
差异化作业调度在Storm上的实现
2017-02-27 03:11陈伯雄艾中良
软件 2017年1期
陈伯雄,艾中良
(华北计算技术研究所,北京 100083)
差异化作业调度在Storm上的实现
陈伯雄,艾中良
(华北计算技术研究所,北京 100083)
作业调度一直是大数据技术研究的热点,关于分布式集群上的调度优化的探讨一直没有停过。本文对比分析对比静态分配调度、均匀分配调度、资源感知调度和就近调度算法,提出差异化作业调度管理技术,并把它应用到分布式实时处理系统Storm当中。经过实验验证,该调度算法能对Storm集群中不同作业任务,进行差异化管理。
作业调度;Storm;分布式计算;大数据
本文著录格式:陈伯雄,艾中良. 差异化作业调度在Storm上的实现[J]. 软件,2017,38(1):77-80
0 引言
作业调度一直是大数据技术研究的重点,通常分布式平台会有自己的一套默认调度逻辑算法,一个好的调度算法能够平衡考量系统的稳定性、性能和负载均衡[1]。作业调度问题始于计算资源有限,不可能同时满足所有作业任务。在单机计算时代,多个任务同时竞争CPU、内存、磁盘IO等资源,所以出现了CPU轮转调度、内存LRU算法这些算法,而在大数据时代,单台机器已经无法支撑作业,作业运行在计算集群中,这时候需要竞争的还有网络带宽等资源[2]。作业调度是通过调度算法,合理地有限的计算资源分配给不同的计算任务,一个好的调度算法需要同时考量系统的稳定性、性能和负载均衡。现有的流计算框架都有一套自己的通用作业调度算法[3-4],一般情况下是能够满足应用需求的,而差异化作业调度问题则在于,现实生产环境中作业需求复杂多样,而现有调度算法调度策略单一;流计算应用开发者对底层组件开发比较熟悉,能够针对具体应用场景从网路、存储等方面进行优化,现有调度算法调度并不能满足这种差异化作业的需求[5]。所以差异化作业调度问题其实是一般作业调度策略上更加高级的需求。
本文将研究静态分配调度、均匀分配调度、资源感知调度和就近调度算法,提出差异化作业调度管理技术,并把它应用到分布式实时处理系统Storm当中,最后通过实验验证,该调度算法能对Storm集群中不同作业任务,进行差异化管理。
1 当前流式处理框架对作业管理方法
1.1 静态分配调度策略
静态分配是指应用在启动之前和运行期间,占用的资源保持不变。或者对某种类型的任务分配固定资源占用。例如,给单个计算任务1 CPU逻辑内核,2G内存空间,20G磁盘空间或者将服务器资源的60%用于在线服务,40%用于离线服务,使得资源总和不超过各自的比例上限。这些应用在执行过程中几乎不悔进行规格调整,是一种静态的调度策略。
1.2 动态均匀分配调度策略
把集群可用的资源抽象出来,将计算资源尽可能均匀的分配到各个计算任务上。Storm的默认调度算法就是基于这种思想实现的。均匀的将每个组件(spout/bolt)的线程(组件并行度)分配到集群中的各个节点。举个例子,一个集群有三个节点,node1有三个worker,node2有两个worker,node3有一个worker。当用户提交一个计算拓扑(该拓扑需要4个worker,1个spout,一个bolt,spout/bolt各占2个线程,共有4个task,每个占用一个worker计算资源)。则Storm会把spout1、bolt1调度到node1,spout2调度到node2,bolt1调度到node3。通过这种策略,可以使得任务比较均匀的与计算资源进行绑定,其缺点是,如果node3挂掉,它会按照当前调度策略重新把bolt1调度给node1,这种简单均匀分配策略可能会造成局部不均衡。
1.3 资源感知调度策略
其核心算法是分析每个工作节点中各类资源的使用情况,然后根据这些资源的使用情况将工作任务调度到到合适的节点上。对于系统资源一般可以用CPU使用率、内存占用、磁盘、网络等进行细粒度划分。简单的资源感知调度策略只求局部优化,比如,针对CPU密集型的任务组件,会将它的处理单元优先分配到CPU空闲资源多的节点上;针对内存密集型的任务组件,会将它的处理单元优先分配到内存空闲资源多的节点上;针对磁盘需求密集型的任务组件,可能会将它的处理单元优先分配到磁盘资源多的节点上。复杂的资源感知调度策略需要对各项资源进行综合评估,给每一项任务每个资源计算权重,然后按照综合资源评分给抢占资源和任务排序,最后将按照顺序把资源分配给计算任务。再进一步则需要负载预测,根据CPU利用率、Memory消耗、Disk消耗,磁盘、网络IO,甚至DB IO这些历史数据中,多维度对应用、应用实例层面分别给出面向不同时间片大小的预测值,其实是非常具有挑战的事情[6]。数据规模、采集的并发实时性,噪声和突发流量甚至限流等,都对模型的响应时间、模型的准确率提出了很高的要求。因为错误的预测可能导致意想不到的调度影响,负载预测和业务关联起来,甚至和能源消耗、成本关联起来,除了趋势评估,还可以帮助决策。由此对数据的协同分析,也需要专业的团队进行跟进。总的来说,资源感知调度策略是一种业务依赖程度高、实现复杂、效果难以预测的高级调度策略。
