
中国象棋博弈系统实现的关键技术探索
2018-02-26 07:53肖秀春刘泽伟陈柏桃
电子技术与软件工程 2018年15期
肖秀春 刘泽伟 陈柏桃

摘要
棋局表示、著法生成、搜索算法、局面评估等是中国象棋人机博弈系统的关键,它决定了一个象棋博弈系统的优劣本文重点从优化中国象棋人机博弈系统性能的目的出发,围绕该系统的实现,探索其若干基本理论问题。同时,探讨了中国象棋人机博弈树的搜索技术;在此基础上,探索局面估值函数的建立方法,以及在各类搜索算法基础之上的优化思路。
【关键词】中国象棋 博弈 棋盘表示 着法生成 博弈树搜索
1 引言
中国象棋是我国一门古老的博弈游戏,其中蕴含了大量关于运筹,谋略的思想。人机对弈是人与计算机之间的决策计算过程,它是人工智能的一个研究分支,它的研究为人工智能带来了很多重要的方法和理论,产生了广泛的社会影响和学术影响。
要实现人机对弈的功能,首先要有能够反映棋盘信息的数据结构,根据规则产生合法着法,并且在轮到计算机走子时,计算机能够搜索到对己方最为有利的着法。我们可以用一棵“博弈树”来表示下棋的过程,树中的每一个节点代表棋盘上的一个局面,对于每一个局面根据不同的着法又产生不同的局面,如此直到叶节点。根据规则,可以可靠地判断输赢,假设每次计算机都能搜索到最优局面,那么计算机将处于不败的地位。但就目前而言,计算机能搜索到的层数有限,因此需要一个评估函数来判断局面的好坏,这样,计算机便能通过评估函数选择对自己最为有利的着法。
从结构上,可以将一个人机对弈系统分为棋盘表示,着法生成,搜索算法以及局面评估几个方面。拥有了以上这些,计算机便能实现基本的对弈功能。与人类相比,计算机还未能根据局面的情况制定作战计划,它擅长的是计算,因而对于棋力的增强,则有赖于搜索算法及局面评估的结合,随着搜索算法的不断改进,搜索过程中剪枝效率越高,搜索的层次越深;同时,对于搜索结果进行的局面评估越精确,搜索得到的着法便越好,计算机的棋力也大幅度提升。
2 棋盘表示及着法生成
无疑地,棋盘表示是中国象棋人机博弈系统着法生成的基础。合适的棋盘表示不仅有利于着法生成中各个搜索节点的存储,也将有利于局面评估函数对当前节点的评价。
2.1 棋盘表示
中国象棋的棋盘为9×10的矩形,一般采用9×10的二维数组表示。但是,这种表示方法将不利于棋盘边界的判断。基于边界的判断考虑,也可以采用16×16的扩展棋盘来表示。通常,采用一个大小为256的一维数组来表示的带扩展边界的棋盘,对于棋子,数字0表示空位(即该位置没有棋子),数字8~14依次表示红方的帅、仕、相、马、车、炮和兵;数字16~22依次表示黑方的将、士、象、马、车、炮和卒。因此棋盘的初始局面可以表示为:
int ChessBoard[256]={
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,20,19,18,17,16,17,18,19,20,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,21,0,0,0,0,0,0,21,0,0,0,0,
0,0,0,22,0,22,0,22,0,22,0,22,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,14,0,14,0,14,0,14,0,14,0,0,0,0,
0,0,0,0,13,0,0,0,0,0,0,13,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,21,0,21,0,21,0,21,0,21,0,0,0,0,
0,0,0,12,11,10,9,8,9,10,11,12,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
这里判断是否超出边界非常简单,利用如下所示的数组,判断棋子所在位置是否为0就行了。
int IsInBoard[256]={
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,
0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,
0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,
0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,
