
基于排序支持向量机的本体学习算法
2016-12-02 05:49高炜兰美辉
苏州科技大学学报(自然科学版) 2016年4期
高炜,兰美辉
(1.云南师范大学信息学院,云南昆明650500;2.曲靖师范学院计算机科学与工程学院,云南曲靖655011)
基于排序支持向量机的本体学习算法
高炜1,兰美辉2
(1.云南师范大学信息学院,云南昆明650500;2.曲靖师范学院计算机科学与工程学院,云南曲靖655011)
作为概念结构化表示、存储和管理的模型,本体越来越受到计算机各领域学者的重视,并广泛应用于生物学、医学、制药学、地理信息系统等其他学科领域。该文提出了一种基于排序支持向量机的本体学习算法,其特点是样本集由顶点对构成,并采用带有敏感参数的亏损函数。最后,将新本体算法应用到生物基因学本体和仿生机器人本体,分别验证了算法对本体相似度计算和本体映射有较高的效率。
本体;相似度计算;本体映射;排序支持向量机
作为一种概念语义表示模型,本体自20世纪90年代引入计算机领域以来,一直受到极大的关注,并得到长足的发展。该模型已经应用于信息检索、查询扩展、图像检索和数据集成等诸多领域。在近30年的发展中,本体作为一种强大的工具模型,被应用在多个学科,比如医学、生物学、制药学、地理科学、心理学和教育学等。一般用本体图G=(V,E)作为模型来表示本体O,其图中顶点表示概念,边表示概念之间的从属关系。本体在各学科中的应用,其核心问题是本体概念之间的相似度计算,进而在本体图模型中使用学习方法的过程,即通过样本得到最优本体函数f:V→R,由此将本体图中每个顶点映射成实数。最后,本体概念之间的相似度则通过概念对应顶点在本体函数下的像的几何距离来衡量。最简单的方法是通过对应实数在实数轴上的距离来衡量,距离越小,相似度越高。
文献[1]将一般排序学习方法引入到本体映射;文献[2]将流形上拉普拉斯算子反映到图上,从而把问题归结于求本体图拉普拉斯矩阵次小特征值对应的特征向量,该向量第i个分量即为第i个顶点对应的实数;文献[3-4]利用有向图和无向图上正则化模型得到本体相似度计算和本体映射学习算法;文献[5]充分利用本体图树形结构特征,并充分考虑到未标记数据特征,由此提出k-部排序半监督学习算法;此外,文献[6]利用正则化瑞利系数,提出新的半监督k-部排序学习算法;文献[7]给出一类新的迭代计算方法,并将此方法应用于本体半监督学习。
笔者利用排序支持向量机,提出一种新的本体学习算法,并将新算法应用于本体工程中的本体相似度计算和本体映射算法。实验部分将该算法应用于生物基因领域验证其对本体相似度计算的有效性,并应用于仿生机器人领域来验证算法对构建本体映射的效率。
1 新算法描述
为了将本体概念的相关信息融入到学习方法中,首先需要对本体概念信息进行预处理,其中关键的一步是将每个概念对应顶点的信息封装到一个固定维度的向量中。不失一般性,设每个顶点的信息都用p维向量来表示。并且在不引起混淆的情况下,用v={v1,…,vp}同时表示顶点v以及顶点v对应的向量。基于排序方法的本体学习算法,其目标可概括为通过本体样本集S的学习得到本体函数f:V→R,该函数是一个得分函数,将所有本体顶点均映射到实数,通过实数之间的几何距离来衡量两顶点对应本体概念之间的相似程度。
排序与之前传统的分类和回归算法有着本质的区别,此类学习算法关注的是由排序函数得到的实数在
实数轴上的相对位置。一般来说,本体学习的样本是一个顶点集合S={(v1,y1),…,(vn,yn)},对应的经验模型可以表示为

l:RV×V×V→R为本体亏损函数,用来衡量排序出错时的惩罚量。最优本体函数f通过最小化Rˆ(f,S)得到。
下面给出基于排序支持向量机(RankSVM)的本体学习算法。与经典排序支持向量模型相比,文中针对本体的具体应用,对如下两点作了改进:(1)传统排序支持向量机模型采用部分实例集作为样本,而在本体具体应用中,可能只需对部分本体顶点对进行相似度计算,因而文中采用一个本体顶点对的集合E′作为样本,并且假设顶点对中前一个顶点在排序函数下的得分比后一个顶点要高;(2)传统排序支持向量机模型采用平方亏损、指数亏损、对数亏损、铰链亏损等亏损函数,文中考虑排序算法的实际特征,允许f(v)和标记y之间存在一定范围的误差,进而采用带敏感参数的亏损函数。
具体地说,考虑上述(1),采用如下经验模型

其中E′是顶点对(v,v′)构成的集合,并且它们对应的标记满足y>y′;I是真值函数,当下标所示论断为真时值为1,否则函数值为0。由于真值函数不可导,因此,直接计算公式(1)的难度很大。用连续凸亏损函数取代真值函数,即


