
聚类分析在外国语言学研究中的应用
2016-06-21 09:41孙仕光
怀化学院学报 2016年3期
孙仕光, 张 萍
(1.同济大学 外国语学院, 上海 200092; 2.井冈山大学, 江西 吉安 343009)
聚类分析在外国语言学研究中的应用
孙仕光1,2,张萍2
(1.同济大学 外国语学院, 上海 200092;2.井冈山大学, 江西 吉安 343009)
摘要:调查显示,我国大部分外国语言学研究者对聚类分析既缺乏了解也不会应用。本文展示了聚类分析和语料库结合可以应用于外国语言学的很多研究领域:词汇语义、句法型式,以及语言的地理变异、文体变异、社会变异和功能变异。聚类分析不仅是一种统计分析技术,而且具有研究方法论意义,即可以以数据驱动的方式系统性的发现研究变量和生成高质量的假设。还特别指出聚类分析可以作为系统功能语言学的定量化研究的一种重要工具。
关键词:聚类分析;语料库;外国语言研究
一、引言
聚类分析,又称数值分类学,是一种多元统计分类技术。聚类分析在商业、生物、工程、人类学和社会学等很多领域内都得到了广泛的研究和成功的应用。语言学研究中的分类问题随处可见,但是学者们用定性方法分类的比较多,运用计量手段分类的比较少见。高一虹等人的研究表明,我国语言研究统计方法的运用比较薄弱,定量方法有待提高[1,2]。王立非的调查结果显示,某些难度较大和技术性强的统计方法未得到充分运用[3]。赵蔚彬的调查显示,十种外语类核心期刊1995年至2000年之间只有一篇应用聚类分析的文章,聚类分析是应用最少的统计方法之一[4]。鲍贵调查了10中外语期刊中10年期间统计方法使用情况,发现如下:多元统计使用率虽然有微弱增长的迹象,但是其使用比率远低于简单推理统计和纯描述性统计[5]。鲍贵报告了多种多元统计方法的使用情况,但是他的调查报告中没有出现聚类分析的使用情况,这似乎显示聚类分析是我国外语研究者使用最少的统计方法之一[5]。以上研究调查的对象的范围、时间段都有限,不是很全面、系统。聚类分析在我国外国语言学研究中应用的总体的情况如何呢?数学基础相对薄弱的外国语言学方向的高校教师是否理解并掌握这一数学工具?她(他)们能否把这一方法运用到语言研究中去?在本文中,我们针对这两个问题进行了调查研究,并对聚类分析在外国语言学研究中的应用做了一些介绍和总结。
二、聚类分析简介

一般来说,语言学学者是根据一个指标对一些对象定性地分类的。但是当面对多个指标,特别是包括定距、定比数量指标时,这种分类方式就无能为力。这时,聚类分析就可以派上用场。我们可以用一个特征向量来代表每个对象,然后对之聚类。聚类分析可以用来探索、揭示数据内部的结构、模式以及各个变量(特征)之间的联系。聚类分析的方法(算法)丰富多样,并且一直处在蓬勃发展中,各种新的聚类方法被不断提出和改进。根据我们的观察,聚合型层次聚类法是语言学研究中应用最广泛的一种方法。
三、聚类分析在我国外国语言学学界的应用现状
本文研究的问题是:1.聚类分析在我国外国语言学研究中应用的总体情况如何?2.我国外国语言学方向的高校外语教师是否理解并掌握这一数学工具?3.她/他们能否把这一方法运用到语言研究中去?
