
基于邻域离散度的异常点检测算法*
2016-12-19 01:12沈琰辉刘华文徐晓丹赵建民陈中育
计算机与生活 2016年12期
沈琰辉,刘华文,徐晓丹,赵建民,陈中育
浙江师范大学 数理与信息工程学院,浙江 金华 321004
基于邻域离散度的异常点检测算法*
沈琰辉,刘华文+,徐晓丹,赵建民,陈中育
浙江师范大学 数理与信息工程学院,浙江 金华 321004
SHEN Yanhui,LIU Huawen,XU Xiaodan,et al.Outlier detection algorithm based on dispersion of neighbors.Journal of Frontiers of Computer Science and Technology,2016,10(12):1763-1772.
异常点检测在机器学习和数据挖掘领域中有着十分重要的作用。当前异常点检测算法的一大缺陷是正常数据在边缘处异常度较高,导致在某些情况下误判异常点。为了解决该问题,提出了一种新的基于邻域离散度的异常点检测算法。该算法将数据点所在邻域的离散度作为该数据点的异常度,既能有效避免边缘数据点的异常度过高,又能较好地区分正常点与异常点。实验结果表明,该算法能够有效地检测数据中的异常点,并且算法对参数选择不敏感,性能较为稳定。
异常点检测;机器学习;数据挖掘;主成分分析
1 引言
随着数字化技术的发展,人们收集到的数据越来越多。然而由于仪器故障、信号干扰、反常行为等因素,数据中通常存在异常点。异常点和其余数据点之间存在显著差异,一方面会干扰特征提取、模式识别等机器学习任务,另一方面又有助于发现信用卡欺诈、基因突变、网络入侵等异常现象[1-2]。因此,异常点检测引起了研究学者的广泛关注。
当前,许多异常点检测算法通过距离或密度来度量数据点之间的差异性,例如LOF(local outlier factor)算法[3]、LDOF(local distance-based outlier factor)算法[4]等。然而这些算法的主要问题是边缘数据点的异常度较高,由于某些情况下边缘数据点并非异常点,这种效应会影响异常点检测效果。例如对于均匀分布的数据(如图1),其中并没有异常点,但是在上述几个算法下,点A和B的异常度却高于其他数据点。如果数据是高斯分布的,这种效应还将进一步放大。显然这种效应对异常点检测是不利的,因为它会模糊正常点和异常点之间的界限。并且在无监督学习的场景下,由于异常点的个数未知,一个有效的异常点检测算法不但要适用于含有异常点的数据集,对于不含有异常点的数据集也要给出合理的结果。
为了解决上述问题,本文提出了基于邻域离散度的异常点检测算法。该算法将数据点所在邻域的离散度作为其异常度,因此对于均匀分布的正常数据点,该算法给出的每个数据点的异常度都是相同的,不存在边缘放大效应。实验结果显示,该算法能够更有效地检测数据集中的异常点。
本文组织结构如下:第2章介绍了异常点检测的相关工作;第3章介绍了主成分分析(principal component analysis,PCA)及其与奇异值分解(singular value decomposition,SVD)的关联;第4章介绍了本文算法的具体原理、算法步骤、算法复杂度以及参数的选择;第5章将本文算法和其他几种算法做了对比实验,分析了算法效果;第6章对全文进行了总结。
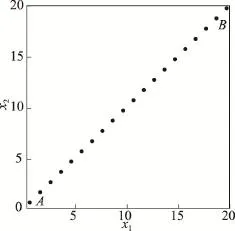
Fig.1 Uniformly distributeddata图1 均匀分布的数据
2 相关工作
