
基于语义蕴含关系的图片语句匹配模型①
2018-01-08 03:11李文波汪美玲
计算机系统应用 2017年12期
柯 川,李文波,汪美玲,李 孜
(中国科学院 软件研究所,北京 100190)
基于语义蕴含关系的图片语句匹配模型①
柯 川,李文波,汪美玲,李 孜
(中国科学院 软件研究所,北京 100190)
本文提出一种基于蕴含关系的图片语句匹配模型IRMatch,旨在解决图片语句两种不同模态语义之间的非对等匹配问题. 在利用卷积神经网络分别对图片和语句进行语义映射的基础上,IRMatch模型通过引入最大软间隔的学习策略挖掘图片与语句之间的蕴含关系,以强化相关图片语句对在公共语义空间中位置的邻近性,改善图片语句匹配得分的合理性. 基于IRMatch模型,本文实现一种图文双向检索方法,并在Flickr8k、Flickr30k以及Microsoft COCO数据集上与基于已有图片语句匹配模型的图文双向检索方法进行了比较. 实验结果表明,基于IRMatch模型的检索方法在上述三个数据集上的R@1,R@5,R@10以及Med r均优于基于已有模型的检索方法.
图文非对等匹配; 蕴含关系; 最大间隔学习; 图文双向检索; 卷积神经网络
1 引言
图片和自然语言语句(以下简称语句)的关联在图片字幕生成、图片检索等图片相关应用中扮演着不可或缺的角色[1-4]. 图片和语句关联的关键是在图片与语句之间建立合理的匹配,其实质为一个多模态匹配问题,具体来说语义相关的图片-语句对的匹配得分应该高于语义不相关的图片-语句对的匹配得分.
目前已有的图片-语句匹配方法主要有两大类,一类是将图片和语句映射到一个公共的语义空间,然后进行两者之间的匹配; 另一类是采用诸如典型相关分析 (Canonical correlation analysis,CCA)[5,6]、深度学习[1]等方式来建立图片和语句之间的关联. 在已有的这些方法中,图片和描述它的语句通常被看作是语义上对等的. 然而,我们发现图片与描述它的语句在语义上并非简单的对等关系. 图1 显示了 Microsoft COCO[7]、Flickr30K[8]与Flickr8K[5]数据集中描述同一图片的5条语句之间语义相似程度[9]的统计情况. 从图1可以看出,上述三个数据集中5条语句语义彼此之间都相似的图片数占数据集中图片总数的比例分别为8.0%,6.6%以及15.3%(请见图中横坐标为10的数据),这表明描述同一幅图片的不同语句之间往往是弱相似或者不相似的. 这是因为描述同一幅图片的不同语句可能是出于不同的描述视角,例如在表1中,右侧的语句“a girl sits on a bar stool”与“dark nightclub with chairs”都描述了左侧的图片,但是二者的语义相似度很低. 这说明,在语义上图片与描述它的语句之间并非对等的关系,而是蕴含关系[3]. 如果按照对等关系进行图片与语句的匹配,那么势必会将弱相似或不相似的语句看作相似的,显然是不合适的.
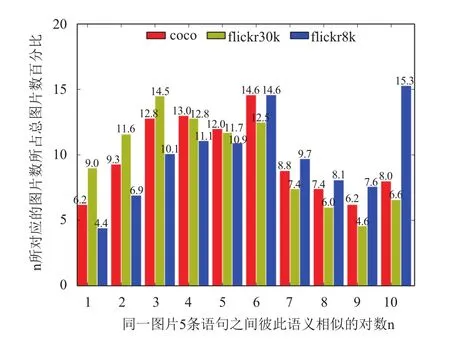
图1 Microsoft COCO、Flickr30K 以及 Flickr8K 数据集中语句相似度的统计

表1 图片与 5 条描述语句示例
本文基于图片与语句在语义上的这种蕴含关系提出一种新的图片语句匹配模型,称为IRMatch模型.IRMatch模型利用卷积神经网络(Convolutional neural network,CNN)分别实现图片与语句的语义映射,在此基础上,在图片语句对得分学习中通过引入最大软间隔的策略挖掘图片与语句之间的语义蕴含关系,以强化相关图片语句对在公共语义空间中位置的邻近性,改善图片语句匹配得分的合理性. 基于IRMatch模型,本文实现了图文双向检索方法,并在Flickr8K[5]、Flickr30K[8]以及 Microsoft COCO[7]数据集上与基于已有图片语句匹配模型的图文双向检索方法进行比较.实验结果表明,基于IRMatch模型的检索方法在上述三个数据集上的R@1、R@5、R@10与Med r均优于基于已有模型的检索方法.
