
无线传感器网络LEACH算法的研究与改进
2018-10-18 02:19严浩伟
小型微型计算机系统 2018年10期
池 涛,严浩伟,陈 明
1(上海海洋大学 信息学院,上海 201306)
2(农业部渔业信息重点实验室,上海 201306)
1 引 言
物联网一般由传感器节点部署在监控区域内,通过无线通信方式将采集到的信息发送给技术人员.由于传感器节点通常是一个微型的嵌入式系统,由干电池供电,它的处理能力、存储能力和通信能力都相对较弱,所以采用合理的调度算法,节省节点的能量以及延长网络生存时间都十分重要.LEACH(Low Energy Adaptive Clustering Hierachy)算法[1]将网络变成层次型拓扑结构,数据通信阶段是通过簇内节点收集信息发送给簇头节点,簇头进行数据融合并且把结果发送给汇聚节点,较好地解决了网络节点能量消耗不均衡的问题.但是该算法中由于簇头节点需要完成数据融合、与汇聚节点通信等工作,所以能量消耗十分大.目前许多学者对LEACH算法进行了改进.文献[2]将网络划分为不同的集群层,采用簇头与簇头之间的通信来节省能量.文献[3]考虑到节点的剩余能量与网络负载平衡,通过选择簇的大小来更改周期.文献[4]提出了VLEACH协议版本,旨在降低节点功耗.文献[5]提出了基于功率管理、能量管理、网络寿命、最佳簇头选择以及多跳数据传输等指标的WSN中各种聚类法.文献[6]根据模糊算法根据节点剩余能量和节点与基站距离计算节点竞争力,通过节点竞争力采用非均匀分簇方法进行簇首选择.文献[7]结合PEGASIS协议提出一种新的能耗均衡的多跳路由算法,优化了簇的结构,均衡了网络能耗,延长了网络生命周期.但迄今为止,改进的算法不是仅考虑了节点的剩余能量就是仅考虑了位置信息,或者俩者结合考虑的时候没有从根源上减小节点能量的消耗.
2 LEACH算法
2.1 算法介绍
LEACH算法选取簇头的过程如下:节点产生一个0~1之间的随机数与预设阈值做对比,如果该数小于T(n),该节点自动成为簇头节点.阈值公式如下:
(1)
其中P是簇头在全部节点中所占的比例,r为经过的轮数,rmod(1/P)表示一轮循环中已经当选过簇头的节点个数,G表示一轮循环中未当选过簇头的节点集合.节点成为簇头以后,广播消息通知其他节点自己是新簇头,非簇头节点根据自己与簇头节点之间的距离来决定加入哪个簇头,并通知该簇头.当簇头接收完所有的节点加入信息后,随即产生一个TDMA定时消息,并且通知簇中所有节点.LEACH算法选择出的簇头节点进行数据融合可以降低全网数据冗余,降低网络能量开销,选择出的簇头进行数据融合后需要定时将数据结果发送给汇聚节点.
2.2 LEACH算法问题描述
LEACH算法使得节点通信变成层次通信,且簇头个数难以控制,容易造成节点分布不均匀.簇头担当了数据融合的任务,减少了其他节点的数据通信量,但簇头节点因为大量的数据通信任务,容易造成节点死亡,从而可能导致网络的瘫痪.同时簇头的选取也没有考虑地理位置和节点能量信息,会造成部分节点死亡过快,从而可能导致系统的网络生命周期缩短.目前相关学者提出的改进算法都存在各自的问题,例如LEACH-C算法[8]利用了模拟退火算法只考虑了节点的能量负载,并未考虑节点位置情况,SEP算法仅考虑了簇头的选取[9].本文结合这三者对LEACH算法进行了改进,提出了GEC算法.
3 GEC算法
3.1 算法详解
GEC算法思想是首先根据簇头计算经验公式得出簇头个数,利用K-means算法将传感器节点进行分簇,分好簇以后将簇内节点距离汇聚节点最近的点作为首轮簇头节点;然后通过分层模型将簇内节点分为3个层次,同时使用分层功率控制技术减小节点能量消耗;最后备选簇头节点直接在簇内第一层内按照节点剩余能量的大小进行选取,GEC算法很好地解决了传统LEACH算法簇头选取的不足,同时通过实验比较,GEC算法相对于LEACH算法以及LEACH的一些改进算法提升了网络生存周期,使得系统更加稳定.
