
面板数据下的线性混合模型及其在车险费率厘定中的应用
2016-06-06 03:20张连增王皎
财经理论与实践 2016年3期
张连增 王皎


摘 要:精算师在进行车险净保费信度厘定时可采用关于面板数据的线性混合模型,本文采用每次交通事故平均损失额和事故发生频率作为车险净保费的计算指标。利用2008~2012年31个省、市、自治区5年的数据,建立面板数据下的线性混合模型,选取人均地区生产总值、每平方公里人口数、民用汽车拥有量作为解释变量,得到每次交通事故平均损失额和事故发生频率的估计模型,进而得到纯保费估计。这一研究可为车险费率市场化提供一定的理论支持和参考。
关键词: 面板数据;费率厘定;车险;费率市场化
中图分类号:F840.65 文献标识码: A 文章编号:1003-7217(2016)03-0022-08
一、引 言
在精算学中,一个基本问题是利用关于某个风险的已知历史索赔及相关外部信息来预测该风险的未来索赔,这就是经验费率厘定问题,因为它与信度理论有密切的联系,所以有时也称为信度厘定问题。车险费率厘定应该根据保险标的风险状况来确定,由于车辆类型、车辆使用者、车辆使用范围、长期行驶线路等不同,风险就存在很大的差异。对单个被保险人来说,理论上讲保险公司要考虑到可获得的被保险人信息,如车型、车辆用途、行驶区域、行驶里程数、性别、驾驶人年龄、交通肇事记录及驾驶行为等因素,从中选出合适的费率厘定变量,进而得到车险净保费。
当前在国际上广义线性模型已被充分应用于车险定价中。国内学者对车险定价的研究也主要集中在广义线性模型方面,较少探讨线性混合模型在车险费率厘定中的应用。孟生旺(2007)简要分析了传统定价方法存在的缺陷,并通过汽车第三者责任保险的损失数据说明了广义线性模型在非寿险产品定价中的具体应用[1]。曾理斌(2007)指出广义线性模型是在风险等级分类基础上的一种非寿险费率厘定方法,可以考虑到各种已识别的风险因素[2]。赵慧卿、王汉章(2011)从索赔频率和索赔额度两个方面利用广义线性模型估计保险费率,分析了从车、从人、从地三个因素的变动对索赔频率和索赔额度的影响[3]。孙维伟、张连增(2013)采用Frees(2010)中汽车第三者责任保险的一组损失数据,在介绍广义线性模型的定义、算法和模型实现的基础上,讨论零调整逆高斯回归模型在汽车保险定价中的具体应用[4]。孙维伟(2014)分析了广义线性模型和广义可加模型的基础和特点,并从Tweedie类分布的视角分析保险索赔额数据的分布[5]。
线性混合模型是线性模型的另一个扩展,尤其适合处理面板数据下的回归问题。一般来说,对面板数据的每个组内,观测量不再有独立性假设。为此通常的线性模型和广义线性模型就不再适用,这就需要采用线性混合模型和广义线性混合模型。因此,线性混合模型与广义线性混合模型在车险定价中的应用研究,必将受到国内外学者的更多关注。
二、面板数据下的线性混合模型
(一)线性混合模型
时间序列数据和截面数据都是一维数据,时间序列是变量按时间先后得到的一组数据,截面数据是变量在给定的时点的一组数据。面板数据兼有时间序列数据与截面数据的特征,可以理解为截面上的个体在不同时点的重复观测数据。与截面数据或时间序列相比,面板数据包含了更多的信息,相应的参数估计更有效;而且在面板数据下,可多层次地分析问题,能够更好地识别出时间序列数据或截面数据不能体现出的特征。
(三)面板数据下的信度模型
信度模型是非寿险定价中经验费率厘定的理论依据。信度理论充分利用已获得的信息,其中包括先验信息和样本信息。设来自先验信息的估计量为M,来自样本信息的估计量为样本均值,信度估计量是对两者的加权平均,即Pc=ζ+(1-ζ)M,其中ζ是信度因子,ζ越大则样本信息更可信。
三、数据来源及模型选定
(一)数据来源及描述
1.数据来源。
