
基于谱聚类算法黑龙江垦区农业机械装备水平聚类分析
2017-12-16 10:48于金明吴秋峰
农机化研究 2017年3期
孟 军,徐 勇,于金明,吴秋峰
(东北农业大学 a.理学院;b工程学院,哈尔滨 150030)
基于谱聚类算法黑龙江垦区农业机械装备水平聚类分析
孟 军a,徐 勇b,于金明b,吴秋峰a
(东北农业大学 a.理学院;b工程学院,哈尔滨 150030)
针对黑龙江省垦区各农场的农业机械装备水平差异性较大及数据维数高的问题,基于谱聚类算法的聚类方法,对2013-2015年垦区东部36个农场的统计数据进行了聚类分析。结合各农场农业生产总值变化速率与平均机耕面积农机总动力变化速率之间的关系,将聚类结果定义为发达农场、中等发达农场、不发达农场3类。结果表明:聚类较为准确,符合垦区农业机械装备水平差异性较大的事实,能够反应垦区农业机械装备水平现状,可为垦区未来经济的协调发展和农业机械管理等方面提供理论依据和有效建议。
农业机械装备水平; 谱聚类算法; 差异;黑龙江垦区
0 引言
黑龙江垦区经过60年的开发建设,已成为我国最大的国有农场群和农业机械装备现代化程度最高的垦区。农业机械装备合理规划有利于粮食综合生产能力的进一步提高,更有利于农场经济的发展[1]。纵观黑龙江省东部垦区的36个农场,各农场之间的农业机械化装备水平存在明显的差异性。客观真实地对各地区进行农机装备水平差异合理分析和评价,是优化农机装备结构的重要措施[2]。因此,对农场现有农机装备水平聚类,不但可为农场管理部门提供理论依据,还可以客观地对农场机械装备的结构化进行合理调整。
本文对黑龙江垦区东部36个农场的农业机械装备水平进行聚类分析,在聚类分析上采用谱聚类算法。建立在谱图理论基础上,与传统的聚类算法相比,能在任意形状的样本空间上聚类且收敛于全局最优解。本文根据统计数,将影响垦区农场农业机械装备水平差异的各项指标定义为影响差异性的不同维数,计算各维数间数据点的相似度矩阵,进而将具有数据结构相似的农场聚为同一类别。