3.2 K-means聚类算法
K-means聚类算法是将n个样本点分成k个聚类,具有方法简单、快速、效果好等特点.本文使用K-means聚类算法首先将n个传感器节点分成k个类,由于K-means聚类算法中k值难以确定,而将它和LEACH算法结合,可以通过簇头经验公式(2)确定k值,而K-means的分类效果远远好于LEACH算法,所以本文结合两者算法思想.
(2)
其中,N是传感器节点总数,Efs是自由空间能量,Emp是衰减空间能量,M是区域边长,dBS为节点到基站的平均距离.根据本文仿真实验参数的设置,求得簇头个数为5.因此K-means算法下的簇头个数为5.本文使用了100个节点进行仿真实验,K-means算法步骤如下:
第1步.从100个传感器节点中随机选中5个簇头点;
第2步.然后求得所有节点到这5个簇头的距离,如节点a距离簇头c值最小,则节点a属于c簇;
第3步.重新计算簇内中心点作为簇头;
第4步.重复2、3步,直到簇头点位置不变.
3.3 簇内分层模型
本文考虑到每次选取簇头时计算量较大,提出基于地理位置的簇内分层算法.具体思路如下:改进的LEACH算法通过K-means算法分好簇以后,我们标记簇内离汇聚节点最近的点,这个点就选为簇头节点,本文设定的仿真实验网络区域为100m*100m,根据节点的实际通讯距离,将簇内节点按照与标记节点的距离分为三个层次.具体过程为:标记节点向簇内节点广播消息,首先标记节点使用功率等级Level a广播数据包,簇内节点收到信息后,反馈一个信息,并将自己处于休眠状态,所有收到信息的节点为簇内第一层.标记节点使用功率等级Level b广播数据包,所有簇内节点收到信息后依照上一步工作,此次所有节点为第二层,剩下的簇内所有节点为第三层Level c.图1是簇内分层的模型,一共将簇分成三个层次.

表1 功率等级与距离的关系

图1 簇内分层模型Fig.1 Hierarchical model of the cluster
3.4 簇头的选取
考虑到LEACH算法选取出的簇头计算量较大且能量消耗大[10],当第一轮簇头节点死亡以后,备选簇头节点直接在簇内第一层内根据节点剩余能量的大小进行选取.当第二轮簇头节点开始选取时,Level a内的节点发送数据包(包括头部00和节点剩余能量),簇头节点判断该节点是否为第一层节点,如果是则通过节点剩余能量的大小来选举.当第一层节点都死亡之后,簇头节点从第二层内依据节点剩余能量大小来进行选取,当第二层节点也都死亡之后,第三层的节点通过剩余能量大小来进行簇头节点的选举,这样只需通过数据包就能判断出节点的位置层次,并且选出的簇头节点具有距汇聚节点距离近和能量多的优势,通过功率的调整,可以尽可能地延长簇头的网络周期,增加了网络的鲁棒性,大大减少了节点的通信开销.
第一轮簇头选取:将节点分为五类S(0)、S(1)、S(2)、S(3)、S(4),根据公式(3)计算每类中节点到汇聚节点的距离,每类中选择最近的点作为簇头节点,首轮为5个簇头节点.
distance=sqrt((S(i).xd-(S(n+1).xd))2+
(S(i).yd-(S(n+1).yd))2)
(3)
备选簇头节点选取:将节点按照所处位置层次进行选择,处在第一层的节点具有高优先级,首先系统判断节点是否处于第一层,若满足,则根据节点的剩余能量看是否为第一层内最多来进行选取,若第一层内的节点都死亡,则第二层节点当选簇头的优先级大于第三层节点,备选簇头节点将在第二层内按照节点剩余能量进行选取.节点剩余能量根据公式(4)计算,备选簇头节点由节点剩余能量最多者当选.
S(i).E=S(i).E-ETX
(4)
其中S(i).E表示节点能量,ETX表示节点发送数据的能量消耗.