1.4 就近调度策略
就近调度策略,而是一种流计算图优化策略[7],其核心思想是减少中间状态,减少数据迁移等带来的开销以提高性能。它的调度思路是将有直接数据传输关系的任务尽可能分配到一起,分配到同一个节点上减少网络传输造成的延时,甚至可能分配到同一个工作进程,减少网络通信、减少任务数据传输中序列化和反序列化带来的额外开销,从而提高流计算引擎的吞吐量并有效降低整体延迟。就近调度策略,也是目前业界性能优化很大的一个方向,比如国内阿里巴巴开源的JStorm,会试图将两个需要通讯的线程尽量放在一个worker中来减少网络的传输。
1.5 现有的调度策略存在的问题
静态分配调度策略是一种静态的悲观的调度策略,有点在于能够有效限制系统资源的占用,缺点是需要提前规划,缺乏灵活性,不适用于复杂的应用场景;动态均匀分配调度策略弥补了静态分配调度策略的缺点,能够根据机器集群当前状态动态调整调度方案,使得计算任务尽可能均匀的利用空闲的集群资源,缺点是没有考虑不同作业之间存在差异[8],例如资源占用类型比例不同,只是简单的把作业调度“平均”分配到集群;资源感知调度策略考略到了作业之间的差异,但是其实现复杂,效果与业务类型,负载感知,甚至和能源消耗、成本关联起来,在实际操作上一般只求局部优化,对某种类型的资源占用进行优化;就近调度策略,能有效降低延迟,但是对集群负载均衡缺乏关注,可能会造成某些机器满负荷而其它机器空载。
2 本文采用的差异化作业调度管理技术
本文分析已有调度技术的优缺点,在已有技术的基础上形成差异化作业调度策略,希望在系统稳定性、性能、负债均衡之间取得一个平衡。该策略主要受动态均匀分配调度策略和就近调度策略影响,在整体上实现负载均衡,在局部利用就近调度,需要实现用户自定义分配方式从而差异化管理了作业。依据如下:现实生产环境中作业需求复杂多样,而现有流计算引擎调度算法调度策略单一,单一调度策略不能适应不同的需求;流计算应用开发者对底层组件开发比较熟悉,能够针对具体应用场景从网路、存储等方面实现就近调度优化,解决业务瓶颈,现有调度算法调度并不能满足这种差异化作业的需求。该策略的应用场景包含:将不同组件放在同一工作节点中来达到替代DRPC的目的,比如task1->task2-task3->task4,把我们可以把task1与task4放到一个工作节点中,这样task4的结果就能直接返回给task1;将上下游的组件放在一起,避免网络传输;强制将一个组件运行分配到一个特定的机器上,减少数据在网络中迁移,减低带宽负载,例如,我们可以将一个操作数据库的组件强制分配到数据库所在的机器上;强制一个组件的不同线程运行在不同的机器中,实现业务隔离;允许用户也可以选择只对部分任务进行自定义分配,剩下其他还是使用默认的分配方式。使用差异化作业调度管理技术就能灵活处理不同业务场景,提高实时计算系统的通用性。本文拟基于开源流式计算引擎Storm进行研究开发,差异化作业调度管理技术。
3 差异化作业调度管理技术在Storm平台上的实现
3.1 具体实现过程
在Storm中,Nimbus根据默认调度程序将任务分配给Supervisor,默认调度器期望能把计算资源均匀地分配给拓扑任务[9],因此就公平性而言,Storm默认的调度策略运转良好,但是对于流处理应用开发者而言,用户不可能预测出Storm集群中拓扑组件运行的位置。又因为不同拓扑任务之间天然就存在差异性,简单的把计算资源均匀地分配给拓扑任务实际上并不能有效地利用集群资源,特别在多节点部署过程中,不个节点的计算能力、计算资源、计算场景很可能也并不相同,在这些角度上分析,允许用户将特定拓扑组件分配给位于特定的计算节点是非常重要的。因此,在Storm上开发者需要一种更加灵活的调度机制,增强用户对集群中运行的拓扑任务的掌控能力,以利于优化某些业务处理性能。
实现作业差异化调度最核心的问题是了解调度器是如何工作的以及如何获取集群信息,其中涉及理解Storm平台的调度流程和与它相关的数据结构。首先从第一个问题出发,调度器是如何工作的,Nimbus服务器启动实例化了scheduler,在用户提交了拓扑之后,nimbus服务执行了mk-assignments方法,其中调用了scheduler的schedule方法,完成资源分配,schedule是其核心实现;schedule方法的默认传参类型是Topologies和Cluster类型,从中我们可以获取所有拓扑信息(TopologyDetails)以及所有工作节点信息(SupervisorDetails),由于Storm中元数据是由thrift定义的,我们可以从storm.thrift文件中找到SupervisorDetails中与调度相关的数据元祖map
(1)在Supervisor端config/storm.yaml实现自己的元数据,比如:


(2)实现IScheduler接口,给出核心代码:配置信息,如果组件配置信息与工作节点元数据相匹配,则把计算资源分配给组件

完成调度程序后,我们需要将其打包到一个jar文件,放在Storm服务器$STORM_HOME/lib/路径下
(3)在Nimbus端config/storm.yaml加入配置:

3.2 结果检验
建立拓扑

拓扑期望实现spout1运行在host1 Supervisor上,bolt2运行在运行在host2 Supervisor上,bolt3运行在host1 Supervisor上,拓扑结构如图1:
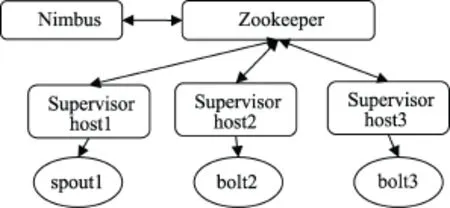
图1 实验拓扑任务
访问Storm UI,executor id[4-4] [2-2] [3-3]分别代表spout1、bolt2、bolt3组件,实验结果如图2。
可以看到调度器拓扑成功将特定组件分配到特定节点host1、host2、host上。

图2 实验结果展示
4 总结
本章首先描述了差异化作业调度管理问题,接着分析了现有分布式作业调度策略的优点和不足,接着提出本文的差异化作业调度管理技术,并解释了它相对现有调度策略的优点及其应用场景。最后在Storm上实现差异化作业调度,并用检验结果。
[1] 赵春燕. 云环境下作业调度算法研究与实现[D][J]. 北京:北京交通大学, 2009.
[2] Shieh C K, Huang S W, Sun L D, et al. A topology-based scaling mechanism for Apache Storm[J]. International Journal of Network Management, 2016.
[3] 陈若飞, 姜文红. Hadoop 作业调度本地性的研究与优化[J]. 软件, 2015, 36(2): 64-68
[4] 詹文涛, 艾中良, 刘忠麟, 等. 一种基于YARN 的高优先级作业调度实现方案[J]. 软件, 2016, 37(3): 84-88
[5] 龙少杭. 基于Storm的实时大数据分析系统的研究与实现[D]. 上海交通大学, 2015.
[6] Peng B, Hosseini M, Hong Z, et al. R-Storm: Resource-Aware Scheduling in Storm[C]// ACM MIDDLEWARE '15 Proceedings of the, ACM MIDDLEWARE Conference. ACM, 2015: 149-161.
[7] 陈廷伟, 张斌, 郝宪文. 基于任务-资源分配图优化选取的网格依赖任务调度[J]. 计算机研究与发展, 2007, 44(10): 1741-1750.
[8] Long S, Rao R, Miao W, et al. An improved topology schedule algorithm for storm system[C]//Computer Science and Applications: Proceedings of the 2014 Asia-Pacific Conference on Computer Science and Applications (CSAC 2014), Shanghai, China, 27-28 December 2014. CRC Press, 2015: 187.
[9] 李川, 鄂海红, 宋美娜. 基于Storm的实时计算框架的研究与应用[J]. 软件, 2014, 35(10): 16-20
Implementation of Differentiated Job Scheduling on Storm
CHEN Bo-xiong, AI Zhong-liang
(North China Institute of Computing Technology, Beijing 100083, China)
Job scheduling has always been a hot topic in the research of large data technology. The research on scheduling optimization on distributed clusters has not stopped. This paper compares and contrasts the static scheduling, the uniform allocation scheduling, the resource aware scheduling and the nearest scheduling algorithm, puts forward the differentiated job scheduling management technology and applies it to the distributed real-time processing system Storm. Experiments show that the proposed algorithm can perform differentiated management of different tasks in the Storm cluster.
Scheduling; Storm; Distributed Computing; Big Data
TP311
A
10.3969/j.issn.1003-6970.2017.01.016
国家基金项目
陈伯雄(1992-),男,研究生,主要研究方向:大数据、软件技术;艾中良(1971-),男,研究员级高级工程师,主要研究方向:网格计算、信息共享及信息安全。
猜你喜欢
能源工程(2022年2期)2022-05-23
重型机械(2020年2期)2020-07-24
铁道通信信号(2020年9期)2020-02-06
装备制造技术(2019年12期)2019-12-25
军事运筹与系统工程(2019年4期)2019-09-11
数学大王·趣味逻辑(2019年5期)2019-06-13
小学科学(学生版)(2019年5期)2019-05-21
经济技术协作信息(2018年30期)2018-11-22
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