以往对农业机械装备水平的聚类和分类问题都是将选取的数据进行分析后去掉影响因素小的数据,往往不能全面反映数据内部结构,导致聚类精度不高;但该算法将影响因素中的每一个数据都考虑在内,提高了聚类的精度。常见的K-means聚类算法、EM算法等都是建立在凸球形的样本空间上,但当样本空间不为凸时,算法会陷入局部最优;直到谱聚类方法被提出,有效地克服了传统聚类算法的以上缺点。为此,针对垦区农场统计数据的庞大和属性多的特点,本文提出的算法可提高聚类精度及计算速度,且使计算结果全局最优。
本研究依据黑龙江农垦统计年鉴提供的数据对农场进行了聚类并结合实际情况分析聚类结果,目的在于正确评价农业机械化装备程度及发展趋势,为实现农业现代化提供理论依据与建议。
1 垦区农业机械装备水平指标的选取
黑龙江垦区的农业机械装备水平可以全面反映垦区农业发展现状及趋势[3],所以应该建立有效的农业机械装备水平的指标体系。该研究结合黑龙江垦区实际情况,为了充分体现农业机械化装备水平的特征,并按照评价指标体系建立的原则,即系统性原则,典型性原则,动态性原则,简明科学性原则,可比、可操作、可量化原则,以及综合性原则建立如图1中的评价指标体系。该体系包括3个层次:第1层次为目标层,即以农业机械化装备水平为评价总目标。第2层次为二级指标,为评价农业机械化装备水平,选取包括总量指标、单位面积农业机械装备量、单位面积农具装备配套量;为更好、更全面地量化二级指标,分别在各个二级指标下设定三级指标。第3层次为具体的8项可量化的三级评价指标。

图1 农业机械装备水平指标体系Fig.1 Level index system of agricultural machinery and equipment
2 谱聚类算法模型
