
基于深度数据的手势识别研究进展
2018-04-16 02:59陈红梅赖重远胡华桦赵维胜
江汉大学学报(自然科学版) 2018年2期
陈红梅,赖重远,张 洋,胡华桦,赵维胜
(江汉大学 交叉学科研究院,湖北 武汉 430056)
沟通是人类集体活动的基础。早在语言文字出现之前,人类就开始通过视觉来传递意义,如人的手势、面部表情和动作。其中,手关节的灵活性使其具有能够赋予大量语义的能力,成为人类不可或缺的沟通方式之一[1]。同时,相较于语言文字,手势沟通更为形象,更易于学习,也更方便理解,具有减轻人类沟通负担,增强沟通效果的潜力,因而在人类的沟通中得到了越来越多的应用[2]。
随着科技的不断进步,人类已经不满足于仅与人类自身进行沟通,通过与机器有效沟通满足人类自身需要成为越来越迫切的需求[3]。为了能让人与机器的沟通像人与人之间的沟通一样自然,人们开发出了一系列手势识别系统,典型的系统包括数据手套[4]、重力传感器[5]、多点触屏[6]以及基于视觉的手势识别系统[7]。前三者都属于接触式交互系统,使用起来不够自然。而最后一种手势识别系统采用非接触式交互方式,更接近于人与人之间的手势交互方式,具有很强的推广价值,因此在当前蓬勃发展的人工智能领域得到越来越广泛的应用[8]。
传统的基于视觉的手势识别系统采用二维光学摄像头采集手势图像。被拍摄手势的反射光线传播到镜头,经镜头聚焦到半导体芯片上,芯片根据光的强弱积聚相应的电荷,产生表示手势画面的电信号,经过扫描、放大和模数转换形成最终的手势数字图像。根据上述原理,采集到的手势图像极易受到光照和杂散背景的影响,给后续的手势提取工作带来了重大挑战,严重制约着基于视觉的手势识别实用化进程。
近年来,深度摄像技术的兴起为解决上述问题带来了新的机遇。在深度数据的辅助下,手势提取的鲁棒性得到大幅提升,并为判断手关节组合,进而准确识别手势创造了有利条件,使得基于深度数据的手势识别系统成为当前最具前景的手势识别系统之一,有力地促进了基于视觉的手势识别的实用化进程。
近两年来,关于手势识别领域的进展综述,有的从开发应用系统原型的角度出发给出了数据集的标注方法[9],有的从发展历程的角度出发介绍了手势识别方法和数据集[10],有的从存在问题的角度出发比较了各种手势识别特征提取、分类和分割方法的优劣[11],还有的则从体系架构的角度出发介绍了手势三维信息的获取、识别和应用[8]。本文的不同之处在于从数据的角度出发,给出手势深度数据的获取原理,分析不同手势数据集的特点,综述适用于不同数据集的手势识别方法,以方便研发人员根据实际获取的深度数据特点设计或选择相应的方法识别手势。
1 手势深度数据的获取
近年来,深度摄像头以其低廉的价格和在人工智能领域广阔的应用前景,成为各大软硬件公司竞相研发的重点,如微软公司的Kinect摄像头[12]、苹果公司的TrueDepth摄像头、英特尔公司的Real Sense摄像头、谷歌公司的Tango摄像头和Leap公司的Leap Motion摄像头[13]等。其中,微软公司的Kinect摄像头市场推出时间最早,软件开发工具包齐全,测试数据库标准化,在手势识别这一领域得到了广大研发者的青睐。在此背景下,本节着重介绍微软公司近年来推出的两款Kinect摄像头,包括它们的结构、原理和性能指标,以方便根据实际需要采集手势的深度数据。
