
一种基于用户对项目属性偏好的推荐算法
2016-11-11 09:40陈伶红徐华中吴友宇
武汉理工大学学报(信息与管理工程版) 2016年5期
陈伶红,徐华中,李 鲍,吴友宇
(1.武汉理工大学 自动化学院,湖北 武汉 430070;2.武汉理工大学 信息工程学院,湖北 武汉 430070)
一种基于用户对项目属性偏好的推荐算法
陈伶红1,徐华中1,李 鲍1,吴友宇2
(1.武汉理工大学 自动化学院,湖北 武汉 430070;2.武汉理工大学 信息工程学院,湖北 武汉 430070)
针对协同过滤推荐算法中存在的数据稀疏性问题,提出了一种基于用户偏好模型的混合聚类推荐算法。利用用户-项目评分矩阵参考TF-IDF和信息熵的原理得到了用户对项目属性的偏好模型,并以此为基础数据进行用户聚类、相似度计算和最近邻查询,然后对用户未评分的项目进行评分预测,进而产生推荐。实验表明,基于用户对项目属性偏好的混合聚类推荐算法与传统的协同过滤和基于用户-项目评分矩阵的聚类算法相比,在推荐精度上表现出一定的优越性。
推荐算法;协同过滤;用户偏好;SOM;K-means
随着信息技术和互联网的发展,人们逐渐从信息匮乏的时代走入了信息过载的时代。推荐系统能够有效地解决信息过载问题,在电子商务领域得到了广泛的应用,其中推荐算法则是最核心的技术点。协同过滤推荐算法是目前最为成熟的一种推荐算法[1],可分为基于用户的协同过滤和基于项目的协同过滤。基于用户的协同过滤推荐算法主要是依据用户的历史评分数据计算用户间的相似度,找到目标用户的最近邻居,目标用户对未评分项目的评分可以通过其近邻对该项目的评分进行预测,将评分最高的前N个项目推荐给目标用户。但是随着电子商务系统规模的扩大,用户数量和项目数量的增加,导致用户-项目评分数据出现严重的稀疏性,用户相似度计算十分耗时,并且很难找到相似的用户集,使得推荐质量下降。为此,许多学者将数据挖掘、机器学习、神经网络等领域的方法与协同过滤相结合。如曹渝昆提出了一种基于Web挖掘和Fuzzy Art神经网络的电子商务顾客分类方法,可以缩小目标顾客的邻居用户搜索范围,缩短推荐时间[2],但是此方法主要挖掘的是隐式数据,对数据处理技术要求较高;成桂兰等提出一种基于SOM和K-means混合聚类的推荐算法[3],该方法在一定程度上缩短了最近邻查询时间,提高了推荐效率和推荐质量,但是稀疏的用户-项目评分数据使得某些可能相似的用户因缺少共同评分项目而导致相似度较低;胡新明提出了一种引用文本分类中的TF-IDF算法将用户对商品的评分矩阵转化为用户对商品属性评分矩阵的推荐算法,在较少数据量的情况下得到与基于用户商品评分矩阵推荐算法同质量甚至更高质量的推荐结果[4],但是该方法忽略了商品属性在不同商品集合间以及商品集合内的分布情况;袁汉宁等提出了基于MI聚类的协同推荐算法[5],通过多示例聚类计算用户的最近邻居集,但是在计算用户间相似度时仍然使用用户-项目评分数据,稀疏的用户-项目评分数据使得某些可能相似的用户因缺少共同评分项目而导致相似度较低。