异常点检测的主要目的是检测数据集中的少数类,目前已经提出了许多异常点检测算法。根据模型的不同,大致可以分为基于统计模型的异常点检测、基于邻近度的异常点检测、基于子空间的异常点检测和基于集成学习的异常点检测。
基于统计模型的异常点检测算法早在计算机发明以前就有不少统计学家进行了研究。该模型假设数据在总体上服从某种分布,并将每个数据点与该分布的契合程度作为其异常度,因此这类方法得出的通常是全局意义上的异常点。一种具有代表性的方法是基于深度的异常点检测算法[5],它假设数据在空间中是由内到外一层一层包裹而成,通过计算出凸多边形包围盒,将数据层层剥离,越处在外层多边形上的数据点异常度越高,但这种方法对超过三维的数据就不甚理想。近年来,Kriegel等人提出了ABOD(angle based outlier detection)算法[6]。该算法的基本设想是:若某个数据点位于数据分布越稀疏的区域,那么以该点为顶点,任取其余两个点与该点分别作直线,所形成的个夹角的方差越小。该算法主要优点是无需设置参数,受数据维数的影响较小,然而该算法的时间复杂度为O(dn3),当数据量很大时,计算开销难以接受。为此Pham等人提出了FastVOA(fast variance of angles)算法[7]。该算法通过随机投影和AMS Sketch方法对ABOD算法作近似处理,在一定误差内,可以将时间复杂度降低到O(n lbn(d+lb2n))。
基于邻近度的异常点检测算法侧重于寻找局部异常点。这类方法的基本假设是,数据集中可能包含多个数据种类,每类数据的分布性质不同,从全局角度寻找异常点不一定有效。因此这类方法在计算数据点的异常度时,只选择对应的局部邻域作为参照集,而不考虑数据的整体分布。这类方法中最具代表性的是基于距离的异常点检测算法和基于密度的异常点检测算法。基于距离的异常点检测算法最早由Knorr等人提出[8-9],该算法的基本设想是:若某个数据点在半径为ϵ的区域内的近邻占总数据点的比例不超过π,则该数据点为异常点。该算法的主要缺点是,实际应用中很难估计参数ϵ。Ramaswamy等人提出了基于k近邻的算法[10],该算法将数据点到第k个近邻的距离作为该点的异常度。基于距离的异常点检测算法的主要缺陷是,如果数据集同时包含多个密度不同的簇,那么密度较小的簇所包含的数据点容易被误判为异常点。为了克服此问题,Breunig等人提出了LOF算法[3]。该算法的基本设想是:如果某数据点处的密度低于其邻域内其他数据点处的平均密度,则该点为异常点,反之则为正常点。该算法的主要问题是对k的取值比较敏感。Kriegel等人提出了LoOP(local outlier probabilities)算法[11],该算法将LOF算法的思想与概率论相结合,使得算法对带噪声的数据更健壮,并且该算法给出的异常度等价于某数据点为异常点的概率,更具有直观意义。Zhang等人提出了LDOF算法[4],该算法在某种程度上借鉴了LOF算法相对密度的思想,它把某个数据点到k个近邻的距离的均值称作KNN distance,把k个近邻彼此之间的距离的均值称作KNN inner distance,然后把这两种距离的比值作为该数据点的异常度。
