
一种基于词频歧义消解的通用中文分词法
2016-05-31 01:43朱新华陈意山
广西师范大学学报(自然科学版) 2016年1期
关键词:词频
彭 琦,朱新华,陈意山
(1.广西师范大学网络中心,广西桂林541004;2.广西师范大学计算机科学与信息工程学院,广西桂林541004;3.广西师范大学漓江学院,广西桂林541006)
一种基于词频歧义消解的通用中文分词法
彭琦1,朱新华2,陈意山3
(1.广西师范大学网络中心,广西桂林541004;2.广西师范大学计算机科学与信息工程学院,广西桂林541004;3.广西师范大学漓江学院,广西桂林541006)
摘要:歧义是在基于词典的分词方法中常见的问题,以往的基于词典的分词方法往往使用双向最大匹配法获得分词结果后,通过使用上下文信息来进行歧义消解,但是对于没有上下文信息的单独语料无法进行歧义消解。本文提出一种通用的基于词频的歧义消解法,该方法是与上下文无关的,能够消解没有上下文信息的语料切分后产生的歧义,扩大了歧义消解的应用范围,简化了歧义消解的处理过程。实验表明:文本方法与传统基于词典的分词算法相比,具有更强的适用性及更高的可用性。
关键词:中文分词;词频;歧义消解
0引言
中文分词被誉为中文信息处理的“桥头堡”,不仅因为分词是自然语言处理中的基础性任务,也缘于中文分词在中文信息处理中的重要地位[1]。在以往的研究中,中文分词算法的主流有基于统计学习的分词和基于词典的分词2种,这2种分词方法各有所长,也都有不足。基于统计学习的分词方法能够较好地识别未登录词并减少歧义,在分词精度上胜于基于词典的分词方法[2],缺点在于需要大量经过人工处理的语料进行训练。日常生活中人们常用的语言搭配是随着时间不断变化的,陈旧的语料训练出的基于统计的分词方法难以驾驭人们日益更新的语言习惯,且人工进行语料库更新是十分巨大繁琐的工作,国内没有能够获取并持续更新的语料库,这是基于统计学习的分词方法所遇到的阻碍。在基于词典的分词方法中,未登录词造成的分词精度降低和容易产生歧义是它的缺陷所在[3],因此未登陆词识别和歧义处理是衡量一个基于词典的分词系统优劣的重要标准。
回顾以往所提出的歧义处理方法,常需上下文信息的统计进行辨别歧义[4],例如使用互信息原理、N元统计模型、t-测试原理、HMM模型、字标注统计[5]等方法或模型进行上下文信息统计以实现歧义消解,无法在没有上下文信息的情况下进行歧义消解,或者上下文信息量少影响歧义消解的质量。在现实生活中需要切分的语料是多种多样的,并不是所有待切分语料都具有上下文信息,一些需要处理的语料往往是单独的,以单个句子的形式出现并要求切分的。例如在因特网上查询信息时输入的文本、网上聊天和电子邮件中输入的单句、问答系统中用户输入的问句等都没有上下文信息。由此可见基于上下文信息进行歧义消解的方法具有局限性。因此本文提出一种运用词频信息进行歧义消解的方法,试图使用该方法对没有上下文信息的语料进行分词后的歧义消解,扩大可处理语料的范围。
1中文分词算法中的歧义类型
对中文文本进行分词是中文信息处理系统中的首要工作,能否从分词算法中提取有效词语信息是决定该中文信息处理系统优劣的关键。在中文分词过程中,根据不同的切分方法,可能得到不同的结果,哪一结果更趋近于人们理解的范畴,是歧义消解所需进行的工作。根据以往歧义消解领域的工作来看,在中文分词过程中产生的歧义类型可分为真歧义字段和伪歧义字段2种。
1.1真歧义字段
真歧义字段是指对同一字串,有2种或2种以上的理解或切分,无论是哪种理解或者切分,都认为是可行的。例如“在广州大学生活丰富多彩”这一字串,可以理解或切分为“在广州大学/生活丰富多彩”,也可以理解或切分为“在广州/大学生活丰富多彩”;再如“学生会写的文章很多”这一字串,可理解或切分为“学生会/写的文章很多”,也可理解或切分为“学生/会写的文章很多”。对于这类歧义,任何一种理解或切分方式都是可行的。这类歧义字段难以进行歧义消解工作,其占总歧义字段的比例较小,约为6%[6]。因此本文提出的歧义消解方法不对其进行处理。