本文第2节对相关工作进行介绍,第3节描述所提出的IRMatch模型,第4节给出实验结果,第5节对全文加以总结.
2 相关工作
当前的图片语句匹配方法[1,3,5,6,10-15]主要有两大类:一类方法是将图片和语句映射到同一语义空间,然后在该空间中进行两者之间的语义匹配. Socher等[14]提出使用语义依赖树递归神经网络(SDT-RNN) 来将语句映射到图片所在语义空间,然后图片与语句之间的关联可以通过该空间上的距离来度量; Klein等[12]使用 Fisher vector(FV)作为语句的表示; Kiros 等[11]提出了Skip-thought vectors(STV)来对语句进行编码以与图片进行匹配; Wang,Jian 等[15]利用 WCNN 提取语句特征,利用CNN提取图片深度特征,将两者映射到同一公共空间,并使用 one vs more 的学习策略进行学习; Karpathy 等[10]的工作在一个更加精细的水平,他们将图片的片段(对象)与语句的片段(类型依赖关系树)嵌入到一个公共空间中从而对两者的关联性进行度量; Plummer等[13]使用实体来实现区域到短语(RTP)的对应关系,从而用于图片-语句建模.
另一类方法利用诸如CCA,深度学习等方法来挖掘图片和语句之间的语义关联. Hodosh等[5]提出核典型相关分析 (Kernel canonical correlation analysis,KCCA)用于发现图片和语句之间共享的特征空间;Yan等[6]将全连接层堆叠在一起来表示语句,同时使用深度典型相关分析(DCCA)来匹配图片和语句; Vendrov,Ivan 等[3]采用 Gated recurrent unit(GRU)来提取语句的特征,并将图片和语句的关系看作是一种偏序关系,并在此关系的基础上度量图片和语句的关联性. Ma,Lin等[1]使用m-CNNs将图片与语句在word、phrase以及sentence级别进行匹配,从而实现图片与语句在局部以及全局的混合匹配.
上述两类已有方法通常将图片和描述它的语句看作是语义上对等的,而本文所提出的IRMatch模型挖掘图片与语句之间的语义蕴含关系,通过CNN将图片与语句映射到公共语义空间,之后基于最大软间隔的策略进行图片语句的关联学习.
3 IRMatch 模型
3.1 模型概述
图片语句匹配的目标是语义相关的图片语句对的匹配得分高于语义不相关的图片语句对的匹配得分[1].解决思路通常有两种: 一种是首先对图片和语句进行表示学习,之后再利用典型相关分析等方法进行图片和语句的语义关联学习[5,6],另一种是将图片与语句映射到一个公共的语义空间,之后再学习图片语句对的匹配得分[10-15]. 其中第二种思路的优势在于图片语句的表示学习和关联学习是同时进行的而不是分离的,使得图片语句匹配过程的整体性更强. 因而本文所提IRMatch模型采用第二种思路进行图片语句匹配,步骤如下:
(1)设I为图片集,S为语句集,建立映射p:I→Rk,q:S→Rk,以将I中图片与S中语句映射到公共语义空间Rk中,其中k是公共空间 Rk的维度.
(2)令得分函数f:Rk×Rk→R量度图片与语句语义映射的匹配度,即若图片与语句越匹配则得分函数的值越大. 进而,基于p,q,f定义损失函数L,并通过求解以L为目标函数的最小化问题学习图片语句对的匹配得分. 本文将匹配得分函数f视作超参数.
更具体地,IRMatch模型利用卷积神经网络CNN分别实现图片与语句的语义映射,在此基础上,在图片语句对得分学习中通过引入最大软间隔的策略挖掘图片语句之间的语义蕴含关系,以强化相关图片语句对在公共语义空间中位置的邻近性,改善图片语句匹配得分的合理性.
