
融合用户兴趣度与项目相关度的电影推荐算法研究
2017-06-01 09:50俞美华
电脑知识与技术 2017年8期
关键词:协同过滤
俞美华

摘要:在目前的电影推荐系统中,传统的推荐算法具有用户评分数据稀疏的不足,因此无法根据用户喜好进行准确推荐。针对上述問题,本文提出一种融合用户兴趣度与项目相关度的电影推荐算法,此算法基于项目类别属性的用户兴趣度计算用户间相似性,并结合基于关联规则思想计算项目间相似性从而产生推荐。基于Movielens数据集的实验结果表明,本文所提出的算法比传统的推荐算法在推荐准确度上有明显提高。
关键词:电影推荐;用户兴趣度;项目相关度;协同过滤
中图分类号:TP301.6 文献标识码:A 文章编号:1009-3044(2017)08-0022-05
随着互联网的迅速发展,网络中的电影数据海量增加,用户对于更准确高效的电影推荐需求越来越迫切,因而能够提供个性化推荐结果的推荐系统(recommerwler systems)越来越多地被运用到电影网站中。现有的推荐技术主要包括基于内容的推荐(Content-Based Recommendation)、协同过滤(collaborative filtering)推荐以及混合推荐(HybridApproach)等,其中协同过滤算法在电影推荐系统中应用最广泛。协同过滤算法的原理是基于对用户一项目评分矩阵的分析,利用历史评分数据获取目标用户的最近邻用户,根据最近邻用户的评分数据进行目标用户的推荐。然而,随着网络和用户规模的日益扩大、项目和用户数量的爆炸式增长,传统的协同过滤推荐算法存在的弊端就会体现:由于用户一项目评分矩阵存在极大的数据稀疏性,推荐结果往往存在偏差,推荐精度较低。
对于数据稀疏性问题,许多学者对传统的协同过滤算法进行修改和完善。Luo等提出用户局部相似性和用户全局相似性的概念来计算用户间的局部相似性和全局相似性,从而产生局部最近邻和全局最近邻,然后计算两种最近邻的预测评分,并通过一个权重控制参数平衡两种预测评分的贡献度。Anan等对Luo的工作进行拓展,考虑评分数据的整体稀疏度和局部稀疏度,由此可以产生可变的估算权重控制参数。Choi等计算用户相似性时考虑目标项目与所有项目的相似性,与目标项目越相似,它在计算最近邻的过程中影响就越大。Lee等嘴时间信息融入到协同过滤算法中,将时间分为若干阶段并给每一阶段赋予相应的权重值,最后基于这些时间权重获取推荐结果。Chen等提出一种基于影响集的协同过滤算法,计算目标项目的最近邻和逆最近邻并分别产生预测结果,最后通过4种方法融合预测结果。Leem等通过基于用户和基于项目的协同过滤产生两种预测结果,再以共同评分数作为权重参数混合预测结果。Wang等提出的基于相似性融合的协同过滤算法是结合目标用户对邻居项目的评分、邻居用户对目标项目的评分、相似用户对相似项目的评分3种数据,并通过评分标准化及概率方法实现预测推荐。Sandyig等结合了数据挖掘的思想,提出了一种基于关联规则挖掘的协同过滤推荐算法。
