
应用连续投影算法及最小二乘支持向量机的单组分纺织品识别
2018-08-23 09:48李佳平沈国康欧耀明辛斌杰
纺织学报 2018年8期
李佳平, 沈国康, 欧耀明, 孟 想, 辛斌杰
(1. 上海工程技术大学 服装学院, 上海 201620; 2. 浙江中天纺检测有限公司, 浙江 海宁 314400;3. 浙江万方安道拓纺织科技有限公司, 浙江 海宁 314400)
随着科技水平的快速进步和纺织新材料的不断涌现,纺织品检测显得极其重要,特别是人们对纺织品的要求越来越高,将更多的注意力聚集在纺织品对人体的危害性[1]上,但以往的纺织品检测方法大都有局限性,例如测量周期长,对检验人员的身体造成伤害,污染环境等。近年来,利用图像处理技术进行纺织品检测逐渐兴起,这种技术不仅可降低人为因素的弊端,有效地检测纺织品的外观以及质量,还可提高劳动生产率[2]。在图像处理技术中,高光谱成像技术比较高效,尽管在纺织领域的应用并不多,但其优越高效的检测方式,不损伤纤维的优点,势必将在纺织行业有广阔的应用空间。
高光谱成像技术结合传统二维成像和光谱技术[3],融合电磁学、光学、信号处理、计算机通信等多学科在光谱维度上进行细致地分割,采集到的图像不但信息丰富、量大,并且识别度高,数据描述模型也比较多[4]。由于该技术具有很高的空间分辨率和谱间分辨率,在军事侦察、地质填图、海洋监测、农业监测、大气和环境监测、航天研究等领域得到越来越广泛的应用[5-6],但是其在纺织行业的应用却刚刚起步[7-9],如应用于棉花杂质的检测和皮棉表面多类异性纤维的检测等[10-12]。杨文柱等[13]提出 780~1 800 nm的近红外波段为异性纤维检测的最优波段;郭俊先等[14]证明高光谱图像可检测多类共存的异性纤维;王戈等[15]利用近红外光谱对竹原纤维、竹粘胶纤维和苎麻纤维进行快速鉴别。本文在利用高光谱成像技术对纤维等进行识别的基础上,尝试利用连续投影算法以及最小二乘支持向量机对织物层面进行识别,在不损伤纤维的情况下,通过相关织物标准样品库的建立、高光谱数据的采集、高光谱数据预处理、高光谱特征提取、纤维成分检测系统的搭建与其校正,试验检测所搭建的系统快速鉴别织物的有效性。
1 材料与方法
1.1 仪器设备与数据处理软件