本文数据来源于2009~2013年《中国统计年鉴》,样本为我国 2008~2012 年31个省、市、自治区的年度数据。车险费率模型分为两大类:索赔频率模型和索赔金额模型。为了对车险进行费率厘定,选择平均每次事故的损失额(AVE_LOSS)和每辆车每年的出险率(FREQ)为被解释变量,选择人均地区生产总值(PGDP)、民用汽车拥有量(NOC)和人口密度即平均每平方公里人口数(PPSM)作为可供选择的解释变量,每次事故的损失额、人均地区生产总值都与价格指数均有密切联系,因此为了使各年的数据有可比性,绝对数值都以2008年为基年进行了消费指数的平减,剔除了通货膨胀的影响①。
2.数据特征。使用R软件的nlme软件包对面板数据进行分析和建模。表1描述了基本的变量随时间变化的特性,可见平均每次事故的损失金额、人均地区生产总值、人口密度、民用汽车拥有量是随时间增长的,每辆汽车发生事故的频率是随时间递减的。标准差和极值表现出在不同的省、市或自治区之间有实质性的差异。
由于实际的宏观经济变量序列一般呈现出如下特征:随着解释变量值的变化,被解释变量值的差异性一般会越来越大。为了消除可能产生的递增型异方差的影响,本文对31个地区的平均每次事故的损失额(AVE_LOSS)、人均地区生产总值(PGDP)、平均每平方公里人口数(PPSM)数据取自然对数进行处理,分别得到各地区的LN_AVE_LOSS、LN_PGDP、LN_PPSM的面板数据序列,取对数后解释变量的系数表明如果解释变量数值增加1%,导致被解释变量的变化百分比。
图1和图2分别是平均每次事故的损失额(AVE_LOSS)和对数化后的平均每次事故的损失额(LN_AVE_LOSS)随时间变化的散点图,图1和图2的每一条线连接着一个省、市或自治区的时间序列数据,从图1可见每一个省、市或自治区的AVE_LOSS变化有较大差别,而从图2可见,对数化后的数据在不同省、市或者自治区的变化差别较小。因此,下面选用对数化的宏观经济数据, 表2描述了对数化后的平均每次事故的损失金额、人均地区生产总值、人口密度、民用汽车拥有量随时间变化的特性。
图3 表示对数化后的平均每次事故的损失金额与人均地区生产总值随时间变化的散点图,每一条连线表示一个省、市和自治区在2008~2012年随时间变化的情况。由图3可以看出来几乎每个省、市和自治区的平均每次事故的损失金额与人均地区生产总值都是正向关系,平均每次事故的损失金额与人均地区生产总值随时间递增,斜率在各个省、市和自治区几乎是相同的。图4表示对数化后的平均每次事故的损失金额与人口密度随时间变化的散点图,图5表示对数化后的平均每次事故的损失金额与民用汽车拥有量随时间变化的散点图,每一条连线表示一个省、市和自治区在2008~2012年之间的随时间变化的情况。
由于每辆车每年的出险率(FREQ)数值很小,为了方便研究,我们将研究每千辆车每年的出险率。图6表示每千辆车每年的出险率随时间变化的散点图,由图6可以看出每千辆车每年的出险率随时间是逐渐递减的,2008年每个省、市和自治区的每千辆车出险率差异比较大,各省的出险率差异逐年递减。
图7和图8分别表示每千辆车每年的出险率与对数化的人均地区生产总值、人口密度随时间变化的散点图,每一条连线表示一个省、市和自治区在2008~2012年之间的随时间变化的情况,由图7可以看出来几乎每个省、市和自治区的事故发生频率与对数化人均地区生产总值成负相关系,人均地区生产总值越高则出险的频率越低。
图9表示的是对数化的平均每次事故的损失金额随时间的增加变量图(added variable plot),增加变量图也称为部分回归图,是在控制了其它潜在变量的影响之后评价一个变量对另一个变量影响的图形工具。增加变量图可以使我们在控制其它解释变量之后观测被解释变量和一个解释变量之间的关系,使分析者不用关注由其它变量引起的差异性,而仅关注被解释变量y和某个解释变量xj的关系。图9表示对数化的平均每次事故的损失金额随时间的增长在每个省、市、自治区是基本一致的,有一个省的增长率相比于其他省、市、自治区的增长率比较大。
