
基于深度增强学习的智能体行为演进研究综述
2017-10-16 23:37郭宪
中国新通信 2017年17期
郭宪
【摘要】 智能体行为演进技术是人工智能方面一个新兴且具有潜力的领域。随着AlphaGo胜利,基于深度增强学习的智能体行为演进技术被大量应用。首先介绍深度增强学习的基本概念及原理,然后介绍当前主流的智能体训练策略,着重分析单智能体提升以及多智能体协作问题的解决方法并对其优缺点进行全面的阐述,最后在深入分析多智能体协作技术目前存在的问题的基础上,对未来发展趋势进行展望。
【关键词】 智能体 行为演进 人工智能 深度增强学习 训练策略
Overview of agent behaviors evolution based on deep reinforcement learning GUO Xian (School of Computer and Information Technology,Beijing Jiaotong University,Beijing 100044)
Abstract: agent behaviors evolution technology is a new and emerging field for artificial intelligence. With the victory of AlphaGo, agent behaviors evolution technology based on deep reinforcement learning has been widely used. Firstly, concepts and principles of deep reinforcement learning were introduced, then the current mainstream training strategies of multi-agent were discussed. This paper analyzed the solution to multi-agent cooperation problem and made an overview about their advantages and disadvantages.Finally, the direction of future work was proposed based on in-depth study of current multi-agent collaboration technology researches.
Key words: multiagent;artificial intelligence; deep reinforcement learning; training strategy; collaborative technology
引言
目前,单智能体的研究已取得了重大的进展,包括下围棋的AlphaGo[1]、打德州扑克的Libratus[2]以及用于医疗诊断的Watson[3]。但是,智能的提升一方面来自个体,另一方面群体交流、协作也是提升智能水平的重要手段;尤其针对人类不擅长的复杂问题,多智能体协作、共同决策可能是个有效途径[4],在电商、游戏、医疗健康等领域都有广泛应用前景。
如何训练机器人进行相互协作,在对信息进行高效整合利用的同时,对敌对方机器人做出打击和摧毁。在训练中,期望让机器人根据对抗训练的动态反馈,自我生成出一套应对的智能体战术,配合彼此,完成战役设想。
一、深度增强学习
1.1增强学习的基本理念架构