采用北京卓立汉光仪器有限公司的Gaia Sorter盖亚高光谱分选仪[16-17]采集图像。该仪器其核心部件包括均匀光源、光谱相机、电控移动平台(或传送带)、计算机及控制软件等。仪器的光谱范围为 1 000~2 500 nm,光谱分辨率为10 nm,像元数为 320像素×256 像素。
采用ENVI Classic 5.3(64-bit)和MatLab R2016b软件对高光谱图像数据进行后续处理。前者主要用于感兴趣区域的设定、点和簇像素的平均光谱以及偏差光谱的提取、图像的一般处理;后者主要用于图像的一般处理、特征降维、特征提取和模式识别等运算。
1.2 实验样本与高光谱图像的获取
利用现有的织物样品库,筛选出8种常见的纯纺织物:棉(C)、涤纶(PET)、羊毛(W)、聚乙烯(PE)、聚氯乙烯(PVC)、锦纶(PA)、亚麻(L)、蚕丝(S),其中每种纺织材料织物80块,共计640块样品。从每块织物上裁剪出5 cm×5 cm的布样作为代表该织物样品的小样,最终获得参与拍照及后续处理的8种纯纺织物的640个织物小样。
将织物小样按照种类排列整齐送入高光谱分选仪中进行高光谱图像采集。图像采集前调整曝光时间为15 ms,以确保采集得到的图像清晰、明亮。电动移动平台设置推进线速度为10 mm/s,避免图像失真。每次图像采集前都进行标准白板校正,采集过程中光谱扫描10次,再取其平均值待用。最终获得大小为640 像素×320 像素×256 像素的三维数据块。
1.3 高光谱图像标定
高光谱图像除包含光谱反射与辐射信息之外,还包含各种对图像有干扰的噪声,如传感器仪器的误差、大气散射吸收导致的传输效应、地形造成的误差等,这些会让光谱曲线失真[18],因此,必须对织物高光谱图像进行校准。对高光谱图像进行辐射校正、图像掩膜、图像滤波之后,才能进行后续的提取感兴趣区域(ROI)[19]:通过辐射校正可消除干扰,得到真实反射率数据[20],由于此次试验所用织物均为纯纺织物,纯度较高,且整体平整,选择平场域法处理图像;通过掩膜处理,使得处理后的高光谱图像只保留有效的织物图像区域以及反射率为0的黑色背景区域[21];通过图像均值滤波[22],对图像进行去噪处理[23]。
2 高光谱数据处理
经过高光谱图像标定后,将采集到的每种纯纺织物的80张高光谱图像中所有织物图像区域设置为感兴趣区域(ROI),均值滤波后得到每种织物在920~2 528 nm内的代表光谱曲线。观察原始光谱数据发现,曲线在920~1 000 nm和2 400~ 2 528 nm区间内变化趋势相同,且存在较多噪点,所携带的光谱信息较少,所以在利用连续投影算法对原始光谱数据处理前,先筛选掉这2个区域内的波段,将 288个波长的数据初步压缩至250个,如图1所示。将采集到的每种纯纺织物(80个)随机分为训练集(60个)和测试集(20个),以方便后续特征波长的提取和分类模型的建立。