下面分别针对基于CNN的图片、语句的语义映射与基于最大软间隔的图片语句对匹配得分学习进行详细的介绍.
3.2 基于CNN的图片语义映射述
近年来CNN已经展现了其超强的图片特征学习能力[16-19],因而本文也采用CNN进行图片语义映射.如图2所示,CNN可由卷积层、池化层以及全连接层等组成,其中卷积层提取图像的特征,池化层针对原始特征信号进行抽象,以减少训练参数,而全连接层主要负责分类与回归.

图2 图片语义映射架构
借鉴文献[3]中的思想,IRMatch模型中用于图片语义映射所采用的CNN是具有19层的VGG网络[18],其包含19个卷积层、4个池化层以及3个全连接层.此CNN以RGB图片作为输入,使用其第二个全连接层的输出作为图片表示[3],其中图片深度特征的维度


3.3 基于CNN的语句语义映射
为了在图片语句对匹配计算中使语句的表示与图片的表示具有一致的形式,IRMatch模型采用CNN进行语句语义映射.
借鉴文献[20]中的思想,用于语句语义映射所采用的CNN具有一个卷积层与一个最大池化层,如图3所示.

图3 语句语义映射架构
输入语句中单词的表示方式与文献[20]一致,即用对应的词向量表示. 输入语句由词嵌入矩阵(图中蓝色的部分)表示,词嵌入矩阵中单词的顺序与该单词在语句中的顺序一致.
卷积过程采用了不同尺寸的卷积核,如图3所示,紫色的卷积核的宽度是3,黄色的卷积核的宽度是4,红色卷积核的宽度是5,它们的长度与词向量的长度是一致的,例如图中紫色卷积核卷积的输入由图中紫色的圆点表示. 卷积核可以看作是不同长度短语的特征提取器,使得整个卷积过程可以提取语句局部的语义特征. 卷积过程的步长均为1. 而所有卷积核的卷积输出均是一个向量,最大池化层对卷积输出的结果进行池化. 池化的宽度分别是每个卷积核卷积输出向量的长度,这样就把每个卷积核卷积的输出池化成为一个点,最终整个CNN所提取特征的维度就是所有卷积核的个数. 将此实现语句语义映射的CNN程序记作sCNN,其以语句为输入,输出为Rk中向量,则对任意的s∈S有:

sCNN在提取语句特征方面具有如下优势: 一是所提取语句特征的维度仅取决于卷积核的个数,而与语句的长度无关; 二是卷积和池化操作考虑了语句的序列与结构的信息,因而很容易处理词汇量很大的数据集,而输出的维度不依赖于词汇量的大小.
3.4 基于最大软间隔的图片语句对匹配得分学习
函数f以图片和语句在公共空间Rk中的映射为输入计算图片语句对的匹配得分. 具体的,IRMatch模型将f视作超参数并选用余弦相似度函数作为f来计算匹配得分,即:

在此基础上,定义如下排序损失函数L:
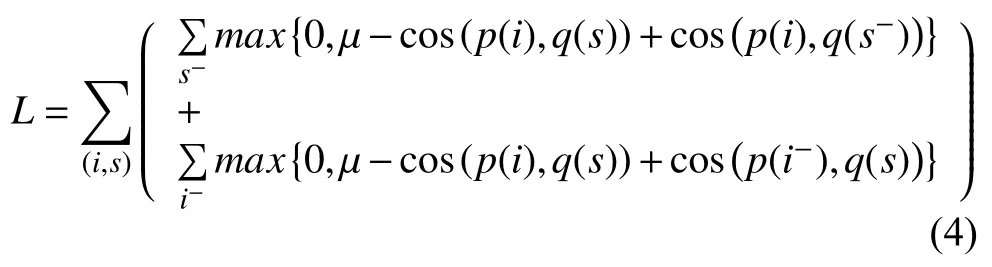





而基于最大软间隔学习的损失函数定义如下:


4 实验
本文在Flickr8k[5]、Flickr30k[8]以及Microsoft COCO[7]数据集上进行了图文双向检索任务的实验,以将所提图片语句匹配模型与文献[1-4,6,10-14,23-28]所提出的模型进行了比较.
