
采用Sigmoid函数的Web服务协同过滤推荐算法*
2017-02-20 10:49毛宜钰刘建勋唐明董
计算机与生活 2017年2期
毛宜钰,刘建勋,胡 蓉,唐明董,石 敏
湖南科技大学 知识处理与网络化制造湖南省普通高校重点实验室,湖南 湘潭 411201
采用Sigmoid函数的Web服务协同过滤推荐算法*
毛宜钰+,刘建勋,胡 蓉,唐明董,石 敏
湖南科技大学 知识处理与网络化制造湖南省普通高校重点实验室,湖南 湘潭 411201
协同过滤;Sigmoid函数;数据稀疏性;推荐系统;用户兴趣
1 引言
近年来随着服务计算及其相关技术的发展,互联网上涌现出大量功能相同但服务质量(quality of service,QoS)各异的Web服务,人们在满足功能需求的同时对服务的非功能性需求愈发重视,使得个性化服务推荐技术成为服务计算领域的一个研究热点。
协同过滤推荐是目前个性化推荐系统中应用最广泛、最成功的技术,它通常分为两类[1]:基于记忆的协同过滤(memory-based)和基于模型(model-based)的协同过滤。基于记忆的协同过滤通过近邻算法对整个用户-项目评分数据集进行计算,求出用户或项目的相似邻居来进行推荐。基于模型的协同过滤通过对历史评分记录进行学习来建立一个复杂的评分模型,然后基于该模型预测目标用户对未评分项目的评分值产生推荐。
由于传统协同过滤方法完全依赖评分产生推荐,而在用户和项目数量巨大的实际应用中,用户往往只对一小部分项目进行评价。这使得可用于度量相似度的评分数据极端稀疏,用户之间常常因为没有共同评分项目而无法进行比较[2]。另外,不同于普通项目,服务质量易随各种客观因素发生变化,用户评分也会随之改变,且用户的评分尺度各异,评分结果可信度难以保证。因此在服务推荐领域,传统的基于评分的协同过滤算法推荐质量并不高。
本文针对上述问题展开研究,提出了一种采用Sigmoid函数的Web服务协同过滤推荐算法。本文算法通过分析用户对服务的历史调用记录,利用TFIDF(term frequency-inverse document frequency)算法的思想计算用户对服务内容的兴趣度;然后引入Sigmoid函数对调用次数进行标准化处理,得到用户对服务功能的兴趣度;最后计算用户兴趣相似度,结合传统协同过滤算法预测用户兴趣,从而进行推荐。经实验证明,本文算法能有效缓解数据稀疏性问题,提高协同过滤方法在服务推荐领域的推荐质量。
本文的创新点和主要贡献有:
(1)利用调用次数预测用户兴趣,弥补了传统方法中由评分数据稀疏造成的不良影响,且调用次数易于获得,抗干扰能力强,比评分数据更可信。
(2)发现了Sigmoid函数与用户兴趣变化之间的关系,充分利用该函数特点反映出用户对服务的感兴趣程度随调用次数的变化情况。
(3)结合内容兴趣度与功能兴趣度来计算用户兴趣相似度,既考虑了用户兴趣随调用次数的变化情况,又考虑了调用同一个服务的不同用户之间的特殊性。
本文组织结构如下:第2章阐述背景与相关工作;第3章详细介绍基于Sigmoid函数的协同过滤推荐方法;第4章通过实验验证本文算法在改善推荐质量方面的有效性;最后对全文进行总结。
2 相关工作