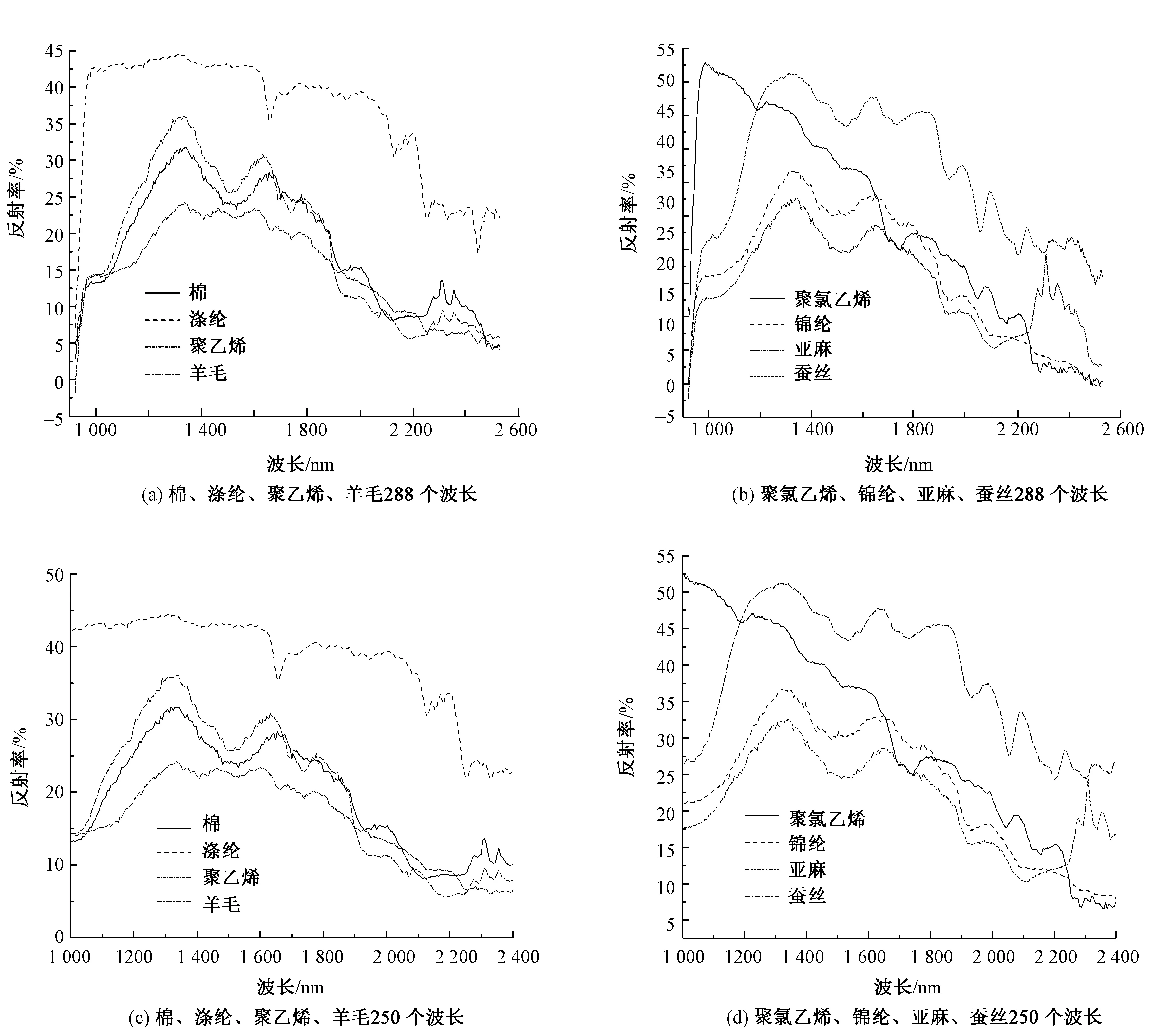
图1 波长与反射率的关系Fig.1 Relationship between wavelength and reflectance.(a)288 wavelengths of C,PET,PE,W; (b)288 wavelengths of PVC,PA,L,S; (c)250 wavelengths of C,PET,PE,W; (d)250 wavelengths of PVC,PA,L,S
2.1 基于连续投影算法的特征波长提取
采用全部250个波长进行训练、筛选时运行数据量大,某些范围内的光谱信息量少,与待测织物的构成及因素缺乏相关关系,因此,进一步对数据进行压缩、降维必不可少。连续投影算法在1965年被提出用来解决凸可行性问题,目前已广泛应用于海洋检测、生物医学成像、森林植被研究、农业生长信息传递、大气辐射监控等领域。连续投影算法可从光谱数据中找到包含最低限度的冗余信息的变量组,使波长变量间的共线性去除,提高光谱信噪比,进而提高模型预测能力[24]。设样本光谱反射率矩阵为Xn×p,性质参数矢量为y,总体样本数为n,全谱波长数为p。波长的确定分为2个步骤。
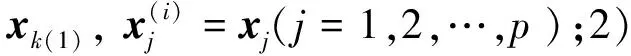
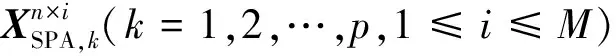
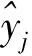
以棉织物为例,利用连续投影算法对棉织物的250个波段进行筛选,样本为验证集的60个待测织物。均方根误差值最小时对应的波长数就是光谱变量的最优解,由测试集的均方根误差预测值确定光谱变量的最优解。模型中包含变量数改变会引起均方根误差改变,其变化如图2所示。若取均方根误差最小值,则为0.426 93,此时变量个数为7。确定的特征波长共7个,按照重要性排序分别为 1 531.4、1 929.2、2 203.7、1 329.8、1 789.1、762.0、1 654.7 nm,此时数据量较最初数据减少97.22%。