4.1 实验设置
4.1.1 数据集
本文选择如下公开图片语句基准数据集进行图文双向检索任务的实验.
(1) Flickr8K[5]: 此数据集由采自 Flickr的 8000 张图片组成,每张图片对应5句描述图片内容的语句. 此数据集提供了标准的训练集、校验集以及测试集划分.
(2) Flickr30K[8]: 此数据集由采自 Flickr 的31783张图片组成,每张图片对应5句描述图片内容的语句. 其中大部分图片的内容与人类活动有关. 本文采用和[28]中相同的划分方法划分训练集、校验集以及测试集.
(3) Microsoft COCO[7]: 此数据集包含 82783 张训练图片以及40504张校验图片. 每张图片对应5句描述图片内容的语句. 本文采用和文献[26]中相同的划分方法来划分训练集,校验集以及测试集.
4.1.2 评价指标
本文采用Med r与R@K评价图文双向检索的结果[10]. Med r表示与查询最相关的结果在结果列表中的平均排名,其值越小越好. R@K(K=1,5,10)表示在前K个结果中出现正确结果的百分比,其值越大越好.
4.1.3 参数设置
在训练过程中,本文采用公式(9)定义的损失函数. 训练batch-size设为250,即每一次从数据集中采样250对不同的相关图片-语句对,对于每一张图片本文获得249与之不相关的语句,同理对于每一个语句本文也可以获得249个与之不相关的图片. 使用Adam优化算法训练25-40个epochs,并且设置初始学习率为0.001,采用提前停止策略防止训练过拟合. 公共空间的维度k设置为1200,词向量的维度设置为300,间隔m的值设置为0.5. 这些超参数,包括学习率以及batch-size,都是通过校验集进行选择的.
4.2 实验结果分析
我们分别实现了IRMatch模型采用最大硬间隔策略 (记为IRMatchH)与最大软间隔策略(记为IRMatchS)时的图文双向检索方法,之后在数据集Flickr8k、Flickr30k 以及 Microsoft COCO 上,计算所实现的图文双向检索方法的Med r与R@K(K=1,5,10),并与文献[1-4,6,10-14,23-28]所提出的方法在上述三个数据集上的结果进行对比,分别如表2,表3,表4所示.
4.2.1 IRMatchH 与已有方法比较
总体来看,基于IRMatchH的检索方法的结果优于基于已有图片语句匹配方法的检索方法的结果. 尤其是在Flickr30k数据集上,所有指标均优于已有方法.这说明CNN能够有效的提取语句的语义信息. 本文采用sCNN来对语句进行特征建模,使用了宽度为1到6的卷积核. 应用了不同宽度的多个卷积核,相当于可以提取蕴含1到6个词的短语蕴含的语义信息. 除了具有提取不同长度短语的能力,该模型还能考虑到语句语序信息以及结构信息. 池化层中的最大池化操作能够对上述语义信息进行筛选. 将语句和图片映射到同一空间中后,使用余弦相似度在公共空间Rk中直接计算语句和图片之间的相似度,从而完成两者之间的关联.
Flickr8K数据集上,FV[12]在语句检索(以图片检索语句)任务中R@1指标略高于IRMatchH的结果,除此之外,两者在各个指标上均取得了最好的结果. 这说明当训练数据不是很充分的时候,本文的模型依然能够很好地对语句和图片进行建模,并且完成两者之间的匹配. 而当数据充分时,在Flickr30k以及Microsoft COCO数据集上,IRMatchH远好于FV[12]的结果.IRMatchH在这三个数据集上的试验结果有效的证实了CNN在提取语句语义信息方面的优越性.
