
高速SRAM编译器时序算法
2016-09-13 03:13吴海宏江南大学江苏无锡4中国电子科技集团公司第58研究所江苏无锡4035
电子与封装 2016年7期
黄 奔,彭 力,吴海宏(.江南大学,江苏无锡4;.中国电子科技集团公司第58研究所,江苏无锡4035)
高速SRAM编译器时序算法
黄奔1,彭力2,吴海宏2
(1.江南大学,江苏无锡214122;2.中国电子科技集团公司第58研究所,江苏无锡214035)
介绍了一种通用嵌入式存储器(SRAM)编译器时序建模的方法。通过对存储器关键路径延时分析,时序模型采用分段拓展的建模方式,用Rows、Columns来对SRAM进行分段,分别讨论各段对时序的影响。采用双线性插值法对模型进一步优化,较大程度上提高了模型的精度。最后与ARM公司0.13 μm工艺的存储编译器进行了验证和对比。结果表明,该模型能够较为精确地描述存储编译器时序。
存储编译器;SRAM IP;时序建模;双线性插值
1 引言
随着纳米工艺时代的到来,嵌入式存储器在SOC中所占据的比例日益增加。作为嵌入模块中应用最普及的一种,嵌入式存储器基于自身的功能特性,以及相同面积下相比于组合逻辑块功耗更低的优点,在深亚微米片上系统设计中被广泛使用。其应用的广泛程度已经与标准单元和输入输出单元相当。而SOC芯片的速度受存储器访问时间的制约,工作频率越高,芯片的处理能力越强。通过对时序的分析,我们可以对工程的综合、映射、布局布线等关键环节进行控制,减少逻辑和布线延迟,从而尽可能提高工作频率,因此明确时序在SOC设计中是至关重要的。时序性能的主要指标是存取时间,存取时间表示从开始一次存储器操作到完成该操作所需要的时间,通常指读时间和写时间二者中的最大值,本文主要以存取时间为例来进行建模分析。
编译器时序建模的难点在于找到一种具有代表性的模型,能够较为精准地描述SRAM IP核时序。Tomohisa Wada等人描述了一个片上缓存存储器的存取时间模型,通过RC等模型分析给出每一种延时模块的解析方程,最后各部分累加得到总的存取时间,但是复杂度相对较高,具有解析模型带有的通用性差、不灵活的缺点[1]。刘一杰采用拟合公式即时序等式同时选取具有代表性尺寸存储器测量的方式建立时序模型,但是该时序模型得到的参数值相对于仿真值误差较大[2]。本文综合上述方法并结合实际的仿真情况,首先通过版图参数的提取搭建关键路径,对具有代表性的存储器进行准确的模拟仿真,然后采用双线性插值的方法推算其他未仿真过尺寸的存储器。本文提出的设计方法使编译器在保持一定精度的条件下,通用灵活性强,设计复杂度较之前的工作大大降低。
文章中描述了针对纳米工艺下嵌入式存储编译器高效准确的时序模型。先在第二节介绍时序建模的理论依据,包括对本文提出方法以及其关键概念的介绍,初步提出存储编译器时序模型并且对该模型的不足之处进行分析。第三节针对模型的不足进行进一步优化,采用双线性插值法提高精度。在第四节中将通过模型计算得到的存取时间与ARM公司编译器导出的数值进行验证对比。对该模型的总结将在最后一节列出。
2 存储编译器时序模型基本原理
2.1存储器关键路径延时分析
