
千万门级FPGA装箱实现及验证
2016-11-15 09:08董志丹董宜平
电子与封装 2016年10期
胡 凯,董志丹,惠 锋,李 卿,董宜平
(1.中国电子科技集团公司第58研究所,江苏无锡214072;
2.无锡中微亿芯有限公司,江苏无锡214072)
千万门级FPGA装箱实现及验证
胡凯1,董志丹2,惠锋2,李卿2,董宜平1
(1.中国电子科技集团公司第58研究所,江苏无锡214072;
2.无锡中微亿芯有限公司,江苏无锡214072)
装箱是FPGA工具设计流程中关键的一步,是综合、工艺映射和布局的桥梁,在很大程度上影响了电路的速度和功耗。基于千万门级FPGA xc5vlx20tff323-2器件,对XST综合工具综合后的网表进行装箱,并把装箱结果转换为XDL格式文件,使用Xilinx工具验证其正确性。
FPGA;装箱;验证
1 引言
现场可编程逻辑门阵列(FPGA)作为一种可编程的芯片,由于其可重构性及低成本的优点,使其在市场上赢得了重要的商业地位。在学术文献中,针对过去那种只包含基本逻辑单元LE的简单FPGA模型的装箱算法已经有了深入的研究。但是现代商业FPGA包含可配置逻辑单元(CLB)、可配置的I/O块(IOB)、特殊的硬核(IP)。其中商业FPGA每个CLB除了包含多个LE,还包含快速进位链(CarryChain)、Muxf7/Muxf8、双输出端口6输入的查找表LUT;IP硬核包含RAM块、数字信号处理(DSP)、数字时钟管理器(DCM)、快速I/O以及其他一些微处理器。
目前,在学术界比较常用的装箱算法相对而言比较少,较早的有Betz和Rose提出的基于面积优化的装箱算法[1],由于电路固有的局部性,装箱后逻辑块的输入数目可能比固有逻辑块整体的输入数目多。Marquardt提出了基于延迟优化的装箱算法[2],在原有基础上增加了对时延的考虑,减少了装箱后关键路径的延迟。Bozorgzadehy提出了基于布通率的装箱算法[3],在LUTs装箱时把布线的约束加入评价函数,从而提高布线效率。不过上述算法研究对象均是针对简单FPGA模型,本文则针对千万门级的FPGA基于其硬件结构展开装箱研究。
2 Virtex-5 CLB结构
本文针对Xilinx Virtex-5这种结构复杂的商业FPGA,实现其装箱并把装箱结果转换成XDL文件的格式,用Xilinx工具验证其结果的正确性。基于Virtex-5硬件特征的复杂性,需要对特殊功能模块进行装箱预处理。
本文重点关注特殊的组合逻辑和IP硬核的装箱。首先介绍Virtex-5架构来展示商业FPGA结构的复杂性,为下一节如何来实现基于复杂架构的装箱提供数据模型。一个Virtex-5逻辑块CLB包含两个SLICEs和一个开关矩阵,每个SLICE中包含4个六输入双输出LUT,8个存储元件,多功能多路复用器和进位逻辑链,可以实现逻辑、算术和ROM函数运算。其中SLICE有两种类型,一类为SLICEL,为普通查找表逻辑发生器,另一类为SLICEM,SLICEM支持两个附加功能:分布式RAM存储数据和移位寄存器。然而,LUT的两个输出端口不是等价的,其中一个速度相对较慢,当有速度要求时这点必须要考虑。
3 Virtex-5装箱实现
装箱既是工艺映射的后处理,也可认为是布局和布线模块的预处理,在FPGA软件开发设计流程中是相当重要的。通用的装箱算法是先把LUTs和FFs一一配对装箱到BLE中,然后再将多个BLE装箱到一个SLICE逻辑块里。就目前而言,由于商业FPGA具有更为复杂的硬件架构,通用的装箱算法不能很好地解决其装箱的需求,例如CLB中进位链的处理、IP硬核的装箱等。
要实现层次化的FPGA装箱首先需要把层次化的网表打平与优化,然后再进行装箱。装箱要优先处理进位链、分布式RAM、Muxf7/Muxf8等特殊单元。
(1)根据SLICE内部资源,如图2所示,一个SLICE内部包括4个进位逻辑,而在SLICE外部进位逻辑的互连线只能是直线,考虑到其走线和在SLICE内部各个进位逻辑连接的特殊性,在装箱中优先对其处理。对于一个SLICE的进位逻辑未满4个时,其末端进位要从MUX或者LATCH的Q端输出;其首个进位逻辑的输入根据连接线网的属性不同其连接会不同。
(2)根据SLICEM内部资源,一个SLICEM内部包括4个6位地址线的分布式RAM,其处理方式与LUT的不同,而元件描述中有 RAM16X1D、RAM32X1S、RAM32X1D、RAM32M、RAM64X1D、RAM64M、RAM128X1S不同的原语,它们分别有不同个数的地址端口,这就需要对上述原语做一次转换,完成装箱。