目前,解决智能体行为演进的基本思路是把这一问题作为一个增强学习[5]问题来解决。不同于分类学习根据类别结果评价智能体表现,增强学习利用状态下的环境反馈来改善自己的行为。一个增强学习问题,一般可以被抽象为:在环境状态s下寻求合理行为a,利用环境反馈r来做出修正。这里,状态s是指随着行动发生,个体与相关区域所处的状态(state);行为a是指在环境状态s下,智能体所做出的对应行为(action);反馈r是指智能体在环境s中做出行为a的评价激励(reward)。在增强学习问题中,智能体可以通过行为a来改变环境状态s;提升手段利用评价反馈r来改变行为a;行为a和状态s联合起来,决定对应的反馈值r[6]。
二、智能体训练策略
基于环境反馈信息自主形成应对策略,一直是智能体研究领域里的核心话题。在过去的一段时间中,计算能力不足和提升策略的限制使得这一领域一直缺乏根本性的进展。近年来,由于摩尔定律以及深度神经网络方法的应用[9-11],硬件性能和提升算法有了长足的进步。随着神经网络在增强学习任务中投入应用,业界不断发展出来一系列相对成熟的智能体训练策略。
2.1单智能体训练策略
到目前为止,满足实践检验的单智能体策略演进机理,可分为DQN (Deep Q Network, 深度Q值网络) [12]和DDPG(Deep Deterministic Policy Gradient,深度决定策略梯度)[13]两类。为了加速神经网络收敛速度,两者采用了逐步优化的TD(Time Difference,时间差)方法[14-16]取代了整体优化的MC(Monte-Carlo,蒙特卡洛)方法[17-18]。
DQN使用Q值网络对步骤行为的逐步长期回报进行预计,在有限离散的行动策略中选取长期回报最大的一个选项;DDPG则在DQN的基础上更进一步,使用Actor-Critic(行动-评价)[19-20]的双网络架构对智能体行动策略进行優化:使用值网络生成连续行动,使得策略总体长期回报J最大;再使用Q值网络对逐步长期回报进行实时评价,以辅助对总体长期回报J的更新优化。DQN与DDPG方法作为单智能体行动策略的基本训练方法,已经在多种机器人的行为训练如机器臂取物[21]、机器腿行走[22]中起到了显著的效果。DQN由于原理限制,能够处理活动速度固定的少数离散自由度的训练问题;而DDPG由于原理上的优势,能够进一步处理活动速度变化的大量连续自由度的训练问题。目前,业内很多智能个体的训练方法正在从人为给定行为策略转变为根据反馈自动生成的DQN乃至DDPG方法。因此,应用DQN和 DDPG的自动训练方法替代人为给定方法,解决多智能体问题,被认为有更大的前景和空间。
2.2多智能体训练策略
智能单体策略训练的进展,使得关于智能群体协作训练的探讨,变得日益重要。同时,现实中的大量零和博弈[23-24]使得团体间的对抗十分常见。由此,多智能体的协作问题[25]应运而生。
相对于以往的单体环境问题,这里探讨的多智能体协作具有更高的复杂度:一方面在于智能团体协同对抗相对于智能单体任务,不但要考虑环境因素,还要考虑到己方、敌方、中立方的行动和意图;另一方面在于考虑个体行动策略的以外,智能团体间的神经元网络联结模式[26]也应纳入考虑。
现有的多智能体协作方法,大都是2016之后提出的。CommNet(Communication Neural Net,交流神经网)[27]默认智能体一定范围内的全联结,对多个同类的智能体采用了同一个网络,用当前态(隐态)和交流信息得出下一时刻的状态,信息交流从利用隐态的均值得出。其优点能够根据现实位置变化对智能体联结结构做出自主规划,而缺点在于信息采用均值过于笼统,不能够处理多个种类的智能体。除此以外,RIAL(Reinforced Inter-agent Learning,增强智能体间学习)[28]和DIAL(Differentiable Inter-agent Learning,差异智能体间学习)[29]个体行为中采取了类DQN的解决方式,在智能体间进行单向信息交流,采用了单向环整体架构[30]两者的区别在于RIAL向一个智能体传递的是Q网络结果中的极大值,DIAL则传递的是Q网络的所有结果。