
晋城矿区3号煤层深部含气量预测
2016-09-23 05:11姜伟
科技与创新 2016年15期
姜伟
摘 要:为了探讨深部煤层含气量的有效预测方法,将支持向量机学习方法应用到了预测模型的建立中。以晋城矿区3号煤层为研究对象,以浅部煤层数据为基础,建立了含气量预测模型,并用煤层深部实测数据对模型进行了检验,精度可满足生产需要,这为煤储层深部含气量预测提供了新思路。
关键词:煤层深部含气量;压裂技术;建模样本;Matlab
中图分类号:P618.13 文献标识码:A DOI:10.15913/j.cnki.kjycx.2016.15.112
煤层含气量是煤储层评价的基本参数之一,是开发潜力评价、有利区预测和选择开发方案重要依据。结合晋城矿区煤层气井的生产实践,当煤层埋深超过800 m时,受地应力的影响,压裂缝延伸的长度和高度都受到了限制,压裂效果大打折扣。随着连续油管分段压裂、滑套工具串分段压裂等新型压裂技术的成熟,压裂改造能力有了很大的提高。在此情况下,人们开始关注后备区埋深大于800 m的区域,但由于前期深部测试样品较少,且对深部煤层含气量的分布规律认识不足,所以,对煤储层深部含气量的预测是非常重要的。
1 支持向量机学习法
支持向量机学习法是由Vapnik率先提出的,是基于统计学理论的一整机器学习方法。其基本思想是高维特征空间内的线性回归,是从线性可分条件下的最优分类超平面发展而来的。给定建模样本数据点集:
. (1)
式(1)中:xi为输入变量;yi为目标变量。
通过机器学习,可找到一个非线性函数f(x)。此时,不仅应满足yi=f(xi),且对于检验样本集{xn+1,xn+2,…,xn+m}而言,其预测值误差应在可接受的范围内。在实际应用中,没必要求得f(x)的解析表达式,只需要借助Matlab软件的SVM工具箱即可。f(x)可通过核函数的选择和相关参数的选取来确定。结合经验选取合适的核函数后,应调节相关参数,直至预测精度令人满意为止。
2 建立含气量预测模型
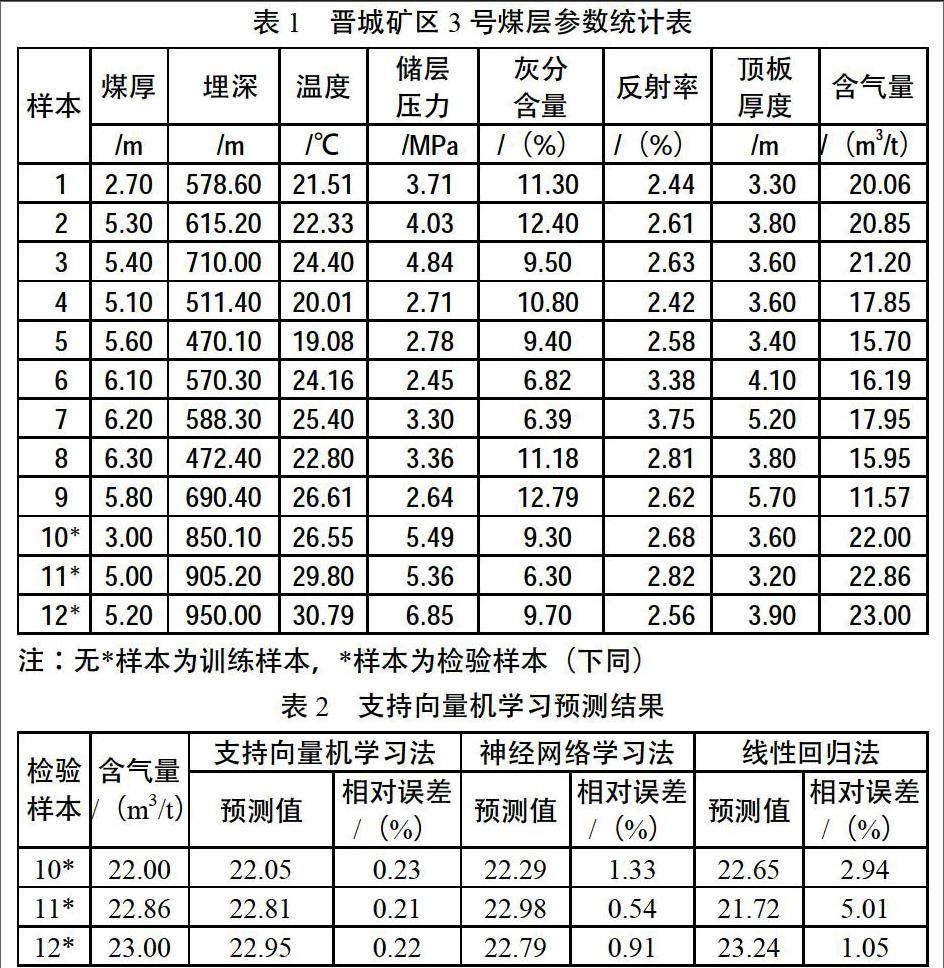