传统的基于邻近度的异常点检测算法都会受到“维数灾”的影响[12]。为了克服此问题,Agrawal对LOF算法进行了改进[13],提出了基于局部子空间的异常点检测算法。该算法的基本设想是:若数据点的近邻在某个属性上的方差越小,则在该属性上越容易发现异常点,应该提高该属性的权重,因此该算法使用加权欧式距离代替LOF算法中的距离函数。Keller等人通过对数据集在不同子空间内属性的边际分布进行研究,发现异常点只有在某些高对比度子空间内才较为显著,因此提出了HiCS(high contrast subspaces)算法[14]。该算法分两阶段进行:第一阶段搜索高对比度子空间,本质上是特征选择的过程;第二阶段在特定的子空间内使用传统方法进行异常点检测。实验结果显示,基于这一改进的LOF算法在高维数据上的效果有了一定改善。然而这种方法的缺点是搜索子空间较为耗时,并且由于各个数据点所适用的子空间不一定相同,若只用一个子空间会影响各数据点异常度的准确性。Kriegel等人提出了SOD[15]subspace outlier degree)算法和COP[16](correlation outlier probability)算法,这两个算法能够对每个数据点选择最佳的子空间进行异常度计算,但是算法复杂度较高。
基于集成学习的异常点检测是近年来出现的一个新的研究热点。这类方法通过构造多个不同的异常点检测器,然后合并所有检测器的输出,使得检测效果比任一单个的检测器更好[17-19]。这类方法的有效性主要取决于3个因素:检测器本身的准确度,检测器之间的差异性,如何集成各个检测器的输出[20]。
3 PCA
PCA是无监督学习中常用的一种数据分析方法,其主要思想是:在降低数据维数的同时,保持数据中对方差贡献最大的特征;其基本方法是:通过正交线性变换,将原数据投影到一个新的坐标系统中,使得新数据在各个主分量(principal component,PC)上投影的方差最大化。
更具体地说,假设数据矩阵为X∈ℝn×d,且每列均值为0。PCA寻求一组标准正交基W=(w1,w2,…,wp),其中wk∈ℝd,使得:
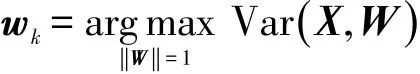
为了求解上式,先将其展开为矩阵形式:
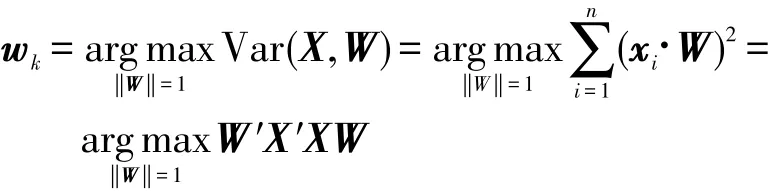
通过拉格朗日乘子法得到:
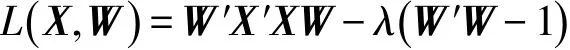
令L(X,W)关于W的偏导数为0,并计算化简得:
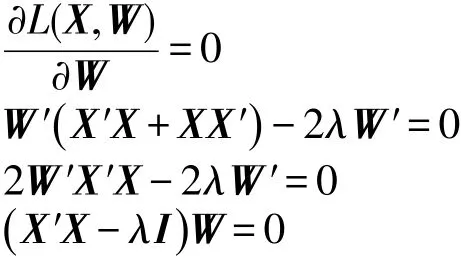
由于X的协方差矩阵Σ=X′X,于是有:
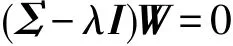
显然上式是一个特征方程。由于协方差矩阵Σ是实对称矩阵,能够对其对进行特征分解,所得的特征向量即为标准正交基,各个特征值即为方差。
然而在实际计算中,为了保证数值稳定性,PCA通常借助奇异值分解来实现。奇异值分解指的是把矩阵X分解为如下形式:
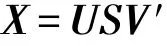
其中,U为n×n阶正交矩阵,每列称为左奇异值向量;V为d×d阶正交矩阵,每列称为右奇异值向量;S为n×d阶对角矩阵,对角线上的元素Sij称为奇异值。将协方差矩阵Σ按奇异值分解的方式展开:
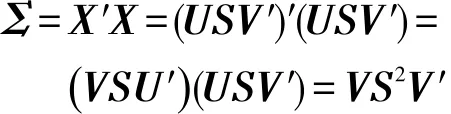
可见PCA所求的标准正交基W就是矩阵X的右奇异值向量V,对应的方差就是矩阵X的各个奇异值的平方。因此直接对矩阵X进行奇异值分解就能间接实现PCA,无需通过计算协方差矩阵然后对其特征分解来实现。
4 基于邻域离散度的异常点检测算法
4.1 离散度
一般而言,数据中的异常点分布较为稀疏,正常点较为密集,如图2所示。为了便于讨论数据点在局部空间内的分布情况,本文先给出邻域的定义。
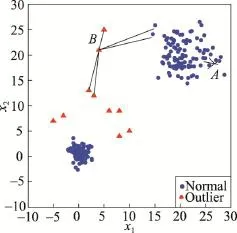