4.2.2 IRMatchS 与 IRMatchH 比较
从表2,表3,表4 可以看出,IRMatchS 的结果好于IRMatchH的结果,尤其是在Microsoft COCO数据集. 这组对比试验表明最大软间隔的学习方式能够有效的解决图片语句非对称匹配问题. 本文采用公式(9)作为训练模型中的损失函数,引入松弛变量将硬间隔转变成软间隔. 由于Flickr8K、Flickr30K以及
Microsoft COCO这三个数据集中图片和语句之间语义之间并非是对等关系,而是一种蕴含关系,并且描述同一图片的语句语义之间存在不相似或者弱相似的情况.因此,若采用硬间隔(IRMatchH)的方式将彼此之间不相似的语句投影在公共空间Rk中的点,无法都临近对应图片的映射点,必然导致某些语句和图片没有匹配在一起. 而采用软间隔的方式,容忍一定的偏差,可以将图片和不同语义的语句关联在一起,因此可以提高匹配的性能以及泛化能力. 对比IRMatchS以及IRMatchH在上述三个数据集上的实验结果,可以佐证这种软间隔(IRMatchS)的学习策略能够很好的解决图片和语句之间的语义非对等问题.
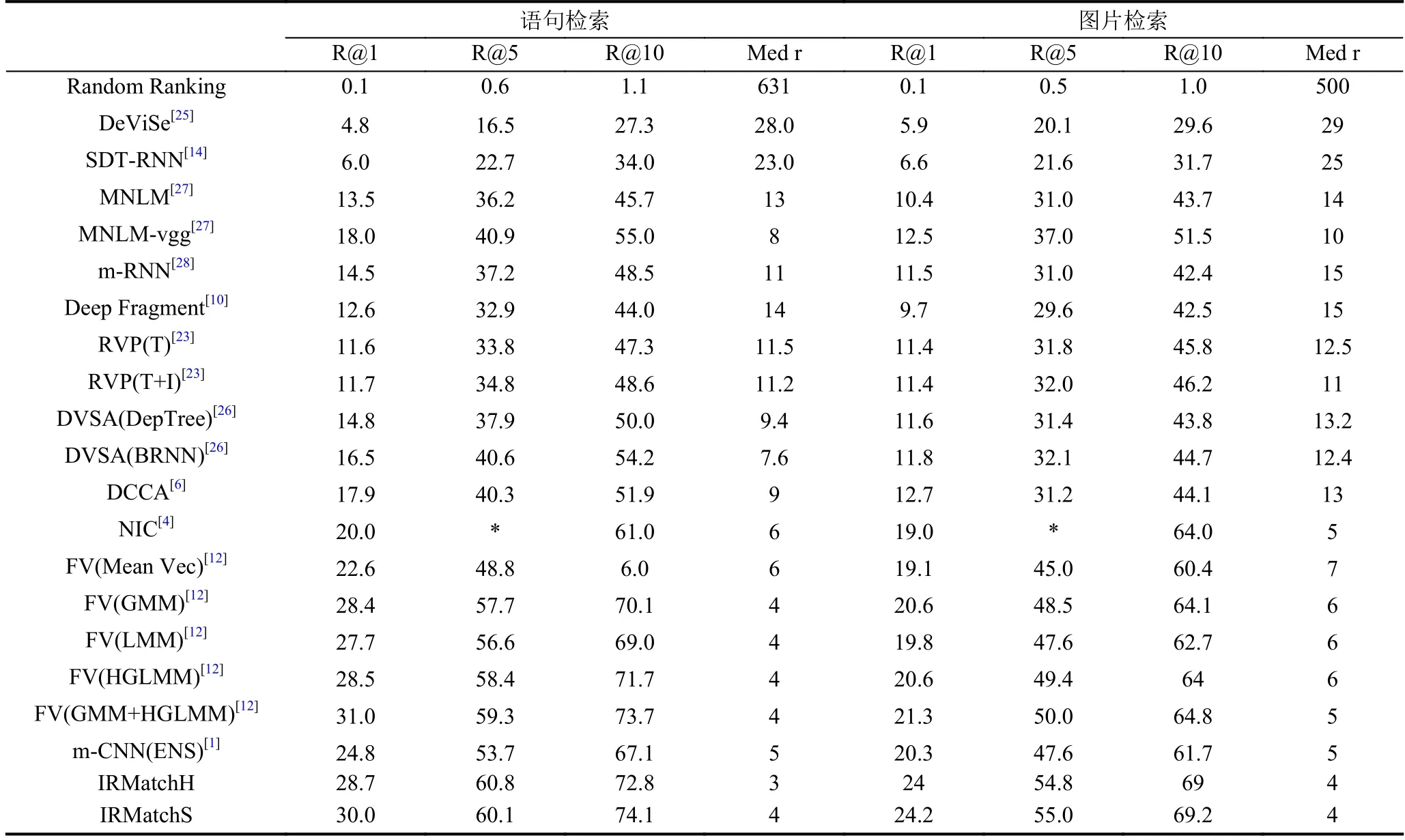
表2 Flickr8k 数据集上图文双向检索比较结果
5 结束语
本文提出一种新的基于语义蕴含关系的图片语句匹配模型IRMatch,能够很好的解决图片和语句语义之间的非对等匹配问题. 该模型使用两种不同的卷积神经网络iCNN与sCNN来对图片以及语句进行语义映射,从而将两者投影到同一公共空间Rk中,有利于两种不同模态数据的直接比较,而且模型采用最大软间隔的学习策略来学习图片语句之间的匹配得分,强化了相关图片语句对在公共语义空间中位置的邻近性,改善了图片语句匹配得分的合理性. 本文分别在 Flickr8K,Flickr30K 以及 Microsoft COCO 数据集上进行了实验,实验表明基于所提IRMatch模型的图文双向检索方法的结果优于基于已有模型的检索方法的结果.