图1 SLICEL
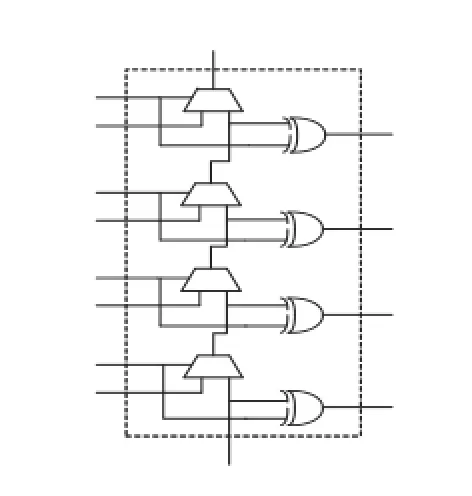
图2 进位链
(3)对于双输出端口的LUT来说,LUT/FF也就有其特殊性。如图4所示,O6直接驱动SLICE的输出端口A,而O5必须通过一个额外的多路选择器,然后驱动SLICE的输出端口AMUX,这使得O5输出比O6输出要慢,因此,在要求高的情况下,O5不适于用在关键路径上。
(4)根据SLICE内部连接关系,Muxf7的驱动点是双端口的LUT的O6端,Muxf8的负载点如果没有寄存器要通过BMUX输出,而LUT的另外端口O5端不能驱动寄存器,O5端输出与Muxf8的输出容易产生竞争。
图3 分布式RAM

图4 基本逻辑单元
在装箱的第一个阶段首先处理特殊单元进位逻辑,根据进位链的长度,按照4个逻辑一组,把进位逻辑装箱到不同的BLE,根据SLICE内部的连接关系,综合每个BLE中进位逻辑的驱动关系对有连接关系的LUT进行装箱,对于多负载(进位逻辑)的LUT,要满足负载的装箱需求,需在LUT与负载间通过插入一个BUF来完成装箱;接下来依次对分布式RAM及RAM块进行配对装箱,并在装箱后的BLE内针对不同的RAM进行拆分;然后对FF进行处理,查找其数据输入端口D的驱动是否是LUT,把配对的LUT和FF装箱到一个BLE中;最后特殊处理Muxf7、Muxf8,其驱动是LUT的O6输出,根据其连接关系查找驱动LUT并把其装箱到一个BLE中,如果其驱动LUT不存在或者已被装箱,需在MUX之前插入一个BUF。
装箱第二阶段是根据装箱的运行规则检查(DRC)进行装箱,以BLE之间连接的线网为研究对象,根据线网的负载引脚数从小到大对线网进行排序;针对线网所连的BLEs,选择其中以连接因子较小的BLE为种子,把线网上其他的BLE依次装箱到种子所在的CLB中;最后把未被装箱的不在BLE线网上的LUT、DFF及其他装箱到CLB中。所谓的连接因子[4]不仅反映这个BLE和较多的线网相连,而且还反映出和该BLE相连线网所含有的引脚数较少,也即这些线网通过装箱更容易被装到CLB中。如图5所示,a的分离度S=3.33,D=3,C=1.11;b的分离度S=2,D=3,C=0.67;b所示的单元B比a所示的单元A更适合做种子;因为选择种子B可以将3条断线完全吸收到CLB内(如d),而A只能将一条线网完全吸收到CLB内(如c)。

