
基于联合非负矩阵分解的话题变迁检测方法
2018-01-19 00:52,,
计算机工程 2018年1期
, ,
(1.华东师范大学 计算机科学与技术系,上海 200241; 2.上海长江计算机有限公司,上海 200241)
0 概述
近年来,互联网新闻报道平台(如LexisNexis、Google新闻和GDELT)已经成为用户观察新闻话题变迁趋势的重要来源。然而,这种新闻语料库面临着信息冗余的问题,特别是针对同一事件的内容的重复报道和新闻之间的互相转载报道,造成了读者对互联网新闻事件的阅读困难。关注话题变迁对人们理解和分析社会事件发展趋势有着积极的意义。话题变迁是指一个话题随着时间变化的过程,一般包含话题提出、话题发展、话题减少和话题消失等4个阶段[1]。在话题变迁过程中,话题的内容通常随时间的变化而改变,即时序文档中包括相似话题和异同话题。因此,识别异同话题及其发生时刻是一个挑战性的任务。
与本文研究相关的是话题发现和演变(Topic Discovery and Evolution,TDE)任务。之前关于TDE的研究工作大多是采用了聚类算法,例如k-means、层级聚类和DBSCAN[2]等。然而,这些方法的准确率较低。近年来,为提高话题发现的准确性,LDA(Latent Dirichlet Allocation)模型和改进的LDA模型被引入到TDE任务中[3]。这些方法主要利用LDA去构建动态话题模型[4]或者判别式话题模型[3],或将LDA与时间上下文特征相结合[4]。其他基于LDA改进的话题模型,例如Link-LDA[5]、关系话题模型[5]和LTECS模型[6],是在LDA模型中添加地理信息或者上下文背景信息等特征元素来提高话题发现的准确率。因为聚类的质量会随着特征矩阵的维度的增加而减小[7],所以上述方法具有以下问题:1)LDAs相关方法不适合从时序文档中发现异同话题,其原因是随着时间发展,旧话题消失和新的话题出现;不同的时间范围内话题的数量也是不同的,上述原因对话题发现的效果影响很大。2)因为LDAs的时间复杂度与话题数和词袋中词语数的乘积呈线性关系,所以LDAs方法在用于大规模文档的话题提取任务时具有较高的时间复杂度。
近年来,非负矩阵分解(Nonnegtive Matrix Factorization,NMF)及其扩展算法被引入TDE任务[6,8-9]。NMF是一种非监督机器学习算法,能够自动挖掘大规模文档集中的话题[10]。与概率话题模型(例如LDA、PLSI)相比,NMF将原始数据矩阵分解为2个子矩阵,并通过平行学习得到各子矩阵的解。因此,比其他概率模型具有更好的可扩展性。文献[5]提出了基于NMF的正则化的共享空间迁移的方法,对2个相关的文档集进行联合建模。设置严格的共享空间,相比于其他方法,该方法的灵活性较差。文献[11]提出了具有偏移向量的基因数据集的NMF方法。该方法的思想是提出共同的基因调节模式,每个数据集中稳定的表达层被偏移向量吸收。文献[6]提出一种利用大型语料库中包含的文本信息和社会情景信息来构建非负矩阵分解的模型。文献[12]提出了通过规范化组稀疏方法来发现多个文档集中的相似话题和异同话题的方法。在其随后工作中设计了一种基于联合NMF的话题建模方法(JNMF),可以发现多个文档集中包含的共同和不同的话题[9]。该方法在联合非负矩阵分解的目标函数中引入了2个惩罚函数来判断最相似的话题和最不同的话题。然而,以上研究大多集中在从大规模语料库中检测潜在的话题,这些方法缺乏从时序文档集中识别话题和跟踪分析话题随时间变迁的能力。