为回答问题1,我们以知网中全部的哲学人文社科文献(包括了外国语言学研究文献)为对象做了调查。这些文献是全国1950年至今的哲学人文社科类全国期刊、硕博士论文、重要会议论文全文数据。我们在其内部各个学科文献分类中,以“聚类”一词作为在论文全文、摘要中出现的词分别进行搜索,我们可以看到各个学科中有多少篇论文含有“聚类”这个词。这些数字反映了聚类分析在各学科中被使用的频繁程度。具体数字如表1(只列出数量最多的前10名学科)。

表1 哲学与人文社科内部各学科含有“聚类”一词的论文篇数
从表1中数字反映的情况来看,哲学与人文社科各学科中应用聚类分析最多的是心理学,其次是中国语言文字,外国语言文字占第三位。外国语言文字使用聚类分析的频率大约为中国语言文字学科的一半左右。这两个学科性质近似,但频数相差较大,说明聚类分析在外国语言文字中还有较大的应用空间。含有“聚类”一词(在全文中出现)的论文数量在心理学、中国语言文字和外国语言文字三个学科中的时间分布情况如图1。

图1 三个学科中含有“聚类”一词的论文数量的时间分布
由于1990年以前含有“聚类”这个词的论文数量极少,我们舍弃了1990年以前的部分。从图中可以看出,在2003年之前极少有使用聚类分析方法的外国语言文字方面的论文,每年不超过5篇。2003年之后,聚类分析的使用稳步增长,频数最高的一年,即2014年,有73篇文章中出现了“聚类”一词。这些仅是外国语言文字学科中全文中出现“聚类”一词的论文篇数,实际应用聚类分析的外国语言文字方面的论文的篇数可能会更少。
可以看出,外国语言文字学科中聚类分析的使用是很少的。这与这个学科量化研究的需求、与我国庞大的从事外语研究的高校外语教师和研究生的人数是不相称的,是偏少的。我们认为产生这种状况产生的原因可能是因为我国外语研究者对聚类分析研究方法不了解、不熟悉或者没有意识到聚类分析在外语研究中的价值。
为了了解我国高校外语教师对聚类分析的了解、掌握情况,也就是上文中第2、3个问题,我们给iResearch学术交流QQ群的566名成员以电子的形式发去了调查问卷。iResearch群是一个外语语言学学术交流群,群成员是来自于全国各地、各种层次的高校的外语教师。可以近似地认为这个群中所有从事外语语言学研究的成员是全国从事外语语言学研究的高校外语教师的一个随机样本。我们回收得到有效答卷408份,有效回收率为72%。然后我们按照分层随机抽样的原则随机选择这些有效答卷中的一部分答卷,使得这些答卷尽量平衡覆盖全国各省(直辖市、自治区)、各省内各地区、各高校。这样就使得选择后的样本答卷具有更好的代表性。最后357份答卷进入数据分析。调查得到的结果如表2、3。

表2 高校外语教师对聚类分析方法的了解程度

表3 高校外语教师的聚类分析应用能力
由表2可知,高校外语教师绝大部分对聚类分析完全不了解,这部分人占了86.3%。有7.8%的高校外语教师对聚类分析稍微了解;仅有3.1%、2.2%、0.6%的高校外语教师分别对聚类分析有一般程度的了解、比较熟悉和非常熟悉。在聚类分析的应用能力方面,表3显示:只有5%的高校外语教师具有应用聚类分析解决问题的能力,绝大部分不具备这种能力(95%)。
表2和表3显示的结果是较为一致的,即绝大部分高校外语教师不了解、不会应用聚类分析方法。这也揭示了高校外语教师至少对多元统计分析方法的掌握是不够全面的。如果高校外语教师对多元统计手段缺乏全面、深入的理解和掌握,他们的科研能力必定会受到很大的限制,因为外国语言学研究中很多问题是靠单因素研究手段不能解决的。面对我国高校外语教师对聚类分析及其在外语研究中的应用缺乏了解的现状,我们认为有必要介绍和总结聚类分析在语言学研究中的应用情况,以资了解和启发。
四、聚类分析在语言研究中的应用领域
