
流形与成对约束联合正则化半监督分类方法*
2017-02-20 10:49钱鹏江顾晓清蒋亦樟
计算机与生活 2017年2期
奚 臣,钱鹏江,顾晓清,蒋亦樟
江南大学 数字媒体学院,江苏 无锡 214122
流形与成对约束联合正则化半监督分类方法*
奚 臣+,钱鹏江,顾晓清,蒋亦樟
江南大学 数字媒体学院,江苏 无锡 214122
半监督学习方法主要通过学习少量标记样本和大量未标记样本知识来提高学习效果,然而目前许多半监督方法注重在未标记样本的利用上深耕,忽略了对标记样本等监督信息的继续研究。鉴于此,结合流形正则化框架提出了一种流形与成对约束联合正则化半监督分类方法(semi-supervised classification method based on joint regularization of manifold and pairwise constraints,SSC-JRMPC)。SSC-JRMPC从两个方面进行研究:一方面该方法继承了流形正则化框架中的特点,将经验风险和结构风险最小化,以及对整个数据的内在数据分布进行运用;另一方面,通过将样本标签转化为成对约束的形式,并把这些扩展的知识并入到目标公式中来进一步探索监督信息包含的知识,一定程度上提高了SSC-JRMPC算法的分类准确性。通过在真实数据集上的实验,验证了上述优点。
半监督学习;分类;流形正则化;成对约束
1 引言
半监督学习是一种结合有监督学习和无监督学习的方法,其学习的基本假定是样本数据和要划分的类别已知,并且具有一定数量的类别已知的样本和大量类别未知的样本。半监督分类利用大量未标记数据扩大分类算法的训练集,主要从有监督学习的角度出发,当已标记训练样本不足时,研究如何自动地利用大量未标记样本信息辅助分类器的训练。
普遍来说,学者在研究时通常都是通过两个方面来提高半监督分类器的性能:一是利用高效手段学习这些少量的标记样本等监督信息,这通常都是借鉴监督学习的手段来实现的;二是利用有效学习方法来挖掘未标记样本中所蕴含的大量可用信息,流形学习方法就是一种有效的手段,它利用一些分布上的假设或者样本之间的内在联系,将未标记样本转化为标记样本,然后合并到标记的数据中,扩大可用的训练数据集,从而使分类器的性能更优异。同时,在半监督学习中,数据标签(class labels)[1-9]作为最为常见且直接的先验知识类型而被普遍利用;成对约束(pairwiseconstraints)[10-12]又称必须关联(must-link)和不可能关联(cannot-link)约束,属于另一种监督信息类型,相对而言具有更大的灵活性和实用性。实际情况下有可能只给出了成对约束而没有数据标签,成对约束可以是事先给定的,也可以是由数据标签转化而来的。
支持向量机(support vector machine,SVM)是Vapnik在统计学习理论[13]基础上发展起来的针对小样本的机器学习方法。该方法由于具有较强的泛化能力,方便对高维数据操作而得到了日益广泛的研究和应用。学者也基于SVM研究衍生出一些半监督支持向量机算法[4,14-18],比较典型的有半监督支持向量机(semi-supervised SVM,S3VM)[4],它基于聚类假设,试图通过探索未标记数据来规范、调整决策边界;直推式支持向量机(tranductive SVM,TSVM)[2],它只考虑一个特定的测试数据集,试图最小化这个测试集上的错分率,而不考虑一般的情况,更强调直推式的概念;拉普拉斯支持向量机(Laplacian SVM)[15],它将流行学习的方法引入到支持向量机中,有效利用了未标记样本包含的知识等。