为从时序文档语料库中发现异同话题,并跟踪和分析所探测的异同话题随着时间的发展的变迁趋势,本文提出一种基于联合非负矩阵分解的时序异同话题发现方法(Discriminative Topics Discovering Using Joint NMF Algorithm,ToD)。ToD方法包括3个主要部分:特征选择,联合NMF模型和优质话题选择。ToD采用改进的联合非负矩阵分解方法来发现多个文档集中的话题集合,并在话题集合中发现不同文档集之间相似和不同的话题。
1 符号定义

本文所采用的方法是检测来自2个不同时间下的文档集Dt和Dt+1中的所有潜在话题,然后同时从Dt和Dt+1中发现相似话题和异同话题。也就是说,给定大规模的文档语料库,ToD方法首先识别异同话题集(包含c个相同的话题和d个不同的话题),然后追踪同一个话题中的话题词随时间演变的趋势。异同话题发现的关键问题之一是确定相似话题Vc和异同话题Vd在所有话题Vk中的比例。为了解决上述问题,本文设计了一种可以同时分解2个文档集Dt和Dt+1的方法,并且引入2个惩罚函数R1和R2去平衡Vc和Vd所占的比例。
为了便于后续的表述和理解,本文统一使用不带下标的字母来表示各自集合中的任意元素。
2 时序异同话题发现算法
ToD方法的主要流程是:在文档预处理之后,首先从文档中提取特征矩阵。然后利用联合NMF模型发现不同子集中的相似话题和异同话题。最后根据话题发现的结果,从中提取优质话题。
为方便叙述,考虑2个文档集合的情况。假设存在时序文档集合D,将D按照时间划分为2个子集合:D1和D2。例如,实验数据集(LTN2011)中包含了1997年—2011年之间的拉丁美洲非法移民的新闻报道,根据年代将数据集划分为2个子集:第1个子集D1包含从1997年—2004年的所有新闻,而另一个子集D2包含了2005年—2011年的所有新闻。
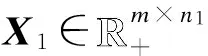
在为文档子集D1和D2构造了2个特征矩阵X1和X2之后,本文使用改进的联合非负矩阵分解算法,分别对这2个特征矩阵进行分解,从而得到相似话题和一同话题。
2.1 改进的联合非负矩阵分解算法
2.1.1 非负矩阵分解算法
X≈W×HT
(1)

由于NMF是NP问题,一般采取迭代计算2个矩阵W和H的方法来求得2个矩阵的解。代表的求解方法是采取梯度投影法来计算矩阵W和矩阵H。虽然梯度投影法不能收敛到全局最优,但是相比其他的迭代算法,有着良好的优化性能[13]。梯度投影法通过计算矩阵X与矩阵W和H的乘积的欧几里得距离来测量近似度,目标方程定义为,
(2)
在矩阵分解的过程中,矩阵中的每个元素只有非负值。矩阵X中的列向量可以解释为矩阵W中所有列向量和矩阵H的分量的线性加权和。因此,W的列向量也称为基向量,W也被视为基矩阵,而权重系数对应于作为系数矩阵H中的列向量的元素。这种基于基向量组合的表示形式具有视觉语义上的可解释性,它反映了零件构成整体的概念。此外,基于简单迭代的NMF方法具有收敛速度快,非负矩阵存储空间小和语义解释性强的优点,因此,它适用于处理大规模文本的话题发现。但是,NMF的工作在处理具有时间属性的多个文档集的问题上关注较少。例如,标准NMF方法,它只能从单个文档集中发现话题,但是无法同时处理多个文档集。因此,标准NMF不能处理多个文档中的话题同时发现的问题。