图2 均方根误差和与其对应的波长Fig.2 Root mean square error (a) and its corresponding wavelength (b)
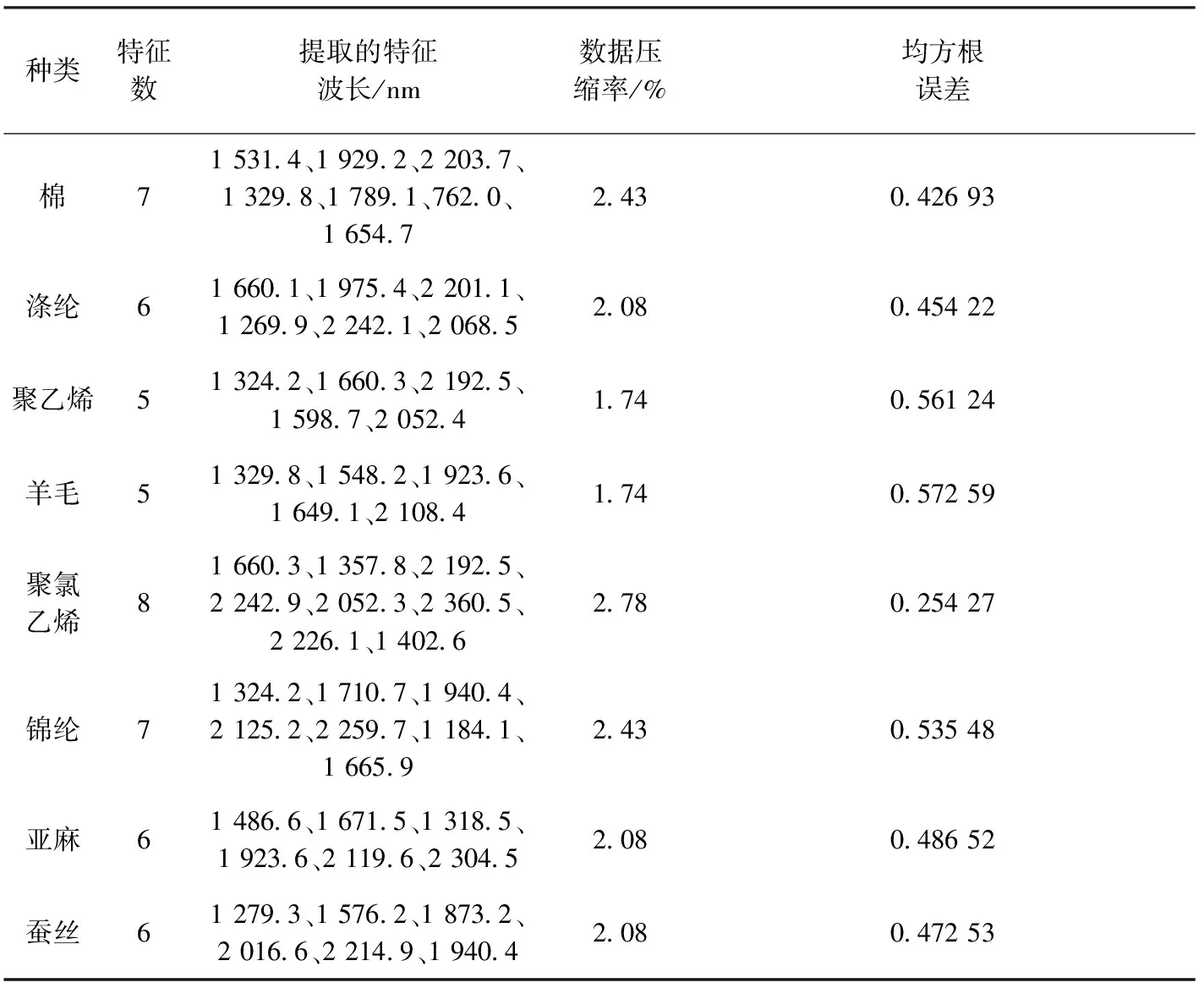
表1 连续投影算法提取的特征波长Tab.1 Characteristic wavelengths extracted by continuous projection algorithm
分别利用连续投影算法提取8种纯纺织物的特征波长,得到的具体数据如表1所示。可知,经过连续投影算法(SPA)处理之后,原始的288个波段被压缩至5~8个特征波长,仅占原始数据的1.74%~2.43%,删减了大量冗余信息,节省了大量的建模时间,且所提取的特征波长所对应的预测均方根误差均小于0.6,有很强的代表性,误差小,符合后续建模要求。
2.2 建立最小二乘法支持向量机分类器
最小二乘支持向量机(LS-SVM)是对标准支持向量机(SVM)的改进,其用等式约束代替了SVM中的不等式约束,通过非线性映射函数φ(x)建立回归模型,利用拉格朗日算子求解最优化问题,对各变量求偏微分。
本文试验采用径向基函数RBF函数作为核函数,其原因为:1)RBF能把样本映射到更高维的空间;2)RBF确定的参数较少,核函数参数的数量直接影响函数的复杂程度。
由此可见,LS-SVM将凸二次规划问题转化为求解线性方程,极大地简化了计算复杂程度,对存储空间要求大大降低,也降低了计算成本。
本文基于核函数为RBF的LS-SVM的相关算法在MatLab 2016b上设计出分类模型,如图3所示。其中模型中的正则化参数gam=10,核参数 sig2=0.2。
图3 以RBF为核函数的LS-SVMFig.3 LS-SVM with RBF kernel function
所建模型中,将棉、涤纶、聚乙烯、羊毛、聚氯乙烯、锦纶、亚麻、蚕丝8种织物的训练集分别导入向量机中进行训练,最终得到8个二类分类器SVM1、SVM2、SVM3、SVM4、SVM5、SVM6、SVM7、SVM8。在识别过程中,将8种织物的验证集和测试集(共640条代表光谱曲线数据)导入SVM1中,分类器分类结果n为1或0,结果为1时即为成功分类,结果为0时就会自动将特征波长输入到下一分类器SVM2,依此类推。若所有分类器输出结果n均为0时,即为无法分类。二类分类器原理及分类器对640个样本分类效果如图4所示。
