一个输入层中神经元输入0元素较多,在选择RBM的神经元个数时,考虑了压缩。具体的神经元个数是根据实验的经验获得,如图3所示,DBN的第一个输入层数据是根据式(8)结果得到的。
3实验与结论
考虑到计算复杂度和参考文献的经验[12-13],本实验最终采用有2个隐层的BP神经网络,首先对BP网络的权值采用DBN算法进行训练得到,再采用BP算法对网络权值进行微调。所有结果用Matlab进行仿真实验,DBN训练部分代码采用DeepLearnToolbox-master工具包(https://github.com/rasmusbergpalm/DeepLearnToolbox),DBN模型的实验如图3所示。设czp,css,csy,csp,cqt分别表示正确地分类到相应类的样本数;tzp,tss,tsy,tsp,tqt分别表示相应类的样本总数。为简单处理,不考虑样本的拒识。整个垃圾过滤系统分类的正确率()定义为
correct_rate=(czp+css+csy+csp+cqt)/(tzp+tss+tsy+tsp+tqt)
(10)
根据式(10)类似可定义每个类的分类正确率。为说明本文算法的有效性,文中从已有的垃圾短信分类文献出找出了有代表性的分类数据,与本文的分类结果进行比较,效果如表2所示。

表2 几种常用模型的结果比较
其中qt,sp,sh,ss,zp,sy训练样本数目分别是7 416、1 770、3 728、2 590、1 220、4 556,测试样本数目分别是14 308、3 672、4 579、6 102、2 553、9 080。
通过实验,文中得到以下现象和结论:
(1)随着DBN的隐层数增加,训练时间大幅延长,训练样本的正确率有所提高,但推广性能没有显著的变化。因此在具体的应用中,合理选择参数很重要;
(2)本文短信分类只使用了一种分类器,分类效果比已发表的文献数据高。一般具体应用是采用多分类器,本文的算法在多分类器环境下,数据效果更佳;
(3)本文算法可应用到其他文本分类中;
(4)为改进算法,研究以单个汉字为单元的向量化对分类的结果影响,是下一步的工作;
(5)在实际应用过程中,特征可将黑白手机名单、主叫、被叫、发送时间因素考虑上,同时分类器增加拒识率因素,还可提高正确识别率。
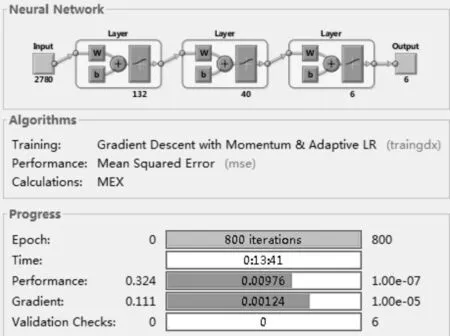
图3 DBN和2个隐层BP网络训练效果比较
参考文献
[1]何蔓微,袁锐,刘建胜,等.垃圾短信的智能识别和实时处理[J].电信科学,2008(8):61-64.
[2]张永军,刘金岭.基于特征词的垃圾短信分类器模型[J].计算机应用,2013,33(5):1334-1337.
[3]李慧,叶鸿,潘学瑞,等.基于SVM的垃圾短信过滤系统[J].计算机安全,2012,13(6):34-38.
[4]万晓枫,惠孛.基于贝叶斯分类法的智能垃圾短信过滤系统[J].实验科学与技术,2013,11(5):44-47,76.
[5]胡龙茂.中文文本分类技术比较研究[J].安庆师范学院学报:自然科学版,2015,21(2):49-53.
[6]Schmidhuber J.Deep learning in neural networks:an overview[J].Neural Networks,2015,61(1):85-117.
[7]Bengio,Ducharme R,Vincent P,et a1.A neural probabilistic language model[J].Journal of Machine Learning Research,2003(3):1137-1155.
[8]Mikolov T,Chen K,Corrado G,et a1.Efficient estimation of word representations in vector space[C].Scottsdale,Arizona:ICLR Workshop,2013.
[9]Hinton G E,Osindero S,The Y W.A fast learning algorithm for deep belief nets[J].Neural Computation,2006(18):1527-1554.
[10]Tieleman.Training restricted boltzmann machines using approximations to the likelihood gradient[C].Helsinki,Finland:ICML,2008.
[11]刘建伟,刘媛,罗雄麟.玻尔兹曼机研究进展[J].计算机研究与发展,2014,51(1):1-16.
[12]Kazuhiro Shin-ike.A two phase method for determining the number of neurons in the hidden layer of a 3-Layer neural network[C].Taipei,Taiwan:SICE Annual Conference,2010.
[13]刘金岭,严云洋.基于上下文的短信文本分类方法[J].计算机工程,2011,37(10):41-43.
欢 迎 投 稿
投稿请登录:www.dianzikeji.org
An Algorithm for Vectoring SMS Based on Word2vec
WANG Guixin1,ZHENG Xiaozong1,ZHANG Haoran1,ZHANG Xiaochuan2
(1.School of Software Engineering,Chongqing Institute of Engineering,Chongqing 402260,China;2.School of Computer Science,Chongqing University of Technology,Chongqing,400054,China)
AbstractThis paper proposes a new method of feature extraction of SMS for better spam message filtering.The method uses the latest results and tools of Word2vec based on deep learning theory.With the content and structure characteristics of Chinese short messages in mind,an algorithm of Vectoring SMS is designed based on this tool.The algorithm can effectively match each text message with a vector.The classification’s experiments on the spam messages are carried out using the proposed algorithm on the deep belief networks.The results show that the performance of the proposed algorithm is improved by 5% compared with the previously reported results.
Keywordsdeep belief nets;deep learning;short messages;vectoring
中图分类号TP29
文献标识码A
文章编号1007-7820(2016)04-049-04
doi:10.16180/j.cnki.issn1007-7820.2016.04.013
作者简介:王贵新(1968—),男,博士研究生。研究方向:机器学习等。
基金项目:国家自然科学基金资助项目(60443004);校内科研基金资助项目(2014xcxtd05;2014xzky05)
收稿日期:2015- 08- 25
猜你喜欢
当代工人(2019年4期)2019-04-22
当代工人(2018年21期)2018-03-06
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
爆笑show(2014年1期)2014-06-23
小雪花·初中高分作文(2009年8期)2009-11-16