0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,
0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,
0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,
0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,
0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,
0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
2.2 着法生成
着法生成主要是用来判断用户的着法是否正确,以及生成计算机的所有着法,用以从中选取最好的着法。对于象棋的各个兵种,我们可以将其各个合理的着法存储起来,在生成时直接取出来就可以了,这样就省去了很多工作,提高了系统的性能。
3 搜索算法
3.1 最小一最大搜索及负极大值搜索
对于博弈双方,每方都在寻求对己方局面有利的着法。假设黑方(为讨论问题方便,可假定为黑方为对弈的人,红方为计算机)赢的局面评估函数分值为负无穷,红方赢的局面评估函数分值为正无穷,那么,黑方肯定选择当前评估函数分值较小的着法而红方应对时,则选择当前评估函数分值较大的着法。如此交替,即是最小一最大搜索。于是,对于计算机来说,其搜索最有利于己方着法时,必须考虑对方的应对着法,其搜索目标为使得经过交替最小一最大搜索,最终得到当前局面的最小评估值。最小一最大搜索原理可如图1所示。
图中展示了黑方当前可以有A、B两种着法,对应黑方的着法A、B,红方对应的着法分别为(C,D)和(E,F),其对应的当前局面评估函数分值分别如上图所示。显然,当黑方选择着法A的话,那么红方肯定会回应D,使估分变为5(红方有利)。但是如果黑方选择着法B,那么红方即使选择最佳着法E,其估分还是-4(黑方有利)。可以看到,每次递归时,走子方改变,选择方式也相应改变,我们可以将其优化为负极大值搜索,即每次递归时将返回值转为负值,以反映当前局面的更改。伪代码如下:
int NegaMax(int depth)
{
int best=-无穷大;
if(depth<=0)
return评价值;
调用着法生成函数,生成所有合法着法;
while(生成的着法)
{
试走一个着法;
value=-NegaMax(depth-1);
撤销该着法;
if(value>best)
best-value;
}
return best;
}。
3.2 Alpha-Beta搜索
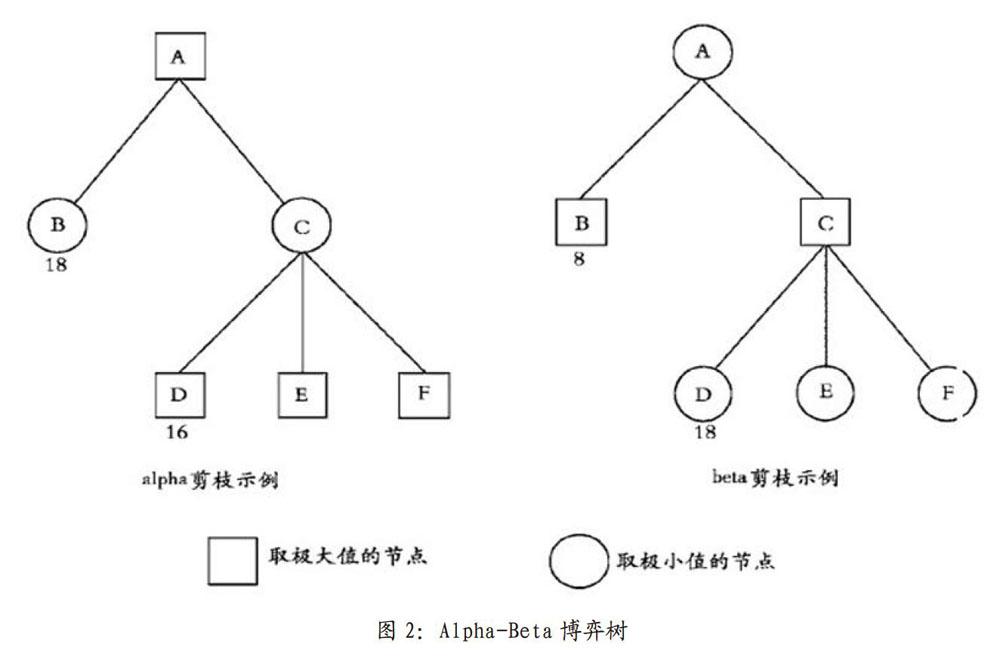
随着搜索深度的增加,局面是呈指数级增长的,所以在有限的时间内,计算机搜索的层数很浅。而计算机要找到更好的着法,搜索的层数应该尽可能深。因此在搜索过程中,应及时停止扩展那些已无必要再扩展的子节点,即相当于剪去博弈树上的一些分枝。如图2所示。
图2中左边部分由于节点C取极小值,可以判断C的值将小于或等于16;而节点A的值为Max(B,C)=18,因此我们不再需要评估节点C的其他节点E、F便可以得出父节点A的值了,这种剪枝策略称为Alpha剪枝。
同样,如图2右边部分所示,我们可以判定节点C的值将大于或等于18,而节点A为Min(B,C)=8,因此我们也不再需要评估节点C的其他节点的值,这种剪枝策略称为Beta剪枝。将Alpha剪枝及Beta剪枝加入负极大值搜索便得到Alpha-Beta搜索算法。伪代码如下:
int A1phaBetaSearch(int alpha,int beta,intdepth)
{
if(depth=0)
return局面评价函数;
调用着法生成子函数,生成所有着法;
for(每个生成的着法)
{
在博弈树中,取出一个着法;
int value=-A1phaBeta(-beta,-alpha,depth-1);
在博弈树中,剪枝一个着法;
if(value>=beta)
break;
if(value>alpha)
alpha=value;
}
return alpha;
}
这就是Alpha-Beta算法,只要有一步好的着法,就可以淘汰很多没必要搜索的节点,包括节点之下的子树,使得搜索效率大为提高。
3.3 MID搜索