为了帮助用户从众多功能相同而服务质量不同的服务中选择符合用户非功能需求的服务,不少学者将协同过滤方法运用到服务推荐过程。Shao等人[3]基于协同过滤思想提出了一种根据用户经验进行相似性挖掘和预测的方法,根据用户历史调用过的服务的QoS值预测用户未使用过的服务的QoS值。Zheng等人[4]则在其基础上,将基于用户的协同过滤与基于项目的协同过滤相结合,提出了WSRec推荐系统来计算QoS的预测值。Rong等人[5]从协同过滤中受到启发,结合用户兴趣相似度和关联规则对Web服务评分进行预测。Chen等人[6]通过建立高效的区域模型来分析QoS特征,并基于该模型采用改进的基于记忆的协同过滤来实现高效率的服务推荐,提高了推荐速度。Li等人[7]同Zheng等人一样,结合两种协同过滤算法,并将用户对服务的历史调用次数引入相似度计算过程,提高了QoS预测值的准确度。Hu等人[8]根据用户调用服务的时间和地点来为目标用户选择最近邻居,提出一种上下文感知的协同过滤方法进行服务推荐。Zhao等人[9]则在协同过滤的基础上,提出一种新的相似度计算方法,同时考虑两个用户共同调用的服务以及分别调用的服务数目,使得到的相似用户更加准确。Deng等人[10]认为现有服务推荐方法大多只关注于单个服务的属性,却忽略了用户与服务之间的关系,因此根据用户对服务的评分建立信任网络,基于该网络计算可信度来进行预测,提高了协同过滤算法的推荐质量。王海艳等人[11]基于Beta信任模型建立用户间信任关系,提出一种基于可信联盟的服务推荐方法。该方法引入服务的推荐属性特征,根据改进的相似度计算方法与服务推荐行为的信任度构建出邻居用户的可信联盟,根据该可信联盟来进行推荐。
现存的服务推荐算法,绝大多数都是基于服务的QoS值来进行推荐,而实际情况中服务的QoS易随网络状况等客观因素发生变化,针对不同用户的QoS差别很大,可信度难以保证。观察发现,人类的兴趣与其行为有很大关联,如用户对项目评分、评论、频繁使用等行为,都表明了用户的兴趣。实际上,用户对不同服务的调用次数相差很大,可以认为,被用户调用次数越多说明该服务越受用户关注。调用次数客观上反映了用户对服务的感兴趣程度,具有很大的利用价值,且相对于评分而言,调用次数不需要用户刻意反馈,易于收集,因此本文将调用次数引入协同过滤方法来进行推荐。
3 基于Sigmoid函数的推荐算法
在实际生活中,由于用户和服务数目众多,人们往往不会对每个使用过的服务进行评价,评分矩阵成为一个高维稀疏矩阵。这就使得用户之间共同评分项目数量很少,甚至完全没有共同评分,给相似度计算过程带来了极大的挑战。学者们经过研究发现,用户在使用网络时的点击、浏览、评论、评分等行为能从某种程度上反映用户兴趣[12-13],为分析用户兴趣提供了更多有利资源。因此本文利用这一结论,将调用次数引入协同过滤推荐过程,根据TF-IDF算法的思想计算用户对服务内容的兴趣度,然后用Sigmoid函数对调用次数进行标准化处理,得到用户对服务功能的兴趣度,并结合两种兴趣度计算用户兴趣相似度,提出了基于Sigmoid函数的协同过滤算法。该算法分为4个步骤:兴趣度计算,用户的兴趣相似度计算,兴趣度预测值计算和推荐。
3.1 兴趣度计算
3.1.1 内容兴趣度计算
调用次数在一定程度上反映了用户对不同服务的感兴趣程度,用户ui对服务oj的兴趣度随ui对oj的调用次数的增加呈正比增加,同时也随着oj被其他用户的调用频率呈反比下降。因此,利用TF-IDF算法[14]的思想,根据调用次数来计算用户对服务内容的兴趣度。
在信息检索领域,TF-IDF是一种评估一字词对于一个文件集中的一份文件的重要程度的统计方法,从理论上讲,它也可以用来评估K维空间中一个对象在某一特定维度的重要性。本文将推荐系统中每个用户看成一个文档,被用户调用的服务为文档中的单词,用户对服务的调用次数即文档中单词出现的次数,由此来计算用户对服务内容的兴趣度。
定义1(内容兴趣度)用户对服务的内容兴趣度表示用户对服务内容的感兴趣程度。假设在推荐系统中,存在一个包含n个用户的集合U={u1,u2,…,un}和一个包含m个服务的集合O={o1,o2,…,om}。用户ui对服务oj的调用次数为Ri,j,服务oj对用户ui的“重要性”由词频TFi,j来计算:


其中,n是推荐系统中总的用户个数。因此,用户ui对服务oj的内容兴趣度由以下公式定义:

用户ui对O={o1,o2,…,om}中所有服务的内容兴趣度值组成用户ui的内容兴趣度向量,即Ci=(Ci,1,Ci,2,…,Ci,m)。
3.1.2 功能兴趣度计算
用户对不同服务的调用次数相差很大。一方面,调用次数可以无限增加没有上限;另一方面,对于调用次数为0的服务,用户也并不是完全没有兴趣,只是尚无使用经验。为了通过调用次数更合理地反映用户兴趣,防止调用次数特别多的服务将用户对其他服务的兴趣淹没,以及为用户未调用的服务赋一个初始值,本文引入Sigmoid函数对调用次数进行标准化,得到用户对服务功能的兴趣度。
Sigmoid函数是一个在生物学中常见的S形函数,它由以下公式定义:

该函数连续、光滑、严格单调,其值在区间(0,1)之间,且关于点(0,0.5)中心对称,是一个良好的阀值函数。在区间(-∞,0]上呈先慢后快的非线性增长;反之,在区间[0,+∞)上呈先快后慢的增长趋势。
定义2(功能兴趣度)在服务推荐系统中,用户对服务的功能兴趣度表示用户对服务所提供的功能的感兴趣程度。用户ui对服务oj的功能兴趣度Fi,j由以下公式得到:
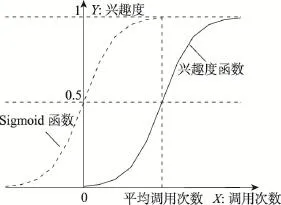
Fig.1 User's function interestingness function and Sigmoid function图1 用户功能兴趣度函数与Sigmoid函数
由式(5)可知,用户ui对O={o1,o2,…,om}中所有服务的功能兴趣度值组成用户ui的功能兴趣度向量,即Fi={Fi,1,Fi,2,…,Fi,m}。
3.2 用户的兴趣相似度计算
相似度计算是协同过滤推荐算法中的一个重要步骤,常用方法有夹角余弦法和Pearson相关系数法[15-16]。本文选用余弦相似度分别计算用户间的内容兴趣相似度和功能兴趣相似度,再结合二者来计算用户的兴趣相似度,具体公式如下:
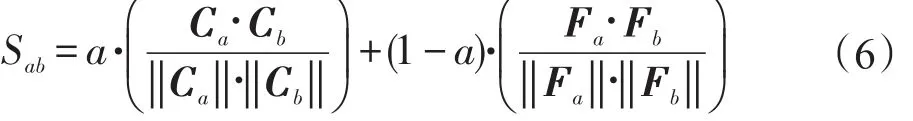
其中,Sab表示用户ua和ub之间的兴趣相似度;‖Ca‖为向量的模;a为设定的可调节的基于内容兴趣相似度和功能兴趣相似度的参数。不失一般性,本文将参数a设为0.5,即认为两者重要性相同,但根据应用或数据集的不同特征,该参数可以进行不同的设置。
3.3 兴趣度预测值计算
在计算出用户之间的兴趣相似度后,选择与目标用户相似度最大的前K个用户组成目标用户ua的最近邻居集Na,然后通过以下公式得出目标用户ua对目标项目oq的兴趣度:

3.4 推荐
得到目标用户对未调用过的服务的兴趣度预测值后,就可以选择出预测值最高的前N项服务推荐给用户,即目前推荐系统中运用最为广泛的top-N推荐。
算法1基于Sigmoid函数的Web服务协同过滤推荐算法
输入:用户-项目调用矩阵R(n,m),目标用户ua,最近邻居个数K,推荐集Irec项目数N。
输出:目标用户ua的top-N推荐集Irec。
步骤1根据式(3)求出矩阵R(n,m)中每个用户对服务的内容兴趣度,得到一组用户内容兴趣度向量C1,C2,…,Cn。
步骤2根据式(5)和用户调用矩阵R(n,m),得到一组用户功能兴趣度向量P1,P2,…,Pn。
步骤3根据式(6)计算用户的兴趣相似度矩阵sim(ui,uj)n×n。
步骤4由sim(ui,uj)n×n,得到与目标用户ua相似度最大的前K个用户,组成ua的最近邻居集Na。
步骤5根据式(7)计算目标用户ua对他未调用过的服务的兴趣度pred(ua,oq)。
步骤6将步骤5中得到的一组兴趣度按由高到低的顺序排列。
步骤7将兴趣度最大的前N个服务组成目标用户的推荐集Irec。
4 实验及分析
4.1 数据准备
本文算法基于用户对服务的调用次数,因此必须建立用户调用次数数据集。本实验通过数据采集程序对1 000个随机抽取的样本用户在4周内的行为进行采集。样本用户每次开机时,都会形成一个对应的日志文件,数据采集程序以2 s一次的频率扫描样本用户计算机的当前焦点窗口,若焦点窗口发生变化,则会在日志中追加一条记录。一个典型的样本行为日志如图2所示。