Fig.2 Data contaminated with outliers图2 含异常点的数据
定义1(邻域)对于数据点xi∈ℝd,若其k阶近邻依次为,其中。则称点集为数据点xi的邻域,点集为数据点xi的去心邻域。
在一定的k取值下,正常点的邻域主要包含其他正常点以及少量噪声点,因此正常点的邻域所占空间较小,邻域较为紧致;而异常点的邻域包含其他异常点甚至正常点,因此异常点的邻域所占空间较大,数据点在该空间内的离散度较高。如图2所示,正常数据点A的去心邻域都是正常点,异常数据点B的去心邻域既包含正常点也包含其他异常点。利用这一特性,只要度量各个数据点所在邻域的离散度,就能实现异常点检测。
可见本文对离散度的定义本质上等同于迹范数(trace norm),因而。根据文献[21]的证明,矩阵的迹范数具有以下性质:
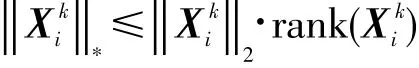
该性质表明,迹范数的上界是谱范数与秩的乘积。若迹范数越大,则谱范数或秩越大,说明构成邻域的数据点较为离散;若迹范数越小,则谱范数和秩都较小,说明邻域在整体上较为紧致。因此定义2能够有效地刻画邻域的离散度。
为了进一步验证定义2对正常点和异常点的区分能力,本文对图2所示的数据集做了初步的实验:取k=5,分别计算正常点和异常点的邻域离散度,然后将离散度视为随机变量,通过核密度估计分别绘制出相应的概率密度函数。最终如图3所示,其中蓝色实线代表正常点的邻域离散度概率密度函数,红色虚线代表异常点的邻域离散度概率密度函数,可见两个分布的重叠部分较小,因此定义2能够有效区分正常点和异常点。
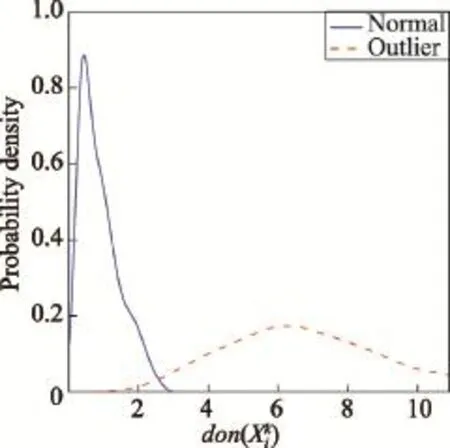
Fig.3 Probability density function of dispersion图3 离散度的概率密度函数
4.2 基于邻域离散度的异常点检测算法
由前文的讨论可知,正常点的邻域离散度较小,而异常点的邻域离散度较大,通过计算数据点所在邻域的离散度,就能得知该数据点的异常度。因此,本文对数据点的异常度定义如下。
定义3(异常度)数据点xi的异常度即为该点所在的k阶邻域的离散度。若某个数据点的异常度越高,则该数据点越有可能是异常点。
根据上述定义,通过计算每个数据点的异常度,按数值高低进行排序,最后输出异常度最高的t个数据点,就可以实现异常点检测。具体算法如下:
算法1 DON算法

本算法通过一次循环就能完成。对每个数据点来说,主要的计算量在于两部分:第一部分是寻找数据点xi的k近邻,通过使用k-d树[22]作为数据结构,查询k近邻的时间复杂度为O(dnlbn)。第二部分是对邻域做主成分分析,由于主成分分析是基于奇异值分解实现的,时间复杂度为O(min(kd2,k2d))。因此当k的取值不超过数据维数时,每个数据点的计算复杂度与维数的关系仍然是线性的。
参数k的选取对算法效果有着最直接的影响。由定义1可知,当k=n时,任意数据点所在邻域等同于整个数据集X,因此邻域的离散度等同于整个数据集的离散度,算法将失去区分能力,从而k的选取并不是越大越好。事实上,如果整个数据集落在m维(m<d)的低维流形上,那么任意局部邻域的有效维数m′都不会超过m,这就意味着取k=m就足以刻画大部分正常点所在邻域的特性。而确定整个数据集的有效维数可以通过对整个数据集做主成分分析来确定,如果前m个主成分的可解释变异量(explained variance)足够高,就可以舍弃其余主成分,认为数据集的有效维数是m。