Kinect 1.0是微软公司于2010年6月推出的一款用于体感游戏的深度摄像头[12]。如图1(a)所示,该摄像头由位于中间的光学摄像头、左侧的红外激光投影器和右侧的深度红外传感器组成。前者又称之为彩色摄像头,后两者统称为深度摄像头。Kinect 1.0采用结构光技术采集深度数据。红外激光投影器向感应区域发射红外激光散斑,深度红外传感器根据反射回的红外散斑在像平面上的位置,计算出感知区域的深度。
为进一步提升深度摄像头的性能,特别是对如手这样的微小物体的辨识度和清晰度,微软公司于2014年10月推出了新一代深度摄像头,称之为Kinect 2.0。如图1(b)所示,该摄像头由位于左侧的光学摄像头、右侧的红外激光投影器和中间的深度红外传感器组成。与Kinect 1.0不同,Kinect 2.0的深度摄像头采用内置的形式。Kinect 2.0采用飞行时间技术采集深度数据。红外激光投影器向感应区域发射红外激光脉冲,深度红外传感器通过计算像平面各个位置上的光程来获取深度数据。

图1 Kinect深度摄像头Fig.1 Kinect depth cameras
表1给出了上述两种深度摄像头的主要性能指标。由表1可知,相较于Kinect 1.0,Kinect 2.0有着更高的视频分辨率,更大的检测范围,更宽广的视野,更高的整体精确度以及更强的关节检测功能。此外,新增的主动红外线探测功能使得Kinect 2.0不仅可以在黑暗中使用并获得相应的深度数据,而且还能产生独立于可见光的红外视场。

表1 两种深度摄像头主要性能指标Tab.1 Main performance indexes of two depth cameras
2 常用手势深度数据集概述
当前,手势识别主要是针对特定任务进行的。这些任务既包括了常用符号的识别,如数字、字母,也包括了常见动作的识别。为便于评估不同手势识别方法的性能,在实际研发中需要约定统一的数据集。常用的手势数据集包括NTU-Microsoft手势数字集[14]、UESTC-ASL手势数字集[15]、ASL手势字母集[16]、HUST-ASL手势混合集[17]、MSR Gesture 3D手势动作集[18]、MSR Action 3D手势动作集[19]和MSR Daily Activity 3D手势动作集[20]。其中,前四者为静态手势集,后三者为动态手势集。它们均由使用Kinect 1.0深度摄像头采集得到的手势彩色图和深度图组成,其光照条件均为室内光照,拍摄背景均为非控制条件下的杂散背景。为简单起见,下面将重点介绍NTU-Microsoft手势数字集[14]、ASL手势字母集[16]和MSR Gesture 3D手势动作集[18]。这3个数据集在设计上基本涵盖了实际手势的外观及变化,采集过程既符合实际拍摄情况,识别结果又具有很强的实用价值,故而在实际研发中得到了广泛的使用。
NTU-Microsoft手势数字集是新加坡南洋理工大学和微软研究院于2011年11月共同推出的手势数字集[14]。要求采集对象必须将手置于最靠近摄像头的位置,以便于后续采用简单的阈值法对深度图上的手部区域进行粗略分割;同时,采集对象的手腕部需要佩戴一条黑色的带子,方便后续检测并对手部区域进行精确分割。一共有10人参与了采集工作,每人采集10类不同的数字手势,每人每类手势采集10次,故总计1 000个手势样本。每类手势样本的示意图如图2(a)所示,这些手势的区别主要在于5个手指的伸直与弯曲上。对于每类手势,其样本包含了大小、旋转、噪声和形变,以及一定程度的翻转和少量关节变化。