本文提出一种改进的联合非负矩阵分解算法(NJNMF),通过使用联合NMF算法与惩罚函数,可以从多个数据集中提取异同话题。
2.1.2 改进联合非负矩阵分解算法描述
在对文档集中的文档进行预处理和特征选择之后,得到2个特征矩阵X1和X2。本文利用NJNMF算法同时分解2个矩阵X1和X2,公式如下:
(3)
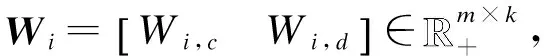
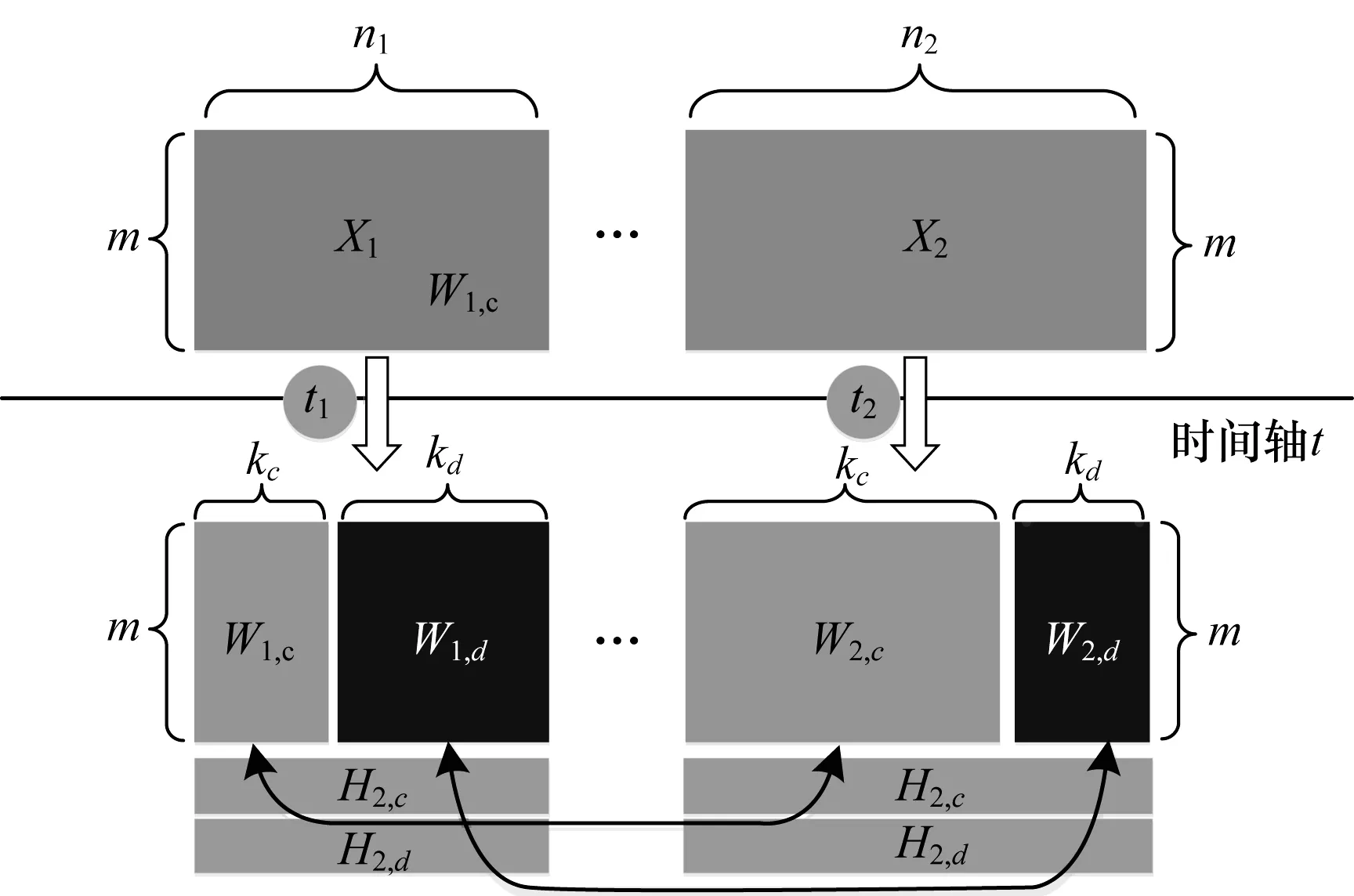
图1 NJNMF算法分解过程示意图
在联合矩阵分解中,本文引入2个惩罚函数R1(W1,c,W2,c)和R2(W1,d,W2,d)到联合矩阵分解过程中,这2个惩罚函数分别代表不同文档集中话题的相似性和差异性。通过这2个惩罚函数,就可以控制矩阵分解后的基矩阵Wi的结果,目标函数为:
ω1R1(W1,c,W2,c)+ω2R2(W1,d,W2,d)
(4)
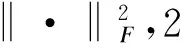
图1显示了改进的联合NMF算法的迭代过程。首先,从2个文档集D1和D2之间获取相似话题和异同话题Vc和Vd,即话题Vk=Vc+Vd是从基矩阵Wi中发现的,基矩阵Wi中的第i列向量也就是话题V中的第i个话题,记为Si,且有k=c+d。其次,基于基矩阵Wi的结构,每个Si都是由m个话题词组成。然后,将第i个话题中的在第j个话题词记为TiWj,这意味着TiWj代表着其话题类别中的特定话题词语。因此,最终可以从2个文档集中得到所有相似和不同的话题以及每个话题所包含的话题词。
2.1.3 惩罚函数
为了得到方程的最优解,首先定义2个惩罚函数R1和R2,公式如下:
(5)
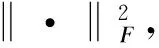
根据式(5),在矩阵分解的过程中,文中利用最小化基矩阵W1和W2元素之间的平方差来聚类相似的话题。在式(5)中,W1,d×W2,d中的第(i,j)个元素表示矩阵W1和W2的内积的值,即W1中第i个话题向量和W2中第j个话题向量的乘积。因此,式(5)中的SFt就表示矩阵W1,d和W2,d之间的所有列向量的内积。其中R2(W1,d,W2,d)中的部分元素的数值将变为零,这样就可以让每一个话题词只能对应于一个话题类别。通过迭代计算,可以在2个数据集之间找到更多的异同话题。然后利用式(5)来计算式(4),得到最终的目标函数:
ω1NFt(W1,c-W2,c)+ω2SFt(W1,d×W2,d)
(6)
2.2 优化算法
为了在文档集D1和D2之间得到最优的k值来发现相似和异同话题,本文选择了块坐标下降法[13]来求解式(6)。该迭代算法具有3个部分:1)最小化惩罚函数R1(W1,c,W2,c)来计算2个矩阵W1,c和W2,c的值,它们表示2个数据集D1和D2的相似话题。2)最小化惩罚函数R2(W1,d,W2,d)来计算2个矩阵W1,d和W2,d的值,这2个矩阵代表的是文档集D1和D2之间的异同话题。3)为参数ω1和ω2选择适当的值以平衡2个惩罚函数R1(W1,c,W2,c)和R2(W1,d,W2,d)的权重比例。该迭代算法的主要思想是:坐标下降法并不是寻求整个变量的梯度,而是沿着变量的每个维度单变量的进行循环地优化。如果函数在当前迭代中未优化,则表明已达到其驻点。因此,该算法可以保证每个极值点就是一个驻点。