晋城矿区是19个首批煤炭国家规划矿区之一,是我国重要的无烟煤生产基地,位于沁水盆地的东翼南端,隶属于沁水煤层气田。矿区主要煤系地层为二叠系下统山西组(P1s)和石炭系上统太原组(C3t),平均厚度为136.02 m。含煤15层,煤层总厚度为14.67 m,含煤系数为10.8%.3号煤层位于山西组中下部,上距K8砂岩约30 m,下距9号煤层48 m。煤厚4.45~8.75 m,平均厚度为6.31 m,含气量为15.3~27.2 m3/t,为目前主要开采层位。为了对3号煤层深部含气量进行预测,根据前期煤田勘探孔资料,选取了7个参数(煤层厚度、储层温度、镜质组最大反射率、煤层灰分含量、储层流体压力、煤层埋藏深度、直接顶板厚度)作为影响煤储层气含量的因素进行数学建模。晋城矿区3号煤层的参数如表1所示。
以9个埋深小于800 m的数据样本建立了预测模型,并以上述7个影响因素为预测模型的输入变量,含气量为输出变量。在Matlab软件的SVM工具中进行处理,通过多次模型参数试验,最终核函数选用了径向基核函数,不灵敏参数ε的值选择为0.05,参数γ的值选择为0.1,惩罚参数C的值选择为10 000.应用3个埋深大于800 m的样本对预测结果进行检验,以检查预测精度是否满足要求。预测值的绝对误差小于0.05 m3/t,相对误差小于3%.神经网络和多元线性回归为目前较为常用的含气量预测方法。分别建立了3个隐藏层,建立了持续次数为500次的神经网络模型和7元线性回归模型。通过预测误差的对比可以看出,支持向量机学习预测精度的方法优于其他两种方法。其原因有2点:①数据样本小。训练样本只有9个,神经网络模型未经过充分的训练,易陷入局部极值,②部分次要的输入变量导致影响因素过于离散,最终使预测结果的精度降低。具体如表2所示。
3 结束语
综上所述,模型预测精度法优于神经网络法和线性回归法,可支持向量机方法对小样本、非线性、多因素数据的建模,为深部含量预测提供了新思路。因此,在煤层气勘探程度较低的区域,可基于煤田钻孔资料对煤储层含气性进行初步评价。
参考文献
[1]连承波,赵永军,汉林,等.煤层含气量的主控因素及定量预测[J].煤炭学报,2005,30(06).
[2]方瑞明.支持向量机理论及其应用分析[M].北京:中国电力出版社,2007.
[3]孟召平,田永东,雷旸.煤层含气量预测的BP神经网络模型与应用[J].中国矿业大学学报,2008,37(04).
〔编辑:张思楠〕