ASL手势字母集是英国萨里大学于2011年11月推出的美国手语手势字母集[16]。一共有5人次参与了采集工作,每人采集24类不同的字母手势(其中不包含动态字母手势j和z),每人每类手势采集超过500次,故总计超过60 000个手势样本。每类手势样本的示意图如图2(b)所示。不少手势类别之间差别很小,如字母a、e、m、n、s、t的外观就非常接近。对于每类手势,其样本包含了大小、旋转、噪声和形变,以及一定程度的翻转变化。
MSR Gesture 3D手势动作集是微软研究院于2012年8月推出的常用动作集[18]。一共有10人参与了采集工作,每人采集12类不同的动作手势,每人每类手势采集2~3次,总计有336个手势样本。这些手势类别包括:Bathroom、Blue、Finish、Green、Hungry、Milk、Past、Pig、Store、Where、Letter J、Letter Z。每类手势样本的示意图如图2(c)所示。这些手势样本序列不仅有前述静态手势样本包含的各种变化,而且还包含了大量的自遮挡和动作节奏的变化。
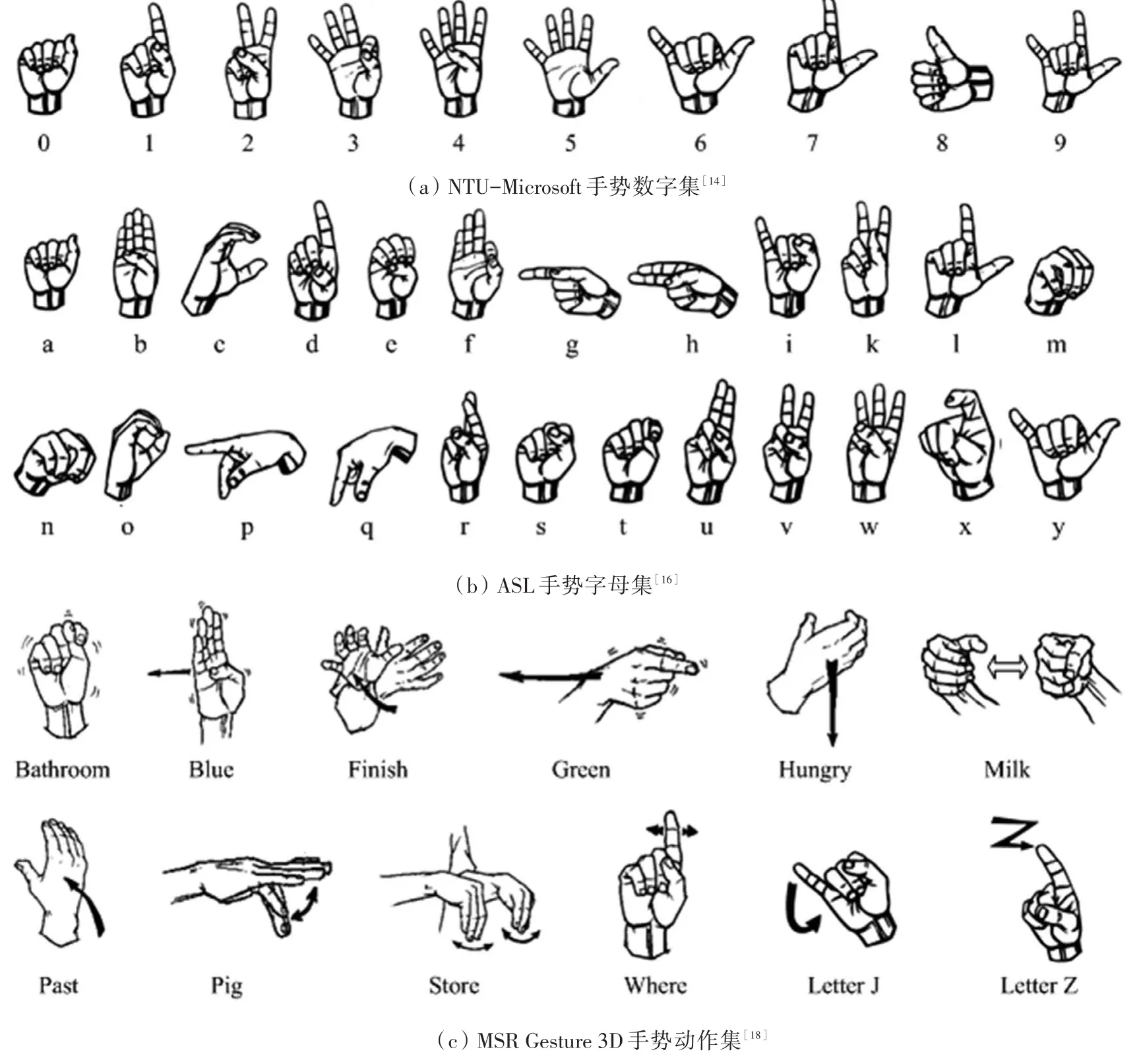
图2 3个常见手势数据集示意图Fig.2 Illustration of three common hand gesture datasets
表2给出了上述3个常用手势数据集的主要参数对比。结合图2和表2可以看出,NTU-Microsoft手势数字集类间间距大、样本类别少,因而简单的匹配识别方法就能满足实际应用要求。ASL手势字母集样本类别多,部分类别间距小,因而需要更为精巧的特征和更强有力的分类方法。比起前两个数据集,MSR Gesture 3D手势动作集在三维空间维度的基础上又增加了时间维度,因此在特征的设计和分类方法的选取上需要将时间维度一并考虑进来。后续的识别方法基本上遵循了上述思路。

表2 3个常见手势数据集主要参数对比Tab.2 Comparison of main parameters of three common hand gesture datasets
3 基于深度数据的手势识别方法
能够识别任意外观和动作的手势是研发人员的不懈追求。在深度数据的辅助下,通过简单的阈值法就能将深度图中的手部区域准确分割出来,从而将手势识别问题转化成手部三维形状的识别问题。下面将按照手势数据集识别由易到难的顺序,依次介绍各种手部形状的特征提取和分类方法,并在对应数据集上比较分析各种方法的性能,以方便研发人员根据实际采集到的深度数据的特点设计或选择相应的方法识别手势。
3.1 手势数字识别方法
对于以NTU-Microsoft为代表的手势数字集,如图2(a)所示,只需判断5个手指中哪些是伸直的即可识别手势。因此,以手指或指尖为特征,以模板匹配为分类方法成为自然选择。
REN等[14]率先提出了基于手指搬土距离(finger-earth mover′s distance,FEMD)的手势识别框架。首先采用阈值分解(thresholding decomposition,TD)或者近似凸分解(near-convex decomposition,NCD)方法将手指从手部区域中分割出来,然后采用FEMD进行匹配。为了更好地在手指特征提取精度和计算量之间平衡,WANG等[21]提出了基于感知形状分解(perceptual shape decomposition,PSD)的手势识别方法。
LAI等[22]则提出了基于指尖的轮廓分段匹配的手势识别框架。首先采用离散曲线演化(discrete curve evolution,DCE)方法检测指尖,然后利用指尖对手部轮廓进行分段匹配。