1.2伪歧义字段
伪歧义字段属于机器形式上的歧义,即同一文本使用不同的切分方法会得出不同的切分结果,但在真实语言环境下,只有唯一正确的切分结果,称其为伪歧义字段。这类歧义字段占歧义总数的94%[7]。伪歧义字段的产生,是因文本切分中形成的交集型歧义字段,交集型歧义定义如下:
定义1在字段ABC中,设A、B、C为子字串,若子字串AB与BC同时存在于词典中,则称ABC为交集型歧义字段。
定义1中,子字串A、B、C可以由一个或多个汉字组成,由于子字串中所含的汉字个数不同,在此引入链长的概念。
定义2交集型歧义字段含有交集汉字的个数称为交集型歧义链长。
歧义字段的交集只含有1个汉字的链长为1,含2个汉字的链长为2,以此类推,含有n个交集汉字的链长为n。例如:交集型歧义字段“的确定”,根据不同的切分顺序可切分为“的/确定”或“的确/定”,交集字段为“确”,由1个汉字成,链长为1。再如,“天安门前”可切分为“天安门/前”或者“天安/门前”,交集字段为“门”,链长也为1。链长为2的交集型歧义字段有:“大学生会”,可切分为“大学生/会”或“大/学生会”,交集字段为“学生”,链长为2。
2基于词频的歧义消解方法
在以往的研究中,歧义消解大多采用基于上下文信息统计的方法进行处理。例如N元统计模型,它是一种考虑上下文语境的统计语言模型[8],其思想认为一个单词的出现与上下文环境中出现的单词序列紧密相关,第n个词的出现与前面的n-1个词相关,而与其他任何词都不相关。设W1W2…Wn是长度为n的字串,那么为了预测词Wn出现的概率,必须知道它前面所有的词出现的概率,并对比切分时产生不同的词可能出现的概率,来进行歧义消解。虽然基于上下文信息的歧义消解方法能够较好地反映字串在整篇文章中的结合紧密程度,具有较好的歧义消解性能,但不适用于没有上下文信息的独立语料,具有一定的局限性。为克服基于上下文信息的歧义消解法必须依赖上下文信息的局限性,本文提出一种基于词频的歧义消解方法,主要分为以下3步:
①从文件中读取词典信息、词频信息及原始语料,放入内存中。使用正、反向最大匹配法分别对原始语料进行切分。正、反向最大匹配法的切分顺序:一种是从句子的开始向末尾结合词,另一种是从句子的末尾向开始结合词,可以有效地判断出哪些字段是可以成为词的字段,即对于字段ABC,如果词典中同时存在AB和BC两个字段,那么使用正向最大匹配法,得到的切分结果是AB/C,使用反向最大匹配法得到的切分结果是A/BC。这样加大了词的判断效果,但是容易产生交集型歧义字段。切分完毕后,将2种切分方法所得到的结果分别存放在2个不同的文件中,以便进行后续的对比处理。
设原始语料中的字串为W,使用正向最大匹配法得到的切分字串序列为X,且X=(x1,x2,x3,…,xn);使用反向最大匹配法得到的切分字串序列为Y,且Y=(y1,y2,y3,…,yn)。
②将切分序列X、Y分别使用正则表达式进行以切分标志为分隔单位的文本匹配,将切分序列放入内存中。将X与Y顺序进行逐项对比,如果切分结果一致,即xi=yi,则表示切分中没有歧义,直接将xi或者yi写入最终的切分结果文件中,并将xi与yi分别从序列X、Y中删除,进行下一项的对比;如果切分的结果不一致,即xi≠yi,则进行歧义处理。
③歧义处理。当xi≠yi时,设歧义字段序列A=(a1,a2,…,am)与B=(b1,b2,…,bm),序列A、B分别为序列X、Y的子串,对于同一原始语料中的字串W,切分成A、B后,其中的汉字总数是不变的,即序列A与序列B所含的汉字个数是一样的,但是分割的方式不一样。在确定了歧义字段序列A、B后,将序列A、B中所含词的词频信息f(a1),f(a2),…,f(am)及f(b1),f(b2),…,f(bm)从词频库中取出,进行求和并计算出平均值fv(A)与fv(B),计算方法如公式(1)所示:

(1)
将fv(A)与fv(B)进行比较,如果满足公式(2),则应采用序列A作为最终切分结果;如果将A与B的位置互换,能够满足公式(2)则应采用序列B作为最终切分结果,其中T为用户指定的阈值;如果这2种情况都不满足,则认为该歧义字段为真歧义字段,不作处理。
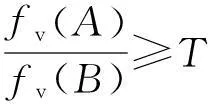
(2)
3系统设计与实现
本文中的分词算法使用Perl脚本语言实现。Perl脚本语言具有较强的文字处理能力,能够运用正则表达式对文本文件中的文字进行查找、替换、删除等工作,其数据类型也较适合存储词表及词频文件。
整个系统的运行过程如图1所示。

图1 系统流程图Fig.1 System flowchart
3.1分词阶段
定义需要进行切分的语料为S=C1C2…Cn,长度为Lenth,最大匹配初始长度为MaxLen,截取最大匹配初始长度的字串为Str,依据正向最大匹配法和反向最大匹配法[9]分别进行分词,将分词结果进行保存,其中正向最大匹配法分词流程图如图2所示。
3.2歧义处理阶段
将分词阶段所产生的文本进行正则式匹配,将正向最大匹配法分词后产生的字串序列存入数组@mmlist,将反向最大匹配法分词后产生的字串序列存入数组@fmmlist。

图2 正向最大匹配法分词流程图Fig.2 Forward maximum matching method flowchart
每次各从@mmlist和@fmmlist取出第一项进行对比,如相同,直接写入最终的分词文件,并删除@mmlist与@fmmlist的第一项;如不相同,即为歧义字串,将歧义字串序列取出,分别计算出字串序列中含有词的词频均值并进行比对,将比值超过阈值的文本存入最终分词文件。具体流程如图3所示。

图3 歧义判断流程图Fig.3 Ambiguity resolution flowchart
4实验测试与结果分析
4.1封闭测试
封闭测试是指只使用指定测试语料中提供的词表文件,或者只使用指定测试语料中的训练语料来获取知识,然后对指定测试语料进行分词处理,并用指定测试语料中提供的正确切分结果与评分标准来考评自己的分词系统[10]。本系统进行的封闭测试使用国际计算语言协会中文语言处理小组(SIGHAN)主办的第二届国际中文语言处理竞赛( Bakeoff2005)所使用的测试集。
4.1.1指标说明
本文使用召回率和精准率这2个指标来评价分词系统。
召回率的计算公式如公式(3)所示:

(3)
精准率的计算公式如公式(4)所示:

(4)
调和均值为召回率与精准率的平均值。
4.1.2阈值选取
在本系统中,阈值的选取能够直接影响切分结果的好坏,根据本系统所需阈值的选取原则,即公式(2)中的分子必须大于分母一定程度后选取分子作为最终结果,因此阈值的选取应从1开始逐渐递增,如选择小于1的阈值,则与本文所述系统逻辑相悖。
选取一组阈值在相同条件下进行封闭测试,得出结果如表1所示。
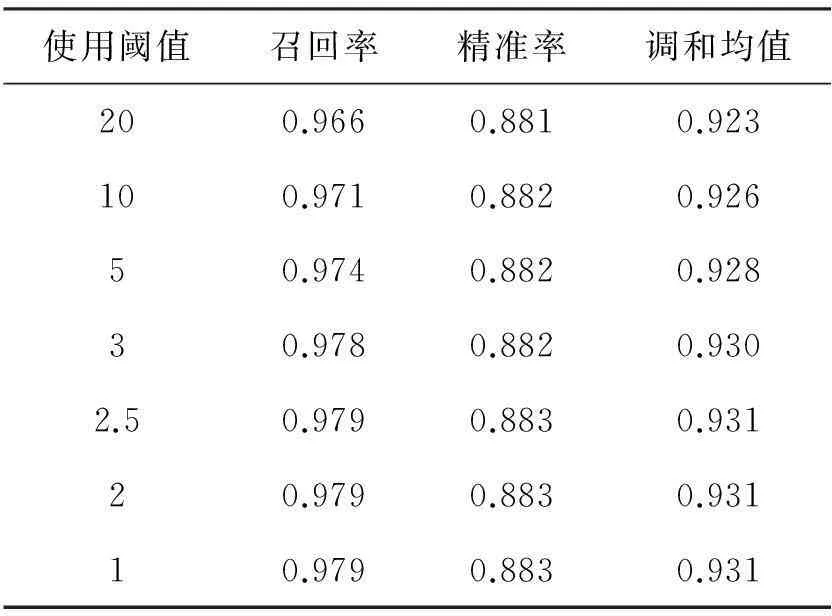
表1 阈值测试结果

表2 封闭测试结果对比
可以看出,在封闭测试中,最优阈值的取值为1至2.5之间,当阈值达到3时会有精准率上的降低,倘若继续增加阈值的大小则召回率及精准率会越来越低。基于以上测试结果我们在进行测试时使用的阈值为1至2.5之间的任何值,用户也可以调整阈值大小来达到所需效果。
4.1.3封闭测试结果对比
在封闭测试中,使用传统的基于词典的正向最大匹配法及反向最大匹配法的测评结果来与本文方法进行纵向比较;使用基于微博语料的统计学习分词方法[11]及中国科学院计算技术研究所研制的汉语词法分词系统ICTCLAS(http://ictclas.nlpir.org)的分词结果进行相同封闭测试中的横向对比,结果如表2所示。