在实验中,两者均可以解决多种类协同的现实问题,且DIAL表现出了很好的抗信号干扰能力。但是,在处理非静态环境的快速反应问题上,RIAL与DIAL的表现仍旧不足。借鉴之前CommNet和DIAL的研究,阿里巴巴团队为了解决多智能体的协作问题,提出了使用BiCNet(Bidirectionally - Coordinated Nets,双向协作网络)[31]决多智能体协作的方法。相较于之前的研究,BiCNet在个体行为上采取了DDPG取代DQN作为提升方法,在群体连接中采用了双向循环网络取代单向网络进行联结。这一方法在DIAL的基础上利用了双向信息传递取代单向信息传递,在多种类协同的基础上一定程度上解决了快速反应的问题。然而,BiCNet的组织架构思想仍旧没有摆脱链状拓扑或者环状拓扑结构,且不具有动态规划能力,在现实实践中会有很大问题。在相互摧毁的真实战术背景下,不具有动态规划能力的网络中一点的破坏会导致所有经过该点的所有信息交流彻底终止。在无恢复的前提下,链状拓扑和环状拓扑对于网络中的每一端点过分依赖,导致少量几点的破坏会对智能体交流网络造成毁灭性影响,团体被彻底拆分失去交流协同能力。
三、单智能体策略提升的基本方法
3.1深度Q值网络DQN
3.1.1 DQN的基本方法
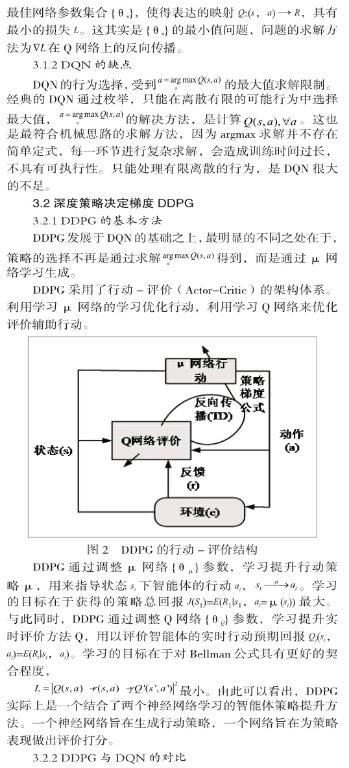
在策略的生成中,由于DDPG的神经网络能够自主产生解,取代了在DQN的已知枚举结果中选择最大的值,DDPG弥补了DQN只能选择有限离散行动的不足,能够解决连续策略生成的训练提升问题。在处理对象自由度提升时,所要做的仅仅是线性加宽μ和Q网络的输入层,而不是指数性地增加Q网络输入层中的行动对应项。在处理多复杂度问题[32]和连续行动策略的表现上,DDPG相较于DQN有着显著的优势。
DQN和DDPG中的Q网络,因为离散枚举和连续求解的区别,在形式上稍有不同,但两种表述等价。DQN采用的是枚举多个Q值,输入层的是状态 ,输出层是所有行动 对应的多个Q值 。DDPG的输入层是状态 和行动 ,输出层是一个Q值 。两者的区别仅仅是前者未定行动但能有限枚举,后者行动既定允许连续变化。在其他方面,例如Bellman公式终止环节的处理以及神经网络反向传播的方法,DQN和DDPG并不存在本质上的差异。
四、多智能体协同问题的解决方法
受到单智能体策略演进方法的启发,当前较先进的多智能体协同问题多采用DQN[12]或者DDPG[13]作为个体行动策略,在此基础上进行个体间神经网络的设计与规划。在多智能体协作问题的研究中[33],相对主流的实现方法是2016年提出的CommNet[27]和DIAL(RIAL)[28],基于二者发展出的最新方法是2017年提出的BiCNet[31]。
4.1交流神经网CommNet
4.1.1CommNet技术原理
CommNet(Communication Neural Net,交流神经网)是最早提出的一类多体问题解决方案,不同于为每一个个体分配一个不同的神经网络来进行决策,CommNet利用同一个网络解决所有个体的行动。在网络中的每一层中,CommNet进行了一次信息的范围交互。而且每一层之间的输入和输出可以形成迭代关系[34]。
然而其缺点是只能处理同种智能体。CommNet在交流公式递推中采取了平均值的形式,假设了所有智能體的权重相同。这其实意味着,CommNet描述的问题默认了智能体的一致性[35]。
4.2差异(增强)智能体间学习
4.2.1 DIAL(RIAL)的基本方法
RIAL(Reinforced Inter-agent Learning,增强智能体间学习)和DIAL(Differentiable Inter-agent Learning,差异智能体间学习)是单智能体策略演进方法DQN在多体问题上扩展。就具体进步而言,RIAL和DIAL在智能个体的DQN步骤间构建了网络联结,使得智能体的DQN评价Q和行动a对应的最大Q做到了信息的单向共享。
