
海量随机数碰撞率检测的快捷方法
2016-08-16 15:46孟秀哲杨栋毅
计算机时代 2016年8期
孟秀哲 杨栋毅
摘 要: 针对海量随机数碰撞率实时检测的需求,利用随机数的随机特性,结合文件系统路径编码的方式,提出了一种类似于平衡B叉树的平衡检索森林的结构与算法。该方法避免了平衡B叉树的编程复杂性,检测效率非常高,有效地解决了海量随机数碰撞率检测因耗时量过大而难以在工程上快速实现的问题。
关键词: 随机数; 海量随机数; 碰撞率检测; 路径编码; 平衡检索森林
中图分类号:TP391 文献标志码:A 文章编号:1006-8228(2016)08-44-03
Abstract: For the demand of real-time detection of massive random number collision rate, by using the stochastic properties of the random number and the file system path coding, a method of balanced search forest similar to the balanced B search tree is proposed. This method avoids the programming complexity of the balanced B search tree, and the detection efficiency is very high. It can effectively solve the problem that the collision rate detection of massive random number is too much time consuming to be quickly realized in engineering.
Key words: random number; massive random number; collision rate detection; path coding; balanced search forest
0 引言
随机数对于系统仿真[1]、信息通讯[2]、计算机随机模拟[3]、随机局部搜索[4]、密码研究[5]、随机验证码、彩票博弈、实验设计和随机抽样等领域或方面都有着十分重要的作用。随机序列的随机性,主要体现在两个方面,一是这个序列的产生是无法确定的,而且是不可以复现的;二是这个序列具有统计特性,当序列足够长时,其中的0和1的个数趋于相等,即具有0、1的均匀性。前者可以用碰撞率来测度,后者可以用均匀性来测度。碰撞率就是读取或产生一系列的32位随机数,统计随机双字的重复次数,最理想的结果就是碰撞次数为0。
海量随机数的数据量非常大,常常是边产生边检验,这就需要维持一张表,不断登记检测过的随机数,统计键值重复的次数。随着检测过程的不断加长,这张记录表会越来越大。如果采用顺序查找,则编程简单,但效率低下,平均查找次数约为(N+1)/2[6],N为表中记录数。如果采用二分查找,则需要对顺序表进行排序,开销可能超过二分查找所节省的时间。“使用二叉树结构,不仅能有效地查表,而且还能迅速地插入和删除记录”[7],二叉树结构因为复杂而使得编程变得困难。为此,我们提出了用于海量随机数碰撞率实时检测的平衡检索森林的巧妙思想与简捷方法。
1 平衡检索森林的基本原理
1.1 基本思想
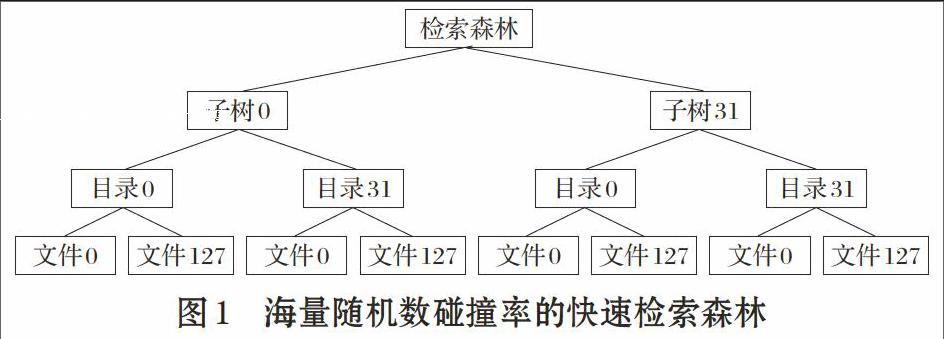
在平衡检索森林中,叶子文件的访问是通过随机数位段编码的方式均匀地进行,叶子文件访问的均匀性源于随机数位段的随机性。快速检索森林是静态平衡的,而不需要像平衡B叉树那样,需要动态维护节点的平衡[8],这是快速检索森林的一大特性与优势,即没有额外的维护开销。通过对每个随机数四个位段的编码(详见2、平衡检索森林的编码规则),分别形成子树、目录和文件的地址,以及,记录的键值。路径与键值两方个面的编码使得叶子文件均匀分布在整个检索森林之下,巨大单一文件被分割为巨量小文件。