在通常的设计中都采用关键路径来代替整个电路进行仿真,以便提高设计效率,减少仿真时间。分析SRAM的读写工作过程可以知道其有两条主要路径,分别是数据写入路径和数据读出路径,其中写操作关键路径上的地址线和字线间的路径存在相应的写延时,读操作关键路径上的位线和数据输出之间的路径存在相应的读延时。对图1所示存储器关键路径进行分析,我们可以将存储器的延时分解成译码期间所需要的延时、字线选择需要的字线延时、位线选择需要的位线延时和存储器固有延时。其中译码期间所需要的延时和存储阵列单元选择所需要的延时与存储器尺寸有关,存储器固有延时与工艺和电路结构有关,而与存储器尺寸无关,为本身具有的延时。
2.2时序模型基本原理
在存储器中,译码器与存储单元阵列直接相连,译码器单元的几何尺寸随存储器内核尺寸变化而相应改变。译码器和存储阵列占据存储器大部分面积,并且译码器和存储阵列面积随存储器容量变化而变化。当存储器容量增大时,译码器和存储阵列面积增大,字线和位线的长度也随之增加,其对应的负载电容变大。
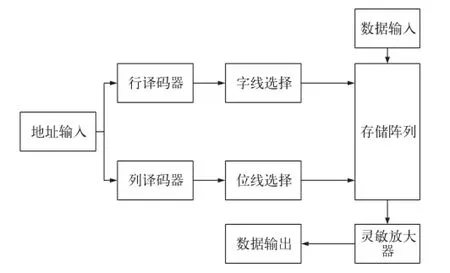
图1 关键路径
接收到地址信号后,译码器需要对字线和位线译码,即所谓的行译码和列译码,而行译码延时和列译码延时与译码驱动的负载电容成正比,负载电容来源于字线和位线,可以近似认为字线译码延时正比于字线行数,位线译码延时正比于位线列数。同理,存储阵列单元选择中字线选择需要的字线延时与挂在字线上存储单元的字线电容有关,同列数成正比,位线选择需要的位线延时与挂在位线上存储单元的位线电容有关,同行数成正比。存储器固有延时包括数据总线驱动延时和数据输出驱动延时,存储器固有延时与存储器尺寸无关,可以将其视为常量。综上,我们可以得出存取时间ta的关系式:
ta=aRows+bColumns+c(1)
其中a、b、c为常数,只需分别取3组仿真值,通过待定系数法,即可以求出a、b、c的值。但是这种方法也有它的缺点:一是误差较大,通常在6%左右;二是由于随机采样三组数据计算得出的a、b、c,会造成a、b、c值随采样数据不同而不同,使误差进一步扩大。
3 存储编译器时序模型优化
3.1编译器时序模型分解
通过研究发现,当words和mux固定不变时,存取时间ta随bits的变化关系如图2所示,从图中可以看出ta与bits近似成线性关系。
当bits和mux固定不变时,存取时间ta随words的变化关系如图3所示,即ta与words近似成线性关系。
而在上节中提到存取时间ta的关系式(1),我们可以将其进一步拆分。(1)式中Rows和Columns分别对应为:
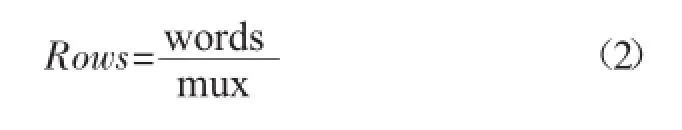
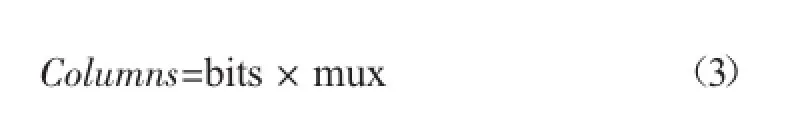
将(2)和(3)式分别代入(1)式中,我们可以得到存取时间ta新的关系式:
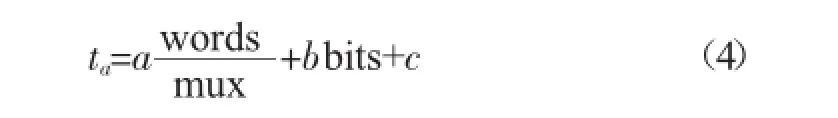
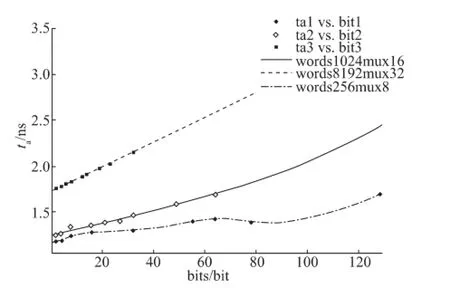
图2 mux和words固定,存取时间ta随bits的变化关系

图3 bits和mux固定,存取时间ta随words的变化关系
在一款存储编译器里面,mux的取值往往是有限的,例如ARM公司支持0.13 μm工艺的编译器其mux的取值分别为8、16、32。这样我们可以把mux=8、mux=16和mux=32作为三种情况来分析,这样做的好处是固定了mux值,减少变量,使模型进一步简化。当固定mux值后,模型可以进一步简化为:
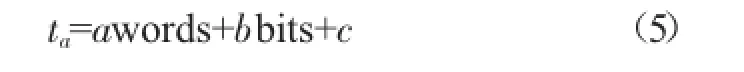
对式(5)固定words时,ta与bits成线性关系,固定bits时,ta与words成线性关系。即此时ta与words、bits成双线性关系,我们可以采用双线性插值法来优化模型。
3.2编译器时序模型优化
双线性插值是有两个变量的插值函数的线性插值扩展,其核心思想是在两个方向分别进行一次线性插值。假设已知函数f在如图4四个点的值,那么我们可以计算出这四个点围成的图形内任意一点的值P= (x,y)。
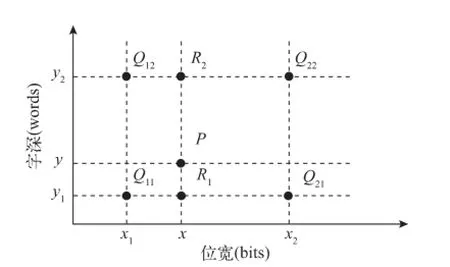
图4 双线性插值
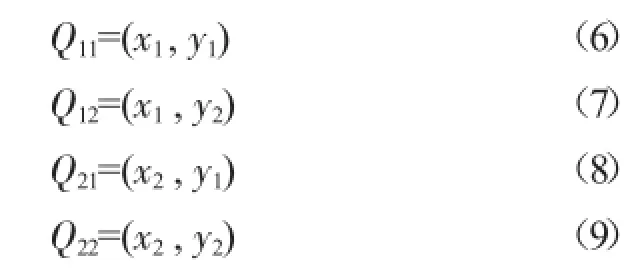
首先在x方向进行线性插值,得到:
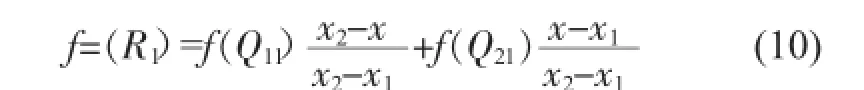
其中R1=(x,y1)。
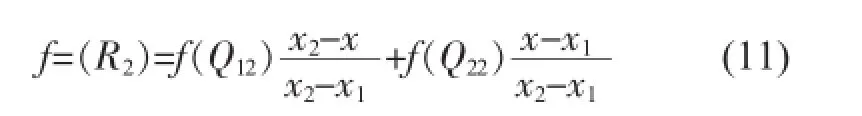
其中R2=(x,y2)。
然后在y方向进行线性插值,得到:
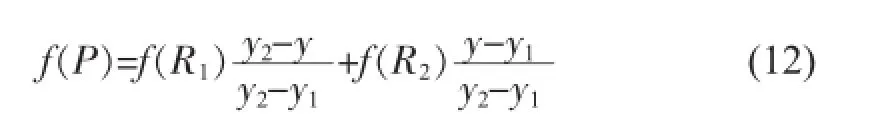
这样就得到想要的结果:
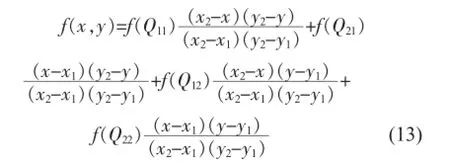
由式(13)可知,在已知围成矩形的四个坐标值及其对应存取时间的条件下,只要知道在这四个点范围内某点的words和bits值,就可以计算出相应的ta值。通过用连续的坐标矩形来描述整个编译器容量,双线性插值法就将问题转化成划分多少个坐标矩形,而划分的坐标矩形数越多,计算得到的ta值也越精准,误差也越小。
以ARM公司存储编译器为例,当mux=8时,其字深words从256变化到4096,位长bits从2变化到128,我们划分坐标矩形时可以按2n来采样,字深选择256、512、1024、2048、4096,位长选择2、4、8、16、32、64、128,这些采样点称之为基点,通过这35个基点将整个存储容量划分为35个坐标矩形,而仿真时只需对这35个采样基点对应尺寸的存储器进行仿真,而不必仿真每个尺寸的存储器,节约了时间,极大降低了设计复杂度。
4 模型验证和对比
4.1模型验证
在本节中,将论文模型计算得出的存取时间与ARM公司编译器对应存取时间进行了验证和对比。基本思想是在输入条件一致的情况下,分别通过论文模型和ARM编译器模型计算得到存取时间,然后比较二者差异,如果差异较小,则认为论文模型是具有实际意义的。该款ARM公司编译器是ARM公司的Artisan系列IP,是为中芯国际(SMIC)提供的一款基于SMIC 0.13 μm工艺的物理IP,对于这款编译器的时序功耗模型我们认为有一定借鉴意义。
具体方法如下:按2n选取ARM公司编译器字深和位宽上一些值对应的存取时间作为基点,然后按照上文方法建立模型,计算出这些基点围成区域内一些尺寸的存取时间,再与ARM公司编译器该尺寸存取时间的值进行对比。ARM公司编译器的规格参数如表1所示。
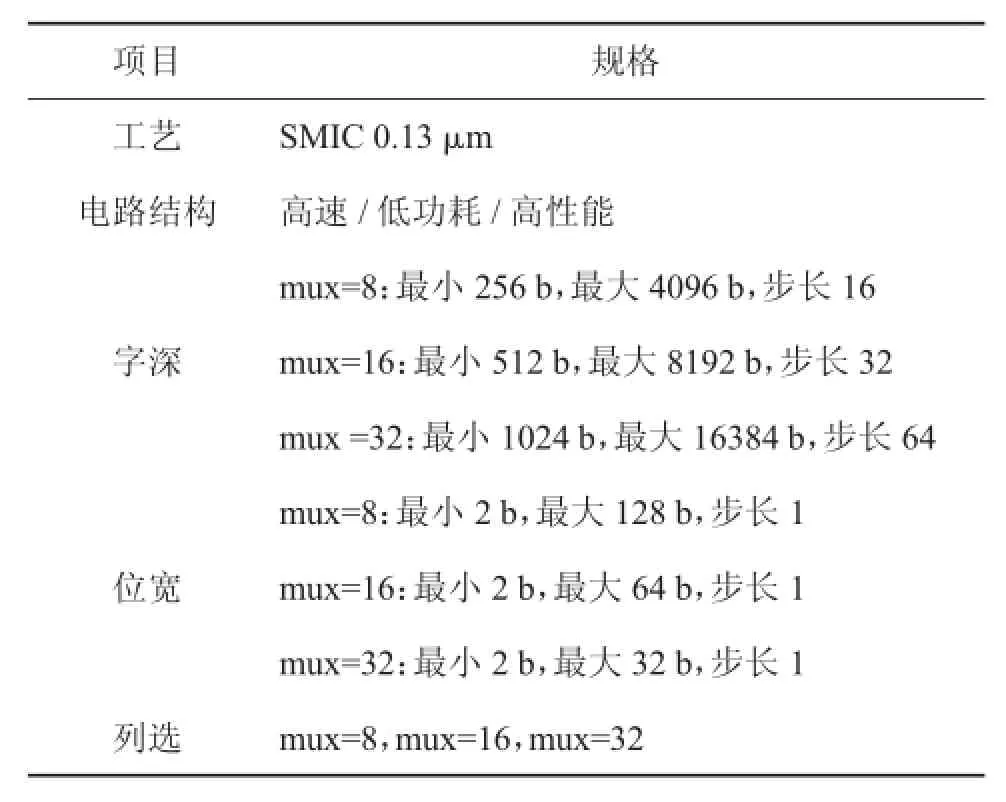
表1 ARMArtisan基于SMIC 0.13 μm工艺编译器平台参数
4.2验证对比结果分析