Fig.2 Log of use beharior图2 用户行为日志
本文利用Matlab对以txt文件形式存储的日志文件进行数据预处理,最后得到812个用户对860个应用程序在4周内共31 206条的使用次数记录,以此作为实验数据集。将数据集平均分为5份,每次实验选择其中1份作为测试数据集,其余4份作为训练数据集。
4.2 准确性分析
4.2.1 度量标准
本文采用平均绝对误差(mean absolute error,MAE)和均方根误差(root mean square error,RMSE)作为推荐质量的度量标准,通过计算预测的兴趣度与实际中用户对服务的兴趣度(即标准化后的调用次数)之间的偏差来度量预测的准确性,MAE和RMSE越小,意味着推荐质量越高。假设预测的兴趣度集合表示为(p1,p2,…,pn),对应的实际兴趣度集合表示为(q1,q2,…,qn),则:
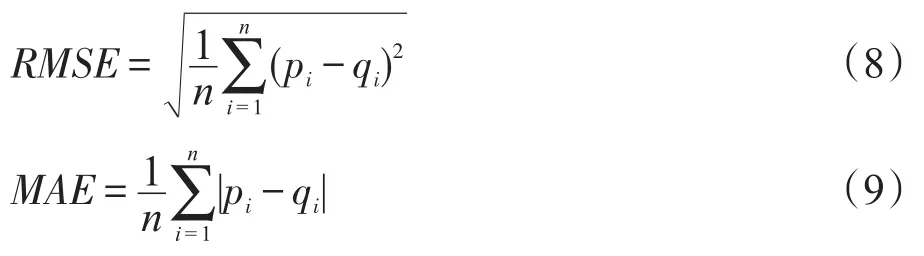
此外,本文还采用准确率(Precision)来比较基于“调用次数”和基于“评分”的协同过滤算法的推荐质量,它表示正确推荐数目占整个top-N推荐集的比例。如果top-N推荐集中某个服务oq出现在目标用户测试集中的访问记录里,则表示生成了一个正确推荐。具体计算如下:

其中,Hits表示算法产生的正确推荐数目;N表示算法生成的推荐总数。
4.2.2 准确性结果及分析
为了验证Sigmoid函数对于预测用户兴趣度的有效性,采用传统标准化方法:

对用户调用次数标准化,然后在此基础上使用协同过滤方法来与本文方法相比较,分别计算两种方法的RMSE和MAE。式(11)中ISi,j为用户ui对服务oj的兴趣度,ni,j是用户ui对服务oj的调用次数,maxni和minni
分别为用户ui所调用的所有服务中调用次数的最大值和最小值。邻居个数从5增加到40,间隔为5,基于5个不同训练集得到的实验结果如图3和图4所示。
图3和图4反映了本文算法的RMSE和MAE结果随最近邻居数目改变的变化情况。从图中的结果可以看出,在任意训练集中,本文算法都具有更小的RMSE和MAE。且随着最近邻居数目的增加,基于Sigmoid函数的协同过滤推荐算法的RMSE和MAE值变化很小,说明本文算法具有较高的稳定性。因此在没有用户评分或用户评分数据极端稀疏的环境下,本文算法不但缓解了数据稀疏性问题,也具有较高的推荐质量。
为了进一步验证本文算法在推荐质量方面的优势,将本文算法与传统的基于用户的协同过滤算法(user-based collaborative filtering,UBCF)以及基于项目的协同过滤算法(item-based collaborative filtering,IBCF)进行比较,实验结果如图5所示。可以看出,本文算法明显优于另外两种基于“评分”的协同过滤算法。
4.3 效率分析