大多数近似算法分别计算矩阵W和H。本文将矩阵Wi和Hi的乘积作为基组,利用式(7)计算Wi×Hi的值:
(7)
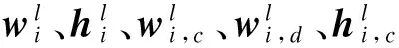
ToD算法的目标是通过迭代更新Wi×Hi中的向量的值,直到获得最优解。为了在迭代过程中得到式(6)中的参数值,本文定义以下迭代规则,公式如下:
(8)
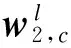
算法1改进的联合NMF算法

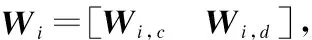
3.end for
4.repeat
5.Update Wi,Hiusing Eq.(8)
6.ComputeR1(W1,c,W2,c)using Eq.(5);
7.ComputeR2(W1,d,W2,d)using Eq.(5);
8.repeat
12.until Update Hiusing Eq.(7);
13.until Stop criteria threshold;
14.End
在算法1中,n1和n2代表的是文档集D1和D2中包含的文档的数目,矩阵X1和矩阵X2分别是文档集D1和D2所构建的特征矩阵,参数ω1和ω2是用于控制惩罚函数的权重,n1和n2分别表示2个文档集中的文档数目,m代表的是D1和D2中的词袋中所有的词语的数目。
2.3 算法分析
标准NMF算法采用的是基于迭代计算的优化方法[14],算法的时间开销主要用于矩阵之间的相乘计算,其时间复杂度取决于待处理的语料库的大小,达到稳定点时平均的迭代的次数,时间复杂度为O(tmnk),其中,m为词袋中词语的数量,n为文档数量,k为话题数量,t是平均迭代次数。
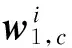
2.4 优质话题选择
为了确定所获得的话题是否为优质话题,本文通过测量话题熵(TE)来提取优质话题:
(9)
其中,p(θ|S)表示话题词θ出现在话题S下的概率。当话题熵的值越大时,话题S越可能是噪声话题。使用式(9)计算每个话题的话题熵,预先设定一个话题熵阈值g,所有小于阈值g的话题熵所对应的话题S被视为优质话题。
3 实验与结果分析
为了评估本文提出的方法,本文进行了2组实验:第1组实验来评估ToD话题发现的效果;第2组实验使用拉丁美洲非法移民数据(LTN2011)来发现随着时间变化,人们所关注的相似话题和异同话题的变迁趋势。所有实验均在具有2.7 GHz CPU和32 GB主存储器的戴尔服务器上进行。
3.1 实验数据集
本文使用2个数据集进行实验,分别是20Newsgroups[9]和LTN2011。
20Newsgroups:20Newsgroups数据集是由20个新闻组,大约20 000个新闻文档构成的,所占硬盘空间近62 MB。该数据集最初由Ken Lang收集,是新闻事件的文档集合。近年来,20Newsgroups已经越来越受到话题发现文本聚类实验的欢迎。 20个新闻组的统计信息如图2所示。

图2 20 Newsgroups数据集的统计信息