为了拓展关于半监督支持向量机方法的研究,本文提出了一种流形与成对约束联合正则化半监督分类方法(semi-supervised classification method based on joint regularization of manifold and pairwise constraints,SSC-JRMPC),在流形正则化(manifold regularization,MR)[15]框架的基础上引入了一项能够有效利用监督信息的约束项,该约束项能够让人们在原有基础上将数据标签转化为成对约束,从而可以进一步地利用已知的监督信息;同时流形正则化框架中的流形正则化项能够保持样本间局部几何结构的特点,保留了流形学习方法在利用未标记样本上的优势。
2 相关工作
2.1 流形正则化框架
文献[15]提出的流形正则化框架,将流形学习方法以及谱图理论的知识引入到传统的正则化方法中,主要是通过图的拉普拉斯矩阵来探索数据的流形结构。假设有l个分属于两个不同的类(+1、-1)的标记样本和u个未标记样本组成的样本集(前l个数据样本为标记样本)Xl+u={xi}(i=1,2,…,l,l+1,…,l+u),它把标记的和未标记的数据编码在一张邻接图中,图的每一个节点代表一个数据点,如果两个数据点之间有很大的相似性,就用一条边将它们对应的节点连接起来。然后为未标记的数据找到合适的类别以使它们与标记的数据和潜在的图结构的不一致性最小化。流形正则化单元为:
其中,边权Wij表示样本点之间的相似性;l、u分别为标记样本数和未标记样本数;;拉普拉斯图L=D-W;D为权重矩阵W的对角度矩阵,。反映的是样本分布的内在流形结构[14]。
将流形正则化单元引入到传统的正则化方法,并结合再生核Hilbert空间(reproducing kernel Hilbert space,RKHS)[19]相关性质,就可以构造出流形正则化框架:

其中,V(xi,yi,f(xi))为损失函数,V(xi,yi,f(xi))=;y是样本标签,y∈{+1,-1};正ii则单元用于控制分类器的复杂性,避免出现过拟合现象;是流形正则化项,用来保持样本分布的内在流形结构。f(x)是决策函数,;γA、γI为两个正则项的参数。
若损失函数V(xi,yi,f(xi))为支持向量机的合页损失函数(hinge loss function),再结合再生核Hilbert的相关知识,可以得到由流形正则化框架衍生出的半监督支持向量机Laplacian SVM[15]的原始优化问题:
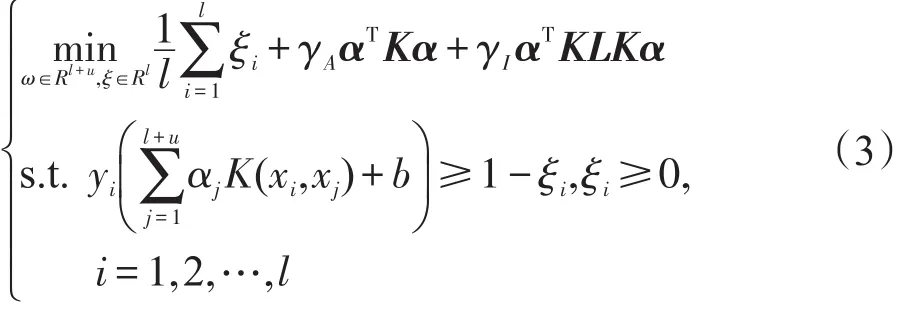
其中,l、u分别代表训练样本中标记样本数和未标记样本数;K(,)表示Mercer核函数;K是核矩阵,K=(Kij)l+u,l+u,Kij=K(xi,xj);L是拉普拉斯图矩阵。
根据Representer Theorems[19],可以得到决策函数的相应形式:

2.2 成对约束监督信息的利用
一般而言,半监督学习中大多给定了部分数据标签,一般做法是引入经验风险项来加以利用,但不能忽略的是数据标签可以转换为成对约束这一信息类型。鉴于此,半监督算法中对监督信息的利用能够通过将数据标签转换为成对约束来进一步利用监督信息。对于如何利用成对约束,一般的做法是将其构造成一个正则项,引入到原始优化问题中,具体的根据是在原始优化问题中当两个有标记样本xi、xj属于同类时,可以判定W_mij=1,样本对应的分类决策函数值f(xi)、f(xj)肯定是同号的,则这里(f(xi)-f(xj))的值就很小,优化问题中(f(xi)-f(xj))2W_mij就小;当样本xi、xj属于异类时,可以判定W_cij,样本对应的分类决策函数值f(xi)、f(xj)肯定是异号的,即一正一负,f(xi)⋅f(xj)的值就小,优化问题中f(xi)f(xj)W_cij就小。必须关联约束矩阵和不可能关联矩阵的定义如下。