CHENG等[23]提出了基于图像对应类的动态时间规整(image-to-class dynamic time warping,I2CDTW)方法。与基于图像对应图像的动态时间规整(image-to-image dynamic time warping,I2I-DTW)方法不同,该方法不仅对轮廓进行整体匹配,还对相邻手指轮廓进行组合匹配,以提高匹配精度。
3.2 手势字母识别方法
对于以ASL为代表的手势字母集,如图2(b)所示,光靠轮廓信息难以识别出轮廓非常相似的手势,如字母a、e、m、n、s、t。因此,充分利用手势内部深度信息成为自然选择。
PUGEAULT等[16]采用Gabor滤波器提取深度特征进行随机森林(random forest,RF)分类。KUZNETSO⁃VA等[24]则提出了多层随机森林(multi-layered random forest,MLRF)方法,该方法首先对ASL手势字母集聚类,然后提取形状函数组合(ensemble of shape function,ESF)特征,再采用MLRF方法实现图像到聚类再到类的识别。KESKIN等[25]提出了基于像素对应类的方法,该方法首先构造基于深度差值的像素上下文特征,然后利用RF方法求解像素对应类的概率,最后对所有像素投票确定最终的类别。
ZHANG等[26]采用了三维面片直方图(histogram of 3D facets,H3DF)构造特征进行支持向量机(sup⁃port vector machine,SVM)和稀疏表示分类(sparse representation classification,SRC)。
为增强翻转变化的鲁棒性,FENG等[17]提出了基于深度投影图的轮廓段袋(depth-projection-mapbased bag of contour fragments,DPM-BCF)方法,该方法首先将手部形状投影到3个正交平面上,然后采用BCF方法进行分类。为进一步利用手势内部信息,FENG等[27]又提出了增强深度投影图(enhanced DPM,eDPM)方法,该方法在BCF特征的基础上,又加入了方向梯度直方图(histogram of orientated gradi⁃ents,HOG)特征。
3.3 手势动作识别方法
对于以MSR Gesture 3D为代表的手势动作集,在前述静态手势的基础上,又增加了时间维度的信息。自然地形成了两类识别方法,一类是构造带时间维度的特征进行识别,另一类是对每一帧采用静态手势识别的方法提取特征再进行特征序列匹配。
对于第一类方法,WANG等[28]提出了基于随机占用模式(random occupation pattern,ROP)的识别方法。首先在由行、列、深度和时间组成的四维空间中随机抽取任意大小的子立方体,接着计算动作在其中的占用比例作为候选特征,然后计算该候选特征的辨识能力并将其作为特征选取的依据,最后通过SRC进行分类。OREIFEJ等[29]提出了基于四维法矢量方向直方图(histogram of oriented 4D normals,HO4DN)的识别方法。首先计算四维空间子立方体中像素的法矢量,接着计算其在正多胞体空间中的投影特征,然后针对比较集中的投影方向增加投影矢量以提升投影特征的分辨力,最后利用SVM进行分类。YANG等[30]在上述方法的基础上提出了基于超法矢量(super vector normal,SVN)的识别方法。首先采用SRC学习关于上述方法得到的法矢量的字典和系数,以此构造自适应空时金字塔结构的超法矢量特征,然后采用SVM进行分类。RAHMANI等[31]提出了基于深度梯度直方图(histogram of depth gradients,HDG)和RF的实时动态手势识别方法。