其中取K:V×V→R为了核函数(比如高斯核、热核、多项式核等),F即为与核函数K相关联的再生核希尔伯特空间,C为平衡参数,项的作用是控制本体函数f的光滑性,从而使算法具有较强的泛化性。引入个变量αij,则优化模型又可以写成

s.t.0≤αij≤对任意(vi,vj)∈E′成立。
由统计学习理论中的表示理论可知,最优解可表示成

最后,将亏损函数替换为带敏感参数的形式,得到

其中ε>0表示误差量,一般取值较小。优化模型(6)可用经典梯度下降策略得到最优解。
特别地,当敏感参数为0或者不带敏感参数的情况下,除了经典梯度下降策略,文中还给出了如下迭代计算方法。
算法A:不带敏感参数条件下基于排序支持向量机的迭代计算方法
输入:训练样本E′以及样本顶点对中每个顶点对应的标记y,核函数K,参数C,T,η
循环:For t=1 to T do

在上述算法中,Q(α)表示公式(4)的二次目标函数。
2 实验
下面通过两个具体的仿真实验来分别验证算法对基因领域相似度计算和仿生机器人领域构建本体映射的效率。特别需要提醒的是,两个实验验证的算法均是模型(6),而上节给出的迭代计算方法由于不涉及敏感参数,故不作为文中实验的对象。
2.1 本体相似度计算实验
由http://www.geneontology.Org网站构建的生物学领域GO本体(该本体为基因相关本体,记为O1),其结构如图1所示,其目的是从语义的角度来分析原子作用、分子结构以及生物过程之间的相互关联。对生物和基因领域工作者来说,它是个有效的数据库,用于相关信息的检索和查询,并可以通过检索来了解其他关联信息。该实验是验证文中算法对GO本体进行相似度计算的效率。实验结果的好坏用P@N[8]平均准确率来衡量。另外,还将本体回归算法[9]、快速排序算法[10]和标准本体排序算法[1]也应用于该生物基因GO本体。表1显示了当N取3、5、10时,四种方法得到数据的对比。
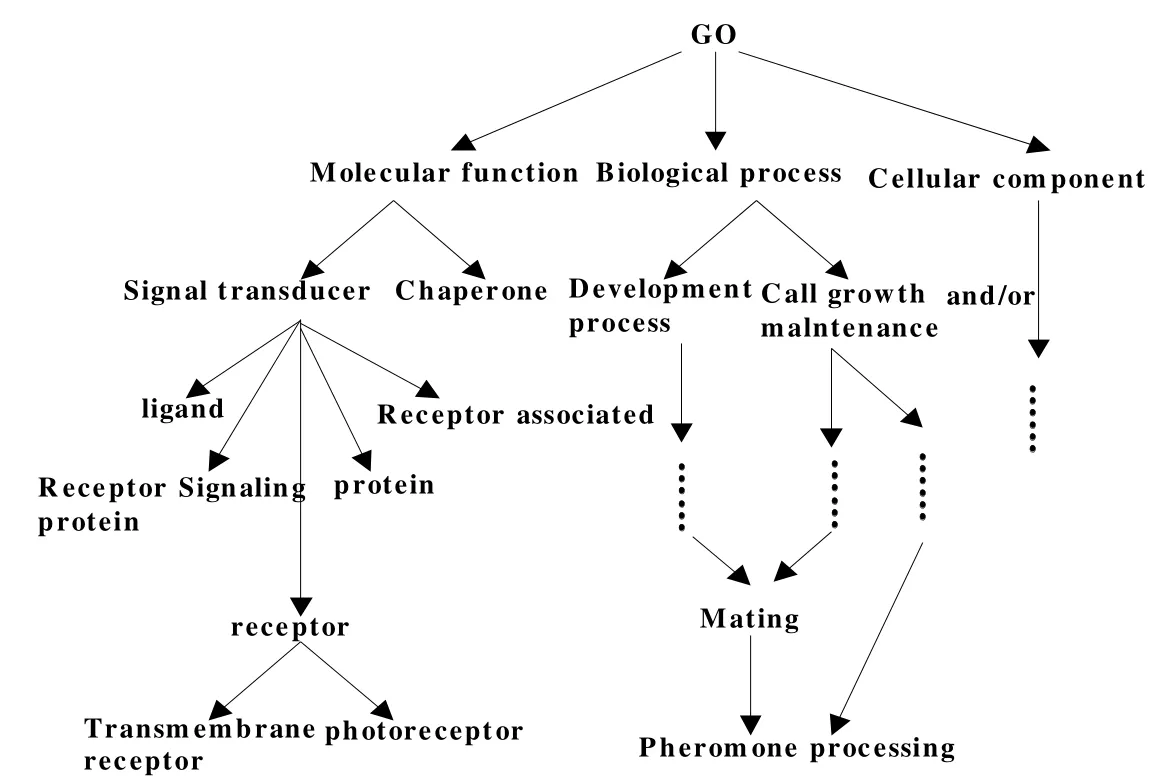
图1 GO本体O1