谱聚类算法是基于谱图理论[4]中图的最优划分思想提出的,它将聚类问题模拟成对无向图的划分,本质是将数据点聚类问题转化成对无向图的最优分割的问题。谱聚类算法将样本数据集中的每个数据点看作图的每个节点V,顶点之间用边E连接,其权重即为数据点的相似度W,进而构造出一个无向加权图G=(V,E)[5]。通过以上的变换可以将原来的聚类问题转化成在图G上的最优划分问题。
标准谱聚类算法主要应用高斯核函数计算数据点之间的相似度,谱聚类算法通用流程[6]为
(1)
i,j=1,2,…,n
根据式(1)所得相似度矩阵S采用k-近邻、ξ-近邻、全连通的其中一种对相似矩阵进行稀疏化处理得到相似矩阵为
W:
wij≥0, i=1,2,…,n; j=1,2,…,n
wij=wji
矩阵变换得到度矩阵D为
(2)
i=1,2,…,n
度矩阵D减去连接矩阵W得到顶点集的拉普拉斯矩阵L[7]。非归一化拉普拉斯矩阵为
L=D-W
(3)
规一化拉普拉斯矩阵具有如下性质,则有
Lsym=D-1/2LD-1/2=I-D-1/2WD-1/2
(4)
Lrw=D-1L=I-D-1W
(5)
其中,式(4)和式(5)中的L即为式(3)中的非归一化拉普拉斯矩阵;Lsym是对称矩阵;Lrw是一个随机游走矩阵,通常是非对称的。
谱聚类算法根据构建的拉普拉斯矩阵,求解其前k个特征值并构建特征向量,然后采用K-means算法对特征向量聚类出k个流行结构。算法步骤描述如下:
1)构造基于样本空间相似度的相似度图,并计算相似度矩阵W及度矩阵D。
2 )计算拉普拉斯L。依据需要解决的实际应用问题采用非归一化的拉普拉斯矩阵或归一化的拉普拉斯矩阵或者归一化的拉普拉斯矩阵Lsym或者Lrw。
3 )计算拉普拉斯L的前k个特征值及其对应的特征向量v1,v2,…,vn(k为需要将数据集进行聚类的个数)。
4 )采用经典K-means[8]聚类算法对特征向量空间的特征向量进行聚类,得到聚类结果C1,C2,…,Ck。
3 农机装备水平聚类及结果分析
基于谱聚类算法,选取2013-2015年8项指标数据的平均值,对黑龙江东部36个农场进行聚类。数据预处理,首先对选取的指标数据按照公式(6)进行无量纲化处理[11-13],则有
