
大数据环境下的危机信息整合模型研究
2017-01-16 02:06李欣
现代情报 2016年12期
李欣
〔摘 要〕大数据环境下,突发事件的危机数据来源复杂多样,通过使用词语相似度计算和Folksonomy自由标记语言,把多模态的危机信息转化成基于内容特征项集合的单一情报信息源,建立危机信息采集萃取的整合组织模型。整合模型包括3个部分:危机信息内容特征项集的提取、RDF资源的统一描述存储和文本内容特征域的聚类划分。通过整合聚类危机信息源,从而实现不同危机信息源载体的规范化整合与组织,为危机的应急管理提供统一化的情报信息数据源。积极发挥情报效用,为突发事件的应急管理提供案例分析和情报预警。
〔关键词〕多模态信息;相似度计算;Folksonomy;RDF;文本聚类
〔中图分类号〕G250.73 〔文献标识码〕A 〔文章编号〕1008-0821(2016)12-0036-04
〔Abstract〕In a BIG DATA environment,the source of the crisis is complex,by using word similarity computation and network users free marking technology,the paper transfed the multimodal crisis information into a single information source,and an integrated model for the extraction of crisis information was established.The integrative course included three processes:collect information and extract features;describe and storage metadata;divide the feature domain.Realizing the integration of different sources of information sources,the paper provided a uniform information platform for emergency response of the crisis,to provide case analysis and intelligence warning.
〔Key words〕multimodal data;similarity computation;Folksonomy;RDF;text clustering
随着2015年“8.12”天津港的爆炸事件,应对突发事件的公共危机安全问题愈发受到了全社会的强烈关注。回顾近几年的公共安全突发事件[1],既有诸如“汶川”大地震的地质自然灾害,也有诸如“H7N9”禽流感的公共卫生事件。在网络化和信息化飞速发展的大数据环境下,面对诸如此类的公共安全突发事件,危机信息的呈现方式和载体形态逐渐多样化,采集的信息样本除了传统的结构化数据外,还有半结构化的文本数据和非结构化的图像数据。海量的多模态危机信息使管理决策部门迷失在信息的洪流中,给危机管理应对过程的预警机制和应急处理带来了巨大障碍,如何把形态各异的不同载体形式的海量危机信息进行统一标准和规范的整合与组织,为危机应对提供情报支持,是应对公共危机预警机制的重要环节,并受到了国内情报学领域专家的高度关注和积极探索。
毕玉青通过分析发现信息化社会中公共危机载体形态呈现出规模海量、影响广泛、未知性强、分散与集中相结合的大数据特质,提出应对危机管理的政府管理建议,从而提高危机应对的有效性[2]。