假定随机数具有30比特有效信息,则不重复随机数文件最多有230=1073741824条记录,接近海量数据。我们不是在一个巨型文件中存储或检索这10亿多条记录,而是将这棵巨大无比的单枝树,人为地切分成一片均匀森林,由32棵树组成,每棵树有32个树杈,每个树杈下面有128片叶子,叶子即子文件,每个叶子最多只有8192条记录。叶子文件共有:32*32*128=25*25*27=217=131072(个)。对于一个30比特的随机数进行检索的过程,实际上就是根据键值的四个位段来定位某棵树、某树杈、某文件及某条记录的过程。其中,对树、树杈及文件的定位,是不需要耗费时间的,它体现在文件路径的编码上面;对记录的查找采用简单的顺序检索方式进行,随机数记录的维护也采用尾部添加的简单方式顺序存储。检索过程中,若子键值不存在,则将其添加于某个子文件尾部;若子键值存在,则碰撞次数++,子键值不添加于子文件尾部。
1.2 编码规则
⑴ 对于任意一个30位的随机数,按照四个位段编码如下:
该森林32棵树的编号(0到31)由随机数的高5位(位29到25)决定,000002 到111112分别对应子树0到子树31。某棵树32树杈的编号(0到31)由随机数的次5位(位24到20)决定。某树杈128个叶子文件的编号(0到127)由随机数的次次7位(位19到13)决定。而随机数的最后13位(位12到0)作为30位随机数的代表储存于小文件中,子文件的记录数最多为213=8192条,这样,一个巨型文件的海量检索就被化简为一个小文件的小规模顺序检索。
⑵ 假定当前随机数的十进制数值为123456789,则十六进制数为0x75BCD15,二进制数为1110101101111001101000101012,不足30位前补0,为(00011)(10101)(1011110)(0110100010101)2,下标2表示二进制。
⑶ 该随机数对应树的编号由键值的高5位(即第一个括号里面的5比特)决定,上述键值所在树的编号即为000112=3。
⑷ 该随机数对应树杈的编号,由键值的次5位(即第二个括号里面的5比特)决定,上述键值所在树杈的编号即为101012=21。
⑸ 该随机数对应树叶(即子文件)的编号,由键值的次次7位(即第三个括号里面的7比特)决定,上述键值所在树叶的编号即为10111102=94。
⑹ 上述键值的末13位(即第四个括号里面的13比特),用来表示一个子文件的键值记录,顺序存储或检索不超过8192条的13位子键值,比顺序存储或查找1073741824条主键值要快得多。当前子文件的子键值为01101000101012=3349。
由键值的四个位段,可以定位随机数位于:子树3、树杈21、树叶94、子键值3349,用符号表示即为:tree[3]、Branch[21]、leaf[94]、subkey[3349]。
2 平衡检索森林的算法实现
2.1 数据结构
为了便于编程实现,需要将上述形象的检索森林,转化为抽象的二级文件目录结构。
⑴ 检索森林对应的根目录定义为:“D:\\SF”。
⑵ 树0到树31对应的一级子目录定义为:“D:\\SF\\T0”到“D:\\SF\\T31”。
⑶ 树i的树杈0到树杈31对应的二级子目录定义为:“D:\\SF\\Ti\\B0”到“D:\\SF\\Ti\\B31”,i=0 to 31。
⑷ 树i的树杈j下的128个文件名定义为:“D:\\SF\\Ti\\Bj\\L0.bin”到“D:\\SF\\Ti\\Bj\\L127.bin”,i=0 to 31,j=0 to 31。
⑸ 整个检索森林就有32*32*128=131072个子文件,为了查找子键值的简单,文件采用二进制格式,这里,“.bin”的文件扩展名特指二进制格式。
⑹ 如此庞大数量的子文件,不论是建立,还是删除,都需要花费一定的时间,但是,换来的好处就是每个文件都很小,检索起来非常快。
2.2 算法描述