4.2开放测试
开放测试与封闭测试相反,不使用指定测试集来对分词系统进行测评,使用任意的测试语料和通用词典及训练语料来进行系统的考评。通用词典与词频文件来自搜狐研发中心发布的搜狗实验室数据(SogouW,http://www.sogou.com/labs/dl/w.html),词频文件中的词频是Sogou搜索引擎索引到的中文互联网语料统计出的15万条高频词,统计时间是2006年10月。
为使测评结果尽量公平,我们从因特网上下载5篇不同领域的测试语料作为样本,平均样本大小为60 KB,使用指标计算公式及阈值与封闭测试中使用的指标公式与阈值相同,得出测试结果如表3所示。
通过实验数据分析,可以发现本文提出的基于词频的中文分词歧义消解法能够改进传统的基于词典的分词方法的精准率和召回率,相对于其他改进的基于词典的中文分词方法[12],也有一定的优势。

表3 开放测试结果对比
4.3结果分析
综合封闭测试及开放测试的结果来看,本文提出的基于词频的通用分词方法不仅在有上下文信息的语料切分中胜过传统基于词典的分词方法,取得较好的结果,而且能够在没有上下文信息的语料切分中使用,无需经过切分好的语料进行训练,打破了需要使用上下文信息才能进行中文分词歧义消解的僵局,是一种广泛适用的通用中文分词方法。
从公式(3)和(4)可以看出,测评结果中的召回率反映的是该分词系统能够从目标语料中提取多少正确及有用的词语信息,是考量一个分词系统优劣的最重要指标,召回率越高表示一个分词系统能够从用户输入的文本中提取的正确词语信息的能力就越高,特别是在搜索引擎、自动问答系统、电子邮件过滤、信息检索与信息摘录、文本分类和自动摘要、自然语言理解等领域,分词系统的召回率尤为重要。本文分词法在封闭测试及开放测试中都取得了0.9以上的召回率,说明本文分词法提取的正确词语信息的能力还是很强的,达到了实用水平。
精准率不仅体现了一个分词系统提取词语信息的能力,还对分词系统的切分准确性进行了考量,在召回率相同的情况下,精准率越高,表示切分结果的准确度越高,精准率越低,表示分词系统获取相同正确词语信息的效率越低。由于本文分词法是免训练的,其歧义消解需要进行双向切分,因此切分的次数比传统方法要多,使得本系统的精准率在测评结果中欠佳,这是本分词系统免训练而获得较高召回率所必须付出的代价。
特别值得强调的是该方法在搜索引擎、自动问答系统、电子邮件过滤、信息检索与信息摘录、文本分类和自动摘要、自然语言理解等需要对无上下文信息语料进行切分的实际运用领域中的具有较强的实用性。既能够不使用上下文信息,又能准确提取出需要的词语信息,也不需要各领域的语料作为训练对象,是一种通用的中文分词方法。
综上所述,本文提出的基于词频的中文分词歧义消解法不失为一种能够广泛应用于各个需要进行中文分词工作领域的通用分词方法。
5结语
本文提出了一种通过词频信息对双向匹配分词结果进行歧义消解的分词方法,最终实验结果表明:使用该方法进行分词既有较高的提取文本信息能力,又扩大了包含歧义消解模块的分词系统适用范围,不失为一种通用的分词方法。如能添加一种通用的未登录词处理模块并结合专有名词词库进行优化,则能具有更好的分词效果,这也是我们下一步的工作。
参考文献:
[1]QIU Xipeng, HUANG Chaochao, HUANG Xuanjing. Automatic corpus expansion for Chinese word segmentation by exploiting the redundancy of web information[C]//Proceedings of the 25th International Conference on Computational Linguistics: Technical Papers. Dublin: ACL, 2014:1154-1164.