针对上述问题,笔者提出了一种基于用户对项目属性偏好模型的混合聚类推荐算法,考虑到项目属性在用户喜欢和不喜欢的集合间以及集合内的分布情况,借鉴文本分类中TF-IDF算法并引进信息熵建立用户对项目属性的偏好模型,然后用SOM算法对该模型中的用户进行粗聚类,将其聚类中心和聚类簇数目作为K-means聚类算法的初始聚类质心和聚类簇数目,在目标用户所在的聚类簇中计算用户相似度并寻找近邻,对未评分的项目进行预测。
1 用户偏好模型
用户对项目属性的偏好模型是进行用户聚类和相似度计算的基础,通过分析用户-项目评分矩阵和项目-属性矩阵,建立用户对项目中出现的所有属性的偏好权重矩阵。
考虑包含m个用户和n个项目的系统,令用户集合U={U1,U2,…,Um}(i=1,2,…,m),项目集合I={I1,I2,…,In}(j=1,2,…,n),用户-项目评分矩阵如表1所示,其中元素rij表示第i个用户对第j个项目的评分值。
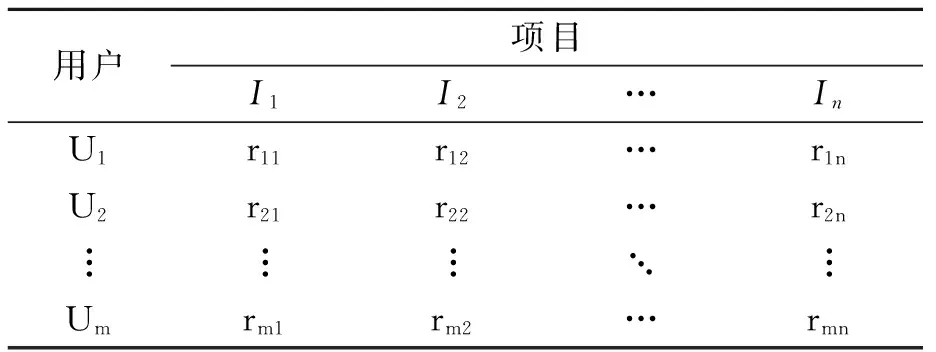
表1 用户-项目评分矩阵
项目属性集合表示为F={f1,f2,…,fs}(k=1,2,…,s),项目-属性矩阵如表2所示,其中元素ajk表示项目Ij的特征属性:
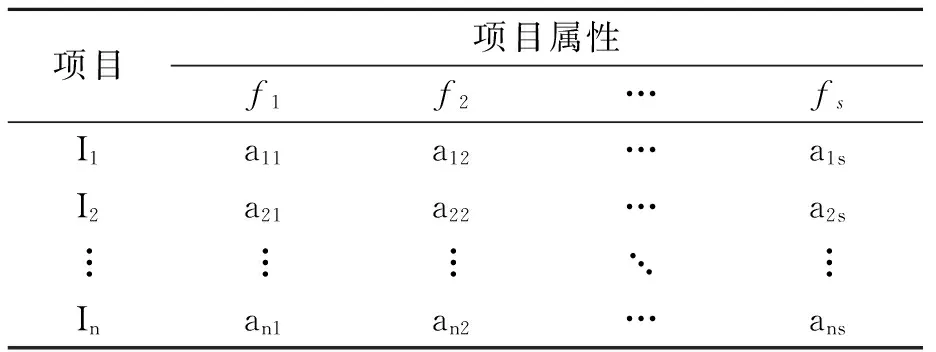
(1)
参考TF-IDF算法的原理,如果属性fj在集合Li中出现的次数越多,说明用户越偏好具有该属性的项目,则属性fj应该赋予较大的权重。根据以上论述得到偏好权重wik为:
(2)

但由式(2)得出的用户对项目属性的偏好权重存在如下问题:①没有考虑到属性fj在集合Li和集合Qi之间的分布情况。如果属性fj在集合Li中出现较多,而在集合Qi中出现较少,则说明用户比较偏好具有该属性的项目,该属性应该赋予较高的权重。如果属性fj比较均匀地分布在集合Li和Qi中,说明用户对具有该属性的项目没有特别偏好,该属性值应该赋予较低的权重。②没有考虑到属性fj在集合Li中的分布情况。在集合Li中出现频率较高的属性的权重应该比出现频率较低的属性要高。如果属性fj在集合Li中出现的频率较低,则该属性应该被赋予较小的权重。考虑到以上两种情况,参考文献[6]在文本分类中引入信息熵来改善TF-IDF算法,引进信息熵来计算用户对项目属性偏好的模型。
若给定的概率分布为P=(p1,p2,…,pn),则由该分布传递的信息量称为P的熵,即:
(3)
属性fj在集合Li和Qi中的概率分布为Poc=(NLik/NRik,NQik/NRik)(其中NQik表示集合Qi中具有属性fj的项目个数),记Hoc(Poc)为属性fj的类间信息分布熵。属性fj在集合Li中的概率分布为Pic=NLik/NLi,记Hic(Pic)为属性fj的类内信息分布熵。
由以上分析可知,Hoc(Poc)越大则属性fj的权重越小,Hic(Pic)越大则属性fj的权重越大。得到改进后的用户Ui对属性fj的偏好权重为:
(4)
其中对Hoc做了一定的修改,常数1是为了防止Hoc(Poc)=0,使得1/(Hoc+1)分布在[0,1]区间。根据式(4)建立用户-项目属性偏好矩阵如表3所示。