熊枫从传统政府危机信息管理中存在的问题出发,结合当前大数据时代的到来给政府危机信息管理带来的契机,进而深入探讨大数据时代政府有效管理危机信息,以弥补传统危机信息管理之不足的策略[3]。
武汉大学的李阳等通过分析大数据环境下的突发事件应急决策情报需求,提升应急决策情报支持能力,探索一种新的应急决策情报支持架构——以情报工程化为主导、情报平行化为支撑的“两融合”应急决策情报服务模式[4]。
吴春玉从政府决策过程入手,在分析不同决策过程信息需求的基础上,选定政府决策信息源,借鉴信息资源库的建设方法,构建政府决策信息采集模型[5]。
通过笔者对当前危机信息的相关文献整理研究后发现,危机情报的应急处理基本上都是围绕大数据环境下的情报需求,从研究作用机理入手,构建危机应对管理模型。本文通过理论研究和实例分析,使用词语相似度计算和Folksonomy自由标记语言,通过定量和定性相结合的分析手段,整合海量数据下不同载体形态的危机信息数据,按照统一的元数据标准规范进行存储,把多模态的危机信息转化成单一的情报信息源,聚类划分文本内容特征域集,从而为危机管理中的决策部门提供精准的危机情报。
1 TF.IDF、Folksonomy、RDF的概念及其模型
1.1 TF.IDF的概念及定义
著名的信息检索系统Smart中提出过一套词语权重的计算方法,这种度量词语在文档中反复出现程度的形式化指标称为TF.IDF。TF.IDF是信息检索领域常用的方法[6],计算词语的TF.IDF权重值,权重得分高的词语就是文本文档的主题词和关键特征词。
TF.IDF的定义如下:
定义1:假定文档集中有N篇文档,词项i在ni篇文档中出现,并且fij为词项i在文档j中出现的次数,词项i在文档j中的TF.IDF得分计算公式如下:
TFij.IDFi=(fij/maxkfkj)log2(N/ni)
TF是词项频率,是指词项在文档中出现次数和文档中所有词项出现的最大次数的比值,那么文档中出现次数最多的词项的TF值是1,文档中其余词项的频率都小于1;IDF是逆文档频率。
1.2 Folksonomy的概念及模型
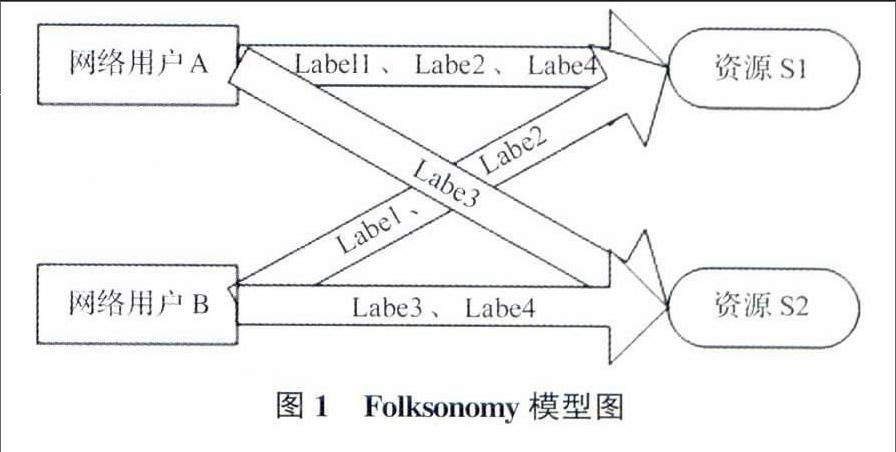
随着WEB2.0的兴起,淡化了信息提供者和信息使用者之间的界限[7],网络用户越来越多的参与到资源的组织和共享中去。用户通过自己的主观认知和对资源的理解程度,对网络共享资源进行标记和整理,使得资源更加具体化并便于检索。从而形成了一种崭新的文献分类方法——自由分类法,即Folksonomy标记语言。
Folksonomy包含资源、标签和用户3个属性,基于Folksonomy的自由分类法是通过鼓励网络用户的兴趣爱好,针对网络资源标记标签的过程。譬如网络用户A和网络用户B,针对共享资源S1和S2,都标记了自己的标签Label1、Labe2、Labe3、Labe4。Folksonomy模型如图1所示。
1.3 RDF的概念与定义
资源描述框架(RDF)是面向语义Web的标准框架,是语义关联数据模型的重要组成部分,语义网的基本特征是面向文本所表示的数据,实现计算机自主阅读和理解的网络化搜索模式。语义网通过使用RDF资源描述框架直接进行深度的资源描述,RDF以标准的XML形式表达,提供一种表述、交换和利用元数据的框架[8]。
RDF的定义如下:
定义2:RDF通常采用三元组(R,D,F)的资源描述框架来描述信息资源或数据对象,其中R是表示资源信息或者数据对象的本身。di∈D={d1,d2,……dm}(i≤m),D是表示资源的m个属性,或者是事物的某些特性。fi∈F={f1,f2,……fm}(i≤m),F表示资源的每个属性相对应的键值等具体内容。
2 多模态危机信息的组织整合模型研究
