
基于cite spaceⅢ对于大数据研究的可视化分析
2017-04-05 15:24郭新敬沈子炀
现代经济信息 2017年3期
关键词:大数据
郭新敬+沈子炀


摘要:本文结合文献计量学的方法和citespace软件与excel软件,对2005—2015年间的web of scienceTM 核心合集收录的2182篇大数据研究领域的文献分别进行了研究现状、知识基础、研究热点、研究前沿进行了可视化分析,进而揭示了国际大数据领域研究的特点规律及动态过程。
关键词:大数据;大数据研究前沿;cite spaceⅢ
中图分类号:G40-057 文献识别码:A 文章编号:1001-828X(2017)003-0-03
引言
随着智能手机、平板电脑等越来越多的智能移动终端被用户所接受,而随着用户量的迅猛增长,数据也在以惊人的速度增长和累积。正是在全球数据暴涨的背景下,大数据,一个用来形容这种庞大的数据集的名词应运而生。目前,学术界、政界、工商界等都对其产生了浓厚的兴趣。大数据是一个抽象的概念,不同领域的专家学者因对其关注的方向不同,所给出的定义也不相同。
美国国家标准和技术研究院(NIST)从学术角度给大数据做了一个定义“大数据是指其数据量、采集速度或者数据表示限制了传统关系型方法进行有效分析的能力,或需要使用重要的水平缩放技术来实现高效处理的数据”。
对于大数据的特征的描述,目前比较流行的是“3VS”和“4VS”两种。“3VS”是由Gartner公司的分析师道格莱尼提出的,他将大数据描述为数量(volume)龐大、种类(variety)繁多、速度(velocity)快且具有即时性的数据集。
“4VS”则是由国际知名数据公司IDC提出的,在其发布的报告中是这样描述大数据的特征的“数量浩大、种类繁多、生成快速、价值巨大单密度低”。正是由于学者专家高涨的研究热情,探索理清大数据的发展方向,明确大数据的研究前沿,理清大数据的知识基础对于大数据研究和管理则显得尤为重要。
一、数据来源与研究方法
本文所选取的数据库具体为科学引文索引SCIE(Science Citation Index expand),检索式为”TS=big data AND TI=big data”,时间为2005—2015,检索结果有2,182条记录,来自web of science核心合集。本文选用可视化分析软件为陈超美团队所开发的CiteSpace III来对所获取到的文献数据进行分析。将之前检索并下载的引文记录放入到data文件夹中,使用CiteSpace III创建一个新的project,时间跨度选择为2005—2015,选择每一年为一个时间段,termtypes选择burstterms,并分别选择author,institution,keyword,cited author,cited reference,cited journal进行分析,设定阈值为:c(2,2,20),cc(3,3,20),ccv(3,3,20)。
二、文献产量分析
文献计量统计是科学研究中重要的研究方法, 它能反映某一学科领域的文献随时间变化的一个分布状况以及研究主题的热度情况。表一为统计表,图一为每年散点图及趋势预测图。对于文献增长的规律用多项式函数进行拟合,得到拟合曲线y = -1.27 x4 + 10223.44 x3 - 30823881.64 x2 + 41304216104.99 x - 20755444911937.60 ,R? = 0.92 ,接近于1,且曲线与数据点较为吻合,说明近期内文献数量将按照此曲线增长。
根据图形我们可以把近十年来对大数据的研究分为两个阶段:
1.萌芽期(2010年以前):2006年,大数据技术形成并运行运算与分布式系统,为大数据的深入研究奠定基础。2007年1月吉姆格雷——数据库软件先驱,第一次将这种转变称为第四范式,他认为面对这种范式,只能开发新一代的计算工具来处理海量数据。2008年,《Nature》在开辟了Big Data专栏,同年计算机社区联盟(Computing Community Consortium)发表了报告Big Data Computing:Creating Revolutionary Breakthroughs in Commerce, Science and Society[1],阐述解决大数据问题的一些方法和技术。2010年2月,肯尼斯库克尔在《经济学人》上发表报告《数据,无所不在的数据》[2]。