参数t的选取也十分重要。在实际的应用场景中,由于没有Ground Truth,无法得知真实异常点的个数,但是可以通过统计的方法估计t的大小。设正常点的异常度为随机变量Y1,异常点的异常度为随机变量Y2,所有数据点的异常度为随机变量Y。若Y1与Y2均服从高斯分布,那么Y就服从混合高斯分布:
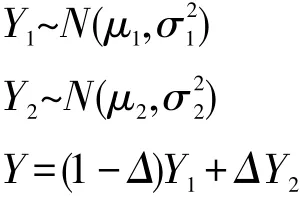
其中Δ∈{0,1},Pr(Δ=1)=π。通过EM算法[23],给定适当的初始值和收敛条件,经过数次迭代就能求出隐变量π,即为异常点的比例,因此可以取。
5 实验
5.1 实验设置
实验采用UCI数据集[24],具体属性如表1所示。其中Iris、Wine数据集由3种类别的样本构成,因此将其中一类数据进行采样,使其所占比例低于10%,并标记为异常点。
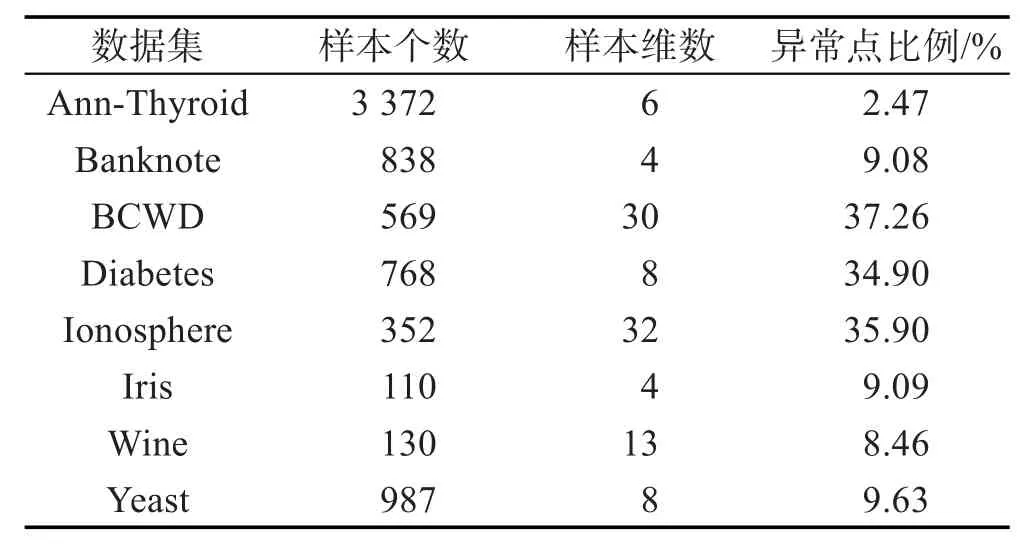
Table 1 Properties of dataset表1 数据集属性
为了验证本文算法的有效性,将DON算法与其他几种流行的异常点检测算法进行对比,这些算法分别是LOF算法[3]、LDOF算法[4]、LoOP算法[11]、HiCS算法[14]、SOD算法[15]。其中LOF和LoOP是基于密度的异常点检测算法,LDOF是基于距离的异常点检测算法,HiCS和SOD是基于子空间的异常点检测算法。这几种算法的实现均来自于ELKI数据挖掘框架[25]。
由于所有对比算法本质上都是依据数据点的局部邻域来计算异常度,对算法效果影响最大参数是k。因此本实验对所有算法分别取k=5,6,…,100进行测试。对于SOD算法,根据文献中的建议[15],实验将参数l设置为k,α设置为0.8。
5.2 评价标准
为了更好地对比各个算法在不同参数下的检测效果,本文采用AUC(area under curve)作为评价标准。AUC指的是ROC(receiver operating characteristic)曲线下方的面积,而ROC曲线的参数式方程如下:
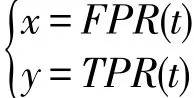
假设所有数据点为集合D,真实异常点为集合G,算法输出的前t个异常度最高的数据点为集合S(t),则TPR(t)和FPR(t)的计算公式如下:
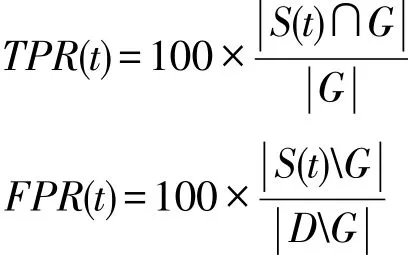
5.3 实验结果与分析
各个算法在不同k值下的AUC如图4所示。
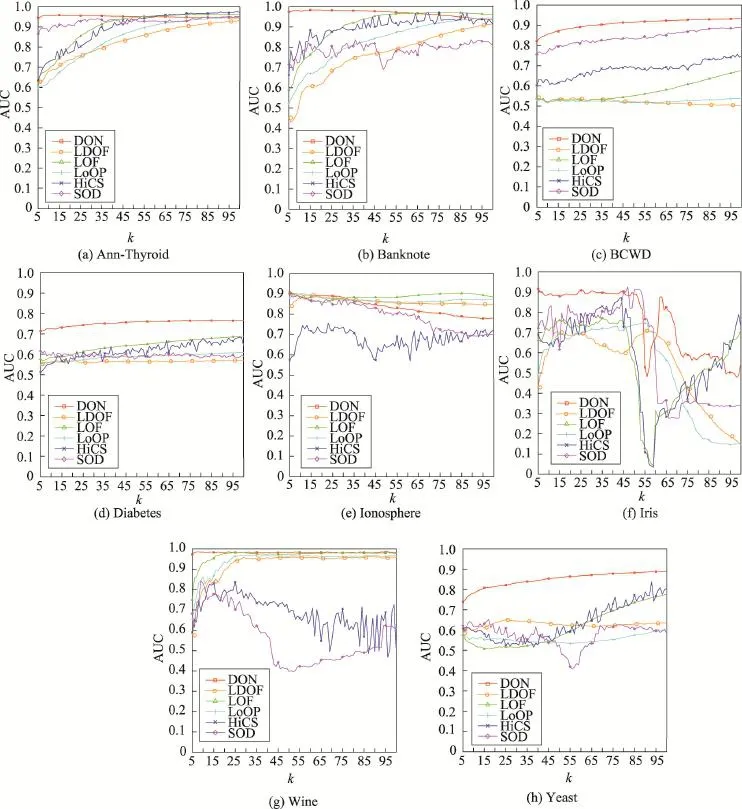
Fig.4 AUC trends with differentksettings of DON,LDOF,LOF,LoOP,HiCS,SOD图4 k取不同值时DON、LDOF、LOF、LoOP、HiCS、SOD算法的AUC变化
对于Ann-Thyroid、Banknote两个数据集来说(如图4(a)、(b)),DON算法在k增大时,AUC呈现出一定的降低趋势,但总体来说AUC仍然维持在0.9以上,算法比较稳定。SOD算法的AUC波动也不大,但是在各种k取值下,算法有效性均不及DON算法。而其余的算法在k≥100之后,AUC才趋于稳定。因为随着k值增大,算法运行时间也越长,而且对无监督学习来说,算法在实际应用时没有Ground Truth,难以调整算法参数,所以相比之下DON算法具有一定优势。
对于BCWD、Diabetes、Yeast数据集来说(如图4(c)、(d)、(h)),由于这3个数据集的异常点比例在30%以上,取较大的k值才能刻画数据点的局部特性。因此大部分算法的AUC总体上随着k的增大而增大,但是DON算法的AUC高于其他算法,并且曲线走势较为稳健。