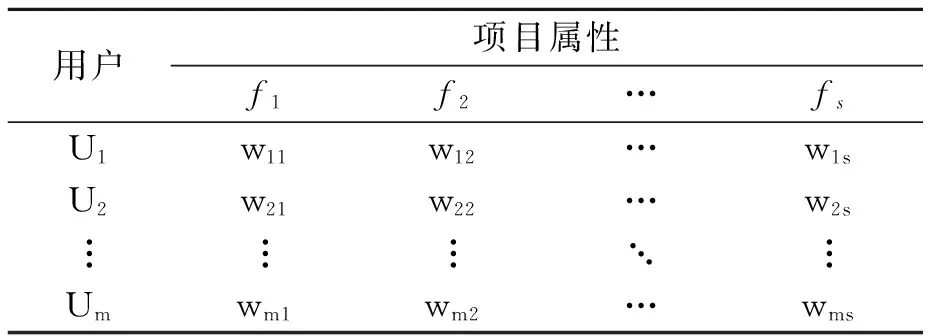
表3 用户-项目属性偏好矩阵
2 推荐过程
推荐算法主要分为5个过程:生成用户-项目属性偏好模型、用户聚类、用户相似度计算和最近邻居查询、评分预测、生成推荐。
(1)生成用户-项目属性偏好模型。通过式(4)生成用户-项目属性偏好模型,作为用户聚类和相似度计算的数据基础。
(2)用户聚类。为了缩短用户相似度计算的时间、缩小用户最近邻居查询范围,需要对用户进行聚类,将用户-项目属性偏好矩阵中项目属性偏好比较相似的用户分配到同一聚类簇中,使同一聚类簇中的用户相似度尽可能高,不同聚类簇中的用户相似度尽可能低。常用的聚类算法有SOM神经网络、K-means聚类算法、层次聚类算法、FCM聚类算法等[7]。SOM算法进行聚类时,网络收敛时间过长,通常网络需要训练上万次才能收敛。K-means算法的初始聚类质心选择不当,很难得到较好的聚类效果,在大规模数据集上收敛较慢。因此采用SOM与K-means聚类相结合的混合聚类模型对用户进行聚类,聚类流程为:①将步骤(1)中得到的用户-项目属性偏好矩阵作为聚类的输入数据,通过SOM对输入训练较少的次数进行粗聚类,输出聚类簇ClusterSOM、神经元的权值ωSOM、聚类簇数目K;②将ωSOM作为原始质心Ooriginal,对于每一个簇内元素不为0的聚类簇,寻找与Ooriginal距离最近的元素作为该簇最终的质心OSOM;③以K、OSOM作为K-means聚类的聚类簇数目和初始聚类质心,对用户进一步聚类,输出用户聚类结果ClusterResult。
(3)用户相似度计算和最近邻居查询。计算目标用户Ui与所在聚类簇cindex中其他用户的相似度。用户相似性的度量标准主要有余弦法、修正余弦法和基于相关性的相似性度量等[8],笔者选用余弦法来计算用户间的相似度:
(5)
其中,ωu和ωv分别为用户u和用户v的项目属性偏好向量。
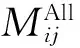
(6)
(4)评分预测。找到目标用户Ui针对目标项目Iij的最近邻用户集合MKnear后,通过集合MKnear中的用户对目标项目Iij评分的加权平均值来描述目标用户Ui对目标项目Iij的评分。评分预测公式为:

(5)生成推荐。重复步骤(3)和步骤(4),预测目标用户Ui对所有未评分项目的评分,选择预测评分最高的N个项目推荐给目标用户Ui。
3 实验过程与结果分析
3.1 数据集
实验采用MovieLens(ml-100K)数据集,该数据集包含了943个用户对1 682部电影的10万个评分。实验采用五折交叉验证法,将实验数据平分成5个互不相交的数据子集,每次选择其中一个数据子集作为测试集,其余4个子集作为训练集,如此循环5次,取每次实验结果的平均值作为最终结果。当用户对项目的评分过少时,难以发现用户对项目属性的偏好,因此在每次实验中,找出测试集中评分项目少于20个的用户,从测试集和测试集中剔除这些用户的评分数据。MovieLens数据集中的项目是电影,根据电影类别,将电影划分为19个类别,0~18分别代表19个项目类别属性,如表4所示。电影类别属性为Unknown的电影不能表示出用户对某一具体属性的偏好程度,因此将电影类别属性为Unknown的项目从训练集和测试集中剔除。