表1 GO本体上四种方法数据对比
由表1中P@3、P@5、P@10准确率对比可知,文中算法对于生物基因GO本体而言,其效率高于其他三类算法。
2.2 本体映射实验
为验证文中算法对建立本体映射的有效性,下面采用仿生机器人本体O2(如图2)和O3(如图3)作为实验对象。其目标是在O2和O3之间建立基于相似度的本体映射。将标准本体排序算法[1]、快速排序算法[10]和基于NDCG测度的本体学习算法[11]也分别应用于仿生机器人本体,并同样采用P@N准确率作为标准对实验结果进行对比。取N的值分别为1、3、5,部分数据见表2。

图2 仿生机器人本体O2

图3 仿生机器人本体O3

表2 仿生学本体四种方法数据对比
根据表2中准确率对比可知,文中基于排序支持向量机的本体算法对于在仿生机器人本体O2和O3间建立本体映射的效率明显要高于其他三种学习算法。
3 结语
笔者提出一种基于排序支持向量机的本体算法,其特点是学习样本由本体顶点对构成,并在亏损函数的选择上选取带敏感参数的亏损函数。两个实验结果表明基于排序支持向量机的本体算法对本体相似度计算和本体映射构建都有较高的效率。从而说明算法在本体应用领域有广泛的前景。
[1]高炜,兰美辉.基于排序学习方法的本体映射算法[J].微电子学与计算机,2011,28(9):59-61.
[2]高炜,梁立,张云港.基于图学习的本体概念相似度计算[J].西南师范大学学报(自然科学版),2011,36(4):64-67.
[3]高炜,梁立.基于超图正则化模型的本体概念相似度计算[J].微电子学与计算机,2011,28(5):15-17.
[4]高炜,朱林立,梁立.基于图正则化模型的本体映射算法[J].西南大学学报(自然科学版),2012,34(3):118-121.
[5]高炜,梁立,徐天伟,等.半监督k-部排序算法及在本体中的应用[J].中北大学学报(自然科学版),2013,34(2):140-146.
[6]高炜,梁立,徐天伟.基于正则化瑞利系数的半监督k-部排序学习算法及应用[J].西南师范大学学报(自然科学版),2014,39(4):124-128.
[7]彭波,徐天伟,李臻,等.迭代拉普拉斯半监督学习本体算法[J].计算机工程与科学,2014,36(11):2164-2168.
[8]CRASWELL N,HAWKING D.Overview of the TREC 2003 web track[C]//Proceedings of the Twelfth Text Retrieval Conference.Gaithersburg, Maryland,NIST Special Publication,2003:78-92.
[9]GAO Y,GAO W.Ontology similarity measure and ontology mapping via learning optimization similarity function[J].International Journal of Machine Learning and Computing,2012,2(2):107-112.
[10]HUANG X,XU T,GAO W,et al.Ontology similarity measure and ontology mapping via fast ranking method[J].International Journal of Applied Physics and Mathematics,2011,1(1):54-59.
[11]GAO W,LIANG L.Ontology similarity measure by optimizing NDCG measure and application in physics education[J].Future Communication,Computing,Control and Management,2011,142:415-421.
Ontology learning algorithm based on ranking SVM
GAO Wei1,LAN Meihui2
(1.School ofInformation,Yunnan Normal University,Kunming 650500,China;2.Department of Computer Science and Engineering,Qujing Normal University,Qujing 655011,China)
As a conceptual structure representation,storage and management model,ontology has raised increasing attention among scholars in various fields of computer,and been widely used in other disciplines such as biology,medicine,pharmaceutics,and geographic information system.In this paper,we have presented a class of ontology learning algorithm based on ranking SVM in which the sample set is consisted of vertex pairs and the loss function is applied with sensitive parameters.The new algorithm is applied to biological gene ontology and humanoid robot ontology.The results have verified that the algorithm has a higher efficiency in calculating the similarity of ontology and constructing ontology mapping.
ontology;similarity measuring;ontology mapping;ranking SVM
TP393.092
A
1672-0687(2016)04-0052-05
责任编辑:艾淑艳
2015-09-18
国家自然科学基金资助项目(11401519)
高炜(1981-),男,浙江绍兴人,副教授,博士,研究方向:机器学习,图论。
猜你喜欢
中等数学(2021年9期)2021-11-22
山东科学(2018年6期)2018-12-20
现代营销(创富信息版)(2018年5期)2018-07-12
中国自行车(2017年5期)2017-06-24
制造业自动化(2017年2期)2017-03-20
中国化肥信息(2016年48期)2016-05-17
文学教育(2016年27期)2016-02-28
IT时代周刊(2015年9期)2015-11-11
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