LTN2011:从LexisNexis中收集并构建了LTN2011数据集。LexisNexis是世界上最大的新闻媒体之一,其中包含美国主要新闻媒体的新闻报道(如纽约时报和华盛顿时报)。利用查询词“illegal”“ immigrant”作为关键词来搜索LexisNexis,这样就得到了从1997年—2011年间关于非法移民问题的所有新闻报道数据。 LTN2011数据集有13 039篇文章,大小为40 MB。是按照平均每年有大约900份的数目收集的新闻报道,以确保新闻数据的平衡性。图3显示了该数据集的统计信息。
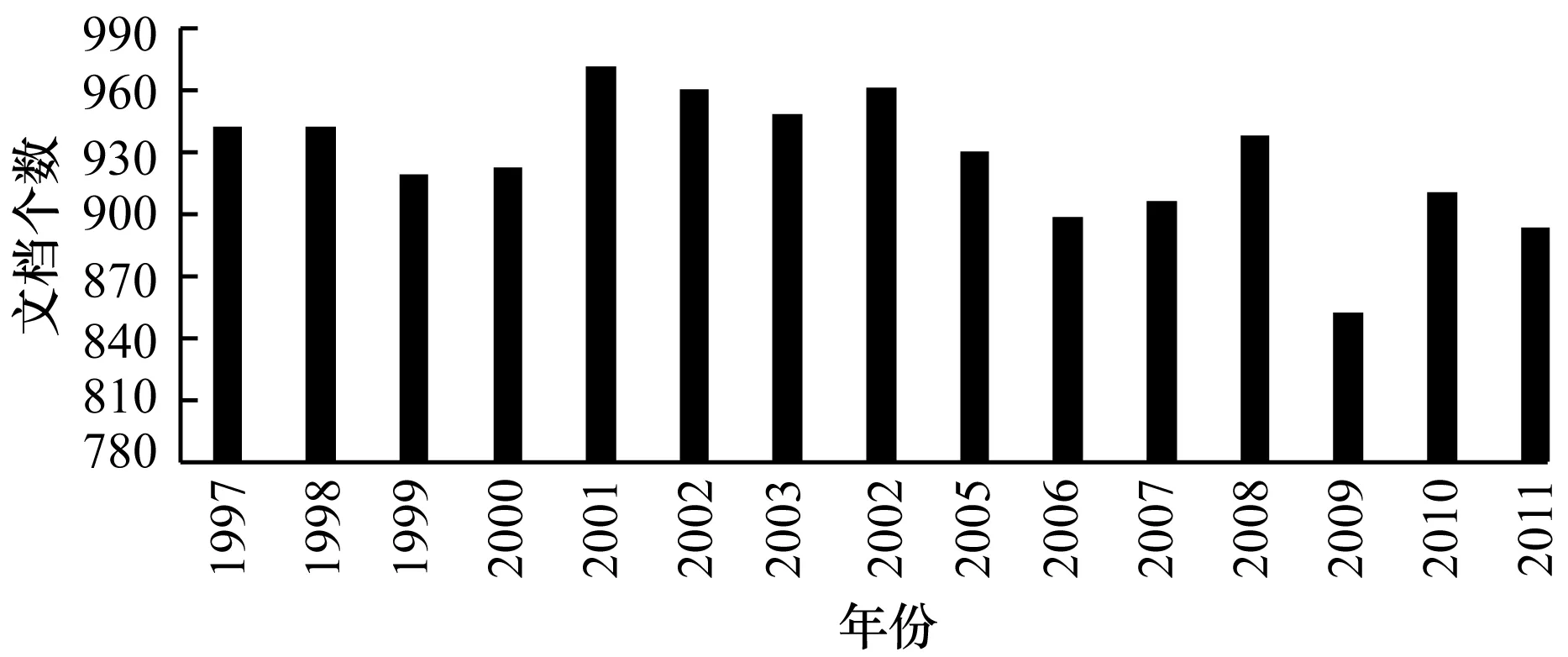
图3 LTN2011数据集的统计信息
3.2 评估指标
本文使用2个常用的度量指标来评估话题发现的结果,分别是准确度(AC)和归一化互信息(NMI)[15]。假定文本样本分别用样本提供的标签来表示,即αi、γi、si,公式如下:
(10)
其中,n是样本文本的数量,在函数δ(x,y)中,当x等于y时,函数δ(x,y)的值为1;否则函数为0。排序映射函数map(γi)的作用,是将样本γi的每个标签都映射到等效的标签上。
本文还使用NMI方法来评估话题提取的效果。NMI方法优于纯度(purity)和熵(entropy)的方法,它可以消除由聚类结果簇个数的不同,对评价聚类结果产生的影响。NMI的值越接近1,表明聚类结果越好。NMI的公式如下:
(11)
其中,C表示样本聚类的实际结果,C′表示由该算法获得的聚类结果,H(C)和H(C′)分别表示C和C′的熵,由式(11)可知,NMI(C,C′)值的变化范围在0~1之间。当C和C′完全相同时,NMI(C,C′)等于1;当C和C′相互独立时,NMI(C,C′)等于0。
3.3 实验设计与分析
实验设计与分析过程如下:
1)20Newsgroups实验结果分析。本文比较了ToD与其他6个话题发现算法在20Newsgroups数据集上的实验结果,分别是LDA[16]、NMF[8]、GNMF[17]、CNMF[17]、LLRNMF[18]和JNMF[9]。后5种方法的实验结果源自文献[9,19]。所有方法的准确度和NMI的实验结果如图4所示,其中,整个矩形是指算法在该指标上的最大值,矩形下部的实心部分是指算法的最小得分,而矩形上部的阴影部分是算法在该指标上的最大得分和最小得分之间的差。
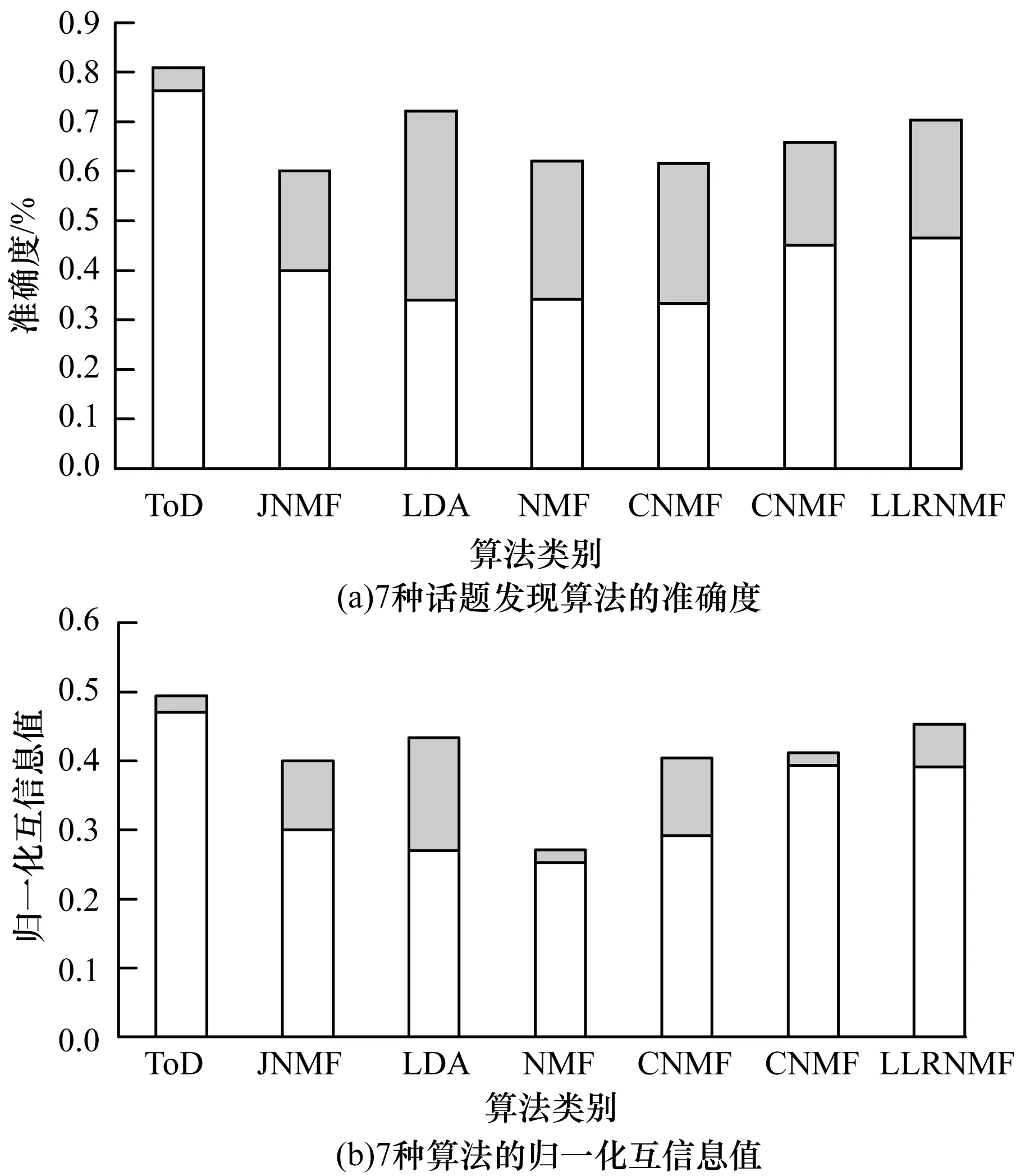
图4在20Newsgroups数据集上7种算法的准确度和归一化互信息值
图4显示ToD算法在准确度和NMI上均胜过其他6种方法。其中,标准NMF算法的准确度最低。从图4中可以看到,ToD方法的准确度和NMI值(80%和0.5)均优于JNMF方法(60%和0.4)[9]。进一步调查表明:JNMF方法的目标是发现2个单独文档集之间的共同和不同话题,而ToD方法通过将时间参数t引入到NFt和SFt中,以改进矩阵迭代计算期间的惩罚函数的值。这样就可以比较在不同时间戳下的多个文档集之间的相似话题矩阵和异同话题矩阵。因此,ToD可以发现并跟踪多个文档集之间的时序异同话题。由于同样的原因,JNMF对多个文档集中的话题的连续性考虑较少,这降低了话题提取的准确性。