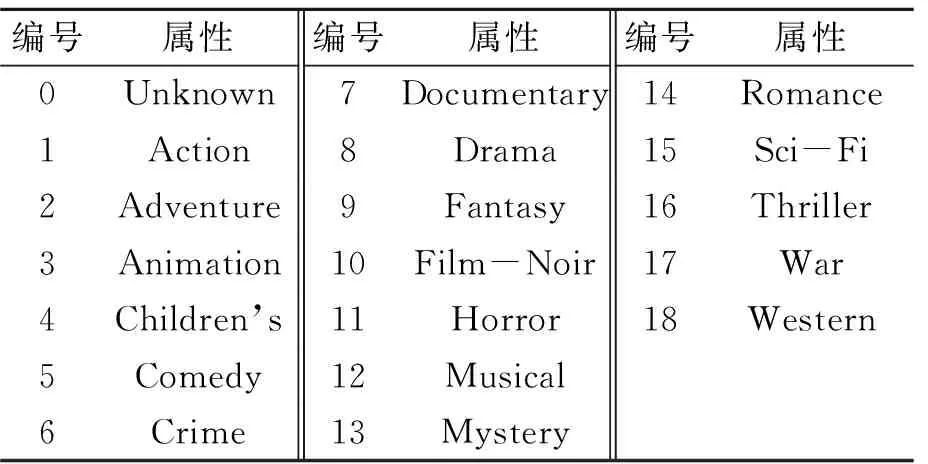
表4 电影类别属性
3.2 性能评价
实验采用平均绝对误差MAE[9]来度量推荐的准确性,MAE值越低推荐结果越准确,其计算公式为:
(8)
式中:pi为预测评分;qi为实际评分。
3.3 结果分析
根据HERLOCKER等[10]的研究结果,在真实环境中最近邻用户数量设置为20~50比较合理,笔者采用的MovieLens数据集共有943个用户,设置SOM的输出神经元数目为6×6,邻居查询个数Knear=[5 10 15 20 25 30 35 40 45 50 55 60 65 70]来进行对比实验,以验证笔者提出算法的优越性。
将笔者提出的利用TF-IDF和信息熵挖掘用户偏好模型,进行SOM+K-means聚类和用户相似度计算的推荐算法称为算法1;将利用TF-IDF挖掘用户偏好模型,进行SOM+K-means聚类和用户相似度计算的推荐算法称为算法2;将利用用户-项目评分矩阵,进行SOM+K-means聚类和用户相似度计算的推荐算法称为算法3;将传统的基于用户的协同过滤推荐算法称为算法4;将基于MI聚类的协同推荐算法称为算法5(根据文献[5]中的描述,选择聚类个数K=20时推荐效果最好,选择表4中1~18的电影属性类别作为实例的内容特征)。

图1 算法1~算法5的对比实验结果
图1所示为算法1~算法5的对比实验结果,可以看出基于SOM+K-means聚类的推荐算法比传统的协同过滤推荐算法效果更好;使用用户偏好模型进行聚类和相似度计算的推荐效果比使用用户-项目评分矩阵的推荐效果更好;使用TF-IDF和信息熵相结合挖掘的用户偏好模型比使用TF-IDF挖掘的用户偏好模型的推荐效果更好。算法1、算法2比算法5的效果好,算法5比算法3、算法4的效果更好,说明算法5通过多示例聚类得到的最近邻集合,比以用户-项目评分矩阵为数据基础进行聚类得到的最近邻居集合更为准确。由于算法5计算用户相似度时使用的是用户-项目评分矩阵,不能更好地挖掘用户间的相似性,使得推荐结果不如算法1准确。
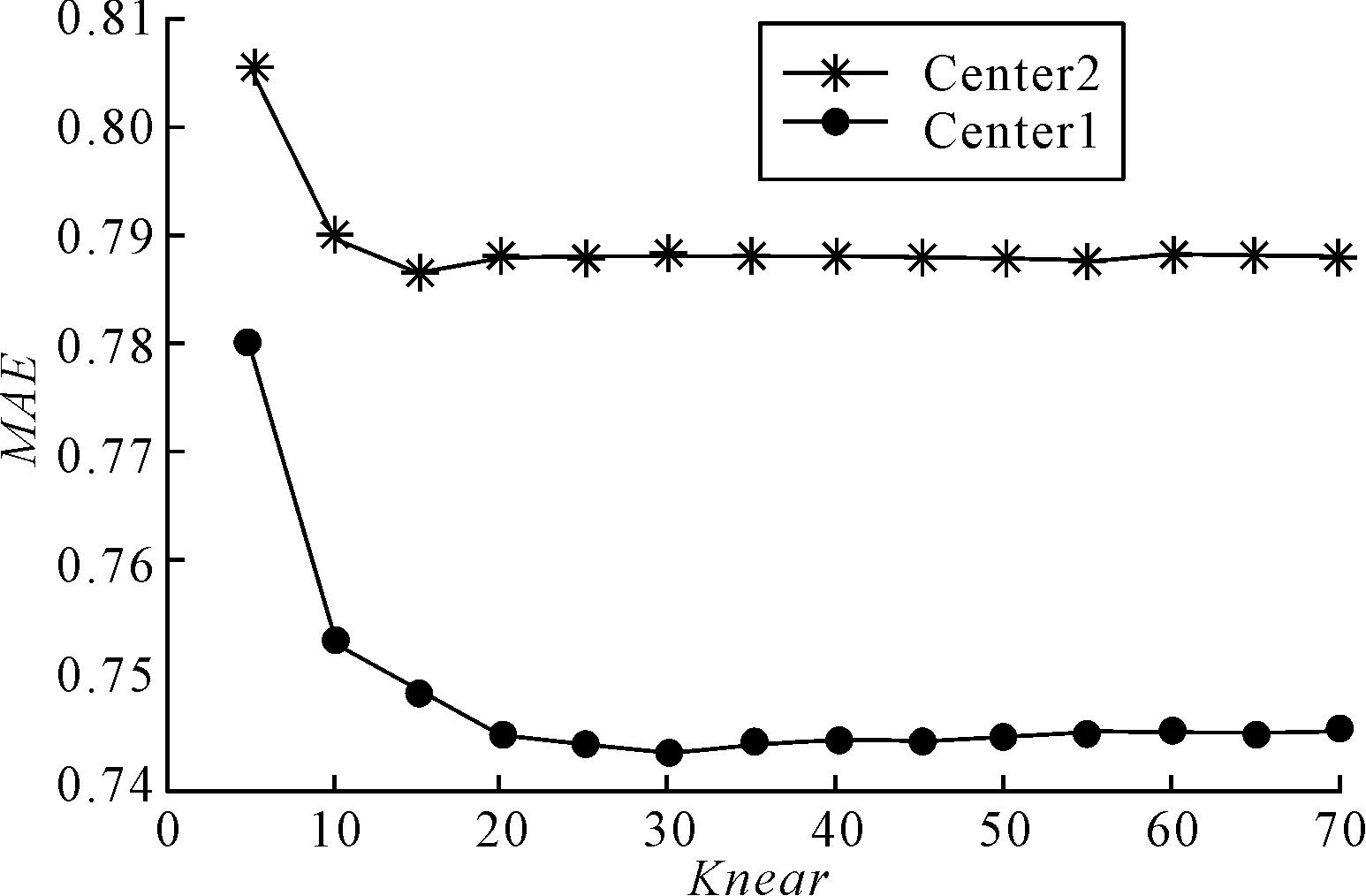
图2所示为算法1、算法2、算法4的用户相似度计算、最近邻查询及评分预测的时间,可以看出当15 图2 不同算法的相似度计算、最近邻查询及评分预测的时间 图3 不同SOM聚类中心下推荐算法的实验结果 图3所示为不同SOM聚类中心下推荐算法的实验结果。SOM聚类结束时,外星权向量位于输入向量聚类的中心,该实验中SOM训练次数较少并未完全收敛,因此选择各聚类簇中离外星权向量最近的一点作为SOM的聚类中心(Center1),文献[3]将SOM聚类结束时各聚类簇中元素的平均值作为SOM的聚类中心(Center2),Center1的推荐效果较Center2要好,即SOM聚类中心的选取比文献[3]更合理。 