RIAL和DIAL的思路是,将第i智能体中的步骤结果,输出到i+1智能体的原始数据中,作为和si+1相同作用的一部分。DIAL将第i智能体诸多{Qk}作为信息进行传递,RIAL仅仅将行动对应最大值maxQk进行传递。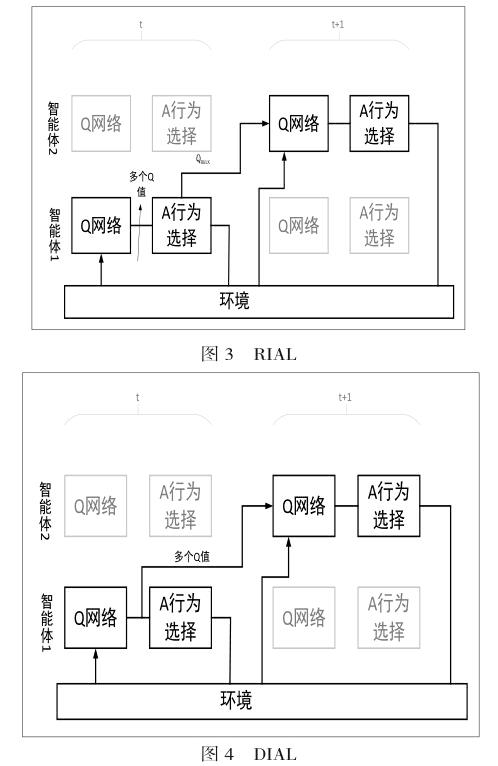
4.2.2 DIAL(RIAL)的优劣
在实际的表现中,DIAL表现出了优于RIAL的性质,这一方面是因为传递的信息更多,另一方面是因为Q网络的全部结果体现了行动的全部可能性,胜过某一个结果所内含的可能性。DIAL相对RIAL在智能体间的信号传递过程中表现出极好的噪声容忍性,对于传递信号添加的适当噪声,仍然能保证训练的正常进行[36-37]。
不过,DIAL(RIAL)在通信架构上实际上采取了单向环状的通信架构,而且动态规划能力不足。总言之,DIAL解决了多种智能体协作的问题,但是在处理快速变化环境上的表现不佳。另外,联结结构僵化脆弱,无法处理动态强的问题,无法耐受网络架构上的破坏,也是DIAL不足之处。
4.3双向协作网络BiCNet
4.3.1BiCNet的基本方法
BiCNet(Bidirectionally-Coordinated Nets, 双向协作网络),是迄今为止实现方法最为先进的多智能体协同方法,结合了 CommNet和DIAL的优点,在能够处理多种类智能体协作问题的同时,在快速变化问题的表现上有了提高。
BiCNet以双向循环网络(Bi-Directional RNN)[38]作为智能体间的联结方式,这样做一方面是为了在智能体间信息交互,另一方面是为了产生局域记忆。在智能个体的行动策略上,BiCNet采用DDPG作为智能体的个体策略。这也就意味着BiCNet实际上使用了两个网络来处理多智能体训练问题,μ网络形成行动策略[39Q网络评价行动。总体来看,BiCNet的μ网络,在作用上等于DDPGμ网络形成策略、雙向RNN进行交流、智能体局域关联进行组织三者的有机组合。
4.3.2 BiCNet的优劣
BiCNet的改进之处在于使用了双向循环网络代替了单向网络,使得信息可以进行双向的交流。这样使得智能体的信息交流速度变快,处理动态问题表现更好。同时,BiCNet采用了DDPG而非DQN作为智能体个体策略,一方面能够处理连续策略问题,一方面复杂度有所降低。另外,又因为其本身并没有做出一些特别的智能体假设限制,使得其对于多种类智能体有处理能力。
五、结束语
现有多智能体协作方法大多具有的结构脆弱以及组织僵化的弱点[40在网络中,信息传递只能按照固有的智能体编号进行传递:以1,2,…,i,…,I,1,…的顺序往复循环。当智能体数量增大时,一次信息遍历需要历经比较长的时间,在这段时间内智能体状态一旦大幅改变,会造成网络失去实时性,进而失效无法有效训练多智能体。这一问题是单向环状通信导致的,i+1对i的通信需要多种连接绕环一周,影响传递的速度可以想见是非常慢的。另外,如果环状网络上的某点出现问题,通信序列在后的智能体将永远无法将信息传给通信在前的智能体,智能体的交流彻底失效。
因此,在智能体连接的信息交换方面,信息交换网络的端点和内容,有很大的探讨的空间。就具体而言,可以在BiCNet的DDPG方法基础上,尝试仿照DIAL(RIAL)中对DQN网络做出的调整,为智能体内部的 网络和Q网络,提供更多种类的交互信息,找寻对应信息的提取源头和最佳的输出点。
综上所述,为多智能体协作提供一种能够耐受打击破坏的有效联结架构,并且为之提供一种动态组织方式。使多智能体架构能够在高破坏烈度的战场环境中保证有效运转并具有自我恢复、调配和规划能力,是未来多智能体协作技术的研究重点。
参 考 文 献
[1]田渊栋. 阿法狗围棋系统的简要分析[J]. 自动化学报,2016,42(5):671-675.