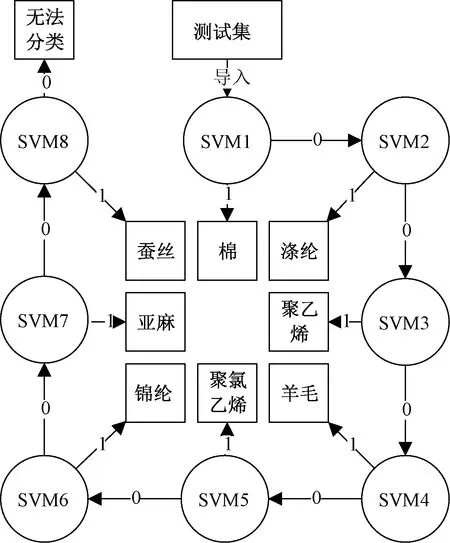
图4 分类器示意图Fig.4 Schematic diagram of classifier
2.3 分类结果
利用连续投影算法(SPA)提取8类共640个纺织样品的特征波长,并将每类80个样品分为训练集(60个)和测试集(20个),最后利用训练集导入基于最小二乘法支持向量机(LS-SVM)建立的二类分类器中,得到了8个二类分类器。8个二类分类器对640个样本分类效果如表2所示。
结果显示,棉、涤纶、聚乙烯、羊毛、聚氯乙烯、锦纶、亚麻、蚕丝8种纯纺织物的60个验证集和20个测试集均得到正确的识别,640个试验样品没有无法识别分类、错误识别分类的情况,所建立模型的识别率和稳定性都符合要求。
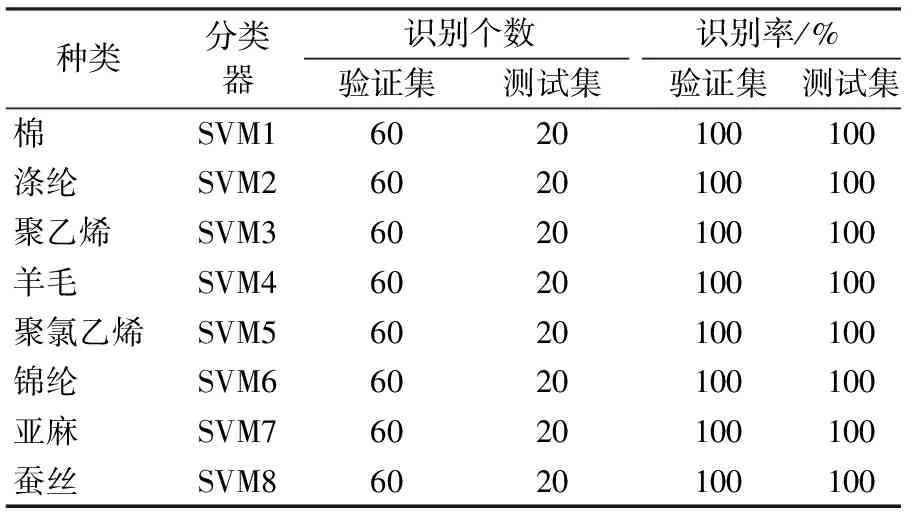
表2 SPA-LS-SVM模型的识别效果
3 结 论
利用高光谱成像技术对由8种常见的天然纤维和合成纤维制成的纯纺织物进行识别,将采集到的 8种织物按照种类分为验证集(60个)和测试集(20个),采用连续投影算法(SPA)结合每种织物的验证集数据,提取出该织物所对应的特征波长数,将原始数据压缩至1.74%~2.43%,大大减少了模型的复杂程度,提高了准确率和运算速度。继而基于最小二乘法支持的向量机对每种织物进行建模得到了 8个二类分类器,并将8种织物的训练集分别导入模型进行训练。最后利用完成训练的分类器对全部640个样本进行识别分类。结果显示对于此8种纯纺织物的640个实验样本,所建模型均可正确识别,高光谱成像技术可用于棉、涤纶、聚乙烯、羊毛、聚氯乙烯、锦纶、亚麻、蚕丝的材料识别。
猜你喜欢
纺织学报(2022年11期)2022-12-23
纺织标准与质量(2022年5期)2022-10-27
材料与冶金学报(2022年2期)2022-08-10
纺织科学研究(2021年7期)2021-12-02
毛纺科技(2021年8期)2021-10-14
纺织科技进展(2021年5期)2021-07-22
纺织科技进展(2021年3期)2021-06-09
计算机应用(2017年4期)2017-06-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