表2、表3和表4分别列出在列选mux=8、mux=16、mux=32的情况下,随机选取不同字深words和位宽bits,由模型计算出对应尺寸的存取时间ta1和ARM公司0.13 μm工艺存储编译器导出的存取时间ta2,并列出二者的误差。从误差分析可以看出由模型计算出的一些存取时间与ARM公司编译器导出的存取时间是非常接近的,这说明本文采用的建模方法与ARM公司编译器的建模方法十分类似,该建模方法通过ARM公司编译器得到了验证,实践证明该方法能够较为精确地描述存取时间时序情况。

表2 列选mux=8时,不同尺寸下模型计算得出的存取时间与ARM公司0.13 μm工艺编译器存取时间对比
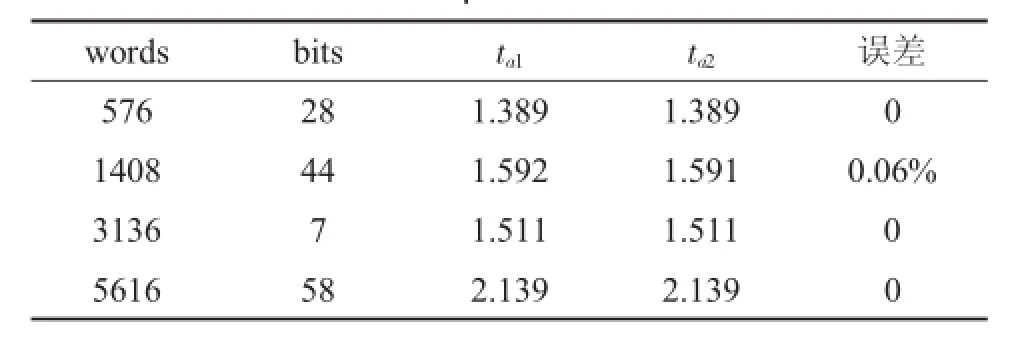
表3 列选mux=16时,不同尺寸下模型计算得出的存取时间与ARM公司0.13 μm工艺编译器存取时间对比

表4 列选mux=32时,不同尺寸下模型计算得出的存取时间与ARM公司0.13 μm工艺编译器存取时间对比
5 结论
测量单个存储器时序,我们可以通过提取版图参数、搭建关键路径的方式对存储器网表进行准确的模拟仿真。对于存储编译器,不可能对所有尺寸的存储器进行模拟仿真,这里选取有代表性的尺寸测量,然后用双线性插值法推算其他未测量过的尺寸的时序。本文介绍了一种存储编译器时序建模的方法,对其理论和方法进行了重点分析,最后与ARM公司编译器进行验证和对比。在保证一定精度的前提下,该方法能有效降低存储编译器设计复杂度,减少设计周期。因此,这种相对灵活的建模方法能够适应当今SOC设计的需求。
[1]H B Bakoglu.Circuits,Interconnections,and Packaging for VLSI[M].Reading MA:Addison-Wesley Publishing Co,1990:56-62.
[2]刘一杰.嵌入式存储编译器设计 [D].上海:复旦大学,2006.
[3]ZHANG K.Embedded memories for nano_scale VLSIs [M].New York:Springer,2009:42-49.
[4]NIKI Y,KAWASUMI A,SUZUKI A,et al.A digitized replica bitline delay technique for random variation tolerant timing generation of SRAM sense amplifiers[J].IEEE J Sol Sta Circ,2011,40(11):2545-2551.
[5]VENKATRAMAN R,CASTAGNETTI R,KOBOZEVA O,et al.The design,analysis and development of highly manufacturable 6-T SRAM bitcells for SOC applications[J]. IEEE Trans Elec Dev,2005,52(2):218-226.
[6]YANG B D,KIM L-S.A low-power SRAM using hierarchical bit line and local sense amplifiers[J].IEEE J Sol Sta Circ,2005,40(6):1366-1376.