[2] Matej Morav?ík,Martin Schmid,,Neil Burch,et al. DeepStack: Expert-Level Artificial Intelligence in No-Limit Poker[J]. Science,2017,356 (6337):508
[3]Murthy Devarakonda, Ching-Huei Tsou. Automated Problem List Generation from Electronic Medical Records in IBM Watson[C]. Proceedings of the 27th Conference on Innovative Applications of Artificial Intelligence. 2015: 3942-3947.
[4] Burt Wilsker. A Study of Multi-Agent Collaboration Theories [R]. Information Science Institute,Research Report. 1996
[5] L. Busoniu, R. Babuska, B. De Schutter. A comprehensive survey of multiagent reinforcement learning[J]. IEEE Transactions on Systems Man & Cybernetics Part C,2008,38(2):156-172.
[6] 劉佳,陈增强,刘忠信. 多智能体系统及其协同控制研究进展[J]. 智能系统学报,2010, 5(1):1-9.
[7]Christopher JCH Watkins,Peter Dayan. Q-learning[J]. Machine learning,1992,8(3-4):279-292,
[8]Hu J L, Wellman M P. Nash. Q-learning for general-sum stochastic games[J]. Journal of Machine Learning Research,2004,4(6):1039-1069.
[9]郭丽丽,丁世飞. 深度学习研究进展[J]. 计算机科学. 2015,42(5):28-33.
[10] C. J. Maddison, A. Huang, I. Sutskever, et al. Move evaluation in go using deep convolutional neural networks[C]. ICLR. 2015.
[11]A. Tampuu, T. Matiisen, D. Kodelja, et al. Multiagent cooperation and competition with deep reinforcement learning[J]. Plos One,2017,12(4):e0172395.
[12]V. Mnih, K. Kavukcuoglu, D. Silver, et al. Playing Atari with deep reinforcement learning[C]. In Deep Learning, Neural Information Processing Systems Workshop. 2013.
[13] TP. Lillicrap,JJ. Hunt, A. Pritzel. Continuous control with deep reinforcement learning[C]. ICLR. 2016
[14]Jordan B. Pollack,Alan D. Blair. Why did td-gammon work[C]. International Conference on Neural Information Processing Systems. 1996,10-16.[15]Gerald Tesauro. Temporal difference learning and td-gammon[J]. Communications of the ACM,1995,38(3):58-68.
[16] J. Schmidhuber. Deep learning in neural networks: An overview[J]. Neural Networks,2014,61-85.
[17]L. Kocsis,C. Szepesvari. Bandit based Monte-Carlo planning[C]. European Conference on Machine Learning,2006:282-293.
[18] X. Guo, S. Singh, H. Lee. Deep learning for real-time atari game play using offline monte-carlo tree search planning[C]. NIPS. 2014
[19]Xin Xu, Chunming Liu, Dewen Hu. Continuous-action reinforcement learning with fast policy search and adaptive basis function selection[J]. Soft Computing - A Fusion of Foundations, Methodologies and Applications,2011,15(6):1055-1070.