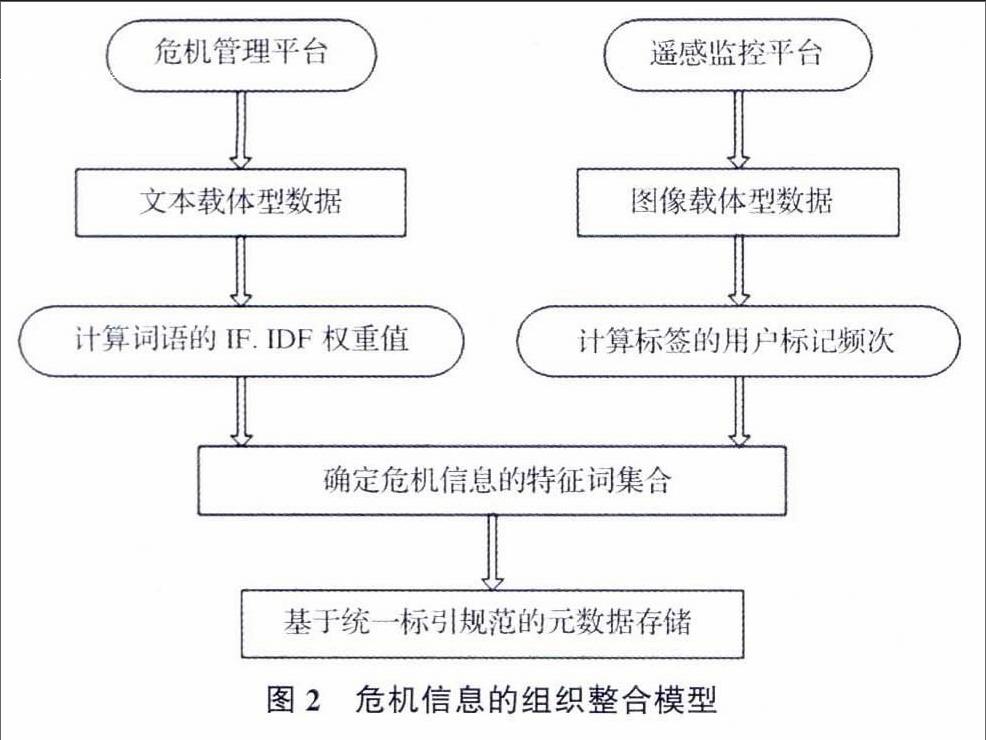
网络泛在环境下,突发事件的危机数据来源复杂多样,因此采集获得的信息具有多元性和不确定性。危机信息的来源包括诸如危机管理平台以及遥感监控平台等途径,危机管理平台记录和收集了大量的文本类型数据集,而遥感监控平台则记录了大量的图像类型数据集。危机数据的组织整理是获得危机情报的基础工作,危机信息的组织整合过程包括数据集合内容特征项集的提取、信息的RDF资源描述存储和文本内容特征域的聚类划分3个阶段。危机信息的组织整合模型如图2所示。
2.1 内容特征项的提取
针对收集整理过程中生成的文本和图像数据载体信息,需要通过使用文本表示语言和网络用户自由标记的途径,把不同模态的危机信息源转化成计算机可以理解和阅读的单一的自然语言信息源,即通过文本数据和图像数据的语义降维模式,把多模态的信息源转化成基于内容特征项的词语集合表示。
2.2 元数据的统一存储
危机信息经过特征项的提取后,通过使用基于语义分析的RDF本体语言来描述危机信息的属性和概念,生成危机信息的资源描述框架,从而进行更深层次的资源信息组织。根据语义网技术RDF三元组的定义,重新进行深度的描述和整理,使非结构化的数据有序化、结构化和整体化,从而为危机信息数据的采集和萃取整合提供数据级的保障基础。
2.3 文本内容特征域的聚类划分
经过信息的整理和特征项集的采集提取之后,形成了以内容特征项集作为标识的词语集合。为了聚类发现已经存储的信息特征项集,通过采用计算词语集合的文本相似度距离来进行聚类计算,把规范化的信息集进行自组织分类,从而为危机信息的预警分析提供相同类型的案例。
3 多模态危机信息的内容特征项提取
公共危机信息采集的数据主要来源有两种:一种来源途径是危机管理平台通过采集网络社交网站的舆论信息而形成的文本数据;另外一种来源途径就是通过城市摄像头等传感设备采集到的图像数据格式。由于文本文档和图像文档都是不属于结构化的数据形态,为了使计算机能够识别和存储采集的危机信息,需要通过使用词语相似度计算和Folksonomy自由标记语言,转换成基于内容特征项的词语集合。
3.1 文本数据的内容特征项提取
文本载体类型的数据信息组织和存储,需要对文本文档的内容进行字词切分处理后,从文字中抽取能代表文档内容特征和彰显文档主题特征的关键词。把获得的关键词作为文档的项特征集合表示,使用文本内容的项特征集来描述相应的文本文档。描述主题的特征词的提取可以通过计算词语在文档中的重要程度来形式化表示,TF.IDF是信息检索中常见的形式化表示模型。
TF.IDF模型是测度词语在文本中重要程度的量化表示。其中TF是通过统计学的知识来衡量词语的重要性,是词语项在本文档中的出现频率,与词语在文档中出现次数成正比。IDF是逆文档频率,是样本集合中文档总数与出现词语项文档数的比值的对数,与词语项在样本集合中出现的次数成反比,TF.IDF模型通过测度TF和IDF的乘积,通过抑制单纯的词语频率度量方法,调整TF权值,可以有效的区分不同文档。
通过计算词语的TF.IDF权重值,选择TF.IDF计算得分最高的m个词语作为文本文档的特征词项,从而把文本载体型数据描述成m个词语项的集合进行信息存储。
文本载体型数据的内容特征项提取算法如下:
输入:N篇文档
输出:N个集合,每个集合包含m个词语
Begin
Step1.使用2-shingling算法进行字词的切分处理
Step2.调用停用词表删除文档中的停用词
Step3.计算词语文档中的TF.IDF权重,选择权重最大的m个词语作为文本的特征词项
Repeat Step1,Step2,Step3
Until所有文档处理完毕;