本文进一步比较和分析了不同k值下的实验结果,如图5所示,从左到右分为LDA、NMF、GNMF、CNMF、LLRNMF和ToD算法的NMI指标。图5显示了在所有方法的NMI指标中,ToD的方法优于其他方法,当增加话题数k时,其他5个算法的NMI值明显减小,而ToD算法在不同k值的情况下依然保持着稳定的值。标准NMF获得最低的NMI得分,是因为该方法较少的使用了文档集中的标签信息,从而导致聚类效果较差。 CNMF是一种半监督算法,它使用样本数据的类别信息作为输入约束。通过将类似的样本数据从高维度投影到低维度,保持样本信息的一致性,所以具有比NMF更好的聚类效果。但是CNMF忽略样本数据结构的信息[20-21],LLRNMF不仅使用样本数据信息的结构,还使用样本数据中的识别信息,所以它具有比GNMF更好的结果。
图5 20Newsgroups数据集上6种算法的NMI评估结果
2)LTN2011实验数据分析。本文使用ToD算法来处理LTN2011数据集,并将1997年—2011年期间关于拉丁美洲非法移民的话题变迁趋势可视化。
(1)数据准备。本文使用以下步骤处理原始新闻数据:首先从文本中移除属性的标签,例如报道字数、作者、出版商等,只保留新闻标题及其新闻正文部分。然后对标题和内容进行了以下预处理,使用了POS过滤、停止词过滤、位置标记和词干预处理等。其次根据它们的出版日期,将LTN2011文档集分为两部分,分别是1997年—2004年和2005年—2011年。从2个文档集中提取特征可以得到2个输入矩阵X1和X2。最后在2个矩阵X1和X2上使用ToD方法来获得1997年—2004年和2005年—2011年之间相似话题和异同话题的结果,并在优质话题选择之后分析话题变迁趋势。
(2)参数选择。为了在不同k值下,得到话题发现的最佳结果,本文通过设置不同的控制参数ω1和ω2来寻找合适的参数值。在LTN2011数据集上显示不同参数的实验结果如图6所示。可以看出,ToD算法在k=10时获得最好的聚类效果。而且当k值从1变到10时,ToD算法的NMI保持稳定。
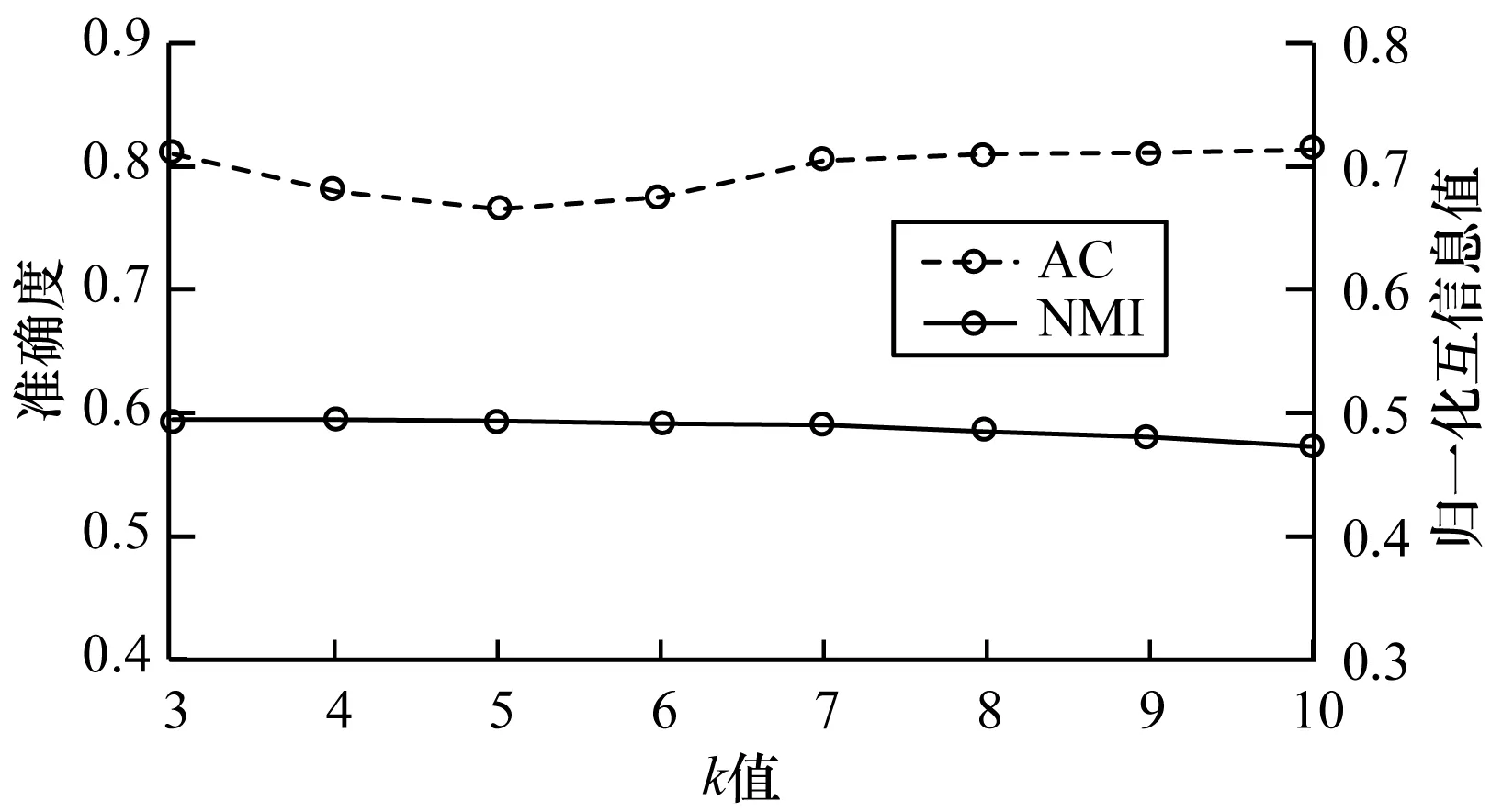
图6ToD算法在LTN2011数据集上的准确度和归一化互信息评估结果
3.4 案例分析
本文分析了1997年—2004年和2005年—2011年2个时间范围每年的拉丁美洲威胁事件的话题演变。通过使用ToD算法,本文从LTN2011文档集中提取相似和异同话题及其话题词。下文通过使用词云和折线趋势图的方式来显示所有发现的话题内容及话题的变迁趋势。图7展示出了4个相似话题的每年的变迁趋势示例。每个折线图部分都表示与拉丁美洲移民事件相关的相似话题的变迁。词云中的话题词的大小表示公众对该话题词语的关注程度。根据图7可以得知拉丁美洲非法移民原有话题的变迁趋势和新兴话题的出现情况,可以看出,移民相关话题分布的峰值在2005年—2006年。话题的峰值主要来源于限制性移民法的颁布。在2004年—2006年期间,国会通过了更严格的移民法。

图7 相似话题的变迁趋势示意图
3.4.1 非法移民话题分析
图7(a)和图7(d)从2个角度展示了非法移民的最相关话题词:公民合法性和就业合法性。这2个话题词在非法移民问题的关注中的有着一致性的变迁趋势。图7(a)表明,公众通常关心移民问题的合法性,他们使用了诸如“Legally(合法)”“illegally(非法)”“deadline(最后期限)”“deport(驱逐)”等话题词来描述移民问题,“legitimacy(合法性)”话题的讨论在2004年达到顶峰。图7(d)中的话题词为“license(许可证)”“industry(工业)”“laborer(劳动者)”“housing(住房)”“employment(劳动伤害叙事)”等,表明政府在移民的合法化方面做了大量工作,并帮助新移民居住在美国。