我们也可以通过一个估算值(g,g+1)作为窗口来进行探测,设定一个上界upperbound和一个下界lowerbound,如果结果大于g,则修改lowerbound,如果小于g,则修改upperbound,如此反复,不断修改边界值,知道upperbound和lowerbound收敛于一点。伪代码如下:
int MTD()
{
g=初始值;
upperbound=INFINITY;
lowerbound=-INFINITY;
while(lowerbound
{
if(g==lowerbound)
beta=g+1;
else
beta=g;
g=AlphaBeta Seach(beta-1 ,beta,nDepth-1)
if(g
upperbound=g;
else
lowerbound=g
}
returng;
}
4 局面评估
一般而言,都是通過局面评估来判断着法的好坏。如果把红方的价值总和设为RedValue,黑方价值总和设为BIackValue,那么Value=BIaekValue-RedValue,就是对于黑方而言的局面的情况。以上分析表明,对于局面评估,着法价值的计算非常重要。我们可以从以下若干角度对着法价值进行计算。
4.1 子力价值
子力价值即是博弈双方各有哪些棋子,以及价值如何。根据文献[5],可以让一个车的价值为500,一个马的价值为300,一个兵的价值为100等等,而将的价值设为无穷大或计算机所能表示的最大的数值。
4.2 机动性及对棋盘的控制
机动性值是棋子的活动范围的度量,通常棋子的活动范围越大,其机动性也越好,而对棋盘的控制范围则是一个棋子的合法着法的范围内,可以通过双方控制该位置的棋子数量及棋子价值来决定哪方的机动性占优。
4.3 棋子位置
对于同一个棋子,位置不同,其价值也有所不同,比方说,过河卒子要比未过河的价值高得多。可以给每个不同的兵种在棋盘上的各个位置给出经验评估值,以确保评估的准确性。
5 性能优化
5.1 迭代深化
在搜索过程中对搜索树作出裁剪,可以有效地降低计算机的搜索时间,从而增加计算机搜索尝试。对搜索树剪枝的关键在于能够搜索到好的着法,否则裁剪效率很低。通常,可以通过一个历史启发表来存储搜索过的好的着法,这大大增加了剪枝的效率。剪枝的效率越高,可使得算法迭代层次越深。
5.2 静态搜索
在下棋的过程有时会遇到这种情况,就是计算机搜索的层次不够深,因而有些厉害的杀着可能搜索不出来,这就导致棋力下降。我们在局面发生震荡的时候加深搜索的层次,直到局面没有吃子或者将军的情况,这较大幅度地提高象棋的棋力。
6 结束语
博弈理论与人工智能的研究有着相互推动的作用:博弈理论对于人工智能研究的发展提出要求;人工智能的研究成果反过来可以应用于博弈系统实践。
本文对计算机博弈理论进行了研究,在深入研究了计算机中国象棋理论基础上,探讨了中国象棋人机对弈系统的设计原理。但是用Alpha-Beta搜索算法或其變种以及启发式搜索的方法,采用局面估值函数对各搜索节点进行估值,这样人为的主观因素很强,而要克服这个问题,则需要计算机进行自学习,以取得更高的独立性及自适应性。
参考文献
[1]王骄,王涛,罗艳红.徐心和.中国象棋计算机博弈系统评估函数的自适应遗传算法实现[J].东北大学学报,2005,26(10):949-952.
[2]危春波.中国象棋博弈系统的研究与实现[D].昆明理工大学硕士学位论文,2008.
[3]徐心和,王骄.中国象棋计算机博弈关键技术分析[J].小型微型计算机系统,2006,27(06):962-969.
[4]刘淑琴,刘淑英.基于博弈树搜索算法的中国象棋游戏的设计与实现[J].自动化与仪器仪表,2017(10):96-98.
[5]金朋,冯速.博弈树搜索算法概述[J].计算机系统应用,2009(09):203-207.
[6]蔡屾.一种中国象棋机器博弈剪枝策略的改进方法[J].国外电子技术,2016,35(03):47-49.
[7]郝卿,黎利辉.基于 Android的中国象棋局域网博弈平台的设计与实现[J].广西民族师范学院学报,2017,34(03):145-148,113.
猜你喜欢
读写算·小学低年级(2016年12期)2016-12-21
读写算(上)(2016年12期)2016-12-13
知音励志·社科版(2016年9期)2016-11-09
商业会计(2016年15期)2016-10-21
商业会计(2016年13期)2016-10-20
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
棋艺(2014年7期)2014-09-09
青年文摘·上半月(1982年4期)1982-01-01