对于第二类方法,KURAKIN等[18]提出了实时动态手势识别系统。该系统首先对采集到的手势在方向上对齐,然后根据手部中心的移动速度、旋转参数和形状构造每一帧的手势特征,最后通过动作图上的解码算法求解。YANG等[32]提出了基于深度运动图(depth motion map,DMM)的方法。首先计算每一帧深度图的三视图,接着对每一视图内的手部区域进行归一化,然后逐帧求差并累加获得DMM,再从中提取相应的HOG特征,最后采用SVM进行分类。ZHANG等[26]则在前述基于H3DF的静态手势特征的基础上,利用基于动态规划(dynamic programming,DP)的表达对手势视频序列进行分段识别。
3.4 各类方法识别精度比较
表3给出了上述各类方法在对应手势数据集上的识别精度。由表3可知,与传统的形状上下文匹配[33]和骨架图匹配方法[34]相比,针对NTU-Microsoft手势数字集提出的方法选取的手指或指尖特征其视觉意义更明确,识别精度更高。进一步地,I2C-DTW方法的识别精度要优于I2I-DTW方法,说明在全局匹配的基础上增加局部匹配,能够有效减少类内变化造成的影响,提升匹配的鲁棒性。而对于拥有更多类别的ASL手势字母集而言,相比于使用图像特征,如HOG[35]、Gabor滤波器,采用几何特征,如H3DF,具有更好的识别效果。进一步地,eDPM方法的识别精度优于DPM方法,说明手势内部深度特征是轮廓特征的补充,能够有效增加具有相近轮廓特征手势类别的类间间距,提升整体识别精度。对于MSR Gesture 3D手势动作集而言,与传统的基于图像特征的三维方向梯度直方图(Histogram of 3D Gradient Orientations,H3GO)[36]方法相比,基于几何特征的HO4DN和SVN方法具有更好的识别效果。进一步地,相比于采用第一类带时间维度的特征分类方法,采用第二类逐帧匹配的方法处理起动作节奏变化问题更加灵活,故而更容易获得更高的识别精度。

表3 各类方法在对应手势集上的识别精度Tab.3 Recognition accuracies of various methods on their corresponding hand gesture datasets
4 结语
基于深度数据的手势识别还有很多值得研究的问题。当前的手势识别均采用单一的深度摄像头从单一角度进行拍摄,造成采集到的三维手势信息部分缺失,这给处理手势的翻转变化和遮挡问题带来了挑战。进一步的研究可以通过布署深度摄像头阵列从多角度拍摄来弥补上述信息的缺失,实现更加鲁棒的手势识别。此外,当前手势识别方法处理的均是通过安装在固定位置的深度摄像头从固定角度采集到的深度数据,从而限制了上述方法在移动机器人上的应用。如何处理移动摄像头采集到的手势深度数据也是值得研究的方向之一。总之,随着人工智能技术的不断进步和人机交互需求量的不断增长,基于深度数据的手势识别必将有着广阔的研发和应用前景。
参考文献(References)
[1] LEFEVRE R.Rude hand gestures of the world:a guide to offending without words[M].San Francisco,CA,USA:Chronicle Books,2011.