未来我们将重点针对语句对应多个图片的语句图片蕴含关系的模型进行研究.

表3 Flickr30k 数据集上图文双向检索比较结果

表4 Microsoft COCO 数据集上图文双向检索比较结果
1Ma L,Lu ZD,Shang LF,et al. Multimodal convolutional neural networks for matching image and sentence. Proc. ofthe 2015 IEEE International Conference on Computer Vision(ICCV). Santiago,Chile. 2015. 2623–2631.
2Mao JH,Xu W,Yang Y,et al. Deep captioning with multimodal recurrent neural networks (m-RNN). Proc. of the International Conference on Learning Representations. San Diego,USA. 2015.
3Vendrov I,Kiros R,Fidler S,et al. Order-embeddings of images and language. Proc. of the International Conference on Learning Representations. San Juan,Puerto Rico. 2016.
4Vinyals O,Toshev A,Bengio S,et al. Show and tell: A neural image caption generator. Proc. of the 2015 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Boston,MA,USA. 2015. 3156–3164.
5Hodosh M,Young P,Hockenmaier J. Framing image description as a ranking task: Data,models and evaluation metrics. Journal of Artificial Intelligence Research,2013,47(1): 853–899.
6Yan F,Mikolajczyk K. Deep correlation for matching images and text. Proc. of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston,MA,USA.2015. 3441–3450.
7Lin TY,Maire M,Belongie S,et al. Microsoft COCO:Common objects in context. Proc. of the 13th European Conference on Computer Vision. Zurich,Switzerland. 2014.740–755.
8Young P,Lai A,Hodosh M,et al. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Trans. of the Association for Computational Linguistics,2014,2(4): 67–78.
9Mueller J,Thyagarajan A. Siamese recurrent architectures for learning sentence similarity. Proc. of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16). Phoenix,Arizona,USA. 2016. 2786–2792.
10Karpathy A,Joulin A,Li FF. Deep fragment embeddings for bidirectional image sentence mapping. Proc. of the 27th International Conference on Neural Information Processing Systems. Montreal,Canada. 2014. 1889–1897.
11Kiros R,Zhu YK,Salakhutdinov R,et al. Skip-thought vectors. Proc. of the 28th International Conference on Neural Information Processing Systems. Montreal,Canada. 2015.3294–3302.
12Klein B,Lev G,Sadeh G,et al. Associating neural word embeddings with deep image representations using Fisher Vectors. Proc. of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston,MA,USA.2015. 4437–4446.
13Plummer BA,Wang LW,Cervantes CM,et al. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. Proc. of the 2015 IEEE International Conference on Computer Vision (ICCV).Santiago,Chile. 2015. 2641–2649.
14Socher R,Karpathy A,Le QV,et al. Grounded compositional semantics for finding and describing images with sentences. Trans. of the Association for Computational Linguistics,2014,2(4): 207–218.
15Wang J,He YH,Kang CC,et al. Image-text cross-modal retrieval via modality-specific feature learning. Proc. of the 5th ACM on International Conference on Multimedia Retrieval. New York,NY,USA. 2015. 347–354.