[20]陈兴国, 高阳, 范顺国. 基于核方法的连续动作Actor-Critic学习[J]. 模式识别与人工智能, 2017,27(2):103-110.
[21]祁若龙,周维佳,王铁军. 一种基于遗传算法的空间机械臂避障轨迹规划方法[J]. 机器人, 2014 , 36 (3) :263-270.
[22]任陈俊. 基于机器视觉的场景目标检测与分类研究[D]. 杭州:杭州电子科技大学,2016.
[23]黎萍,杨宜民. 基于博弈论的多机器人系统任务分配算法[J]. 计算机应用研究,2013,30(2):392-395.
[24]叶晔,岑豫皖,谢能刚. 基于博弈论的多移动机器人聚集任务路径规划[J]. 计算机工程与应用, 2009,45(06):216-218.
[25]段勇,徐心和. 基于多智能体强化学习的多机器人协作策略研究[J]. 系统工程理论与实践,2014,34(5):1305-1310.
[26]D. Maravall, J. De Lope, R. Domnguez. Coordination of communication in robot teams by reinforcement learning[J]. Robotics and Autonomous Systems,2013,61(7):661-666.
[27] S. Sukhbaatar, A. Szlam, R. Fergus. Learning Multiagent Communication with Backpropagation[C]. NIPS. 2016
[28]JN Foerster , YM Assael , ND Freitas. Learning to Communicate with Deep Multi-Agent Reinforcement Learning[C]. NIPS. 2016
[29]S. Ioffe,C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]. ICML,2015:448-456.
[30] F. S. Melo, M. Spaan, S. J. Witwicki. QueryPOMDP: POMDP-based communication in multiagent systems[C]. European Conference on Multi-agent Systems,2011,7541 :189-204.
[31] Peng Pengy, Quan Yuany, YingWen.Multiagent Bidirectionally-Coordinated Nets for Learning to Play StarCraft Combat Games[EB/OL].https://arxiv. org/abs/1703.10069,2017-03-29.
[32] Angeliki Lazaridou, Alexander Peysakhovich, Marco Baroni. Multi-agent cooperation and the emergence of (natural) language[EB/OL].https://arxiv. org/abs/1612.07182,2017-03-05.
[33] Caroline Claus,Craig Boutilier. The dynamics of reinforcement learning in cooperative multiagent systems[C]. AAAI/IAAI, 1998:746-752.
[34]Y. Li, D. Tarlow, M. Brockschmidt, et al. Gated graph sequence neural networks. ICLR, 2015
[35]袁坤. 多智能體网络一致性问题的分布式算法研究[D]. 合肥:中国科学技术大学,2014.
[36]M. Courbariaux,Y. Bengio. BinaryNet: Training deep neural networks with weights and activations constrained to +1 or -1[EB/OL]. https://arxiv.org/ abs/1602.02830,2016-03-17.
[37] G. Hinton,R. Salakhutdinov.Discovering binary codes for documents by learning deep generative models[J]. Topics in Cognitive Science,2011,3(1):74-91.
[38]Mike Schuster,Kuldip K Paliwal.Bidirectional recurrent neural networks[J]. IEEE Transactions on Signal Processing,1997,45(11):2673-2681.
[39]Nicolas Usunier, Gabriel Synnaeve,Zeming Lin, et al. Episodic exploration for deep deterministic policies: An application to starcraft micromanagement tasks[EB/OL].https://arxiv.org/abs/1609.02993,2016-11-26.
[40] Long-Ji Lin. Reinforcement learning for robots using neural networks[R]. Technical report, DTIC Document, 1993.
猜你喜欢
科学Fans(2019年6期)2019-07-26
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
小康(2017年16期)2017-06-07
都市家教·下半月(2016年11期)2016-12-29
中学课程辅导·教学研究(2016年14期)2016-12-23
南风窗(2016年19期)2016-09-21
南风窗(2016年19期)2016-09-21
考试周刊(2016年45期)2016-06-24
考试周刊(2016年37期)2016-05-30