Fig.3 Comparison onRMSEusing 5 different training sets图3 5个不同训练集的RMSE值
为了考察基于Sigmoid函数的协同过滤推荐算法在不同用户数量、不同服务数量下的运行效率,通过实验记录了本文算法与传统标准化方法在用户和服务数目由200增加至800时产生推荐所需的运行时间,并将其绘制成图6。
从图6中可以看出,两种算法的计算效率都随着用户和服务数目的增加而降低,但传统标准化方法的速度降低更快。因此当系统中用户和服务数量过多时,本文算法计算效率更高。
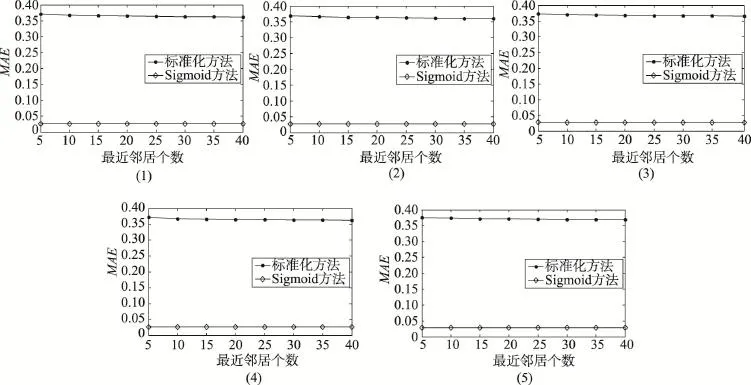
Fig.4 Comparison onMAEusing 5 different training sets图4 5个不同训练集的MAE值
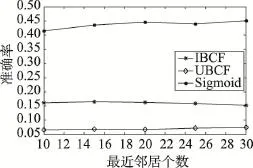
Fig.5 Recommendation precision using different CF methods图5 不同协同过滤算法对准确率的影响
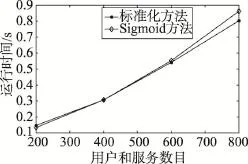
Fig.6 Comparison of different methods on time to generate recommendations图6 不同方法产生推荐所需运行时间
5 结束语
推荐系统能帮助用户从海量信息中获取到自己真正需要的资源,给人们的生活带来便利的同时也提高了网站收益,因此受到各界的广泛关注,国内外众多学者为提高推荐准确度而进行了大量研究,提出了许多不同的方法。本文针对传统协同过滤算法在用户评分数目很少的服务推荐领域推荐质量不高的问题,提出了一种根据用户对服务的调用次数将Sigmoid函数与传统协同过滤相结合的推荐算法。本文算法通过分析用户对服务的历史调用记录,利用TF-IDF算法的思想计算用户对服务的内容兴趣度;然后引入Sigmoid函数来描述用户对服务的功能兴趣随调用次数非线性变化的情况,基于两种兴趣度计算用户兴趣相似度;并结合传统协同过滤方法预测用户兴趣产生最终推荐。实验结果表明,本文算法能有效缓解数据稀疏性问题,提高了推荐质量。下一步工作将会考虑调用次数数据依然稀疏的情况,结合基于语义内容的推荐,进一步解决稀疏问题,并提高推荐精度。
[1]Breese J S,Heckerman D,Kadie C.Empirical analysis of predictive algorithms for collaborative filtering[C]//Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence,Madison,USA,Jul 24-26,1998.San Francisco:Morgan Kaufmann Publishers Inc,1998:43-52.
[2]Papagelis M,Plexousakis D,Kutsuras T.Alleviating the sparsity problem of collaborative filtering using trust inferences[C]//LNCS 3477:Proceedings of the 3rd International Conference on Trust Management,Paris,France,May 23-26,2005.Berlin,Heidelberg:Springer,2005:224-239.
[3]Shao Lingshuang,Zhang Jing,Wei Yong,et al.Personalized QoS prediction for Web services via collaborative filtering [C]//Proceedings of the 2007 IEEE International Conference on Web Services,Salt Lake City,USA,Jul 9-13,2007. Piscataway,USA:IEEE,2007:439-446.
[4]Zheng Zibin,Ma Hao,Lyu M R,et al.QoS-aware Web service recommendation by collaborative filtering[J].IEEE Transactions on Services Computing,2010,4(2):140-152.
[5]Rong Wenge,Liu Kecheng,Liang Lin.Personalized Web service ranking via user group combining association rule [C]//Proceedings of the 2009 IEEE International Conference on Web Services,Los Angeles,USA,Jul 6-10,2009. Piscataway,USA:IEEE,2009:445-452.