基于以上研究,本文进一步提出了一种融合用户兴趣度与项目相关度的电影推荐算法,该算法从用户和项目两个方面来解决相似性度量的问题,通过用户间相似性计算得到候选邻居集合,并在此基础上结合项目间的关联关系得到双重邻居选取后的最近邻用户集合,由此产生最终的推荐结果。其中在改进的用户相似性度量过程中引人用户共同评分和用户对项目类别属性的偏好,同时通过挖掘项目间的关联关系计算项目关联度。通过结合以上二者,本文所提出的方法能够对传统基于协同过滤的电影推荐算法进行改进,有效解决数据稀疏性的问题,保证电影推荐的质量和精确度。
1相关研究
1.1基于协同过滤的传统电影推荐算法
在传统的电影推荐算法中,应用最广泛的是协同过滤算法。根据Breese等人的分类方法,协同过滤算法可以分成两类:基于记忆的协同过滤和基于模型的协同过滤。其中基于记忆的协同过滤算法通过用户一项目评分矩阵获得用户间或项目间的相似关系,然后以这种相似关系产生进行推荐,主要又可分为基于用户的协同过滤算法(User-based Collaborative Filtering,UBCF)和基于项目的协同过滤算法(ITem-based CollaborativeFiherinG,IBCF)两种。
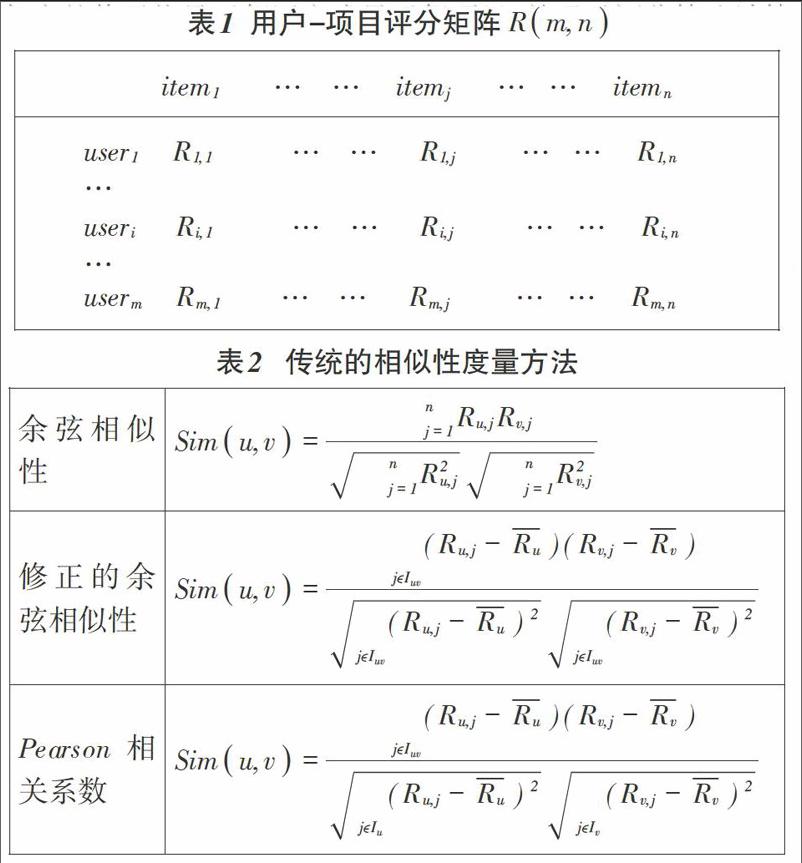
传统的协同过滤推荐算法基于用户-项目评分矩阵R(M,n)寻找目标用户的最近邻(nearest neighbor)集合,集合U表示所有用户,集合I表示所有项目,其中m行表示m个用户,n列表示n个项目,Ri,j表示用户i对项目j的评分值,这个评分值体现了aseri对itemj的兴趣和偏好。用户-项目评分矩阵如表1所示:
以用户-项目评分矩阵为基础,采用基于用户或基于项目的相似性度量方法来计算用户间或者项目间的相似度,根据相似度的值寻找最近邻用户或最近邻项目,并通过评分算法计算出预测评分,最后根据预测评分的排序结果进行推荐。目标用户的最近邻居查询的准确性直接影响整个推荐系统的推荐质量,因此相似性的度量成为提高推荐准确率的关键。相似性度量方法主要有余弦相似性、修正的余弦相似性、Pearson相关系数等方法,具体计算法如表2所示。计算可以基于用户间或基于项目间的计算,表2中以基于用户的相似性计算为例,即基于用户的协同过滤算法:
1.2传统相似性算法的不足
余弦相似性的计算方法较为简易,但是该方法将用户未评分项目的评分默认为0且没有考虑不同用户可能有不同的评分尺度,有些用户倾向打高分而有些用户倾向打低分。
修正的余弦相似性计算方法中,如果用户只对一个项目评分,则平均评分次数为1,即分母为0,从而无法计算用户之间的相似性。由于数据稀疏性,可能导致较多用户无法计算相似性,使得推荐结果存在偏差。
Pearson相似性计算方法中,当共同评分项目数为2时,Pearson相关系数只有1或者-1两个值,因此该方法会导致公共评分项目数比较少的用户占优势。
2融合用户兴趣度与项目相关度的电影推荐算法
2.1用户兴趣度的相似性度量