对于Ionosphere数据集来说(如图4(e)),DON算法在k≤30时效果较好,之后呈现出下降趋势。LOF和LDOF算法在k=5附近取得最好效果,之后也逐渐下降。而LoOP算法则在k≥85附近才取得最好效果。HiCS算法总体上效果不佳,而且波动较大。
对于Iris数据集来说(如图4(f)),大部分算法在k>50之后,AUC开始显著下降。考虑到该数据集由两种数量为50的正常点以及10个异常点构成,当k>50时,正常点的邻域必然包含异常点或是另一类别的数据点,导致正常点的异常度增大,与真实异常点之间的区分度降低,因此AUC的下降是合理的。
对Wine数据集来说(如图4(g)),DON算法在取不同的k时AUC较高,且波动较小。而LOF、LDOF、LoOP算法则在k≥25之后,AUC才逐渐趋于稳定。相比之下,HiCS、SOD算法的表现不太理想,尤其是k≥25之后,AUC严重降低。
综上分析,DON算法在7个数据集上都取得了较好的效果,在不同参数下表现也较为稳定,AUC基本不会随着k值的变化出现较大波动。
6 总结与未来工作
本文提出了一种新的基于邻域离散度的异常点检测算法,该算法能够有效克服正常数据在边缘处异常度过高的问题。实验结果表明,本文算法能够更有效地检测数据集中的异常点,并且对参数选择不敏感,性能较为稳定。进一步的工作包括分析本文的异常点定义与其他文献中的异常点定义之间的内在联系,研究使用集成学习的方式进一步提高异常点检测的准确率。
[1]Yang Chao,Chen Guoliang,Shen Yifei.Outlier analysis for gene expression data[J].Journal of Computer Science and Technology,2004,19(1):13-21.
[2]Prakobphol K,Zhan J.A novel outlier detection scheme for network intrusion detection systems[C]//Proceedings of the 2008 International Conference on Information Security and Assurance,Busan,Korea,Apr 24-26,2008.Piscataway,USA: IEEE,2008:555-560.
[3]Breunig M M,Kriegel H P,Ng R T,et al.LOF:identifying density-based local outliers[C]//Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data,Dallas,USA,May 15-18,2000.New York:ACM,2000: 93-104.
[4]Zhang Ke,Hutter M,Jin Huidong.A new local distancebased outlier detection approach for scattered real-world data [C]//LNCS 5476:Proceedings of the 13th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining,Bangkok,Thailand,Apr 27-30,2009.Berlin,Heidelberg:Springer,2009:813-822.