聚类分析被应用于语义、句法型式、认知语言学、心理语言学、计算语言学和社会语言学等研究领域中。聚类分析的应用一般是与语料库数据结合。具体应用领域如下:
(一)词汇语义学
语言学中存在这一假设:语言项目的语境分布信息揭示了这个语言项目的语义、功能特点。语言成分的意义就是这些语言成分的分布条件或限制。比如,Firth提出了名句:“观一词之同伴可知一词”(You shall know a word by the company it keeps)[6];Hanks指出:“动词的语义由它的补足语模式决定。”[7]语料库提供了词的分布环境信息,比如共现词及其频率,共现的语法型式或构式及其频率信息。根据语料库提供的这些共现特征的频率信息,聚类分析可以用来较客观、系统地辨析近义词、反义词的意义和用法。Gries提出的词汇行为轮廓(Behavioral Profiles)研究方法就是这种利用聚类分析的方法,感兴趣的读者可以参阅Gries(2012)[8]。有趣的是,Divjak & Gries用实验证明了同(近)义词的类或簇具有心理现实性[9]。聚类分析在词汇语义学中的应用对词典编纂、外语教学有很实用的价值。
(二)句法型式研究
聚类分析可以帮助我们对语料库中的句法结构进行聚类,帮助我们进行经验数据性的句法研究。比如我们可以对语料库中某单词的全部索引行进行聚类,识别、提取该词汇(比如动词)的全部句法型式(pattern),从而取得对特定单词的句法行为的全局性的、系统性的认识[10]。这对数据驱动的句法研究、词典编撰、外语教学有很大的价值。
型式就是由动词、名词和形容词与其补足语成分组合而成的短语单位[11],如V from n into n,其中V表示核心词,from和into指具体词项,n表示名词短语。型式语法研究的目的则在于抽象归纳出不同词类的所有型式。
聚类分析抽取、概括句法型式的做法如下:先建构句法型式的一系列特征集合;继而将每个索引行中的具体语言信息转换为对应的型式特征信息;然后采用相似度算法对同一检索词析出的索引行进行聚类分析;进而提取每组索引行中的公共特征项;最终实现相关单词的句法型式的自动识别与提取,如图2。
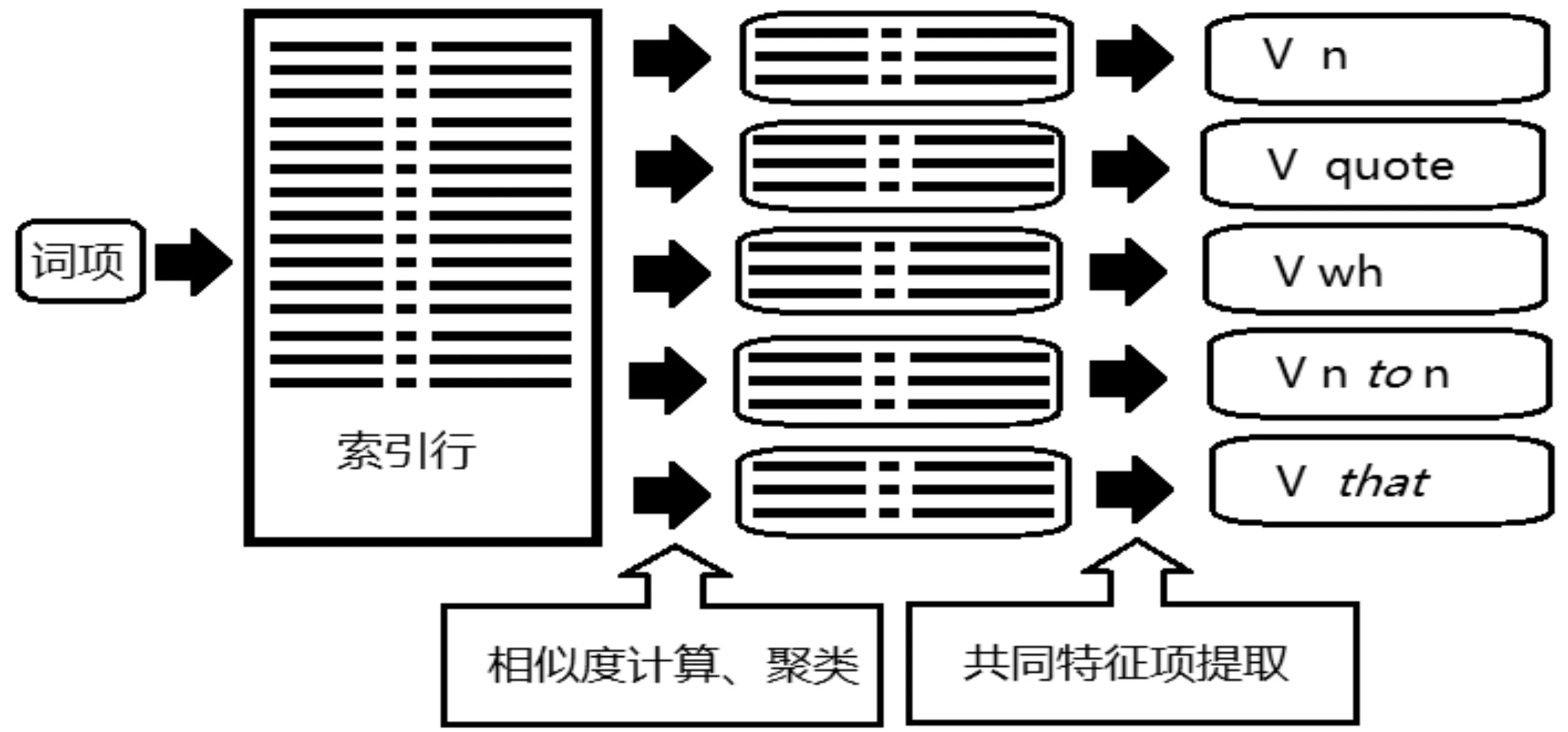
图2 通过聚类分析从索引行抽象、概括句法型式[10]
(三)语言的文体(风格)变异研究
一个语篇会呈现出各种语言结构单位的使用统计特征。这些统计特征包括:词长、句长、型符类符比、单现词比例、词性比例、句型比例等。很多研究证实各种语言结构特征在不同体裁的文本中客观地存在着变异[12,13]。语言风格、文体、体裁是由于各种语言结构单位的特征的频率分布差异而产生的。这些频率分布的差异构成了分析语篇风格、文体的物质基础[14]。通过各种特征对文本进行统计分析的思想最早见于数学家Morgan在1851年的猜想和建议。研究者可以根据这些语言结构单位统计特征实现对不同风格、文体的文本或语篇的聚类[14-16]。
另外,一个作者也会在语言产出中表现出各种语言结构单位的个性化使用统计特征,好比这个作者的“语言指纹”。我们可以对一个作者的很多作品的语言使用情况进行统计,得出这个作者对各种语言结构单位使用的统计特征,这些统计特征就是他/她的“语言指纹”。从相反的角度来讲,我们可以根据一些已知的作者的“语言指纹”,把作者身份已知的文本与作者身份未知的文本进行文本聚类分析或相关分析,然后根据分析结果来识别这些匿名作品的作者,或对识别作者身份提供参考[15,16]。比如,李贤平对《红楼梦》的120回进行聚类,发现前80回和后40回分别被聚为两大类,词汇使用统计特征截然不同。李贤平据此提出自己的看法:《红楼梦》前80回是曹雪芹所作,后40回是高鹗等人增补而成[15]。
(四)语言的地理变异:方言聚类