(6)
2013-2015年8项指标数据平均值处理后分别设为2013-2015年间机耕总面积平均值x1(hm2);农业生产总值x2(万元);农业机械总动力x3(kW);单位耕地面积联合收割机数量x4(台/hm2);单位耕地面积大中型拖拉机数量x5(台/hm2);单位耕地面积小型拖拉机数量x6(台/hm2);单位耕地面积大中型拖拉机配套农具x7(台/hm2);单位耕地面积小型拖拉机配套农具x8(台/hm2)。具体数据如表1所示。
本文应用MatLab软件进行程序编写。首先,输入处理后的数据集为X=(x1,x2,x3,x4,x5,x6,x7,x8,x9,x10)。第2步通过高斯核函数计算数据对之间距离,按照公式(1)计算得相似度矩阵W。其计算过程中数据点间距离越大相似度越低,保证相似度大的农场聚为同一类的概率增大,而相似度较小的农场疏远 。第3步按照公式(4)构造拉普拉斯矩阵L,最后采用经典K-means算法对L的特征向量进行聚类,聚类结果如表2所示。
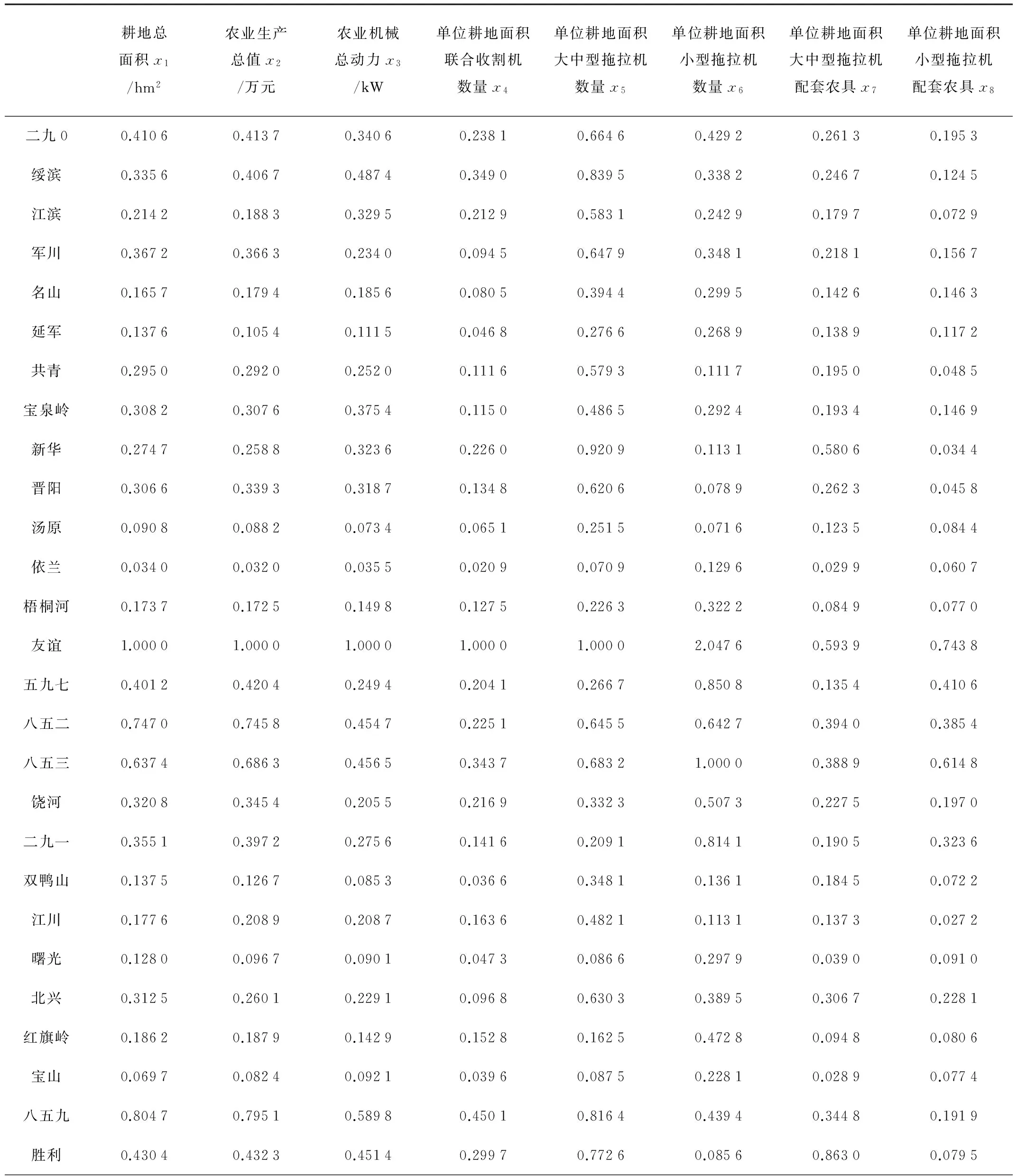
表 1 黑龙江东部36个农场2013-2015年间平均农业机械装备统计数据Table 1 Heilongjiang eastern 36 farm 2013-2015 three years average agricultural machinery and equipment statistics
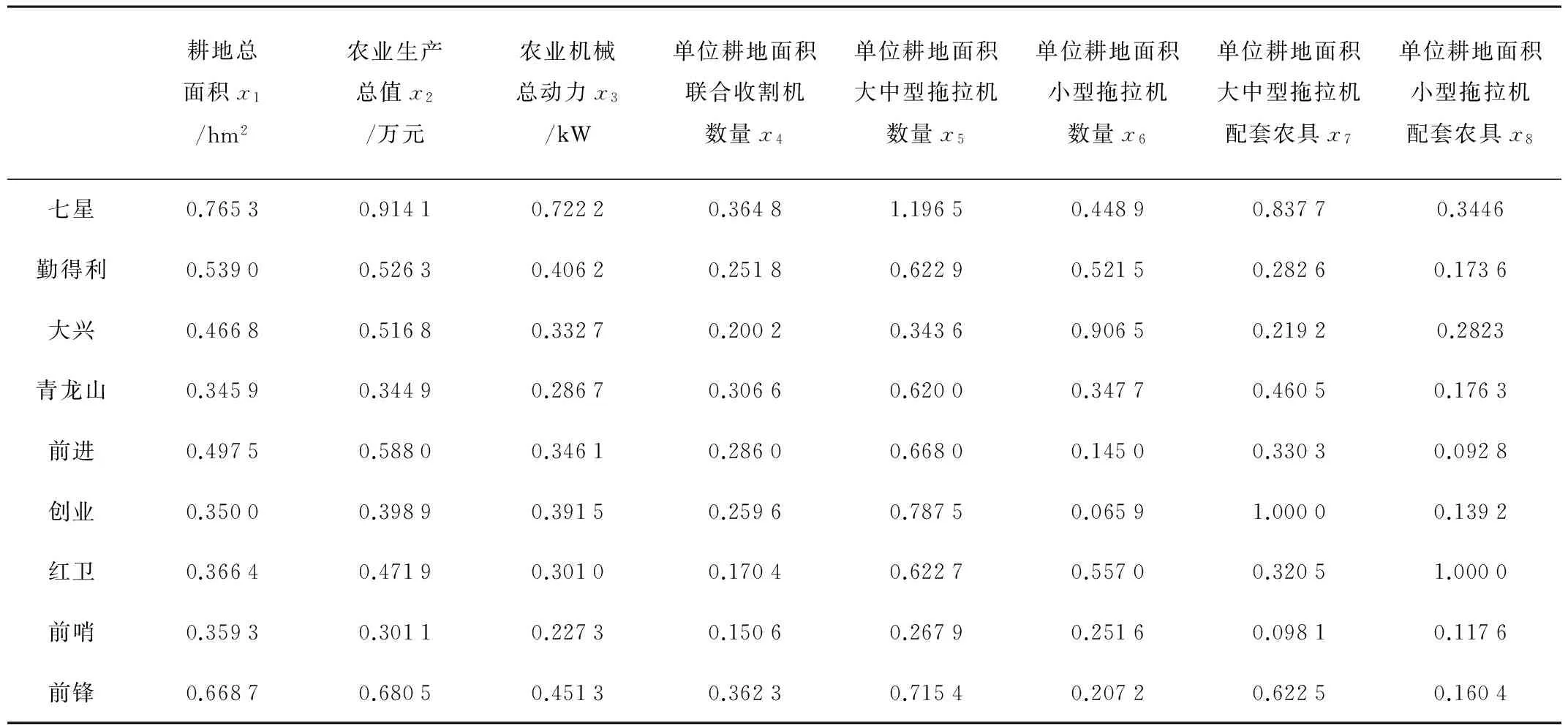
续表1

表 2 黑龙江垦区东部36个农场农机装备水平聚类结果Table 2 Heilongjiang reclamation area east of 36 farm agricultural equipment level clustering results