传统的用户间相似性计算只针对用户评分的相似性,但是现实中用户间的相似性不仅与用户对项目的评分有关,还与用户对某类项目的喜好程度有关,即用户对项目类别属性的兴趣度。当两个用户评分的项目属性相似时,则可认为这两个用户之间也具有较高的相似性。目标用户与其邻居对项目类别属性的兴趣度应该是具有一定的相似性,因此本文结合基于用户兴趣度的相似性对传统的基于用户相似性度量方法进行改进,并选取候选用户集合。
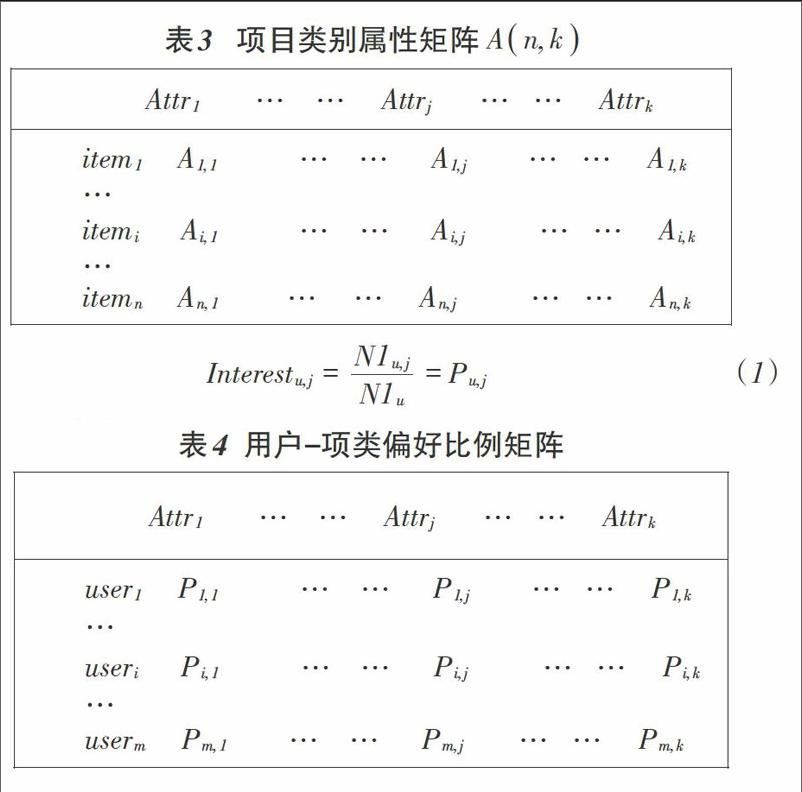
定义1.项目类别属性。假设项目类别属性用集合A={Attr1,Attr2…,,Attrk}来表示,每个项目的特征都可以用集合中的一个多个类别属性来描述。注意的是,现实生活中多数情况是—个项目只属于一个类别属性,因此后文的研究只考虑这种情况。
如表3所示,项目类别属性矩阵A(n,k)是一个二值型矩阵,其中Ai,j的值为1代表项目i具有类别属性j,为0则代表项目i不具有此类别属性。
定义2.用户兴趣度。将用户对于项目类别属性的偏好看作用户兴趣度,用户评价某类项目的次数越多,表明用户对这类项目越感兴趣。用户u对某种项目类别属性Attrj的用户兴趣度Interestu,j可用公式(1)表示为:
(1)
其中,N1u,j表示用户u对j类项目的评价总数,N1u表示用户u已评价项目的总数。Interestu,j反映了用户对某一项目类别属性的偏好是基于整体的用户偏好进行的相对计算,由此获得更加准确的用户兴趣度。
如表4所示,可以建立用户一项类偏好比例矩阵P(m,k),其中Pi,j根据公式(1)进行计算可得。
实验2.为了验证本文所提出的融合用户兴趣度与项目相关度的电影推荐算法(ours)的有效性,在同样环境下用同样的实验数据将该算法与传统的基于余弦相似性协同过滤(UCB-CF)、基于Pearson相关系数的协同过滤(UPBCF)以及目前被广泛用于对比实验的文献14所提出的IRPCF算法进行对比实验,比较各自的推荐质量MAE。本实验中最近邻用户个数K设置为从5递增到60,间隔为5,平衡因子ω设置为0.5。实验结果如图2所示:
由上图可知,在任意K值下,本文所提出的新算法ours都获得了最小的MAE值;同时随着最近邻个数K的增加,MAE的值减小,推荐系统的准确度得到提高且趋于稳定。此外,新算法ours的平均MAE值为0.766,较UCBCF的0.822、UPBCF的0.811和IRPCF的0.796都有显著降低。这是因为UCBCF和UPBCF是基于整个用户集合选取最近邻而忽略了项目类别属性的影响,导致MAE值较大;IRPCF则需要以两个用户之间的评分项目对集合为基础,但由于存在评分项目对集合为空的现象,导致此算法的推荐质量有所减低。而本文所提出的算法能够有效得融合用户兴趣度和项目关联度两个方面的影响,通过双重选取最近邻,有效提高了整体推荐的准确性和质量。
4结论
结合电影推荐系统的实际需求,通过分析传统电影推荐算法的不足,本文綜合考虑用户的项目类别属性偏好和项目的关联关系对相似性计算的影响,提出了一种融合用户兴趣度与项目相关度的电影推荐算法。通过对比实验分析比较算法的准确性,表明本文所提出的算法能够有效提高推荐系统的精度与质量。