方言分类研究是语言学中应用聚类分析最早的一个领域。Goebl在1982年首先把聚类分析应用于方言分类的研究之中并取得成功[17]。自此以后,聚类分析在以Goebl和Nerbonne为代表的欧洲方言计量学研究中继续得到广泛而成功的应用。
在汉语方言研究领域,郑锦全和陆致极是应用聚类分析应用研究方言分类问题的开拓者[18,19]。运用聚类分析对汉语方言进行分类的其它研究还有:马希文[20],邓晓华和王仕元[21],王士元和沈钟伟[22]等。聚类分析已经成为了我国方言研究领域中一种重要的研究方法。
(五)语言的社会变异、功能变异研
语言变异与社会结构的关系很复杂,用传统的一般研究手段无法处理。传统的研究方法中,研究变量的选择、假设的建立都是研究者根据某种理论框架、既有的一些研究个案、个人在一个研究领域的经验或者灵感进行的。这是至今仍然通行的研究方法。虽然我们不否认这种研究方法的意义,但是我们必须承认的是:这种传统的研究方式是瞎子摸象式的,具有一定盲目性,而且有时候是东一榔头西一棒子,缺乏系统性。根据个人的经验或灵感提出的语言研究假设带有一定的盲目性,因为与大规模的语言数据相比,个人的经验、灵感总是有限的。聚类分析可以克服这些局限。聚类分析帮助研究者从大规模语言数据中发现数据的结构,根据数据结构系统性地发现、提取与研究现象显著(这里不是指狭义上的显著:统计显著)相关的研究变量,系统性的发现变量之间的相关性,据此提出假设,作为建构理论模型的基础。这种大规模数据驱动的变量和假设发现方法更有系统性、全局性,并且减少了盲目性。
比如,Jones-Sargent利用聚类分析方法分析了地方方言的语音数据,探索了语音变异与社会因素各水平的变异之间的联系,得出了一些有趣的社会语言学假设[23]。Moisl等人对英国Tynside地区英语方言语料库中的语音数据进行聚类分析后发现,该地区的语音的系统性变异与社会因素(如性别、职业、教育水平)相关[24,25]。
从Moisl等提出的语音变异与社会因素之间关系假设可以看出,聚类分析对研究人员具有重要的方法论意义,而不只是一种具体的统计分析技术:聚类分析可以帮助研究者鸟瞰、总览大规模语言数据,从中发现全局性的数据结构;聚类分析可以帮助研究者以数据驱动的方式全面、系统地找出明显与研究问题相关的研究变量、变量之间的关系,有针对性地提出假设。这种方法不仅适用于社会语言学研究,也适用于其它一些语言学研究领域、语言学理论框架内的研究,比如下文中要讨论的把聚类分析应用于系统功能语言学中语域研究的案例。
聚类分析可以发挥用武之地的另一个领域是对语言的功能变异的研究,比如对语言功能变体—语域的研究。语域是指各种各样的受情景因素支配的语言变体[26]。语域的例子有:新闻广播、演说语言、广告语言、课堂用语、家常谈话、与幼童谈话等。基于大型语料库,Douglas Biber运用因子分析、层次聚类分析等统计技术开创了语言语域变体的多维研究[27-30]。自建立以链,这种多维度分析方法以其宏观的研究视角和对统计技术的精巧运用得到研究者的青睐,在语料库语言学中占有独特的地位。其它的研究还有Gries,Newman & Shaoul[31]。他们利用了BNC幼儿语料库和ICE-GB语料库中不同长度的N元组作为层次聚类的基础,识别了不同语域之间的亲疏关系。
研究者可以按照词频、词长、句长、句子结构复杂度、各种词类的比例等指标对大量的、类型多样的语篇聚类,并按照图9所示的方式,探索、发现聚类结果与语场、语旨和语式各变量或子变量的关系(比如语旨变量内有权利关系、接触频率、感情投入等子变量),然后根据观察到的变量之间的关系提出研究假设,作为进一步研究的基础,或者是作为认识聚类指标变量与语境变量关系的参考。根据这个案例我们可以看到,聚类分析可以成为系统功能语言学的定量研究的一个重要工具。当前我国的系统功能语言学定量化研究还很不足。从研究方法上看,系统功能语言学的研究,比如语域、体裁的研究,和语料库结合的还比较少。系统功能语言学领域内的学者可以学习Biber和Moisl等人的研究,利用聚类分析等多元分析工具,和语料库数据结合,更广泛地探索、开展系统功能语言学的定量化研究。