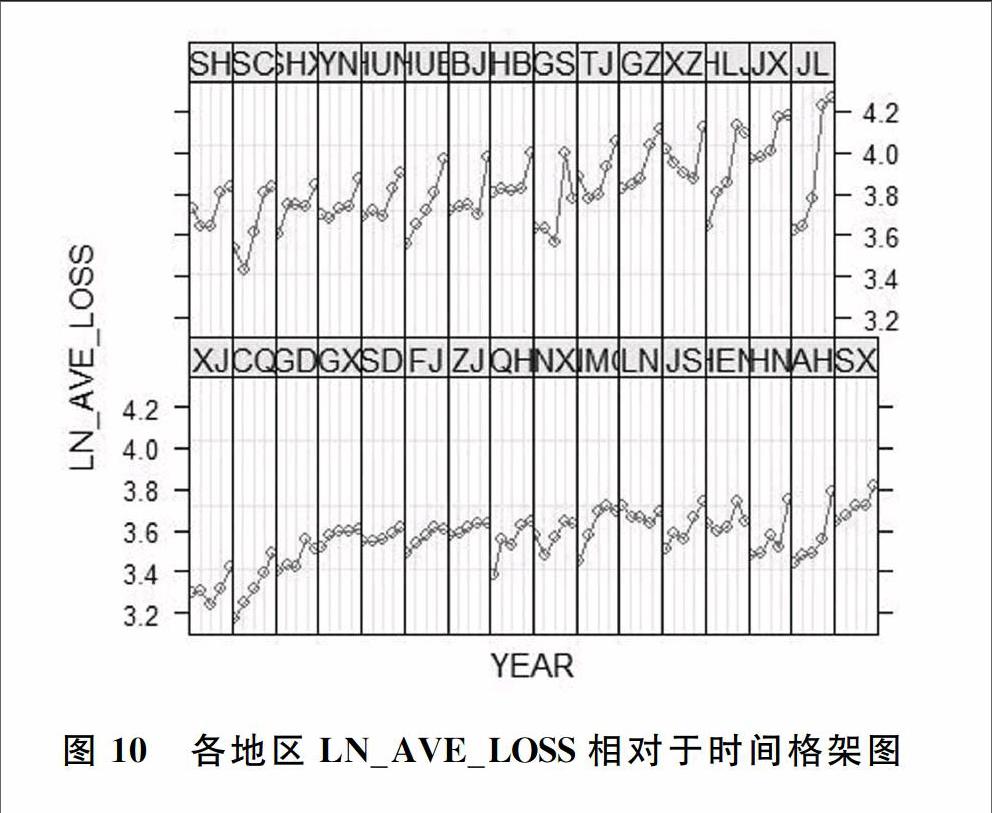
图10和图11分别为对数化的平均每次事故的损失金额和事故发生频率随时间变化的格架图(trellis plot)。格架图把多个面板数据在一个矩阵列中表示出来。图10和图11中的每个面板图都是相似的,但是每一个面板图基于不同的省、市、自治区,这种图形结构的便于验证每一个省、市、自治区对数化后平均每次事故的损失金额的增加和事故发生频率的递减,并从中观测到每一个省、市、自治对数化后平均每次事故的损失金额和事故发生频率的总体水平和斜率。
(二)模型选定及参数估计
根据关于数据特征的描述和基本分析,选用如下线性混合效应模型来拟合平均每次事故的损失金额和事故发生频率,模型选定如下:
四、总结
与时间序列数据模型和截面数据模型进行比较,可见使用线性混合模型分析面板数据时,包含的样本数量更多,对模型参数的估计效果更理想,该模型既能描述总体的一般特征,又能体现出不同个体之间的差异。本文利用散点图、增加变量图等图形工具直观地描述出平均每次事故损失额与人口密度、人均地区生产总值、民用汽车拥有量的关系,及事故发生频率与人口密度、人均地区生产总值的关系,便于精算人员进行模型分析和模型诊断,为研究索赔金额和索赔频率提供了参考。
同时,平均每次事故损失额和事故发生频率的估计可以使用面板数据下的线性混合模型得到,进一步净保费可以用索赔金额与索赔频率的乘积求得。面板数据下的线性混合模型有以下几个优点:有更多的备选模型可供选择,不限于信度模型;统计软件(如R软件)使数据分析更简便;精算人员有另一种解释费率厘定的方法;精算人员可用图形或诊断工具来选择模型并且评价它的适用性。
注释:
①省份按照《中国统计年鉴》的顺序,分别为北京、天津、河北、山西、内蒙古、辽宁、吉林、黑龙江、上海、江苏、浙江、安徽、福建、江西、山东、河南、湖北、湖南、广东、广西、海南、重庆、四川、贵州、云南、西藏、陕西、甘肃、青海、宁夏、新疆。
参考文献:
[1]孟生旺.广义线性模型在汽车保险定价的应用[J].数理统计与管理,2007,(1):24-29.
[2]曾理斌.广义线性模型在非寿险费率厘定中的运用[J].金融经济, 2007,(18): 60-61.
[3]赵慧卿,王汉章.我国车险费率厘定的实证研究——基于广义线性模型的分析[J].天津商业大学学报, 2011,(5): 8-12.
[4]孙维伟,张连增.ZAIG模型在车险定价中的应用研究[J].保险研究, 2013,(4): 43-51.
[5]孙维伟.基于Tweedie类分布的广义可加模型在车险费率厘定中的应用[J].天津商业大学学报,2014,(1):60-66.
[6]Frees E W,Young V R, Luo Yu.Case studies using panel data models [J].North American Actuarial Journal, 2001,(4): 24-42.
(责任编辑:宁晓青)
猜你喜欢
科技创业月刊(2022年7期)2022-09-19
成都信息工程大学学报(2021年3期)2021-11-22
装备制造技术(2021年1期)2021-05-21
汽车维修与保养(2019年4期)2019-11-25
时代金融(2016年23期)2016-10-31
时代金融(2016年23期)2016-10-31
商业经济研究(2016年14期)2016-09-14
中国证券期货(2015年6期)2015-06-16
中国证券期货(2015年6期)2015-06-16
天津商业大学学报(2014年1期)2014-04-16
