
云计算环境下基于关联量的数据部署与任务调度方法研究与实现
2018-01-29 07:51涂春萍
西安文理学院学报(自然科学版) 2018年1期
涂春萍
(华东交通大学 信息工程学院,南昌 330013)
随着科学的发展,社会已经进入大数据时代,在科学研究和统计分析等领域有着各种数据,在世界各地不同科研院所和公司也都有大量数据,世界各地科学家和公司都对数据研究投入大量工作,他们也会参与同一任务的研究,鉴于此,数据的部署和任务的调度对提高任务的执行效率就显得非常重要.云计算是近年来IT领域的核心计算方式,目前云计算的定义还不明确,现阶段被人们广泛接受的是美国技术研究院给出的定义:云计算是一种付费模式,这种模式基于互联网相关服务的增加、使用和交付,云计算中的云指的是网络和互联网.云计算有超强的计算能力,最高可以达到每秒10万亿次,在预测天气变化,模拟核武器爆炸和研究股市发展趋势等方面都有大量的应用[1].
网络计算可计算的领域十分狭隘,且计算效率很低,只能在均匀执行的环境下获取资源,已经无法满足时代的要求,因此云计算越来越成为一种主流计算方式.许多大型企业如Google、IBM、亚马逊和雅虎等都在自己研发的线上软件中广泛使用云计算,为客户提供具有超级计算能力的线上软件.云计算除了在商务企业中得到大量使用,也在科学研究、医疗服务、金融业等其他领域中有着广泛应用.科学工作流在云计算环境中本地环境和虚拟环境下的远程通道和广域网间进行资源存取.科学工作流是大数据时代科学家必须要使用的研究方法,科学工作流是基于计算机模型的科学建模和实验的事实标准,科学家所研发的大量数据和数据集都必须利用高性能计算环境和可视化工具来完成对数据的分析研究工作.单个SWFMS已经不能执行整个实验,一旦实验环境存在差异,单个SMFMS的局限性就会凸显出来,它无法对整个实验来进行操作,因此需要针对单个实验的不同工作流建立不同模型.云计算环境下的科学工作流有如下特点:①弹性服务.在云计算环境下科学工作流的服务规模可以调节伸缩,它拥有自动适应业务负载动态变化的能力.保证了使用者利用的资源满足业务的需求,有效地避免了服务器性能不稳定而导致服务质量的下滑和服务资源的浪费.②资源池化.云计算环境下的科学工作流资源共享,管理方式统一.网络虚拟技术可以将资源合理分配给不同的使用者,且整个资源放置、管理和分配过程都对使用者和用户透明化.③按需付费.整个付费过程都是根据服务内容完成,为用户提供的应用程序、数据存储和基础设施等资源都可以根据用户的需求直接提供,既可以对用户资源使用量进行监控,也可以根据资源使用情况对服务进行收费.④泛在接入.接入方式极其便捷,使用者可以利用各种终端设备,例如PC电脑、智能手机和笔记本电脑等,随时随地就可通过Internet对云计算服务进行访问.使用者只要通过电脑或手机进入数据中心,就可按照自己的需求进行运算.
本文在云计算环境下研究了关联量数据的部署和调度方法,首先对云计算环境下科学工作流的特点进行分析,根据所分析的特点提出数据间的数据依赖模型;然后结合聚类理论方法,设计出相应的算法来完成数据的资源部署和任务调度;最后利用仿真实验,验证所提模型和算法的有效性和合理性[2].
1 基于关联量数据调度的方法研究
云计算中的“云”指的是互联网中计算机群和网络群,每一个计算机群至少包括几十万台计算机,最多甚至可以达到几百万台.云计算在Internet虚拟服务器上进行运算,是一种超级计算模式,每秒的运算能力可以达到十万亿次,被普遍应用到各个领域之中,尤其是在计算天气变化,预测核武器爆炸情况和研究市场走向这三个领域使用更为广泛.
1.1 数据间的数据依赖模型设计
鉴于上述提出的云计算环境下科学工作流的特点提出数据间的数据依赖模型,其公式表示为:
公式中:A1表示多元组工作值;A2表示工作流活动对象;A3表示活动对象的输出参数;A4表示最大数据环境下的工作流对象输入参数;A0表示变化工作数据的使用值[3].确定了云计算所要研究的数据,通过以下公式来建立数据间的依赖关系:
公式中:Ar表示云计算的存储对象,Am表示数据的依赖节点值,Jpbr表示识别参数.经过上述参数、条件限定完成了数据依赖模型的设计.
2 基于关联量数据调度方法实现
利用上述设计的数据依赖模型结合聚类理论方法可以完成数据的资源部署和任务调度,对于参数的限定算法如下:
公式中:a1、a2、a3分别表示分云计算算法下的有效数据值、有效系统参量、依赖参量;ΔP表示云计算数据a1、a2、a3的差值参数;K(G)表示大数据环境下的云计算依赖程度,通过上述公式可以对参数进行限定;由于本文设计的依赖模型使用的是质数排列,因此需要对数列编辑进行重新组序,用公式表示为:
公式中:R表示数据激活对象,s表示数据传递值,n表示数据依赖值,q表示不同数据之间的所属的特征类型参数.通过上述算法可以完成对数据资源部署.对于数据资源调度算法公式如下:

3 仿真实验
为了测定本文设计的在云计算环境下的数据依赖模型和算法的有效性和合理性,设计了对比仿真实验.
3.1 参数设定
为保证设计的云计算环境下数据依赖模型和算法的有效性,对参数进行设定:多元组工作值A1的值域为[39.25,65.87],工作流活动对象A2的值为37.56,活动对象的输出参数A3的值域为[45.75,85.28],最大数据环境下的工作流对象输入参数A4的值域为[20.25,75.37].设置实验的参数见表1.

表1 实验参数
3.2 结果分析
通过上述设定的参数进行实验,得出的数据部署结果如图1所示.
通过图1分析,本文所建立的数据依赖模型和数据算法可以有效地完成数据的资源部署,且部署范围更广,部署范围在0~500之间,而且对于资源的部署更加均匀.利用本文设计的算法完成资源调度,调度结果如图2所示[5].
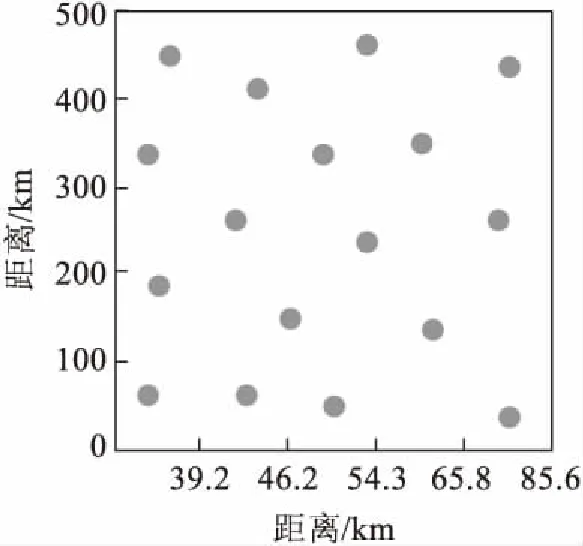
图1 关联量数据部署图

图2 关联数据资源调度图
通过图2分析可以看出,多元组工作值A1在39.2~85.6之间,利用本文给出的数据模型可以有效地将不同数据资源区分,完成数据资源调度,且调度面积更加均匀,调度结果更加准确.
综上所述,本文设计的云计算环境下的数据依赖模型和算法,能够在云计算环境下对数据资源进行快速、准确的调度和部署.
4 结语
通过分析和实验,可以发现本文设计的在云计算环境下的数据依赖模型和算法能够有效完成资源部署和数据调度,调度结果更加准确,调度范围更广泛,调度模式更合理,值得大力推广使用.希望本文设计的云计算环境下基于关联量的数据部署与任务调度方法的研究方法,对以后研究者研究此课题提供理论上的帮助.
[1] 郭力争,赵曙光,姜长远.云计算环境下基于关联量的数据部署与任务调度[J].计算机工程与科学,2013,35(8):1-7.
[2] 郭力争,耿永军,姜长源,等.云计算环境下基于粒子群算法的多目标优化[J].计算机工程与设计,2013,34(7):2358-2362.
[3] 任琼,常君明.基于任务分类思维的云计算海量资源改进调度[J].科学技术与工程,2016,16(12):101-105.
[4] 李建锋,彭舰.云计算环境下基于改进遗传算法的任务调度算法[J].计算机应用,2011,31(1):184-186.
[5] 方晖.云计算环境下海量数据高效调度模型仿真[J].微电子学与计算机,2014(9):159-161.
猜你喜欢
消费电子(2022年7期)2022-10-31
成都信息工程大学学报(2021年5期)2021-12-30
今日农业(2021年7期)2021-07-28
非公有制企业党建(2020年5期)2020-06-16
数字通信世界(2020年3期)2020-04-06
制造技术与机床(2019年4期)2019-04-04
电子制作(2017年20期)2017-04-26
太空探索(2016年9期)2016-07-12
现代防御技术(2016年1期)2016-06-01
信息通信技术(2015年6期)2015-12-26