结合以上聚类结果、各农场农业机械总动力和农业生产总值增长速率可以看出:第1类农场农业生产总值和农业机械总动力分别是3类结果中平均值增长较快的一类,如图2所示;通过了解该类农场的地貌环境等信息及图3中农业机械装备数量配比图可以将该类农场归纳为农业机械装备水平较高,大中型机械与小型机械结构较为合理的农场。如友谊、八五三、八五二等农场拥有土地面积大的地块居多,且大中型农业机械装备数量及配套农机具数量多,小型拖拉机及设备较少,农机装备配比较合理,因此农业生产总值增长速率较快,属于大中型农业机械装备占主导地位农场,故定义为发达农场。
第2类农场农业机械装备水平处于中等平稳发展趋势,农业生产总值与农业机械总动力都属于缓慢增长类型,呈现较平稳增长趋势,属于中等发达农场。
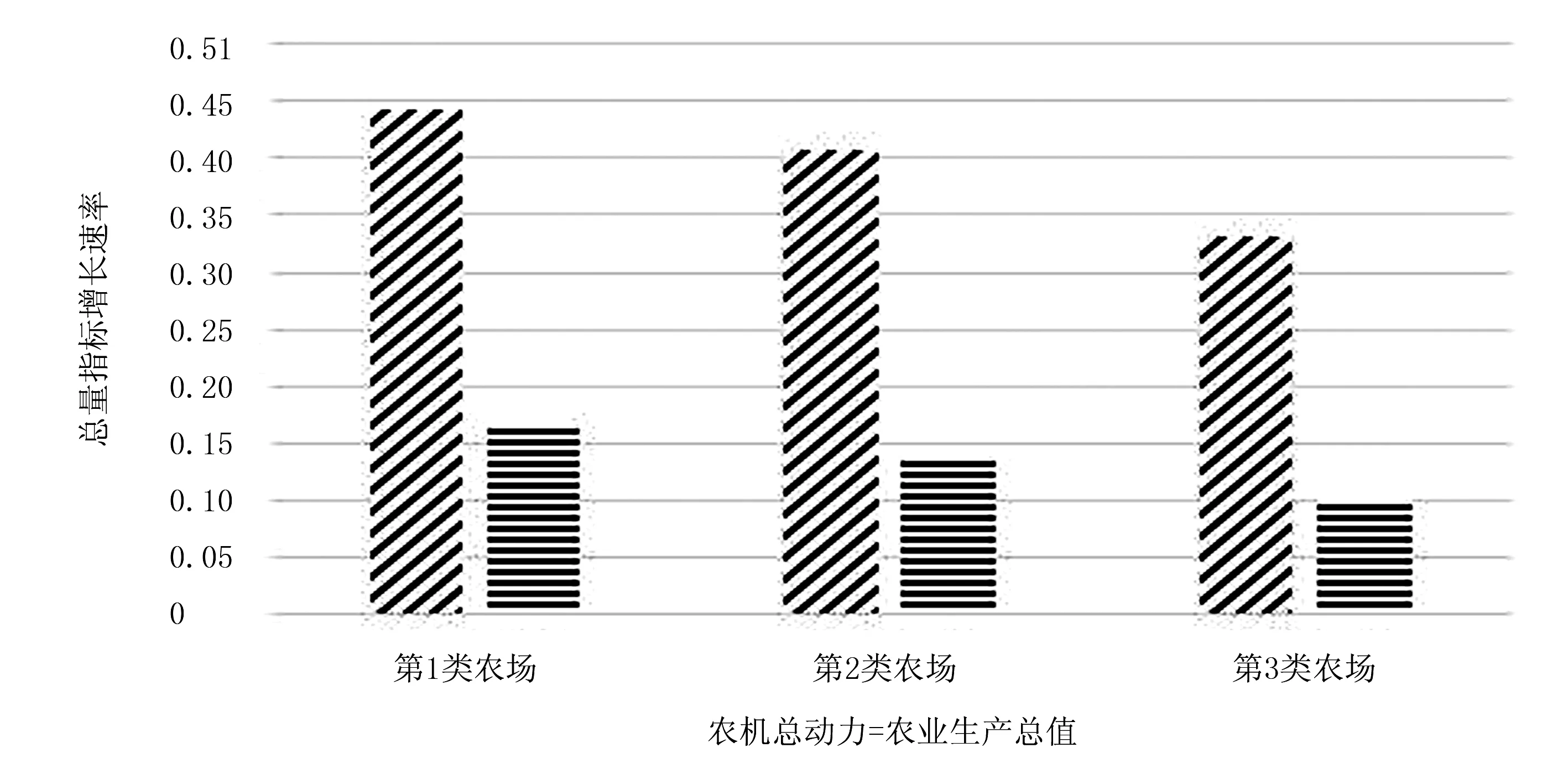
图2 3类农场农业机械总动和农业生产总值平均增长速率Fig.2 Three types of farm agricultural machinery and agricultural total average GDP growth rate
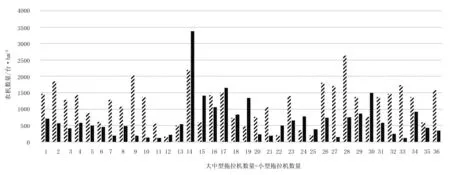
1.二九0 2.绥滨 3.江滨 4.军川 5.名山 6.延军 7.共青 8.宝泉岭 9.新华 10.晋阳 11.汤原 12.依兰 13.梧桐河 14.友谊 15.五九七 16.八五二 17.八五三 18.饶河 19.二九一 20.双鸭山 21.江川 22.曙光 23.北兴 24.红旗岭 25.宝山 26.八五九 27.胜利 28.七星 29.勤得利 30.大兴 31.青龙山 32.前进 33.创业 34.红卫 35.前哨 36.前锋图3 36个农场机耕面积平均大中型拖拉机及小型拖拉机数量Fig.2 The 36 farm tractor area of large and medium-sized tractors and the average number of small tractors