文本数据的内容特征项提取,即是通过使用词语相似度计算的表示算法,使用特征词语集合来表示文本内容,从而把获取的危机信息文本载体型数据进行结构化的统一表示和存储。
3.2 图像数据的内容特征项提取
图像数据的计算机存储是以图像的像素数组来构成,我们可以计算图像像素的平均数目等简单属性,但是无法给出任何图像特征的内容项。但是自由标记语言使得我们对图像内容的辨认和识别有了可能性,Folksonomy的自由标记语言允许和鼓励用户对网络上导航发布的图像信息数据库进行标记,因此针对图像数据的存储可以通过采用用户自由标记的关键词Tag项作为其内容特征的识别方法,使非结构化的图像载体类文件可以通过结构化的数据表示。
大数据环境下,Folksonomy中海量的用户参与资源信息的标记为我们确定图像的特征词项提供了数据基础,偶尔的错误标记也不会对该图像内容属性造成大的影响。自由标记语言统计图像的用户标签频次,通过可视化技术使资源的标签按照频次多少进行上浮和下沉,然后选择标引频次最高的关键词作为该图像的特征词项,从而完成图像载体形态数据的结构化表示过程。
图像数据的内容特征项提取算法如下:
输入:N个图像
输出:N个集合,每个集合包含m个词语
Begin
Step1.计算图像的所有标记词语的频率次数
Step2.选择频率次数最高的m个词语作为文本文档的特征词项
Repeat Step1,Step2
Until所有图像处理完毕;
根据图像数据表示的处理算法,把获取的危机信息图像格式数据进行文本表示,把图像数据的用户标记进行频次统计,提取对应的关键词项集合。
3.3 特征项集的RDF描述存储
文本文档格式和图像格式的危机信息数据经过提取代表内容特征的词语集合进行表示,萃取后的词语集合不但能够代表相应的数据源特征,而且能够把不同的数据来源进行归一化处理,转换成能够被计算机识别存储的结构化数据。
基于语义网关联数据挖掘算法的出现让突发事件应对相关的危机全数据采集成为可能。语义网是新一代的互联网核心,语义关联数据模型是指基于语义关联的数据表达和结构组织模型,该模型不但包含资源信息,同时也包含信息之间异构的语义结构。从而进行更深层次的资源信息组织,为危机数据的聚类计算提供基础条件。
危机信息中的资源描述框架中,R是危机信息来源,D是危机信息的内容特征属性,F是能够表示该危机内容特征的属性值,即特征项的集合。使用RDF三元组来表示和描述归一化处理后的危机数据,可以更深层次的揭示危机信息的内容特征属性,同时是非结构化的危机数据有序化。危机信息的元数据的RDF/XML表述如下:
〈?xml version=″1.0″?〉
〈rdf:RDF
xmlns:rdf=http:∥www.w3.org/1999/02/22-rdf-syntax-ns#
xmlns:dc=″WB000002″〉
〈rdf:Description〉
〈dc:feature〉
〈rdf:Bag〉
〈rdf:li〉关键词1〈/rdf:li〉
〈rdf:li〉关键词2〈/rdf:li〉
〈rdf:li〉关键词3〈/rdf:li〉
〈/rdf:Bag〉
〈/dc:feature〉
〈/rdf:Description〉
〈/rdf:RDF〉
危机信息的特征词项集合通过上述的RDF语义关联结构来描述和存储,把非结构化的多种数据存在形式转换成统一的、计算机可以识别的语义结构表示,为危机信息的聚类分析和情报预警提供数据级的基础保障。
4 基于Map-Reduce的危机信息聚类研究
公共危机信息经过采集后,形成了以内容项为特征的词语集合,因此可以通过采用计算不同词语集合之间的相似度距离来进行聚类计算,把采集的公共危机进行自组织分类,自动聚类已经存储的危机信息特征项集合,发现该危机的类型并建立危机模型,从而在危机预警期间为危机的管理决策部门提供相同类型的分析案例和预警方案,提高突发危机事件的应急处理能力。