笔者为了解决评分矩阵稀疏性问题,通过TF-IDF算法和信息熵生成用户对项目属性偏好的模型,然后以此为数据基础进行用户聚类和相似度计算,使得相似用户之间的相关性增强,缩短了最近邻用户的查询时间,通过五折交叉对比实验得出,笔者提出的算法具有更高的推荐质量和效率。但笔者研究的前提是假设用户兴趣不会发生变化,然而在实际研究中,用户的兴趣是会随时间发生变化的,因此需要将时间因素同项目属性等结合起来,以提高推荐系统的准确性,这将是下一步研究的重点。 [1] 刘鲁,任晓丽.推荐系统研究进展及展望[J].信息系统学报,2008 (1): 82-90. [2] 曹渝昆.基于神经网络和模糊逻辑的智能推荐系统研究[D].重庆:重庆大学,2006. [3] 成桂兰,刘旭东,陈德人.基于混合聚类的个性化推荐算法[J].武汉理工大学学报(信息与管理工程版),2011,33(3):379-381. [4] 胡新明.基于商品属性的电子商务推荐系统研究[D].武汉:华中科技大学,2012. [5] 袁汉宁,周彤,韩言妮.基于MI聚类的协同过滤推荐算法[J].武汉大学学报(信息科学版),2015,40(2):253-257. [6] 李原.中文文本分类中分词和特征选择方法研究[D].长春:吉林大学,2011. [7] 冯晓蒲,张铁峰.四种聚类方法之比较[J].微型机与应用,2010,29(16):1-3. [8] SARWAR B, KARYPIS G, KONSTAN J, et al. Item-based collaborative filtering recommendation algorithms[C]∥Proceedings of the 10th International Conference on World Wide Web. [S.l.]:[s.n.], 2001: 285-295. [9] KARYPIS G. Evaluation of item-based top-n recommendation algorithms[C]∥Proceedings of the Tenth International Conference on Information and Knowledge Management. [S.l.]:[s.n.], 2001: 247-254. [10] HERLOCKER J L, KONSTAN J A, BORCHERS A, et al. An algorithmic framework for performing collaborative filtering[C]∥Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.