五、聚类分析的优势、不足和在语言学研究中的应用前景
聚类分析这种分(聚)类方法的优势之一是比定性的分类方法更具有客观性和可重复性。聚类分析是基于事实、数据的,所以说它具有客观性。当然,这并不是说,聚类分析完全排除了主观因素。聚类数值特征、算法的选择、距离计算方式等方面的选择仍然带有一定的主观性。但是,聚类分析中指标(特征)、类的定义、距离计算方式、算法等参数一旦被人们设定,这种分(聚)类就具有可重复性、可检验性,也提供了不同分(聚)类方法优劣比较的基准。依靠主观定性分类的方法重复性较低,因为专家和新手各自的理论素养、经验和直觉差别很大,也很难复制,他们各自的分类结果也会相异。我们知道客观性和可重复性是科学研究的要求和基本特点,所以,可以说聚类分析比定性分类更具有科学性。
聚类分析的另一个优势是它可以处理大规模的数据。人类面对小数据,可以发现其中的结构,提出猜想和假设。但是当人类面对复杂的大数据时,人的认知能力局限使得他们难以穿透其中并发现数据中的结构和规律,也难以提出合理的猜想或假设。聚类分析可以对复杂的大数据进行高速、准确的处理,发现大数据中的结构、规律,帮助人们提出更合理的假设,例如我们在上文中提出的聚类分析用于产生假设的案例。
聚类分析的不足是输出结果存在稳定性和效度问题。项梦冰所做的方言聚类分析实验表明,聚类分析是一种倚重数量关系的分析,采用的方法不同,结果也往往有差异。她指出聚类分析可以给分类工作提供重要的参考,但倘若奉之为圭臬则未免失于偏颇[32]。这一看法与学术界对聚类分析的看法一致,即:聚类分析本质上是探索性数据分析,用来探索、发现数据的内在结构,聚类结果只能用作参考。
多种因素会影响导致聚类结果的稳定性或效度:特征(指标、变量)的选取、特征权重的分配、类的定义、距离的计算方法等。对聚类结果的质量或效度的评估和优化、提高也是聚类分析工作的一个环节,也是一个被广泛探讨的研究领域。效度高的聚类分析结果不是一蹴而就的,聚类分析是一个精心准备、反复比较、调试、优化提高输出结果的过程。
大数据时代,语料库数据越来越丰富,聚类算法等数据挖掘技术也越来越精进、成熟。当前,越来越多的学者对内省式的语言数据提出批评和质疑,转为倾向于使用语言用法数据[33-35]。Bresan等人指出基于语言直觉的语言数据不可靠,而基于语言用法数据的语言研究更加坚实、更具有生态效度[33]。冯志伟也指出小数据得到的语言知识是有限的、不可靠的,语言学者应该从语料库中挖掘语言知识[35]。可以想见,未来越来越要依靠对较大规模的语言数据进行数据挖掘得到语言知识。大规模的语言数据靠人工、肉眼是无法处理的。此时,聚类分析等数据挖掘方法就是我们的工具。外语研究者应该掌握包括聚类分析在内的数据挖掘技术,以使自己的研究跟得上时代潮流。
六、结语
聚类分析是基于语料库语言用法数据的语言研究的一个有力的探索性工具。本研究的调查显示,我国大部分外国语言学研究者对聚类分析既缺乏了解也不会应用。本文指出聚类分析和语料库结合可以应用于外国语言学的很多研究领域:词汇语义、句法型式,以及语言的地理变异、文体变异、社会变异、功能变异和历时变异等。并且,聚类分析不仅是一种统计分析技术,而且具有研究方法论意义,即可以以数据驱动的方式系统性的发现研究变量和生成假设。本文特别指出聚类分析可以作为系统功能语言学的定量化研究的一种重要工具。
参考文献:
[1]高一虹,等.中、西应用语言学研究方法发展趋势[J].外语教学与研究,1999(2).
[2]高一虹,等.关于外语教学研究方法的调查[J].外国语,2000(1).
[3]王立非.应用语言学统计研究方法的实证调查——态度与实践[J].外语研究,2002(1):66-70.
[4]赵蔚彬.十种外语类核心期刊(1995-2000)统计手段使用调查[J].解放军外国语学院学报,2002(9):65.
[5]鲍贵.我国外语教学研究中的统计分析方法使用调查[J].外语界,2012(1):44-51.
[6]Firth,J.R.Papers in linguistics[C].Oxford:Oxford University Press,1957.
[7]Hanks,P.Contextual Dependency and Lexical Sets[J].International Journal of Corpus Linguistics,1996,1(1):75-98.
[8]Gries,S.Behavioral Profiles:A Fine-grained and Quantitative Approach in Corpus-based Lexical Semantics[C]//Gonia Jarema,Gary Libben,& Chris Westbury.Methodological and Analytic Frontiers in Lexical Research.Amsterdam & Philadelphia:John Benjamins.2012:57-80.
[9]Divjak,D.S.& S.Gries.Clusters in the Mind? Converging Evidence from Near Synonymy in Russian[J].The Mental Lexicon,2008,3(2):188-213.
[10]于涛.基于索引行聚类的英语动词型式自动识别与提取研究[D].北京:北京外国语大学,2015.
[11]Hunston,S.& G.Francis.Pattern Grammar:A Corpus-Driven Approach to the Lexical Grammar of English[M].John Benjamins,2000.
[12]Biber,D.Variation across speech and writing[M].Cambridge University Press,1988.
[13]Swales,J.M.Genre analysis,English in academic and research settings[M].Shanghai:Shanghai Foreign Language Education Press,2001.
[14]陈芯莹,李雯雯,王燕.计量特征在语言风格比较及作家判定中的应用——以韩寒《三重门》与郭敬明《梦里花落知多少》为例[J].计算机工程与应用,2012,48(3):137-139.
[15]李贤平.《红楼梦》成书新说[J].复旦学报(社会科学版),1987(5):3-16.
[16]肖天久,刘颖.基于聚类和分类的金庸与古龙小说风格分析[J].中文信息学报,2015(9).
[17]Goebl,H.Dialektometrie:Prinzipien und Methoden des Einsatzes der numerischen Taxonomie im Bereich der Dialektgeographie[M].Vienna:Verlag der sterreichischen Akademie der Wissenschaften,1982.