[6]Chen Xi,Liu Xudong,Huang Zicheng,et al.Regionknn:a scalable hybrid collaborative filtering algorithm for personalized Web service recommendation[C]//Proceedings of the 2010 IEEE International Conference on Web Services,Miami, USA,Jul 5-10,2010.Piscataway,USA:IEEE,2010:9-16.
[7]Li Yali,Pan Shanliang,Huang Xi.A kind of Web service recommendation method based on hybrid collaborative filterng [J].Journal of Computational Information Systems,2012, 8(20):8357-8364.
[8]Hu Rong,Dou Wanchun,Liu Jianxun.A context-aware collaborative filtering approach for service recommendation [C]//Proceedings of the 2012 International Conference on Cloud and Service Computing,Shanghai,China,Nov 22-24,2012.Piscataway,USA:IEEE,2012:148-155.
[9]Zhao Shuai,Zhang Yang,Cheng Bo,et al.A feedbackcorrected collaborative filtering for personalized real-world service recommendation[J].International Journal of Computers Communications&Control,2014,9(3):356-369.
[10]Deng Shuiguang,Huang Longtao,Wu Jian,et al.Trustbased personalized service recommendation:a network perspective[J].Journal of Computer Science and Technology, 2014,29(1):69-80.
[11]Wang Haiyan,Yang Wenbin,Wang Suichang,et al.A service recommendation method based on trustworthy community[J].Chinese Journal of Computers,2014,37(2):301-311.
[12]Li Yong,Meng Xiaofeng,Liu Ji,et al.Study of the longrange evolution of online human-interest based on small data [J].Journal of Computer Research and Development,2015, 52(4):779-788.
[13]Liu Jian,Sun Peng,Ni Hong.Estimation of user interest degree based on neural network[J].Computer Engineering, 2011,37(7):187-189.
[14]Chan N N,Gaaloul W,Tata S.A recommender system based on historical usage data for Web service discovery[J]. Service Oriented Computing and Applications,2012,6(1): 51-63.
[15]Su Xiaoyuan,Khoshgoftaar T M.A survey of collaborative filtering techniques[J].Advances in Artificial Intelligence, 2009,2009:4.
[16]Hofmann T.Latent semantic models for collaborative filtering[J].ACM Transactions on Informatiotems,2004,22(1): 89-115.
附中文参考文献:
[11]王海艳,杨文彬,王随昌,等.基于可信联盟的服务推荐方法[J].计算机学报,2014,37(2):301-311.
[12]李勇,孟小峰,刘继,等.基于小数据的在线用户兴趣长程演化研究[J].计算机研究与发展,2015,52(4):779-788.
[13]刘建,孙鹏,倪宏.基于神经网络的用户兴趣度估计[J].计算机工程,2011,37(7):187-189.