16He KM,Zhang XY,Ren SQ,et al. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. Proc. of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago,Chile. 2015.1026–1034.
17Krizhevsky A,Sutskever I,Hinton GE. ImageNet classification with deep convolutional neural networks. Proc. of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe,Nevada,USA. 2012.1097–1105.
18Simonyan K,Zisserman A. Very deep convolutional networks for large-scale image recognition. Proc. of the International Conference on Learning Representations. San Diego,USA. 2015.
19Szegedy C,Liu W,Jia YQ,et al. Going deeper with convolutions. Proc. of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston,MA,USA.2015. 1–9.
20Kim Y. Convolutional neural networks for sentence classification. Proc. of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha,Qatar. 2014. 1746–1751.
21Kingma DP,Ba J. Adam: A method for stochastic optimization. Proc. of the International Conference on Learning Representations. Banff,Canada. 2015. 1–13.
22Dahl GE,Sainath TN,Hinton GE. Improving deep neural networks for LVCSR using rectified linear units and dropout.Proc. of the 2013 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). Vancouver,BC,Canada. 2013. 8609–8613.
23Chen XL,Zitnick CL. Mind’s eye: A recurrent visual representation for image caption generation. Proc. of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston,MA,USA. 2015. 2422–2431.
24Donahue J,Hendricks LA,Guadarrama S,et al. Long-term recurrent convolutional networks for visual recognition and description. Proc. of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston,MA,USA.2015. 2625–2634.
25Frome A,Corrado GS,Shlens J,et al. DeViSE: A deep visual-semantic embedding model. Proc. of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe,Nevada,USA. 2013. 2121–2129.
26Karpathy A,Li FF. Deep visual-semantic alignments for generating image descriptions. Proc. of the 2015 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Boston,MA,USA. 2015. 3128–3137.
27Kiros R,Salakhutdinov R,Zemel RS. Unifying visualsemantic embeddings with multimodal neural language models. arXiv: abs/1411.2539,2014.
28Mao JH,Xu W,Yang Y,et al. Explain images with multimodal recurrent neural networks. arXiv: abs/1410.1090,2014.
Image Sentence Matching Model Based on Semantic Implication Relation
KE Chuan,LI Wen-Bo,WANG Mei-Ling,LI Zi
(Institute of Software,Chinese Academy of Sciences,Beijing 100190,China)
In this paper,we propose a model called IRMatch for matching images and sentences based on implication relation to solve the nonequivalent semantics matching problem between images and sentences. The IRMatch model first maps images and sentences to a common semantic space respectively by using convolutional neural networks,and then mines implication relations between images and sentences with a learning algorithm by introducing maximum soft margin strategies,which strengthens the proximity of locations of related images and sentences in the common semantic space and improves the reasonability of matching scores between images and sentences. Based on the IRMatch model,we realize approaches of bidirectional image and sentence retrieval,and compare them with approaches using existing models for matching images and sentences on datasets Flickr8k,Flickr30k and Microsoft COCO. Experimental results show that our retrieval approaches perform better in terms of R@1,R@5,R@10 and Med r on the three datasets.
nonequivalent match between images and sentences; implication relation; maximum margin learning; bidirectional image and sentence retrieval; convolutional neural network
柯川,李文波,汪美玲,李孜.基于语义蕴含关系的图片语句匹配模型.计算机系统应用,2017,26(12):1–8. http://www.c-s-a.org.cn/1003-3254/6130.html
国家“863”项目 (2013AA01A603)
2017-03-22; 修改时间: 2017-04-13; 采用时间: 2017-04-24
猜你喜欢
文萃报·周二版(2022年3期)2022-01-20
计算机研究与发展(2022年1期)2022-01-19
计算机应用(2020年12期)2020-12-31
小学生学习指导(低年级)(2019年3期)2019-04-22
文苑(2015年9期)2015-09-10
读写算·小学低年级(2014年4期)2014-07-24
海外英语(2013年9期)2013-12-11
海外英语(2013年10期)2013-12-10
新课程学习·中(2013年3期)2013-06-14
小雪花·成长指南(2009年10期)2009-12-04