[5]Johnson T,Kwok I,Ng R T.Fast computation of 2-dimensional depth contours[C]//Proceedings of the 4th International Conference on Knowledge Discovery and Data Mining, New York,Aug 27-31,1998.Menlo Park,USA:AAAI,1998: 224-228.
[6]Kriegel H P,Shubert M,Zimek A.Angle-based outlier detection in high-dimensional data[C]//Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Las Vegas,USA,Aug 24-27,2008.New York:ACM,2008:444-452.
[7]Pham N,Pagh R.A near-linear time approximation algorithm for angle-based outlier detection in high-dimensional data[C]//Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing,Aug 12-16,2012.New York:ACM,2012:877-885. [8]Knorr E M,Ng R T.A unified approach for mining outliers [C]//Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining,Newport Beach, USA,Aug 14-17,1997.Menlo Park,USA:AAAI,1997: 219-222.
[9]Knorr E M,Ng R T.Algorithms for mining distance-based outliers in large datasets[C]//Proceedings of the 24rd Inter-national Conference on Very Large Data Bases,New York, Aug 24-27,1998.San Francisco,USA:Morgan Kaufmann Publishers Inc,1998:392-403.
[10]Ramaswamy S,Rastogi R,Shim K.Efficient algorithms for mining outliers from largedata sets[C]//Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data,Dallas,USA,May 15-18,2000.New York: ACM,2000:427-438.
[11]Kriegel H P,Kröger P,Schubert E,et al.LoOP:local outlier probabilities[C]//Proceedings of the 18th ACM Conference on Information and Knowledge Management,Hong Kong, China,Nov 2-6,2009.New York:ACM,2009:1649-1652.
[12]Beyer K,Goldstein J,Ramakrishnan R,et al.When is“nearest neighbor"meaningful?[C]//LNCS 1540:Proceedings of the 7th International Conference on Database Theory,Jerusalem,Israel,Jan 10-12,1999.Berlin,Heidelberg:Springer, 1999:217-235.
[13]Agrawal A.Local subspace based outlier detection[C]//Proceedings of the 2nd International Conference on Contemporary Computing,Noida,India,Aug 17-19,2009.Berlin,Heidelberg:Springer,2009:149-157.
[14]Keller F,Muller E,Bohm K.HiCS:high contrast subspaces for density-based outlierranking[C]//Proceedings of the 2012 IEEE 28th International Conference on Data Engineering, Arlington,USA,Apr 1-5,2012.Piscataway,USA:IEEE, 2012:1037-1048.
[15]Kriegel H P,Kröger P,Schubert E,et al.Outlier detection in axis-parallel subspacesof high dimensional data[C]//Proceedings of the 13th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining,Bangkok,Thailand,Apr 27-30,2009.Berlin,Heidelberg:Springer,2009: 831-838.
[16]Kriegel H P,Kröger P,Schubert E,et al.Outlier detection in arbitrarily oriented subspaces[C]//Proceedings of the 12th IEEE International Conference on Data Mining,Brussels, Belgium,Dec 10-13,2012.Piscataway,USA:IEEE,2012: 379-388.
[17]LazarevicA,Kumar V.Feature bagging for outlier detection [C]//Proceedings of the 11th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago,USA,Aug 21-24,2005.New York:ACM,2005: 157-166.
[18]Liu F T,Ting K M,Zhou Zhihua.Isolation-based anomaly detection[J].ACM Transactions on Knowledge Discovery from Data,2012,6(1):3.
[19]Zimek A,Gaudet M,Campello R J,et al.Subsampling for efficient and effective unsupervised outlier detection ensembles[C]//Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago,USA,Aug 11-14,2013.New York:ACM,2013: 428-436.
[20]Zimek A,Campello R J,Sander J,Ensembles for unsupervised outlier detection:challenges and research questions a position paper[J].ACM SIGKDD Explorations Newsletter, 2013,15(1):11-22.
[21]Fazel M.Matrix rank minimization with applications[D]. Serra Mall,Stanford,USA:Stanford University,2002.
[22]Arya S,Mount D M,Netanyahu N S,et al.An optimal algorithm for approximate nearest neighbor searching fixed dimensions[J].Journal of theACM,1998,45(6):891-923.
[23]Hastie T,Tibshirani R,Friedman J.The elements of statistical learning[M].New York:Springer,2001:272-282.
[24]Lichman M.UCI machine learning repository[Z].2013.