必须关联约束矩阵W_m具体定义为:

式(5)中Lm为样本中属于同一类的组合数,i,j=1, 2,…,l,l+1,…,l+u;这里的其他情况包括样本xi和xj中某一个标签未知。
不可能关联约束矩阵W_c具体定义为:
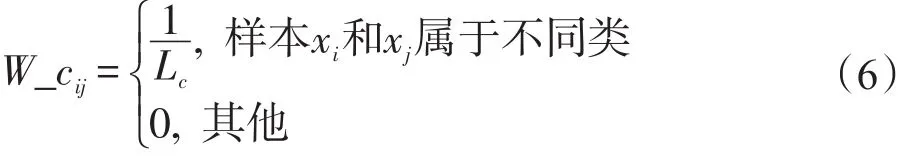
式
(6)中Lc为样本中不属于同一类的组合数个数;i,j=1,2,…,l,l+1,…,l+u;这里的其他情况包括样本xi和xj中某一个标签未知。
对于必须关联约束的使用:
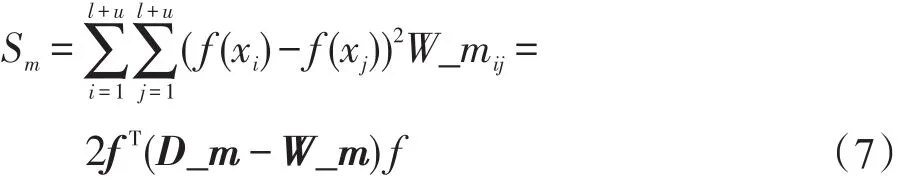
式(7)中f(x)是分类决策函数;W_m为必须关联约束矩阵,为(l+u)阶方阵;D_m为必须关联约束矩阵W_m的对角矩阵,。
对于不可能关联约束的使用:
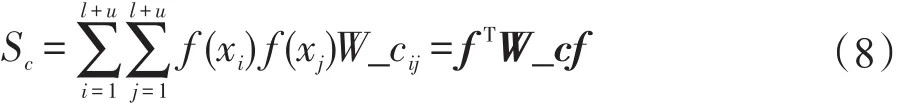
式(8)中f(x)是分类决策函数;W_c为不可能关联矩阵,为l+u阶方阵。需要说明的是虽然这里的关联约束矩阵W_m和W_c都是l+u阶方阵,但是这里得到的约束信息其实都是从一开始给定的有标记样本中得到的,而必须关联约束和不可能关联约束信息除了可以从有标记样本中得到,也有可能是包括那些虽然不知道样本标签,但知道哪些样本属同类,哪些属异类。因此,保留矩阵大小为l+u阶,而不是l阶。
那么结合对两种关联约束的利用,可以得到对成对约束的利用,表示为:这里可以根据式(9)定义出监督约束矩阵Sw以及监督利用正则项S:
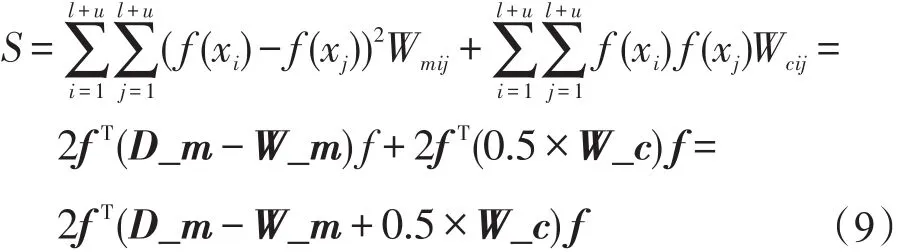
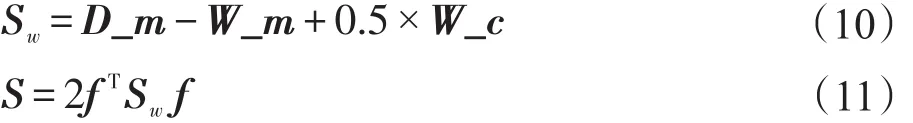
3 流形与成对约束联合正则化半监督分类方法
前面介绍了拉普拉斯支持向量机的流形正则化框架、半监督学习中监督信息的类型及其利用,而本文的流形与成对约束联合正则化半监督分类方法,从高效利用标记样本等监督信息和有效学习未标记样本知识两个方面出发,提高分类器性能。假设有l个分属于两个不同的类(+1,-1)的标记样本和u个未标记样本组成的样本集Xl+u={xi}(i=1,2,…,l,l+1,…,l+u),这l个标记样本中属于同一类的组合数共Lm个,属于不同类的组合数共Lc个。
把监督约束利用正则项S引入到流形正则化框架中,就可以得到SSC-JRMPC算法的目标函数:
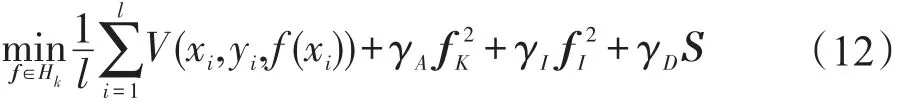
其中,V(xi,yi,f(xi))为标记样本的损失函数,这里的损失函数选择了与SVM相同的损失函数,即合页损失函数,V(xi,yi,f(xi))=max{0,1-yif(xi)}=ξi,yi是样本标记,yi∈{+1,-1},ξi为松弛变量,表示训练样本集中标记样本对应的ξi不为0,其余未标记训练样本点的ξ都等于0。f(x)是决策函数;正则单元用于控制分类器的复杂性,避免出现过拟合现象;是流形正则化项,用来保持样本分布的内在流形结构;S是用来利用成对约束这种监督知识的正则项。γA、γI、γD作为3个正则项的参数,控制着各自对应正则项的复杂性。值得注意的是,当γD→0时,目标函数就退化为Laplacian SVM算法。
当样本内在几何结构呈现出非线性流形时,就要借助再生核希尔伯特空间的相关知识,利用核技巧把输入空间(Rn)的数据映射到特征空间H(希尔伯特空间),再在特征空间里用线性分类学习方法从训练数据中学习分类模型。