[2] KELLYS D,MANNINGS M,RODAK S.Gesture gives a hand to language and learning:perspectives from cognitive neurosci⁃ence,developmental psychology and education[J].Language and Linguistics Compass,2008,2(4):569-588.
[3] CARD S K,MORAN T P,NEWELL A.The psychology of human-computer interaction[M].Hillsdale,New Jersey:Lawrence Erlbaum,1983.
[4] STURMAN D J,ZELTZER D.A survey of glove-based input[J].IEEE Computer Graphics and Applications,1994,14(1):30-39.
[5] ZHANG X,CHEN X,LI Y,et al.A framework for hand gesture recognition based on accelerometer and EMG sensors[J]. IEEE Transactions on Systems,Man,and Cybernetics-Part A:Systems and Humans,2011,41(6):1064-1076.
[6] HOGGAN E,WILLIAMSON J,OULASVIRTA A,et al.Multi-touch rotation gestures:performance and ergonomics[C]∕∕Sig⁃chi Conference on Human Factors in Computing Systems.Paris,France:ACM,2013:3047-3050.
[7] EROL A,BEBIS G,NICOLESCU M,et al.Vision-based hand pose estimation:a review[J].Computer Vision and Image Un⁃derstanding,2007,108(1):52-73.
[8] CHENG H,YANG L,LIU Z C.Survey on 3D hand gesture recognition[J].IEEE Transactions on Circuits and Systems for Vid⁃eo Technology,2016,26(9):1659-1673.
[9] RUFFIEUX S,LALANNE D,MUGELLINI E,et al.Gesture recognition corpora and tools:a scripted ground truthing method[J].Computer Vision and Image Understanding,2015,131:72-87.
[10]PISHARADY P K,SAERBECK M.Recent methods and databases in vision-based hand gesture recognition:a review[J].Com⁃puter Vision and Image Understanding,2015,141:152-165.
[11]ORAZIO T D,MARANI R,RENÒ V G,et al.Recent trends in gesture recognition:how depth data has improved classical ap⁃proaches[J].Image and Vision Computing,2016,52:56-72.
[12]ZHANG Z Y.Microsoft Kinect sensor and its effect[J].IEEE Multimedia,2012,19(2):4-10.
[13]WEICHERT F,BACHMANN D,RUDAK B,et al.Analysis of the accuracy and robustness of the leap motion controller[J]. Sensors,2013,13(5):6380-6393.
[14]REN Z,YUAN J S,ZHANG Z Y.Robust hand gesture recognition based on finger-earth mover′s distance with a commodity depth camera[C]∕∕ACM International Conference on Multimedia.Scottsdale,Arizona,USA:ACM,2011:1093-1096.
[15]CHENG H,DAI Z J,LIU Z C.Image-to-class dynamic time warping for 3D hand gesture recognition[C]∕∕IEEE International Conference on Multimedia and Expo.San Jose,CA,USA:IEEE,2013:1-6.
[16]PUGEAULT N,BOWDEN R.Spelling it out:real-time ASL finger spelling recognition[C]∕∕IEEE International Conference on Computer Vision Workshops.Barcelona,Spain:IEEE,2012:1114-1119.
[17]FENG B,HE F Z,WANG X G,et al.Depth projection maps-based bag of contour fragments for robust hand gesture recognition[J].IEEE Transactions on Human-Machine Systems,2017,47(4):511-523.
[18]KURAKIN A,ZHANG Z,LIU Z.A real time system for dynamic hand gesture recognition with a depth sensor[C]∕∕European Signal Processing Conference.Bucharest,Romania:IEEE,2012:1975-1979.
[19]LI W Q,ZHANG Z Y,LIU Z C.Action recognition based on a bag of 3D points[C]∕∕IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops.San Francisco,CA,USA:IEEE,2010:13-18.
[20]WANG J,LIU Z C,WU Y,et al.Mining actionlet ensemble for action recognition with depth cameras[C]∕∕IEEE Computer So⁃ciety Conference on Computer Vision and Pattern Recognition.Providence,RI,USA:IEEE,2012:1290-1297.