[18]陆致极.闽方言内部差异程度及分区的计算机聚类分析[J].语言研究,1986(2):9-16.
[19]郑锦全.汉语方言亲疏关系的计量研究[J].中国语文,1988(2):234-249.
[20]马希文.比较方言学的计量方法[J].中国语文,1989(5).
[21]邓晓华,王仕元.中国的语言及方言的分类[M].中华书局,2009.
[22]王士元,沈钟伟.方言关系的计量表述[J].中国语文,1992(2).
[23]Jones-Sargent,V.Tyne Bytes:A computerised sociolinguistic study of Tyneside[M].New York:Peter Lang International Academic Publishers,1983.
[24]Moisl,H.,W.Maguire,& W.Allen.Phonetic Variation in Tyneside:exploratory multivariate analysis of the Newcastle Electronic Corpus of Tyneside English[C]//F.Hinskens.Language Variation—European Perspectives.Amsterdam:John Benjamins,2006:127-142.
[25]Moisl,H.& W.Maguire.Identifying the Main Determinants of Phonetic Variation in the Newcastle Electronic Corpus of Tyneside English[J].Journal of Quantitative Linguistics,2008(15):46-69.
[26]张德禄.语域变异理论与教学[J].山东外语教学,1990(1):45.
[27]Biber,D.The multi-dimensional approach to linguistic analyses of genre variation:An overview of methodology and findings[J].Language Resources and Evaluation,1992(26):331-345.
[28]Biber,D.University Language:A Corpus-based Study of Spoken and Written Registers[M].Amsterdam:John Benjamins,2006.
[29]Biber,D.Multi-dimensional Approaches[C]//A.Lüdeling & M.Kytø.Corpus Linguistics:An International Handbook,Vol 2.Berlin:Walter de Gruyter,2009:822-855.
[30]荣红.基于多维度分析模式的语言变异研究综述[J].河北大学学报(哲学社会科学版),2008(1):107.
[31]Gries,S.,J.Newman,and C.Shaoul.N-grams and the clustering of registers[J].Empirical Language Research,2011,5(1).
[32]项梦冰.聚类分析在汉语方言研究中的运用[J].语文研究,2015(4).
[33]Bresnan,J.,Cueni,A.,Nikitina,T.,& Baayen,R.H.Predicting the dative alternation[C]//G.Bouma,I.Kraemer,& J.Zwarts.Cognitive Foundations of Interpretation.Amsterdam:Royal Netherlands Academy of Arts and Sciences,2007:69-94.
[34]Manning,C.Probabilistic Syntax[C]//R.Bod,J.Hay,& S.Jannedy.Probabilistic Linguistics.Cambridge,Massachusetts:The MIT Press,2003:289-341.
[35]冯志伟.论语言学研究中的战略转移[J].现代外语,2011(1):1-11.
Cluster Analysis and its Applications in Foreign Language Studies
SUN Shi-guang1,2,ZHANG Ping2
(1.SchoolofForeignLanguages,TongjiUniversity,Shanghai200092;2.JinggangshanUniversity,Ji’an,Jiangxi343009)
Abstract:A survey indicates that most foreign language researchers across China lack an understanding of cluster analysis and cannot apply it in linguistic studies.Based on the analysis of corpus data,the authors of this paper hold that cluster analysis can be used in the following areas:lexical semantics,syntactic pattern studies,dialectology,stylistic,social and functional variation of language.Besides being a statistical technique,cluster analysis also has methodological implications:it can help researchers systematically discover variables relevant for subject matter;and it is a tool of generating high quality hypotheses in a data-driven way.It is also pointed out that cluster analysis can serve as an important quantitative research tool for systemic functional linguistics.
Key words:cluster analysis;corpus;foreign language studies
收稿日期:2016-02-17
作者简介:孙仕光,1975年生,男,山东临沂人,讲师,博士研究生,研究方向:功能语言学,语料库语言学。
中图分类号:H087
文献标识码:A
文章编号:1671-9743(2016)03-0108-06
猜你喜欢
文化创新比较研究(2020年13期)2021-01-14
天津外国语大学学报(2020年1期)2020-03-25
大经贸(2016年9期)2016-11-16
中国市场(2016年33期)2016-10-18
科技视界(2016年20期)2016-09-29
企业导报(2016年9期)2016-05-26
语言与翻译(2015年4期)2015-07-18
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
外语教学理论与实践(2014年4期)2014-06-13