[2]杨尔弘,方莹,刘冬明,等. 汉语自动分词和词性标注评测[J]. 中文信息学报,2006, 20(1):44-49,97.
[3]翟凤文,赫枫龄,左万利. 字典与统计相结合的中文分词方法[J]. 小型微型计算机统,2006,27(9):1766-1771.
[4]费洪晓,康松林,朱小娟,等.基于词频统计的中文分词的研究[J]. 计算机工程与应用,2005,41(7):67-68,100.
[5]ZENG Xiaodong, WONG D F, CHAO L S, et al. Graph-based semi-supervised model for joint Chinese word segmentation and part-of-speech tagging[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. Sofia: ACL, 2013:770-779.
[6]刘开瑛. 中文文本自动分词和标注[M]. 北京:商务印书馆,2000:66.
[7]郑家恒,张剑锋,谭红叶. 中文分词中歧义切分处理策略[J]. 山西大学学报(自然科学版),2007,30(2):163-167. DOI:10.13451/j.cnki.shanxi.univ(nat.sci.). 2007.02.009.
[8]王晓龙,关毅,计算机自然语言处理[M]. 北京:清华大学出版社,2005:49.
[9]赵珀璋,徐力.计算机中文信息处理:下[M]. 北京:宇航出版社. 1989:386.
[10]黄昌宁,赵海. 中文分词十年回顾[J]. 中文信息学报, 2007,21(3):8-19.
[11]ZHANG Longkai, LI Li, HE Zhengyan, et al. Improving Chinese word segmentation on micro-blog using rich punctuations[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics: Volume 2: Short Papers. Sofia: ACL, 2013:117-182.
[12]莫建文,郑阳,首照宇,等. 改进的基于词典的中文分词方法[J]. 计算机工程与设计, 2013,34(5): 1802-1807.
(责任编辑黄勇)
A General Method of Chinese Word Segmentation Based on the Resolution of Word Frequency Ambiguity
PENG Qi1, ZHU Xinhua2, CHEN Yishan3
(1.Network Center,Guangxi Normal University, Guilin Guangxi 541004, China;2.College of Computer Science and Information Technology, Guangxi Normal University,Guilin Guangxi 541004,China;3. College of Lijiang, Guangxi Normal University, Guilin Guangxi 541006,China)
Abstract:Ambiguity is a common problem in dictionary based word segmentation methods. In the past, the word segmentation method based on dictionary often uses the bidirectional maximum matching method to get the result of word segmentation, and then carries out ambiguity resolution by using the context imformation, which cannot be used in the environment without context information. A general disambiguation method based on word frequency is presented in this paper, which is context-free and expands the application range of ambiguity resolution. Experimental results show that compared with the traditional methods of dictionary-based Chinese word segmentation, this method has a stronger applicability and higher availability.
Keywords:Chinese word segmentation; word frequency; ambiguity resolution
中图分类号:TP391
文献标志码:A
文章编号:1001-6600(2016)01-0059-07
基金项目:国家自然科学基金资助项目(61363036,61462010)
收稿日期:2015-08-10
doi:10.16088/j.issn.1001-6600.2016.01.009
通信联系人:朱新华(1965—),男,广西桂林人,广西师范大学教授。E-mail: zxh429@263.net
猜你喜欢
心理科学进展(2022年2期)2022-02-18
内江科技(2021年8期)2021-09-13
亚太教育(2018年5期)2018-12-01
长江丛刊(2017年27期)2017-12-01
智富时代(2017年9期)2017-11-04
智富时代(2017年9期)2017-11-04
档案管理(2017年4期)2017-08-10
黑龙江教育学院学报(2017年3期)2017-03-30
中国修辞(2017年0期)2017-01-31
读者·校园版(2015年7期)2015-05-14