假设存在这样的映射函数φ(x):Rn→H,对所有的x,z∈Rn,Mercer核函数K(x,z)=φ(x)⋅φ(z)。根据对传统SVM的了解,这里的分类决策面的法向量ω实际上是和所有训练样本(标记样本和未标记样本)都有关的,根据Representer Theorems[19],可以将特征空间中的决策超平面法向量表示为:



4 实验与结果分析
为了验证本文SSC-JRMPC算法的有效性,将SSC-JRMPC算法分别在UCI数据集、文本分类数据集上进行测试,并与相应的方法进行比较。
4.1 实验设置及运行环境
为了体现SSC-JRMPC算法的优势,本文用了5种算法和SSC-JRMPC算法作比较,其中包括基础的SVM算法和4个半监督方法,具体为TSVM、Laplacian SVM、meanS3VM-iter[15]、meanS3VM-mkl[15]。在实验中有关参数选择上,这里采用交叉验证的方法,具体设置为当标记样本点个数低于20个时,用留一法验证;其他情况下用5折交叉验证。对于对比算法meanS3VM-iter和meanS3VM-mkl,仍采用其原文献推荐的参数区间设置;对于SVM算法,参数C寻优区间在{0.001,0.01,0.1,1,10,100,1 000}之间;本文SSCJRMPC算法和Laplacian SVM算法中的参数γA、γI、γD和近邻点个数的寻优区间分别位于{10-5,10-4, 10-3,10-2,10-1,101,102}、{10-5,10-4,10-3,10-2,10-1,101,102}、[0:0.1:1]和{3,5,7,9}。所有算法均采用高斯径向基核函数,核宽度参数σ2的取值为样本数据的平均距离。同时,所有实验仅提供了数据标签这一种类型的监督信息。本文实验均采用以下的硬件配置与编程环境:Windows 7系统,CPU是i5-4590,编程环境是Matlab 2013。
4.2 真实数据实验及结果分析
4.2.1 UCI数据实验及结果分析
为了更全面地说明本文SSC-JRMPC算法作为一种半监督分类方法具有的分类性能,UCI数据集具体参数如表1。同时,每个数据集的实验中,都事先将源数据分割成一个训练集和测试集,再在训练集中取2%、4%、6%、8%、10%的点作为有标记样本,余下作为未标记样本参与半监督方法的训练,这样重复10次,取10次结果的均方差来进行统计。6种算法的实验对比结果如图1和表2所示。
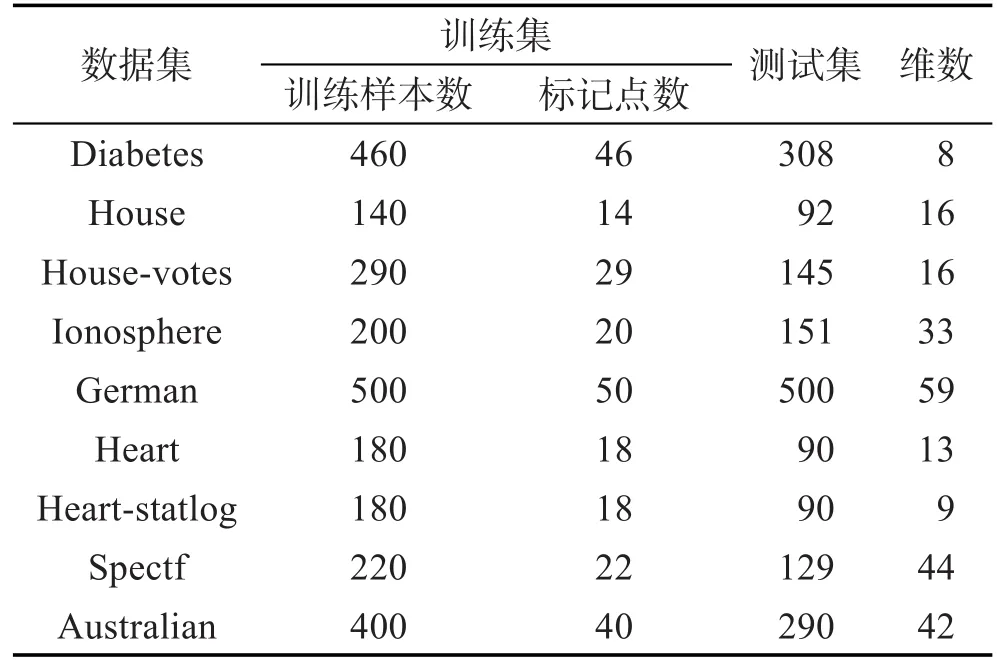
Table 1 UCI data parameters表1 UCI数据参数
观察图1和表2,可以得知如下结论:
首先,从图1中可以看出,在标记样本过少(2%、4%)的情况下,本文算法体现不了多大优势。这主要因为SSC-JRMPC算法一部分是将标记样本标签转化成关联约束信息来利用,如果标记点过少,关联约束信息的利用对算法影响甚微;只有当标记点足够多时,关联约束信息的利用才会对算法主体带来较好效果。但无论如何,可以明显地看出,本文SSCJRMPC算法都比Laplacian SVM算法要好,这也证明了本文算法结合充分利用标记样本知识和有效学习未标记样本知识这两个方面的正确性和有效性。
其次,本文SSC-JRMPC算法比实验中其他对比算法性能要好,归根到底,可以理解为其他算法未能充分利用标记样本知识和有效学习未标记样本知识这两个方面。SVM算法作为监督学习方法,只利用了标记样本知识;Laplacian SVM虽然结合了两个方面,但是并未充分完全利用到标记样本知识,它主要依靠流形学习方法学习未标记样本知识来达到训练的目的;TSVM通过不断迭代来达到最优,其实也只是依靠其中的标记样本知识;meanS3VM方法中的两个算法虽然结合了充分利用标记样本知识和有效学习未标记样本知识这两个方面的知识,但是可以发现其利用标记样本知识的策略和Laplacian SVM算法中一样,并未充分完全地利用到标记样本知识。