由图2中可看出:第3类农场平均农业机械总动力和农业生产总值增长速率较慢。通过了解该类农场实际地理环境发现,这些农场农机装备结构配比不合理。如汤原农场地块小且分散,地理位置复杂,适合小型拖拉机耕种;然而该农场大中型拖拉机数量相对较多,不因地制宜地选取合适本农场地块的农业机械装备,导致作业过程中出现大型机械闲置,小型机械不够的不平衡现象。曙光农场无论是大中型拖拉机数量还是小型拖拉机数量都相对较少,导致春种秋收时期机械装备不够用的情况,这种不合理的农机装备配比影响着该农场的农业生产总值,甚至有些农场呈现负增长情况,属于不发达农场。
4 结语
黑龙江垦区东部36个农场农业机械化装备水平差异性很大,本文通过对2013-2015年间10项数据指标的平均值进行基于谱聚类算法的聚类分析,聚类结果分为3类。同时,结合实际情况将3类农场概括为发达农场、较发达农场和不发达农场。发达农场经济效益高、农业机械化装备水平高,农场各方面呈现协调发展的态势。较为发达农场农业机械装备水平较高,属于农业机械装备水平带动经济发展的农场,随着农业机械总动力的平稳增长农业生产总值也趋于平稳增长趋势,适度增加农业机械投资以及提高农业机械的使用效率有助于农场未来经济稳定增长。非发达农场机械化水平并不高,农业经济效益发展滞后,大中型拖拉机和小型拖拉机比例严重失调,相关部门应根据本农场环境和地理位置合理的购置新型机器,也可以尝试同其余机械装备结构不合理的农场进行等价交换,如拥有大中型拖拉机过剩的农场交换本农场缺乏的小型拖拉机等。政府决策部门应加大农业机械化投资,并制定相关政策合理调配农业机械,根据农场具体环境,配备相应农机具,提升农业经济效益。
本文的研究可为各个农场的农机维修部门提供参考意见,发达农场实施采购大中型农机维修材料为宜。较发达农场根据不同农场条件采购大量相应农机维修设备为宜。
[1] 党召娣.我国农业机械化水平现状及重要性简述[J].南方农业,2014,8(12):63-67.