图7(c)和图7(b)中出现了一些新兴的话题。图7(c)显示了一个新的相关话题即移民的方式,从“immigrats(移民)”“landing(登陆)”“vessel(船舶)”和“coast(海岸)”等词语中可以看到,人们经常使用交通相关的术语,例如,“ship(船)”“carry(携带)”“island(岛)”“port(港口)”“navy(海军)”“rescue(救援)”,而其中“smuggling(走私)”的关注度更多,这也意味着公众虽然关注移民的方式,但是认为无论何种移民方式,这样的移民都是非法的。图7(b)揭示了“illegal immigration and human trafficking(非法移民和人口贩运)”的相关话题。注意到从1997年到2004年,关注的焦点一直在诸如“smuggle(走私)”、“truck(卡车)” “charge(费用)”“passport(护照)”“death(死亡)”“cargo(货物)”等。虽然在随后的几年(从2004年—2011年),这个话题有更高的关注,但此类话题的变迁趋势与这一时期的人口贩运整体趋势一致,且在2001年达到峰值,然后从2001年到2004年呈减少的趋势。
3.4.2 异同话题的变迁趋势分析
ToD算法还可以分析不同文档集之间异同话题的变迁趋势。如图8所示,可以看到有3种不同字体的话题词:1)刑事定罪的相关话题词(斜体单词);2)联邦政府移民法规的相关话题词(普通字体单词);3)移民经济问题的相关话题词(加粗字体单词)。图8(a)表明,新闻媒体不断着重于移民问题消极方面的报道,即判定拉丁美洲移民问题为刑事犯罪,例如“illegal(非法)”和“crime(犯罪)”等(见图8(a)中的斜体单词)。移民犯罪化的主要后果是监狱人数和驱逐出境人数的增加,体现在话题词“deportation(驱逐出境)”“jail(牢狱)”“prison(监狱)”等(见图8(b)中的斜体字体)。普通字体字体反映了联邦政府关于移民问题的立场,例如“official(官方)”“law(法律)”“enforcement(执行)”等。图8(b)显示了公众对移民问题在经济方面的关注,由诸如“employer(雇主)”“worker(工人)”“economic(经济)”“worker(工作)”(见图8(b)中的加粗字体)等话题词表示。
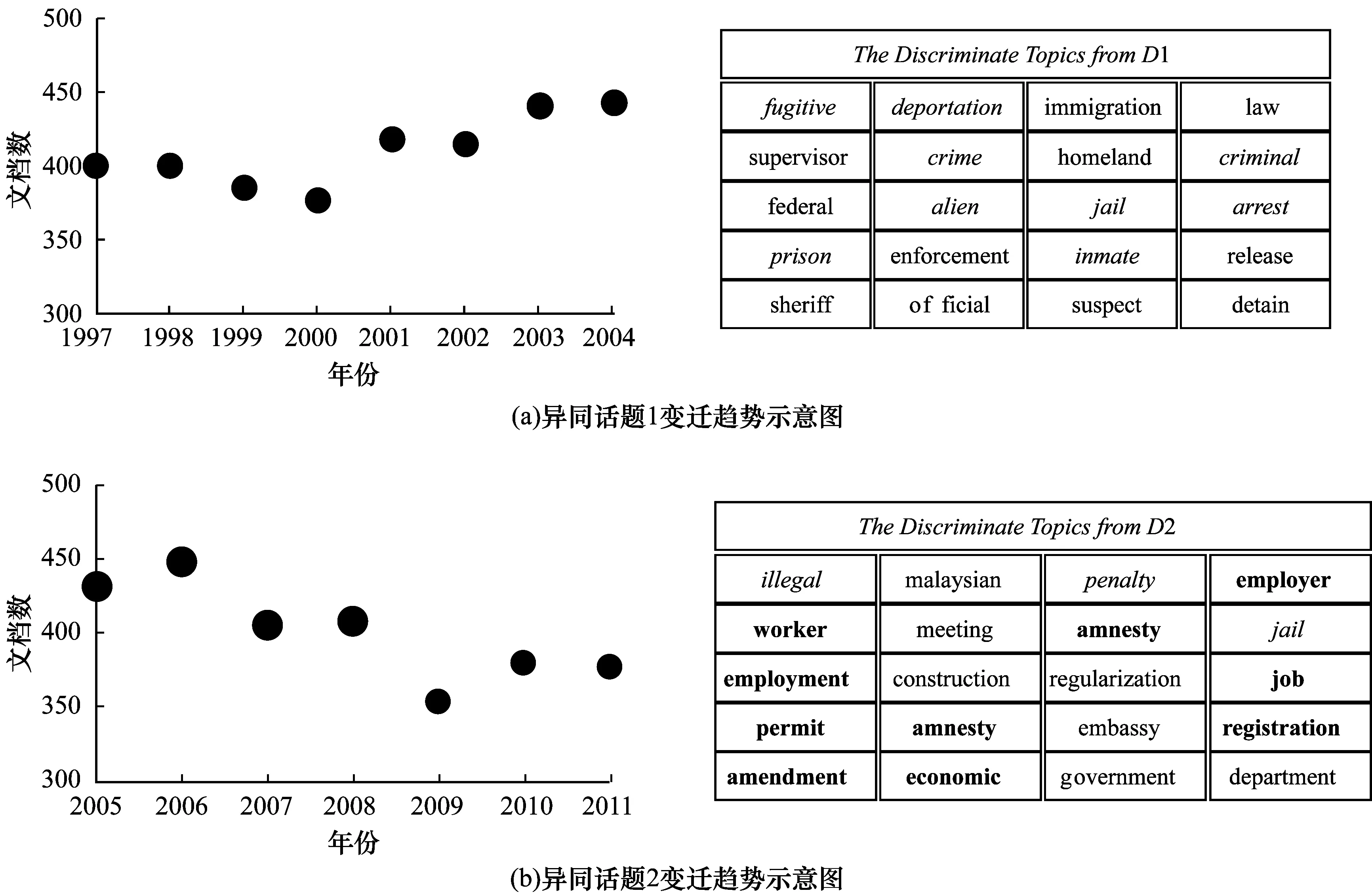
图8 LTN204文档集中2个不同话题的变迁趋势示意图
4 结束语
本文针对大规模时序文档集中异同话题发现问题,提出一种改进的联合NMF算法(ToD)。该算法可以从时序性文档集中同时发现相似和异同话题;然后通过计算所有话题的话题熵,以提取优质话题;接着将这些优质话题可视化,以展示LTN2011的话题变迁的趋势;最后对2个真实的文档集的进行实验。实验结果证明,ToD算法的AC与NMI优于其他6种话题发现算法。下一步将继续优化ToD算法的效率,使其可以支持大规模文档语料库的实时TDE分析的任务。此外,计划建立一个具有可视化功能的TDE系统来展示时序文档集之间的相似话题和异同话题的变迁趋势。
[1] 楚克明,李 芳.基于LDA模型的新闻话题的演化[J].计算机应用与软件,2011,28(4):4-7.