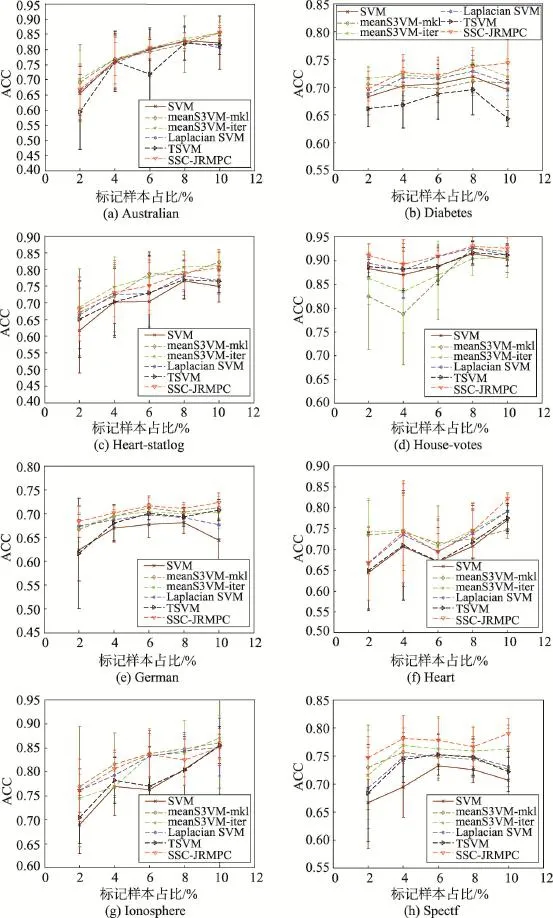
Fig.1 Classification performance comparison of 6 algorithms on different datasets图1 不同数据集上6种算法分类性能比较
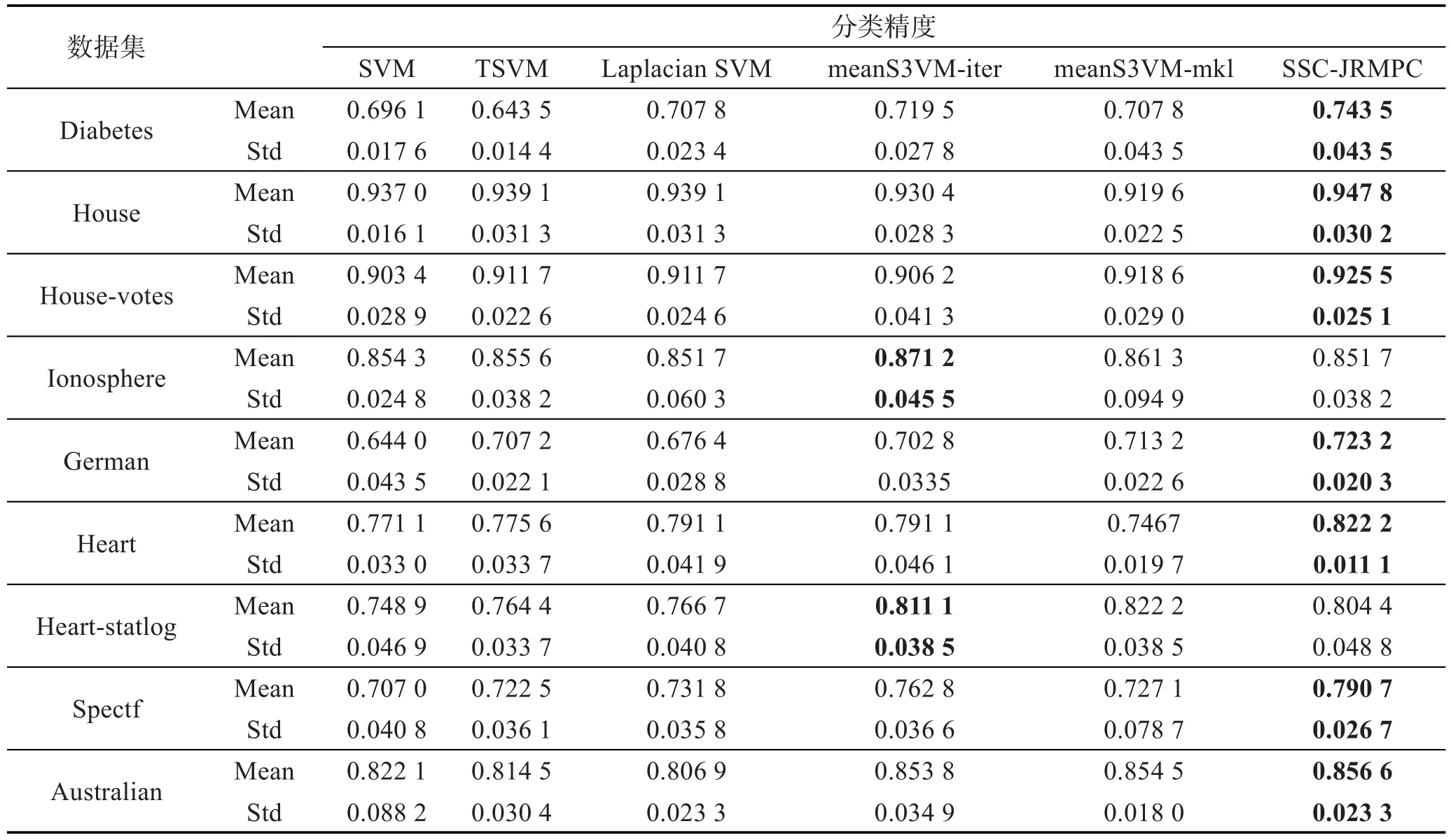
Table 2 Classification results of 6 algorithms on 10 percent labeled dataset表2 10%标记样本点上6种算法分类结果
同时,在Heart-statlog和Ionosphere数据集中,虽然本文SSC-JRMPC算法效果稍次于meanS3VM-iter,但其算法效果依然不弱于其他算法。其原因可以归结于,这里meanS3VM方法根据标记样本的类别均值去估算未标记样本均值,从而学习未标记样本知识的作用要比流形学习的作用大;而且对标记样本的利用已经很好,这点可以从SVM算法效果对比可以看出,因为它们利用标记样本知识的策略相同,所以造成了meanS3VM方法分类效果稍好于本文算法。
4.2.2 文本分类实验及结果分析
20个新闻组(20Newsgroups,20NG)[20]收集大约20 000篇新闻组文档,涵盖行政、体育等20个不同领域的新闻事件。20NG可分为4个大类,每个大类包含多个子类。特征上20NG很好地反映了不同文本数据集所具有的特征。这里对20NG中的4个大类两两组合来进行实验,每个大类选择500个样本,并选取2个子类,具体数据构成见表3。实验设置与UCI数据实验相同。原始20NG数据维数很高,用BOW工具箱[21]对其进行了降维处理。实验结果见表4。
观察表4,可以得知如下结论:
本文SSC-JRMPC算法在TSVM算法处理文本分类问题稍显优势的情况下,依然表现出很好的效果,就算在“Comp VS talk”、“sci VS talk”实验中,本文算法和TSVM表现的效果差距不大。原因可以总结为,TSVM方法最初就是针对文本分类问题提出来的,因此其在处理文本分类问题时优势较明显,但本文算法同时结合充分利用标记样本知识和有效学习未标记样本知识这两个方面的知识,分类效果表现同样很好,再次证明了本文SSC-JRMPC算法的正确性和有效性。
同时,可以看出SSC-JRMPC算法始终优于Laplacian SVM算法,原因可以归结于SSC-JRMPC算法比Laplacian SVM算法能更为有效地利用标记样本知识,通过参数调节其比重,保证了本文算法始终好于Laplacian SVM算法。
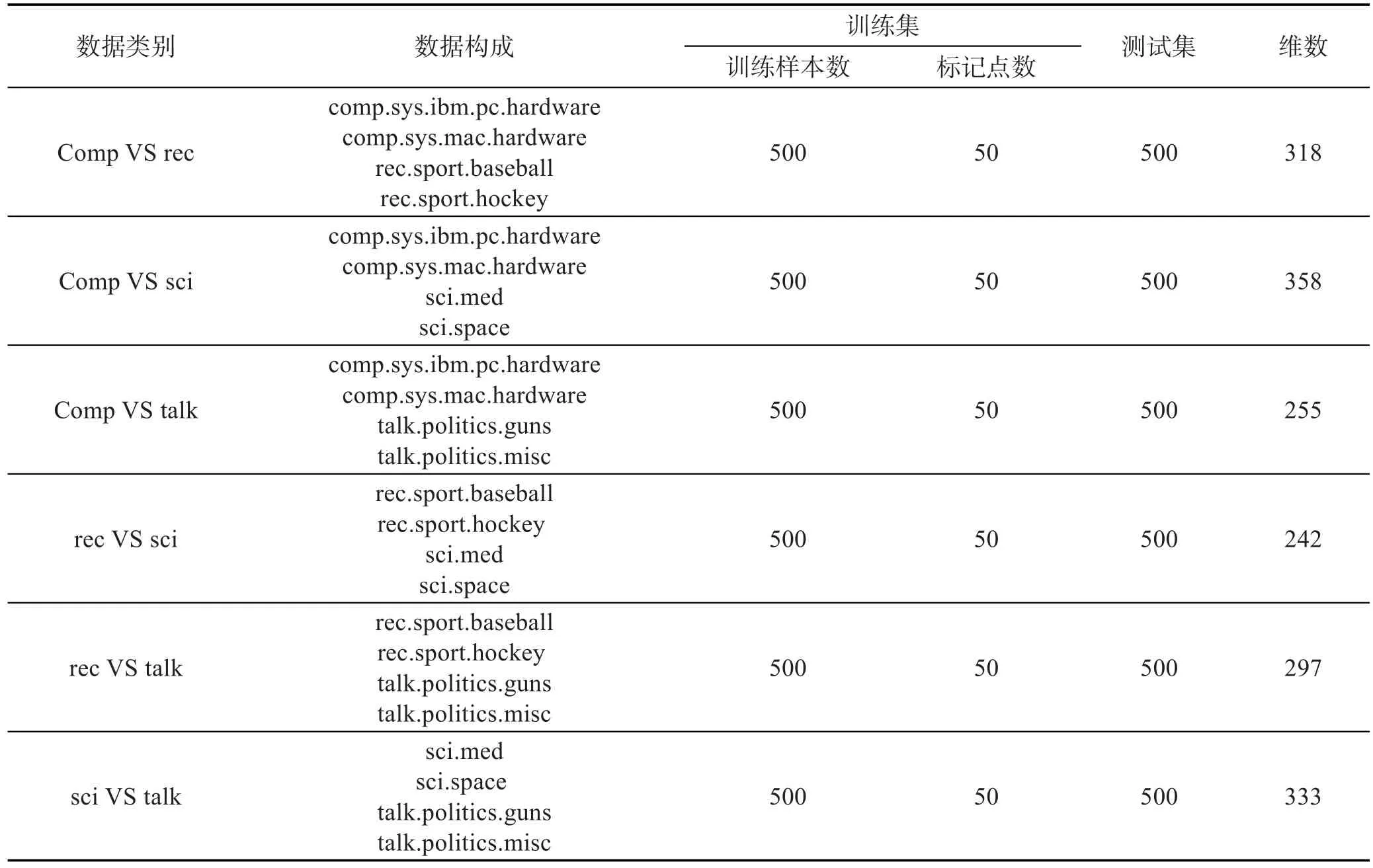
Table 3 Structure of text datasets表3 文本数据构成
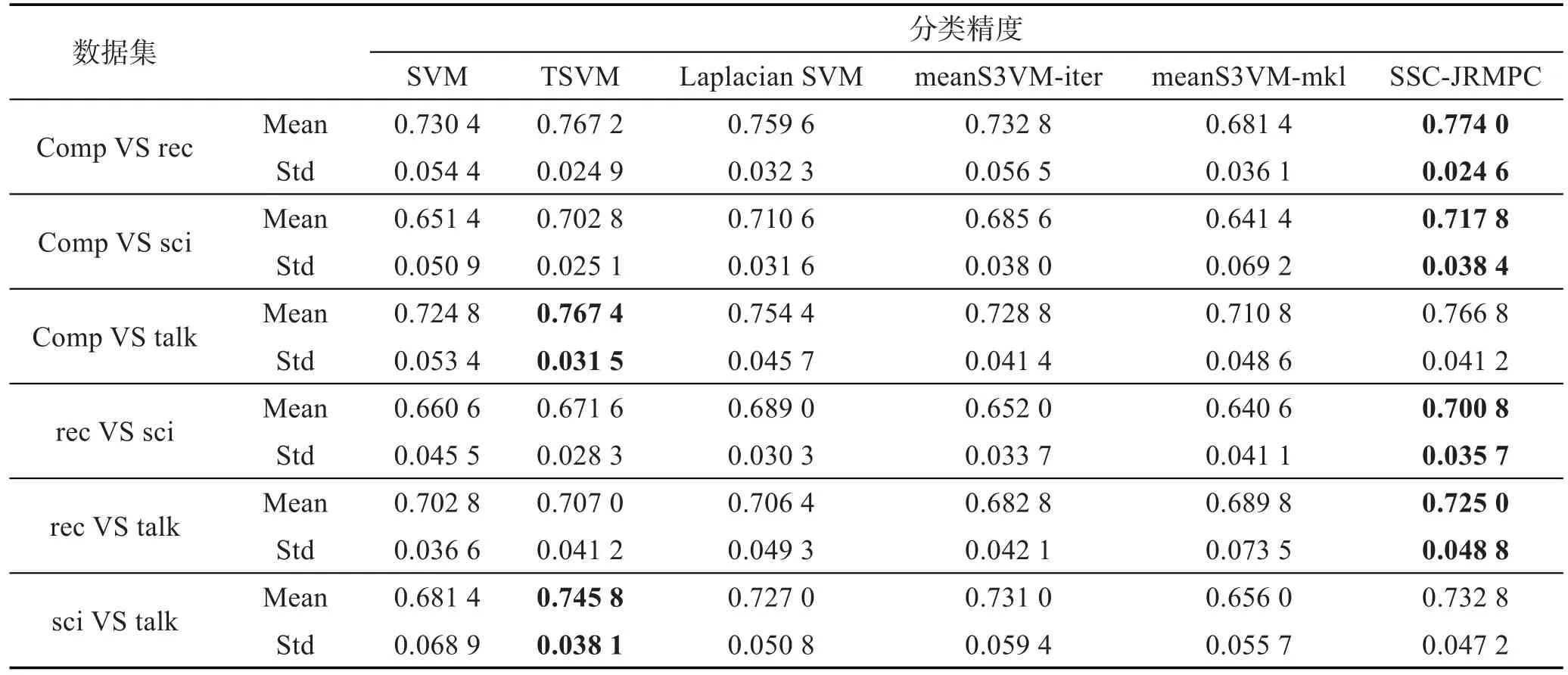
Table 4 Experimental results of text classification表4 文本分类实验结果
5 结束语
本文归纳了半监督学习方法的一般特点,从充分利用标记样本等监督信息知识和有效学习未标记样本知识这两个方面考虑来提高分类器性能,结合了流形框架的知识,提出了流形与成对约束联合正则化半监督分类方法(SSC-JRMPC)。本文方法不但利用了流形学习方法有效利用未标记样本的优势,同时也考虑了如何进一步利用监督信息包含的知识。这些保证了SSC-JRMPC算法在对监督信息的利用上更具有一般适用性和有效性。由于监督信息约束正则项的引入,也会一定程度上提高算法的时间、空间复杂度,并且本文算法针对大型数据不具备快速学习能力,如何克服算法上述不足将是以后研究的方向。