2.增长期(2011-2015):2011 年2 月为了对科学研究中大数据的问题及其重要性进行讨论,Science杂志出版专刊Dealing with Data。同年5月,继物联网,云计算之后,“大数据”成为又一个广受关注的名词,全球知名咨询公司麦肯锡(McKinsey&Company)肯锡全球研究院(MGI)将大数据再次推向一个热潮,发布了一份报告——《大数据:创新、竞争和生产力的下一个新领域》[3]。同年,Gartner 将大数据列入2012 年十大战略新兴技术。 6 月,IDC 研究报告《从混沌中提取价值》[4]中构成了大数据的理论基础,并提出预计未来全球数据增速将会维持,到2020 年全球数据量将达到令人恐怖的35ZB,2010 年全球数据量跨入ZB 时代,全球数据量大约每两年翻一番,预计2011全球数据量将达到1.8ZB。
2012年3月,大数据已经成为重要的时代特征,在白宫网站上,美国奥巴马政府宣布投资2亿美元到大数据领域,并发布了《大数据研究和发展倡议》[5]。
2013年5月,麦肯锡全球研究所(McKinsey Global Institute)称大数据已成为这些可能改变世界格局的12项技术中许多技术的基石,并发布了一份名为《颠覆性技术:技术进步改变生活、商业和全球经济》[6]的研究报告。2014年4月,世界经济论坛发布了《全球信息技术报告(第13版)》[7],其是以“大数据的回报与风险”为主题。同年美国数据管理领域的专家学者从学术的角度介绍大数据的产生、处理流程和方法,联合发布了《大数据白皮书》(《Challenges and Opportunities With Big Data》)[8],并提出了面对大数据的若干挑战。
三、知识基础分析
通过知识基础分析, 可以挖掘出大数据研究的发展脉络和研究基础。知识基础分析一般可以从早期奠基性文献、高被引文献两个方面进行。在CitespaceⅢ软件中, 可以通过绘制共被引文献知识图谱来展示关联数据的知识基础。 在进行软件参数设置时, 节点类型只选择共被引文献(Cited Reference),调整阈值为(2,2,20),(4,3,20),(4,3,20), 运行后生成145 个网络节点, 403 条连线, 生成的共被引文献知识图谱见图3, 图中节点的大小与节点相对应的文献被引频次成正比, 节点越大表明该文献的被引次数越高, 紫色节点代表关键节点文献。
1.早期奠基性文献
早期奠基性文献是某一学科领域后期研究的重要知识来源, 其认定的主要条件是文献被引时间早且被引频次相对较高。通过对共被引文献的时间序列知识图谱进行分析,发现大数据领域研究的奠基性文章有4 篇, 第一篇是Jeffrey Dean 和Sanjay Ghemawat 于2008 年发表的《MapReduce: simplified data processing on large clusters》[9]。两位作者在该篇文章首次详细介绍了MapReduce这种现今非常主流大数据处理编程模式。第二篇为Adam Jacobs在2009年发表的《The pathologies of big data》[10],作者在该文中指出了遇到大数据处理瓶颈时会出现的几个典型问题。第三篇是由Jeremy Ginsberg1, Matthew H. Mohebbi1, Rajan S. Patel1, Lynnette Brammer2, Mark S. Smolinski1 & Larry Brilliant1在2009年联合发表的《Detecting influenza epidemics using search engine query data》[11],几位作者在介绍了大数据在预防医学领域的一些应用。第四篇是Jeffrey Dean 和Sanjay Ghemawa在2010年发表的《MapReduce: a flexible data processing tool》[12],两位作者在文中指出了MapReduce的引用在众多领域的优点。
2.高被引文献
一般来说,高被引文献在一定程度上反映了文献的学术影响力和经典程度, 而且,其中的知识常被作为相关研究学者进一步研究的知识基础来源。因此,利用CitespaceⅢ软件分析得出大数据领域研究被引频次较高的文献,如图中引文年轮较大的几个节点所示。