[7]XU Y,GAO Z Q,HE X Q.A flexible embedded SRAM IP compiler[C].IEEE Int Symp Circ Syst,New Orleans,LA, USA.2007:3756-3759.
[8]Z Zhao-Yong et al.A 90 nm CMOS embedded low power SRAM compiler[C].IEEE 8th International Conference,2009:625-628.
High-Speed SRAM Compiler Timing Algorithm
HUANG Ben1,PENG Li2,WU Haihong2
(1.Jiangnan University,Wuxi 214122,China;2.China Electronics Technology Group Corporation No.58 Research Institute,Wuxi 214035,China)
The paper introduces a method of SRAM compiler timing modelling.By analyzing the delay of the critical path,timing model adopts segmented expansion method to discuss the impact of segments on timing. The bilinear interpolation method further optimizes the timing model,thereby greatly improving the accuracy. The compiler is then compared with the ARM 0.13 μm memory compiler.The results show that the model is capable of accurate description of the timing.
memory compiler;SRAM IP;timing;bilinear interpolation

TN402
A
1681-1070(2016)07-0022-04
2016-3-21
黄奔(1989—),男,湖北咸宁人,江南大学集成电路工程研究生,现在无锡中科芯模拟部门从事存储编译器电路设计工作。
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20
初中生学习指导·提升版(2020年6期)2020-09-10
语数外学习·初中版(2020年5期)2020-09-10
铁道通信信号(2020年7期)2020-02-06
计算机与网络(2019年9期)2019-10-21
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
浙江大学学报(工学版)(2016年11期)2016-06-05
中学生数理化·八年级数学人教版(2016年2期)2016-04-13
环球时报(2014-06-18)2014-06-18
组合机床与自动化加工技术(2014年10期)2014-03-01