[1]Gan Haitao.Research on semi-supervised clustering and classification algorithm[D].Wuhan:Huazhong University of Science and Technology,2014.
[2]Nigam K,McCallum A K,Thrun S,et al.Text classification from labeled and unlabeled documents using EM[J].Machine Learning,2000,39(2/3):103-134.
[3]Rosenberg C,Hebert M,Schneiderman H.Semi-supervised self-training of object detection models[C]//Proceedings of the 7th IEEE Workshop on Applications of Computer Vision, Breckenridge,USA,Jan 2005.Washington:IEEE Computer Society,2005:29-36.
[4]Bennett K,Demiriz A.Semi-supervised support vector machines[C]//Advances in Neural Information Processing Systems 11:NIPS Conference,Denver,Colorado,USA,Nov 30-Dec 5,1998.Cambridge,USA:MIT Press,1999:368-374.
[5]Fung G,Mangasarian O L.Semi-supervised support vector machines for unlabeled data classification[J].Optimization Methods and Software,2001,15:29-44.
[6]Chaudhari N S,Tiwari A,Thomas J.Performance evaluation of SVM based semi-supervised classification algorithm [C]//Proceedings of the 10th International Conference on Control,Automation,Robotics and Vision,Hanoi,Vietnam, Dec 2008.Piscataway,USA:IEEE,2008:1942-1947.
[7]Tang F,Brennan S,Zhao Q,et al.Co-tracking using semisupervised support vector machines[C]//Proceedings of the 11th IEEE International Conference on Computer Vision, Rio de Janeiro,Brazil,Oct 2007.Piscataway,USA:IEEE, 2007:1-8.