[2] 袁玉萍,安增龙.基于支持向量机的农机装备水平差异分类研究[J].中国农业大学学报,2015,20(4):167-173.
[3] 孙福田.农业机械化对农业发展的贡献及农业机械化装备水平的研究[D].哈尔滨:东北农业大学,2004.
[4] Zelnik-Manor L,Perona P.Self-tuning spectral clustering[J].Advances in Neural Information Processing Systems,2004,17:1601-1608.
[5] 1.Z Wu, R Leahy.An optimal graph theoretic approach to data clustering:theory and its application to image segmentation[J].IEEE Trans on PAMI,1993,15( 11):1101-1113.
[6] 蔡晓妍,戴冠中,杨黎斌.谱聚类算法综述[J].计算机科学,2008,35(7):14-18.
[7] 公茂果,焦李成,马文萍,等.基于流形距离的人工免疫无监督分类与识别算法[J].自动化学报,2008,34(3):367-375.
[8] Chi Y,Song XD.On evolutionary spectral clustering[J].ACM Transactions on Knowledge Discovery from Data,2009,3(4):17-47.
[9] 王淑艳,孟军,柏继云.区域可持续农业定量综合评价[J].农机化研究, 2009,31(1):56-58.
[10] 王福林.农业系统工程[M].北京:中国农业出版社,2009.
[11] 堵秀凤,张健,张宏民.数学建模[M].北京:北京航空航天大学出版社,2011:179-190.
Analysis of Heilongjiang Reclamation Area Agricultural Mechanization Level Clustering Based on Spectral Clustering Algorithm
Meng Juna, Xu Yongb, Yu Jinmingb, Wu Qiufenga
(a.College of Science; b.College of Engineering, Northeast Agricultural University, Harbin 150030, China)
With problems about the difference in agricultural mechanization level and high dimension data of Heilongjiang ,proposed the clustering method which based on spectral clustering algorithm to analyze the statistics of 36 farms from 2013-2015 in the reclamation area of the East.Combined with the relationship between the farm variation rate of agricultural GDP and average area of tractor agricultural machinery total power rate of change , the result of cluster is defined developed farm, more developed farm, underdeveloped farm. The result of clustering is accurate which can consistent with the reclamation area agricultural mechanization level difference of large fact and reflect the reclamation area agriculture machinery and equipment level of the status quo. It can provide a theoretical basis and effective suggestions for the future in the coordinated development of economy and the agricultural machinery management.
the level of agricultural machinery and equipment; spectral clustering; difference; Heilongjiang reclamation area
2016-03-24
公益性行业(农业)科研专项(2015-2019)
孟 军(1965-),男,哈尔滨人,教授,博士生导师,(E-mail)1135044376@qq.com。
徐 勇(1990-),男,黑龙江双鸭山人,硕士研究生,(E-mail) 249858881@qq.com。
S231
A
1003-188X(2017)03-0026-06
猜你喜欢
农业工程学报(2022年4期)2022-04-24
吉林农业·下半月(2017年11期)2017-11-11
吉林农业(2017年22期)2017-02-02
科学与财富(2016年26期)2016-12-01
农产品市场周刊(2015年15期)2015-10-30
农产品市场周刊(2014年15期)2014-08-22
中国质量与标准导报(2014年9期)2014-02-28
吉林农业·下半月(2009年7期)2009-09-08
吉林农业·下半月(2009年6期)2009-07-31
吉林农业·下半月(2009年5期)2009-06-26