[21]WANG C,LAI Z Y,WANG H Y.Hand gesture recognition based on perceptual shape decomposition with a Kinect camera[J]. IEICE Transactions on Information and Systems,2013,96(9):2147-2151.
[22]LAI Z Y,YAO Z J,WANG C,et al.Fingertips detection and hand gesture recognition based on discrete curve evolution with a kinect sensor[C]∕∕Visual Communication and Image Processing Conference.Chengdu,China:IEEE,2016:1-4.
[23]CHENG H,DAI Z J,LIU Z C,et al.An image-to-class dynamic time warping approach for both 3D static and trajectory hand gesture recognition[J].Pattern Recognition,2016,55:137-147.
[24]KUZNETSOVA A,LEAL-TAIXE L,ROSENHAHN B.Real-time sign language recognition using a consumer depth camera[C]∕∕IEEE International Conference on Computer Vision Workshops.Sydney,NSW,Australia:IEEE,2013:83-90.
[25]KESKIN C,KIRAC F,KARA Y E,et al.Randomized decision forests for static and dynamic hand shape classification[C]∕∕IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops.Providence,RI,USA:IEEE,2012:31-36.
[26]ZHANG C Y,TIAN Y L.Histogram of 3D Facets:a depth descriptor for human action and hand gesture recognition[J].Com⁃puter Vision and Image Understanding,2015,139:29-39.
[27]FENG B,LUO H F,WU Y J,et al.Robust hand gesture recognition based on enhanced depth projection maps(eDPM)[C]∕∕International Conference on Wireless Communications and Signal Processing.Yangzhou:IEEE,2016:1-5.
[28]WANG J,LIU Z C,CHOROWSKI J,et al.Robust 3D action recognition with random occupancy patterns[C]∕∕European Con⁃ference on Computer Vision.Spring-Verlag,2012:872-885.
[29]OREIFEJ O,LIU Z C.HON4D:histogram of oriented 4D normals for activity recognition from depth sequences[C]∕∕IEEE Com⁃puter Society Conference on Computer Vision and Pattern Recognition.Portland,OR,USA:IEEE,2013:716-723.
[30]YANG X D,TIAN Y L.Super normal vector for activity recognition using depth sequences[C]∕∕IEEE Computer Society Confer⁃ence on Computer Vision and Pattern Recognition.Columbus,OH,USA:IEEE,2014:804-811.
[31]RAHMANI H,MAHMOOD A,HUYNH D Q,et al.Real time action recognition using histograms of depth gradients and ran⁃dom decision forests[C]∕∕IEEE Workshop on Applications of Computer Vision.Steamboat Springs,CO,USA:IEEE,2014:626-633.
[32]YANG X D,ZHANG C Y,TIAN Y L.Recognizing actions using depth motion maps-based histograms of oriented gradients[C]∕∕ACM International Conference on Multimedia.Nara,Japan:ACM,2012:1057-1060.
[33]BELONGIE S,MALIK J,PUZICHA J.Shape matching and object recognition using shape contexts[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2002,24(4):509-522.
[34]BAI X,LATECKI L J.Path similarity skeleton graph matching[J].IEEE Transactions on Pattern Analysis and Machine Intelli⁃gence,2008,30(7):1282-1292.
[35]DALAL N,TRIGGS B.Histogram of orientated gradients for human detection[C]∕∕IEEE Computer Society Conference on Com⁃puter Vision and Pattern Recognition.San Diego,CA,USA:IEEE,2005:886-893.
[36]KLASER A,MARSZALEK M,SCHMID C.A spatio-temporal descriptor based on 3D-gradients[C]∕∕British Machine Vision Conference,Leeds,United Kingdom,BMVA,2008.
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
汽车工程师(2021年12期)2022-01-18
现代装饰(2020年6期)2020-06-22
红领巾·萌芽(2019年9期)2019-10-09
小学科学(学生版)(2018年12期)2018-12-19
小学阅读指南·低年级版(2017年6期)2017-06-12
学苑创造·B版(2017年3期)2017-05-03
汽车维修与保养(2015年8期)2015-04-17
网络与信息(2009年8期)2009-05-10
少年科学(2006年1期)2006-02-07