MAO Yiyu was born in 1992.She is an M.S.candidate at Hunan University of Science and Technology.Her research interests include service computing and cloud computing,etc.
毛宜钰(1992—),女,湖南邵阳人,湖南科技大学硕士研究生,主要研究领域为服务计算,云计算等。

LIU Jianxun was born in 1970.He received the Ph.D.degree in computer science from Shanghai Jiao Tong University in 2003.Now he is a professor and Ph.D.supervisor at Hunan University of Science and Technology,and the member of CCF.His research interests include workflow and service computing,etc.
刘建勋(1970—),男,湖南衡阳人,2003年于上海交通大学计算机系获得博士学位,现为湖南科技大学教授、博士生导师,CCF会员,主要研究领域为工作流,服务计算等。

HU Rong was born in 1977.She received the Ph.D.degree in computer aplications from Nanjing University in 2014.Now she is a lecturer at Hunan University of Science and Technology,and the member of CCF.Her research interests include service computing and data mining,etc.
胡蓉(1977—),女,湖南湘潭人,2014年于南京大学计算机应用专业获得博士学位,现为湖南科技大学讲师,CCF会员,主要研究领域为服务计算,数据挖掘等。

TANG Mingdong was born in 1978.He received the Ph.D.degree from Institute of Computing Technology,Chinese Academy of Sciences in 2010.Now he is an associate professor and M.S.supervisor at Hunan University of Science and Technology,and the member of CCF.His research interests include service computing and cloud computing,etc.
唐明董(1978—),男,湖南永州人,2010年于中国科学院计算技术研究所获得博士学位,现为湖南科技大学计算机学院副教授、硕士生导师,CCF会员,主要研究领域为服务计算,云计算等。

SHI Min was born in 1991.He is an M.S.candidate at Hunan University of Science and Technology.His research interests include information retrieval and service computing,etc.
石敏(1991—),男,湖北大冶人,湖南科技大学硕士研究生,主要研究领域为信息检索,服务计算等。
Sigmoid Function-Based Web Service Collaborative Filtering Recommendation Algorithm*
MAO Yiyu+,LIU Jianxun,HU Rong,TANG Mingdong,SHI Min
Key Lab of Knowledge Processing and Networked Manufacturing,Hunan University of Science and Technology, Xiangtan,Hunan 411201,China
+Corresponding author:E-mail:maoyiyu151@gmail.com
Collaborative filtering techniques have been widely used in various recommender systems.However,they are likely to suffer from the data sparsity problem which often results in inaccurate recommendation results.In view of this problem,this paper proposes a collaborative filtering recommendation algorithm based on Sigmoid function,by analyzing users'invocation records of services.Firstly,the relationship between a user and the invocation number of service is analyzed to acquire the user's interest in contents of service by using TF-IDF algorithm.Then,a Sigmoid function is used to calculate the user's interest in function of service according to the invocation number.Finally,personalized service recommendation is performed by combining the user's contents interestingness with the function interestingness.The experimental results show that this algorithm can effectively alleviate the data sparsity problem and thus achieve better prediction accuracy.
collaborative filtering;Sigmoid function;data sparsity;recommender system;users'interest
10.3778/j.issn.1673-9418.1511072
A
TP301
*The National Natural Science Foundation of China under Grant Nos.61572186,61572187(国家自然科学基金);the Scientific Research Fund of Education Department of Hunan Province under Grant No.15K043(湖南省教育厅科研基金);the Project of State Key Laboratory for Novel Software Technology at Nanjing University under Grant No.KFKT2015B04(南京大学计算机软件新技术国家重点实验室资助项目).
Received 2015-11,Accepted 2016-03.
CNKI网络优先出版:2016-03-07,http://www.cnki.net/kcms/detail/11.5602.TP.20160307.1710.008.html
MAO Yiyu,LIU Jianxun,HU Rong,et al.Sigmoid function-based Web service collaborative filtering recommendation algorithm.Journal of Frontiers of Computer Science and Technology,2017,11(2):314-322.
摘 要:协同过滤推荐技术被广泛用于各个推荐系统,但它仍然存在着用户评分数据稀疏性问题,可能导致推荐结果不准确。针对该问题,提出了一种采用Sigmoid函数的协同过滤推荐算法。首先,分析用户兴趣与其调用服务的次数之间的关系,利用TF-IDF算法计算用户对服务内容的兴趣度;其次,定义一个Sigmoid函数,根据服务调用次数计算用户对服务功能的兴趣度;最后,基于内容兴趣度和功能兴趣度计算用户兴趣相似度完成协同过滤算法,实现个性化的服务推荐。实验证明,该方法能有效缓解数据稀疏性问题,提高了推荐质量。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
新班主任(2022年4期)2022-04-27
商用汽车(2021年4期)2021-10-13
作文周刊·小学一年级版(2021年36期)2021-01-14
阅读与作文(小学高年级版)(2020年8期)2020-09-12
商品与质量(2019年34期)2019-11-29
汽车观察(2019年2期)2019-03-15
计算机系统应用(2019年3期)2019-03-11
民生周刊(2017年19期)2017-10-25
中国信息化·学术版(2013年1期)2013-05-28