将被引频次≥30 的4 篇文献作为大数据领域研究的高被引文献,如表所示。被引频次排在首位的依旧是Jeffrey Dean 和Sanjay Ghemawat 于2008 年发表的《MapReduce: simplified data processing on large clusters》[9],被引频次为161次,足以说明这篇文献是大数据领域研究的经典文献。第二位是麦肯锡研究院在2011年发布的报告《Big data: The next frontier for innovation, competition, and productivity》[3],被引频次为92次,作为从经济和商业维度诠释大数据发展潜力的第一份专题研究成果,该报告系统阐述了大数据概念,详细列举了大数据的核心技术,深入分析了大数据在不同行业的应用,明确提出了政府和企业决策者应对大数据发展的策略。第三位是Deal Jeffrey L.在2013年出版的《BIG DATA: A REVOLUTION THAT WILL TRANSFORM HOW WE LIVE, WORK, AND THINK》[13],被引频次为43次,概述详细介绍了大数据的概念、特征、构成,和处理算法的使用。第四位是White T.在2012年出版的《Hadoop: The Definitive Guide》[14],被引频次为38次,作者主要介绍了Hadoop这种大数据处理程序, Hadoop是一个由Apache基金会所开发的分布式系统基础架构用户可以在不了解分布式底层细节的情况下,开发分布式程序。
四、研究前沿分析
1.机构—国家分析
本文检索的2182篇文献共计147个节点97条连线,如图二所示,从引文年轮上来看,美国最大,中国次之,年轮越大被引次数越多,说明该国家做作的研究价值越高,约为世界学者所接受。其中交大两个年轮的最外层红色圆环面积较大这说明美国和中国所做的研究在2015年内仍旧有较大的引用次数。从国家合作来看,美国的合作伙伴多为欧洲国家包括英国,西班牙,奥地利等,中国的合作伙伴位澳大利亚加拿大等。从机构合作上来看,不难看出最大的两个合作群落是以中国、澳大利亚、加拿大机的研究机构为核心和以美国、欧洲研究机构为核心的两大合作群落(分别编号为#1,#2),从这两个合作群落的合作形态上不难看出,#1大致呈现为直线形态,每一个节点至于与其相连的的上下两个节点有联系,而#2则呈现出网状形态,群落内的主要节点间联系密切,是一种较为成熟的合作形态。由《社会网络分析》[15]我们可知,中心中介度是度量是用来度量个体在社会网络中联系密切程度的数据。由表不难看出在#2中的国家中心度较高
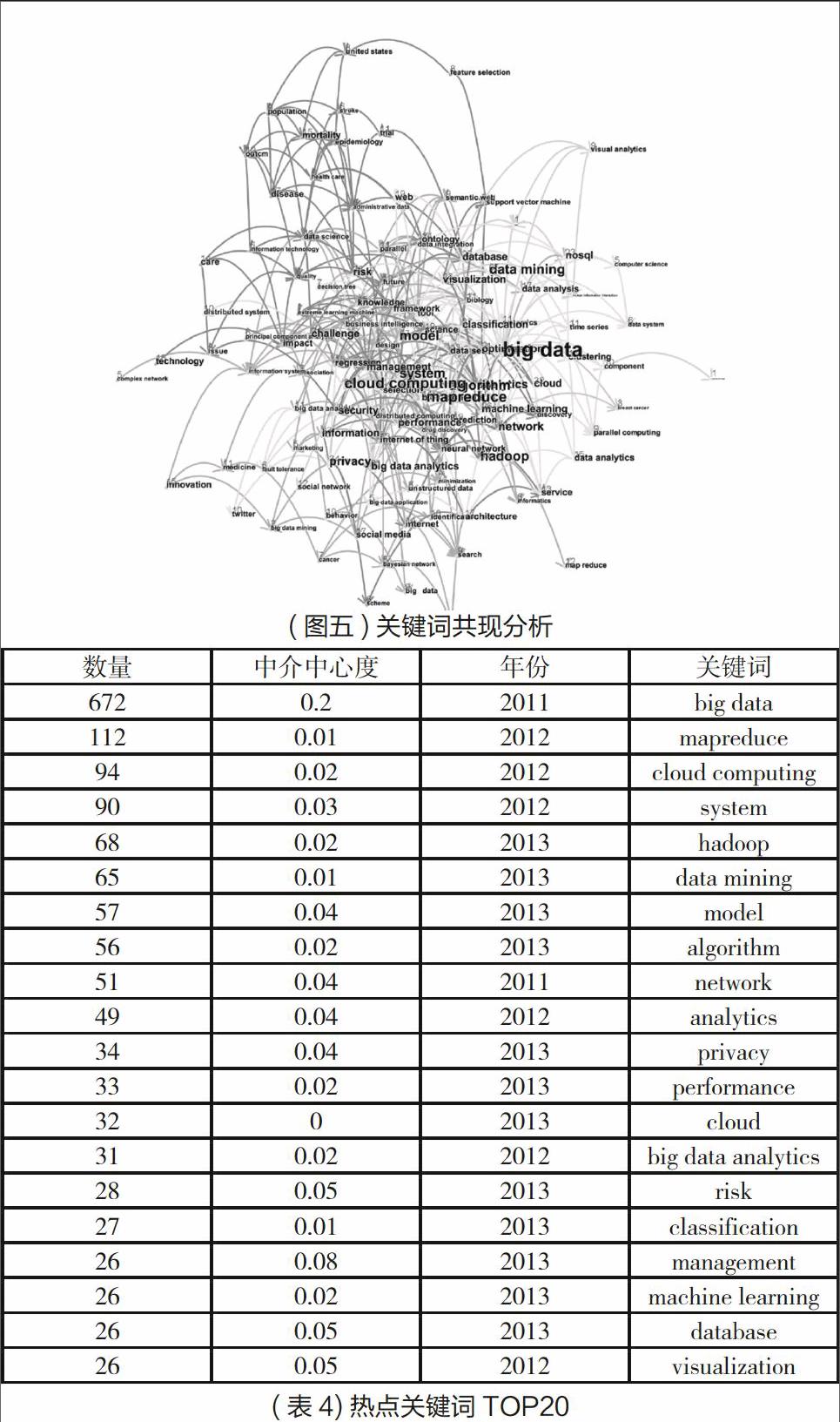
2.研究热点分析
本文2182篇文献共计162个关键词,399条连线,如图二所示。从图中我们不难看出,大数据的研究各个关键点之间的联系非常密切,最密集处 big data关键点的中介中心度为0.2,此外,从诸如network,medicine,agriculture health,social media等关键词我们也不难看出大数据与各个领域联系紧密,自大数据这一概念被提出以来至今的这十年中各个领域对大数据的研究抱有非常的热情,也取得了丰硕的成果。 表二为关键词中出现次数排在前二十位的。其中做高的为big data ,说明学术界对于大数据的概念定义特征有着深入的研究,其次为mapreduce,cloud computing,Hadoop,data minig等熱点词汇,MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。是目前处理大数据的一种主流方式。cloud computing是基于互联网的相关服务的增加、使用和交付模式,通常涉及通过互联网来提供动态易扩展且经常是虚拟化的资源,其运算能力高达每秒10万亿次。Hadoop是一个由Apache基金会所开发的分布式系统基础架构用户可以在不了解分布式底层细节的情况下,开发分布式程序。Data mining是指数据挖掘,一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。故我们不难看出学术界对于大数据的研究以对大数据的应用和处理大数据的工具与技术为主。
五、结语
以Web of ScienceTM 核心合集数据库中2182篇大数据领域研究的文献为对象, 对大数据的研究现状、研究基础、研究热点、研究前沿进行了可视化分析,得出以下结论:
1.大数据的研究可分两个时期,2010年之前为萌芽期,大数据刚刚进去人们视线,大数据方面的研究刚刚起步,2011年至2014年为增长期,大数据越来越为人们所重视,社会各界都对大数据充满了浓厚的兴趣,研究文献数量激增。2015年以后为成熟期,文献研究数量稍有回落,学术界的研究方向开始转向对于大数据的处理技术,以及在各学科的应用融合。
2.国家及机构合并网络知识图谱, 揭示了国家或机构的合作状况和分布状况, 在合作关系上,还没形成一个好的合作网络; 在国家层面上, 美国、中国、澳大利亚等国是发文较多的国家, 其中美国研究的发文量远远超过其它国家,并且其的发文最具研究关键性; 在机构层面上,美国哈弗大学、斯坦福大学、中国的社科院、清华大学等是发文较多的机构, 并且在发文机构中以高校机构为主。
3.共被引文献知识图谱揭示了大数据领域研究的知识基础构成, 其中早期奠基性文献如Jeffrey Dean 和Sanjay Ghemawat 于2008 年发表的《MapReduce: simplified data processing on large clusters》[9]和在2009年发表的《Detecting influenza epidemics using search engine query data》[11],以及Adam Jacobs在2009年发表的《The pathologies of big data》[10]是大数据领域研究的知识基础。另外,高被引文献集合也是重要的知识基础构成要素。
4.大数据研究领域产生了一些研究热点, 包括大数据本身的研究,大数据处理方式的研究,大数据在web上的应用,大数据在商业领域的应用,数据挖掘等。
参考文献:
[1]Computing Community Consortium,2008,Big Data Computing:Creating Revolutionary Breakthroughs in Commerce, Science and Society.
[2]肯尼斯库克尔,2010,数据,无所不在的数据,经济学人.
[3] MGI,2011,Big data: The next frontier for innovation, competition, and productivity.
[4]IDC,2011,Extracting Value from Chaos.
[5]American government,2012,大数据研究和发展倡议.
[6]MGI,,颠覆性技术:技术进步改变生活、商业和全球经济.
[7]世界经济论坛,2014,全球信息技术报告(第13版).
[8]H. V. Jagadish,2014,Challenges and Opportunities With Big Data.
[9]Jeffrey Dean & Sanjay Ghemawat ,2008 ,MapReduce: simplified data processing on large clusters.
[10]Adam Jacobs,2009,The pathologies of big data.
[11]Jeremy Ginsberg1, Matthew H. Mohebbi1, Rajan S. Patel1, Lynnette Brammer2, Mark S. Smolinski1 & Larry Brilliant1, 2009,Detecting influenza epidemics using search engine query data.
[12]Jeffrey Dean & Sanjay Ghemawat,2010,MapReduce: a flexible data processing tool.
[13]Deal Jeffrey L.,2013,BIG DATA: A REVOLUTION THAT WILL TRANSFORM HOW WE LIVE, WORK, AND THINK.
[14]White T.,2012,Hadoop: The Definitive Guide.
[15]OReilly Media,2013,社會网络分析:方法与实践.
猜你喜欢
今传媒(2016年9期)2016-10-15
今传媒(2016年9期)2016-10-15
新闻世界(2016年10期)2016-10-11