Step1 初始化检索森林,只生成两级子目录。
Step2 生成32*32*128个二进制空文件,若原来文件中有子键值记录,则自动清空。
Step3 产生或读取30位的随机数。
Step4 依次读取该随机数的前三个位段,根据平衡检索森林的编码规则(见表1)拼接构造出叶子文件的路径名。
Step5 打开该树叶文件。
Step6 取该随机数的最后13位,形成叶子文件的键值,顺序比较该文件中的全部记录,若键值存在,则碰撞次数++;若不存在,则将该键值添加到该叶子文件尾部。
Step7 关闭叶子文件。
Step8 终止循环吗?if(终止) then {goto Step 10}。
Step9 goto Step 3。
Step10 碰撞率=碰撞次数/随机数的总数。
Step11 结束。
3 效率分析与实验结果
3.1 效率分析
假定30位随机数的记录数量为N,且每一个叶子文件的碰撞率检测采用简单的二进制文件顺序检索方法,则每个叶子文件的记录数平均为:M=N/(32*32*128)=N/217。对于顺序文件查找,如果每个输入键码都以相同的概率出现,则在一次成功的查找中,键码与顺序表中记录的比较次数:
C=(1+2+3+4+…+M)/M[9]=(M(M+1)/2)/M
=(M+1)/2=(N/217+1)/2=(N/218+0.5)≈N/218
标准差约为0.289M[10]=0.289*N/217,因此,平衡检索森林中随机数的平均检索效率约为N/218。
3.2 实验结果
实验条件为个人台式机,操作系统为Microsoft Windows XP SP3,CPU为Genuine Intel(R) 1.60GHZ,2GB内存。对于平衡检索森林中庞大数量的子文件,首次建立过程需要4分钟,非首次建立过程需要3分10秒,删除过程需要3分50秒。对于2560Kbyte的二进制随机数文件,需要3小时45分检测完毕。2560Kbyte的二进制随机数的检测结果如下:记录数=655360,碰撞数=47,碰撞率=0.000072,合格阈值=0.0001,本次碰撞率测试合格。
4 结束语
在海量随机数碰撞率的实时检测项目中,我们提出了平衡检索森林的结构与方法,不仅为开发与测试带来了高度的简便性与可靠性,而且,为海量随机数碰撞率的检测带来了极高的效率。但这种结构与方法也存在着一定的问题,就是当随机数的随机性能不是很好的时候,这个检索森林的平衡性会受到一定程度的影响。下一步的研究重点是将叶子文件记录查找方法与杂凑(HASH)技术相结合,进一步提高检索森林在随机数的随机性不是很好状况下的检索效率。
参考文献(References):
[1] 杨睿.论伪随机序列及其应用[J].沈阳工程学院学报(自然科学版),2009.5(2):168
[2] 江裕剑等.计算机模拟随机数发生器的产生、检验及应用[J].成都电讯工程学院学报,1983.1:117
[3] 张广强.均匀随机数发生器的研究和统计检验[D].大连理工大学硕士学位论文,2005.
[4] 栾忠兰等.伪随机数发生器的统计性质检验及其应用[J].计算机应用与软件,2010.27(10):168
[5] 卢开澄.计算机密码学(第2版)[M].清华大学出版社,1998.
[6] (美)Donald E. Knuth著,苏运霖译.计算机程序设计艺术 第3卷排序与查找(第2版)[M].国防工业出版社,2003.
[7] (美)Donald E. Knuth著,苏运霖译.计算机程序设计艺术 第3卷排序与查找第2版[M].国防工业出版社,2003.
[8] (美)Donald E. Knuth著,苏运霖译.计算机程序设计艺术 第3卷排序与查找(第2版)[M].国防工业出版社,2003.
[9] (美)Donald E. Knuth著,苏运霖译.计算机程序设计艺术 第3卷排序与查找(第2版)[M].国防工业出版社,2003.
[10] (美)Donald E. Knuth著,苏运霖译.计算机程序设计艺术 第3卷排序与查找(第2版)[M].国防工业出版社,2003.