本文词语集合之间的组织分类采用距离计算中的Jaccard距离度量。给定词语集合A和词语集合B,那么词语集合A和词语集合B的距离计算公式如下:
Jaccard(A,B)=1-SIM(A,B)(1)
SIM(A,B)=A∩B/A∪B(2)
假定词语集合A={关键词1;关键词2;关键词3;关键词4}和词语集合B={关键词1;关键词2;关键词3;关键词5},因此集合A和集合B的并集共有5个关键词语,集合A和集合B的交集是3个相同关键词,由公式(1)、(2)可知,词语集合A和词语集合B的距离Jaccard(A,B)=1-3/5=0.4,假定给定的距离阈值是0.5,距离阈值可以根据分类的实际效果进行设定。由于Jaccard(A,B)<0.5,因此词语集合A和词语集合B是相似度高的词语集合,即词语集合A和词语集合B所表示的危机信息被认定是属于同一类型的危机。如果两个词语集合的Jaccard距离大于给定的距离阈值,就表明这个词语集合相似度比较低,那么这两个词语集合所表示的危机信息则不会被计算机认定为同一类型。通过计算危机信息的词语集合Jaccard距离,可以很容易的把危机信息进行类别划分,从而在危机预警过程中匹配同类型的预警案例。
在网络泛在环境下,通过各种渠道获得的危机信息是单个人和单台机器无法计算和处理的。面对海量的数据,分布式的高效存储系统具有高度的容错性和并发性,是处理海量数据的基础条件,同时分布式的高效处理系统就更加显得非常重要。Map-Reduce是非常强大的分布式计算方法,通过使用Map-Reduce计算模式的投影算法能满足非关系型危机数据的分布处理需要,支撑起组分异质型数据的融合处理,从而满足海量数据的同步计算和分布处理,保障大数据环境下海量危机信息数据的分类组织,为危机的预警管理提供情报支持。
5 结束语
针对危机信息中常见的两种存在形式,本文通过使用词语相似度计算和Folksonomy自由标记语言,把不同模态的危机信息源转化成单一的基于内容特征项的词语集合。然后通过使用基于语义分析的RDF本体语言来描述危机信息的属性和概念,生成危机信息的资源描述框架,聚类划分文本内容特征域集,把规范化的信息资源进行自组织分类,从而进行更深层次的资源信息组织和整合,为危机信息的预警分析提供相同类型的案例。但是还要加强其他信息情报机构的参与和纵向合作[9],为危机管理中的决策部门提供精准的危机情报,从而积极发挥情报效用,为突发事件的应急管理进行案例分析和情报预警。
参考文献
[1]郑红玲.突发事件应急管理面临的挑战及对策[J].领导科学,2010,29:55-56.
[2]毕玉青.基于大数据视野下的地方政府公共危机管理研究[J].现代经济信息,2016,(2):141,143.
[3]熊枫.基于大数据时代的政府危机信息管理研究[J].兰州学刊,2015,(5):193-197.
[4]李阳,李纲.工程化与平行化的融合:大数据时代下的应急决策情报服务构思[J].图书情报知识,2016,(3):4-14.
[5]吴春玉.政府决策信息采集模型研究[J].情报科学,2006,(3):373-376.
[6]覃世安,李法运.文本分类中TF-IDF方法的改进研究[J].现代图书情报技术,2013,(10):27-30.
[7]余本功,顾佳伟.基于Folksonomy和RDF的信息组织与表示[J].现代图书情报技术,2014,(11):24-30.
[8]马张华.信息组织(第3版)[M].北京:清华大学出版社,2008:53-77.
[9]宋丹,高峰.美国自然灾害应急管理情报服务案例分析及其启示[J].图书情报工作,2012,20:79-84.
(责任编辑:孙国雷)