[25]Achtert E,Kriegel H P,Zimek A.ELKI:a software system for evaluation of subspace clustering algorithms[C]//LNCS 5069:Proceedings of the 20th International Conference on Scientific and Statistical Database Management,Hong Kong, China,Jul 9-11,2008.Berlin,Heidelberg:Springer,2008: 580-585.

SHEN Yanhui was born in 1987.He is an M.S.candidate at Zhejiang Normal University.His research interests include machine learning and data mining,etc.
沈琰辉(1987—),男,江苏宜兴人,浙江师范大学硕士研究生,主要研究领域为机器学习,数据挖掘等。

LIU Huawen was born in 1977.He received the Ph.D.degree in computer science from Jilin University in 2010. Now he is an associate professor at Zhejiang Normal University.His research interests include data mining and machine learning,etc.
刘华文(1977—),男,江西乐安人,2010年于吉林大学获得计算机博士学位,现为浙江师范大学副教授,主要研究领域为数据挖掘,机器学习等。发表学术论文20余篇,其中SCI检索13篇,主持或承担过多项国家自然科学基金、浙江省自然科学基金、中国博士后基金和国家重点实验室开放项目等。

XU Xiaodan was born in 1978.She is a lecturer at Zhejiang Normal University.Her research interests include machine learning and data mining,etc.
徐晓丹(1978—),女,浙江东阳人,浙江师范大学讲师,主要研究领域为机器学习,数据挖掘等。发表学术论文10余篇,主持或参与过多项浙江省自然科学基金、浙江省教育厅项目等。

ZHAO Jianmin was born in 1950.He received the M.S.degree in computer science from Zhejiang University in 2000.Now he is a professor and Ph.D.supervisor at Zhejiang Normal University.His research interests include machine learning,cloud computing and Internet of things,etc.
赵建民(1950—),男,上海人,2000年于浙江大学获得硕士学位,现为浙江师范大学教授、博士生导师,主要研究领域为机器学习,云计算,物联网等。发表学术论文50余篇,主持或承担过多项国家自然科学基金、浙江省自然科学基金重大项目、国家公安部项目等。

CHEN Zhongyu was born in 1965.He received the Ph.D.degree in computer science from Shanghai University in 2010.Now he is a professor at Zhejiang Normal University.His research interests include machine learning and data mining,etc.
陈中育(1965—),男,浙江浦江人,2010年于上海大学获得计算机博士学位,现为浙江师范大学教授,主要研究领域为机器学习,数据挖掘等。发表学术论文30余篇,主持或承担过多项国家自然科学基金、浙江省自然科学基金、浙江省科技厅重点项目等。
Outlier DetectionAlgorithm Based on Dispersion of Neighbors*
SHEN Yanhui,LIU Huawen+,XU Xiaodan,ZHAO Jianmin,CHEN Zhongyu
College of Mathematics,Physics and Information Engineering,Zhejiang Normal University,Jinhua,Zhejiang 321004,China
+Corresponding author:E-mail:hwliu@zjnu.edu.cn
Outlier detection is an important task of machine learning and data mining.A major limitation of the existing outlier detection methods is that the outlierness of border points may be very high,leading to yield misleading results in some situations.To cope with this problem,this paper proposes a novel outlier detection algorithm based on the dispersion of neighbors.The proposed algorithm adopts the dispersion of a data point's neighbors as its outlier degree, thus the outlierness of border points will not be very high while the normal data and outliers can still be well distinguished.The experimental results show the proposed algorithm is more effective in detecting outliers,less sensitive to parameter settings and is stable in terms of performance.
outlier detection;machine learning;data mining;principal component analysis
10.3778/j.issn.1673-9418.1509075
A
TP181
*The National Natural Science Foundation of China under Grant Nos.61272007,61272468,61572443(国家自然科学基金);the Natural Science Foundation of Zhejiang Province under Grant No.LY14F020012(浙江省自然科学基金);the Foundation of Zhejiang Educational Committee under Grant No.Y201328291(浙江省教育厅项目).
Received 2015-07,Accepted 2015-09.
CNKI网络优先出版:2015-10-20,http://www.cnki.net/kcms/detail/11.5602.TP.20151020.1041.002.html
猜你喜欢
吉林大学学报(理学版)(2020年3期)2020-05-29
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
自动化学报(2018年7期)2018-08-20
周口师范学院学报(2016年5期)2016-10-17
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
现代防御技术(2016年1期)2016-06-01
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