[8]Guillaumin M,Verbeek J,Schmid C.Multimodal semi-supervised learning for image classification[C]//Proceedings of the 23rd IEEE Conference on Computer Vision and Pattern Recognition,San Francisco,USA,2010.Piscataway,USA: IEEE,2010:902-909.
[9]Gao Jun,Wang Shitong,Deng Zhaohong.Global and local preserving based semi-supervised support vector machine[J]. Acta Electronica Sinica,2010,38(7):1626-1633.
[10]De Melo F M,De Carvalho F D A T.Semi-supervised fuzzy C-medoids clustering algorithm with multiple prototype representation[C]//Proceedings of the 2013 IEEE International Conference on Fuzzy Systems,Hyderabad,India, Jul 7-10,2013.Piscataway,USA:IEEE,2013:1-7.
[11]Zhao Jinguo,Chen Min,Zhang Zhao,et al.Localized pairwise constraint proximal support vector machine[C]//Proceedings of the 9th IEEE International Conference on Cognitive Informatics,Beijing,Jul 7-9,2010.Piscataway,USA: IEEE,2010:908-913.
[12]Zhang Zhao,Ye Ning.Constraint projections for discriminative support vector machines[C]//Proceedings of the 2009 International Joint Conference on Bioinformatics,Systems Biology and Intelligent Computing,Shanghai,Aug 3-5,2009. Washington:IEEE Computer Society,2009:501-507.
[13]Vapnik V N.Statistical learning theory[M].New York:Wiley Press,1998.
[14]Li Yufeng,Kwok J T,Zhou Zhihua.Semi-supervised learning using label mean[C]//Proceedings of the 26th Annual International Conference on Machine Learning,Montreal,Canada,2009.New York:ACM,2009:633-640.
[15]Belkin M,Niyogi P,Sindhwani V.Manifold regularization: a geometric framework for learning from examples[J].Journal of Machine Learning Research,2006,7:2399-2434.