[2] ESTER M,KRIEGEL H P,SANDER J,et al.A Density-based Algorithm for Discovering Clusters in Large Spatial Databases with Noise[C]//Proceedings of KDD’96.Berlin,Germany:Springer,1996:226-231.
[3] JIANG Y,LI X,MENG W.Discword:Learning Discriminative Topics[C]//Proceedings of IEEE/WIC/ACM International Joint Conferences on Web Intelligence and Intelligent Agent Technologies.Washington D.C.,USA:IEEE Press,2014:63-70.
[4] ZHANG H,KIM G,XING E P.Dynamic Topic Modeling for Monitoring Market Competition from Online Text and Image Data[C]//Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2015:1425-1434.
[5] LIU Y,NICULESCU M A,GRYC W.Topic-link Lda:Joint Models of Topic and Author Community[C]//Proceedings of the 26th Annual International Conference on Machine Learning.New York,USA:ACM Press,2009:665-672.
[6] KALYANAM J,MANNTRACH A,SAEZ T D,et al.Leveraging Social Context for Modeling Topic Evolution[C]//Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2015:517-526.
[7] 王 鑫,李 璐,王晓芳.基于 Nyström 谱聚类的词典学习[J].计算机工程与应用,2014,50(6):112-117.
[8] LEE D D,SEUNG H S.Algorithms for Non-negative Matrix Factorization[C]//Proceedings of Advances in Neural Information Processing Systems.[S.1.]:MIT Press,2001:556-562.
[9] KIM H,CHOO J,KIM J,et al.Simultaneous Discovery of Common and Discriminative Topics via Joint Nonnegative Matrix Factorization[C]//Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2015:567-576.
[10] LI Q,CHEN B,MA S,et al.Contrastive Ttopic Evolution Discovery via Nonnegative Matrix Factorization[C]//Proceedings of IEEE International Conference on Communications.Washington D.C.,USA:IEEE Press,2016:1-6.
[11] BADEA L.Extracting Gene Expression Profiles Common to Colon and Pancreatic Adenocarcinoma Uing Simultaneous Nonnegative Matrix Factorization[J].Biocomputing,2008,290(13):279-290.
[12] KIM J,MONTEIRO R,PARK H.Group Sparsity in Nonnegative Matrix Factorization[C]//Proceedings of SDM’12.[S.1.]:SIAM Press,2012:851-862.
[13] KIM J,HE Y,PARK H.Algorithms for Nonnegative Matrix and Tensor Factorizations:A Unified View Based on Block Coordinate Descent Framework[J].Journal of Global Optimization,2014,58(2):285-319.
[14] 李 谦.非负矩阵分解及其在高维数据应用中的研究[D].北京:北京交通大学,2014.
[15] ESTEVEZ P A,TESMER M,PEREZ C A,et al.Normalized Mutual Information Feature Selection[J].IEEE Transactions on Neural Networks,2009,20(2):189-201.
[16] BLEI D M,NG A Y,JORDAN M I.Latent Dirichlet Allocation[J].Journal of Machine Learning Research,2003,3(1):993-1022.
[17] LIU H,WU Z,CAI D,et al.Constrained Nonnegative Matrix Factorization for Image Representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(7):1299-1311.
[18] WANG Q,CAO Z,XU J.Group Matrix Factorization for Scalable Topic Modeling[C]//Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval.New York,USA:ACM Press,2012:375-384.
[19] 舒振球,赵春霞.基于局部学习的受限非负矩阵分解算法[J].华中科技大学学报(自然科学版),2015,43(7):82-86.
[20] 杜世强,石玉清,王维兰,等.基于图正则化的半监督非负矩阵分解[J].计算机工程与应用,2012,48(36):194-200.
[21] 蓝 龙.半监督非负矩阵分解算法及其在文本聚类中的应用[D].长沙:国防科学技术大学,2012.
猜你喜欢
光子学报(2022年8期)2022-09-23
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
中国粮食经济(2018年12期)2018-12-30
中国粮食经济(2018年10期)2018-12-30
中国粮食经济(2018年11期)2018-12-27
对外经贸实务(2017年11期)2018-02-01
人大建设(2017年6期)2017-09-26
电脑爱好者(2017年7期)2017-05-06