图5 连接因子的选择
装箱的程序设计流程如图6所示。
4 装箱验证
装箱完成后,其结果保存为XDL格式文件,然后利用Xilinx的XDL工具来验证其正确性。
以18位累加器ae18_core为测试用例,其测试范围涵盖双输出端口的LUT、Muxf7/Muxf8、进位链、RAM32M、RAM32X1D等分布式RAM,以及特殊的IP核DSP48。输入为综合后的网表文件(.edf,.vlg),通过本文提出的优化装箱布局布线后以XDL格式的文件输出,即ae18_core_route.xdl文件,在Xilinx工具ISE Design Suite 64 Bit Command Prompt中输入xdl-xdl2ncd ae18_core_route.xdl、drc-eae18_core_route. ncd、netgen-ecnformalityae18_core_route.ncdae18_ core_route.v-w命令,验证装箱结果和规则的正确性。如图7所示,图7(a)是Xilinx装箱后的结果,图7(b)是本文结合面向对象程序设计装箱后的结果,图7(c)通过Xilinx工具验证了装箱结果的正确性。

图7 装箱结果的验证
5 结论
针对Xilinx Virtex-5架构的商业FPGA,分析其硬件架构,建立数据模型和装箱DRC;并对其特殊单元优先处理,结合已有的装箱算法通过面向对象的设计方法来实现,并通过Xilinx的XDL工具对装箱结果进行验证。
[1]V Betz,J Rose.Cluster-based logic blocks for FPGAs:Area-efficiency vs.input sharing and size[C].IEEE Custom Integrated Circuits Conference,Santa Clara,CA,1997:551-554.
[2]A Marquardt,V Betz,J Rose.Usingclusterbased logic blocks andtiming-drivenpackingtoimproveFPGAspeedanddensity[C].International Symposium on Field-Programmable Gate Arrays,Monterey,CA,1999:37-46.
[3]E Bozorgzadehy,S Ogrenci Memiky,X Yang z,M Sarrafzadehy.Routability-drivenPacking:Metricsand Algorithms for Cluster based FPGAs[M].
[4]胡云,王伶俐,唐璞山,童家榕.基于布通率的FPGA装箱算法[J].计算机辅助设计与图形学报,2007.
Packing Implementation and Verification for 10M-gate FPGA
HU Kai1,DONG Zhidan2,HUI Feng2,LI Qing2,DONG Yiping1
(1.China Electronics Technology Group Corporation No.58 Research Institute,Wuxi 214072,China;
2.East Technologies,Inc,Wuxi 214072,China)
Packing is a key step in the FPGA tool flow that straddles the boundaries between synthesis,technology mapping and placement,and that greatly influences circuit speed,density,and power consumption. In the paper,xc5vlx20tff323-2 device,a 10M-gate FPGA,is described in detail covering the packing of the net list synthesized by XST tool,conversion to XDL file and verification by Xilinx tools.
FPGA;packing;verification

TN402
A
1681-1070(2016)10-0032-04
2016-6-3
胡凯(1984—),男,江苏常州人,东南大学电子科学与技术专业本科毕业,工程师,从事集成电路设计工作,在FPGA(可编程逻辑门阵列)技术领域有丰富经验。
猜你喜欢
烟草科技(2022年5期)2022-05-30
包装工程(2022年3期)2022-02-22
学生天地(2020年17期)2020-08-25
人大建设(2020年3期)2020-07-27
人大建设(2020年2期)2020-07-27
铁道通信信号(2019年5期)2019-10-10
当代陕西(2019年14期)2019-08-26
铁道通信信号(2019年12期)2019-05-21
铁道通信信号(2019年2期)2019-03-26
电脑知识与技术(2016年19期)2016-08-18