[S.l.]:[s.n.], 1999:230-237. CHEN Linghong:Postgraduate; School of Automation, WUT, Wuhan 430070, China. A Recommendation Algorithm Based on Users’ Preference of Item Features CHENLinghong,XUHuazhong,LIBao,WUYouyu Considering the problem of data sparsity in traditional collaborative filtering recommendation algorithm, a hybrid clustering recommendation algorithm based on users’ preference is proposed. The users’ preference model is obtained by using user-item rating matrix and referring to the principle of TF-IDF and information entropy, which is the basic data of users clustering, similarity calculation and nearest neighbor query. Item recommendation is accomplished after predicting the rates for the no-rated items. Experiment shows that the hybrid clustering recommendation algorithm based on user p for project attributes has some advantages over the traditional collaborative filtering and clustering algorithm based on user-item scoring matrix. recommendation algorithm; collaborative filtering; users’ preference; SOM; K-means 2095-3852(2016)05-0616-05 A 2016-05-25. 陈伶红(1991-),女,湖北武汉人,武汉理工大学自动化学院硕士研究生. TP301.6 DOI:10.3963/j.issn.2095-3852.2016.05.021
4 结论
猜你喜欢
新班主任(2022年4期)2022-04-27
科学大众(2020年23期)2021-01-18
铁道通信信号(2019年6期)2019-10-08
汽车观察(2019年2期)2019-03-15
雷达学报(2017年6期)2017-03-26
中国卫生(2016年5期)2016-11-12
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
南都周刊(2015年4期)2015-09-10