[16]Zhao Ying.Research on semi-supervised support vector machines algorithms[D].Harbin:Harbin Engineering University, 2010.
[17]Li Yufeng,Kwok J T,Zhou Zhihua.Cost-sensitive semisupervised support vector machine[C]//Proceedings of the 24th AAAI Conference on Artificial Intelligence,Atlanta, USA,Jul 11-15,2010.Menlo Park,USA:AAAI,2010:500. [18]Li Yufeng,Tsang I,Kwok J T,et al.Convex and scalable weakly labeled SVMs[J].Journal of Machine Learning Research,2013,14:2151-2188.
[19]Schölkopf B,Herbrich R,Smola A J.A generalized repre-senter theorem[M]//Computational Learning Theory.Berlin,Heidelberg:Springer,2001:416-426.
[20]Dai Wenyuan,Xue Guirong,Yang Qiang,et al.Co-clustering based classification for out-of-domain documents[C]//Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,San Jose, USA,Aug 12-15,2007.New York:ACM,2007:210-219.
[21]McCallum A K.BOW:a toolkit for statistical language modeling,text retrieval,classification and clustering[EB/OL]. (1996)[2015-08-18].http://www.cs.cmu.edu/mccallum/bow.
附中文参考文献:
[1]甘海涛.半监督聚类与分类算法研究[D].武汉:华中科技大学,2014.
[9]皋军,王士同,邓赵红.基于全局和局部保持的半监督支持向量机[J].电子学报,2010,38(7):1626-1633.
[16]赵莹.半监督支持向量机学习算法研究[D].哈尔滨:哈尔滨工程大学,2010.

XI Chen was born in 1993.He is an M.S.candidate at School of Digital Media,Jiangnan University.His research interests include pattern recognition,intelligent computation and its applications,etc.
奚臣(1993—),江南大学数字媒体学院硕士研究生,主要研究领域为模式识别,智能计算及应用等。

QIAN Pengjiang was born in 1979.He received the Ph.D.degree from Jiangnan University.Now he is an associate professor and M.S.supervisor at School of Digital Media,Jiangnan University.His research interests include pattern recognition and their applications,bioinformatics and medical image processing,etc.
钱鹏江(1979—),博士,江南大学数字媒体学院副教授、硕士生导师,主要研究领域为模式识别及应用,生物信息,医学图像处理等。

GU Xiaoqing was born in 1981.She is a Ph.D.candidate at School of Digital Media,Jiangnan University.Her research interests include pattern recognition,intelligent computation and its applications,etc.
顾晓清(1981—),女,江南大学数字媒体学院博士研究生,主要研究领域为模式识别,智能计算及应用等。

JIANG Yizhang was born in 1988.He is a Ph.D.candidate at School of Digital Media,Jiangnan University.His research interests include pattern recognition,intelligent computation and its applications,etc.
蒋亦樟(1988—),男,江南大学数字媒体学院博士研究生,主要研究领域为模式识别,智能计算及应用等。
Semi-Supervised Classification Method Based on Joint Regularization of Manifold and Pairwise Constraints*
XI Chen+,QIAN Pengjiang,GU Xiaoqing,JIANG Yizhang
School of Digital Media,Jiangnan University,Wuxi,Jiangsu 214122,China
+Corresponding author:E-mail:xichen_0305@163.com
In order to improve the learning performance,semi-supervised learning methods aim at exploiting the knowledge of a small amount of labeled examples as well as lots of unlabeled data instances simultaneously.However, most existing semi-supervised approaches,primarily focus on the effective utilization of those label-unknown data, and the successive study regarding the label-known examples is usually neglected.In light of such situation,in terms of the manifold regularization framework,this paper proposes a novel semi-supervised classification method based on joint regularization of manifold and pairwise constraints(SSC-JRMPC).This method proceeds from two aspects:on one hand,inheriting from the manifold regularization framework,the optimization regarding both empirical risk and structural risk,and the use of intrinsic data distribution of entire dataset are considered concurrently;on the other hand, by transforming the sample labels into the must-link/cannot-link pairwise constraint conditions and incorporating these extended knowledge into own objective formulation,the knowledge existing in the supervision information is further mined.As the results,the classification accuracy of SSC-JRMPC is distinctly enhanced.The experiments on real-world datasets confirm the merits of this paper work.
semi-supervised learning;classification;manifold regularization;pairwise constraints
10.3778/j.issn.1673-9418.1510018
A
TP181
*The National Natural Science Foundation of China under Grant No.61202311(国家自然科学基金);the Natural Science Foundation of Jiangsu Province under Grant No.BK201221834(江苏省自然科学基金);the R&D Frontier Program of Jiangsu Province under Grant No.BY2013015-02(江苏省产学研前瞻性研究项目).
Received 2015-10,Accepted 2016-02.
CNKI网络优先出版:2016-02-03,http://www.cnki.net/kcms/detail/11.5602.TP.20160203.1126.004.html
XI Chen,QIAN Pengjiang,GU Xiaoqing,et al.Semi-supervised classification method based on joint regularization of manifold and pairwise constraints.Journal of Frontiers of Computer Science and Technology,2017, 11(2):303-313.
猜你喜欢
吉林大学学报(理学版)(2022年2期)2022-05-30
兰州理工大学学报(2021年3期)2021-07-05
兰州理工大学学报(2021年3期)2021-07-05
南京大学学报(数学半年刊)(2020年1期)2020-03-19
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
科技风(2018年1期)2018-05-14
上海师范大学学报·自然科学版(2018年3期)2018-05-14
小学阅读指南·低年级版(2017年1期)2017-03-13
人生十六七(2015年6期)2015-02-28
计算机辅助工程(2012年5期)2012-11-21