3.5 分层功率控制技术
簇内分好层以后,得到了一个三层节点模型,由于标记节点使用不同的功率等级可以和簇内节点顺利通信,所以簇内节点依据不同的位置层次,使用Level a、Level b、Level c三个不同的发射功率可以保证和簇头节点顺利通信,这样保证了簇内节点的连通性.簇头节点的发射功率依据和下一跳节点的距离进行设定.对此本文使用了传感器节点进行试验,芯片为CC2530,Z-Stack可设置功率范围在-22dBm~+3dBm,设定一个板子为终端设备发送数据,一个板子为协调器节点进行接收数据,调节发射节点的功率,这里测试的功率范-22dBm~2dBm,定时发送数据,通过协调器显示信息在串口上.因为实验参数设置,节点的通信半径在87m左右,所以这里选择了可到达的通信距离结果,实验结果见表1.通过分层功率控制技术,可以减小节点的能量消耗,节点功率与距离的关系参照公式(5).
(5)
P表示发射功率,εami和εamo表示放大参数,Rb表示传输速率,distance表示接收节点的距离,do表示节点通信可达距离.通过调整节点发射功率,可以得出节点发送数据时的能耗,见公式(6).
(6)
ETX表示发射单位报文损耗能量,EDA表示多路径衰减能量,εamia表示第一层节点的放大参数,εamib表示第二层节点的放大参数,εamic表示第三层节点的放大参数,K表示数据的发送量.根据式(5)可以求得放大参数,代入式(6)可得节点能量消耗,剩余能量通过初始能量减去消耗的能量求得.通过分层功率控制技术可以减小节点传输数据时的能量开销,而且保证了网络了拓扑结构,延长了网络寿命.
4 模拟实验
GEC算法实验采用MATLAB 2016a进行仿真,仿真参数设置见表2.
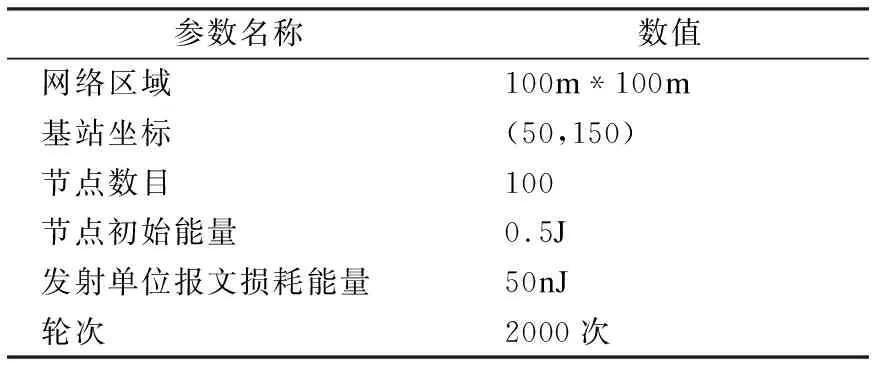
表2 仿真参数表
通过MATLAB仿真,LEACH算法和K-means聚类算法分好簇的结果如图2、图3所示,图2LEACH算法随机生成100个节点,产生了8个簇头(图中+号表示簇头,其他表示节点)且位置分布不合理,分类效果差,有些簇头负载过重,而有的负载过少,图3 K-means聚类算法将100个节点分为了5类,节点分簇效果较好.
通过MATLAB仿真得出的一个簇内分层仿真图如图4所示,通过节点所处位置将簇内节点分为三个层次,依次为Level a(+节点)、Level b(*节点)、Level c(o节点).LEACH算法和GEC算法死亡节点数目对比如图5所示,LEACH算法在进行到900轮次左右时,出现了第一个节点的死亡,到950次左右时,节点开始出现大面积死亡;LEACH-C算法在进行到940轮次左右时,出现了第一个节点的死亡,到950次左右时,节点开始出现大面积死亡;SEP算法在进行到990轮次左右时,出现了第一个节点的死亡,到1110次左右时,节点开始出现大面积死亡.GEC算法在1040轮次左右的时候,开始出现第一个节点死亡,首个节点死亡时间较LEACH算法延长了16%左右,较LEACH-C算法延长了11%左右,较SEP算法延长了5%左右.GEC算法节点在1040-1150 轮次的时候节点死亡较少, 到1150轮次左右的时候,节点开始出现大面积死亡.所以本文提出的GEC算法比LEACH算法系统鲁棒性更强,系统更加稳定,节点生存周期延长.
如图6所示,使用LEACH算法,网络系统进行到2000轮次左右的时候,网络剩余能量几乎耗尽;使用LEACH-C算法,网络系统进行到1800轮次左右的时候,网络剩余能量几乎耗尽;使用SEP算法,网络系统进行到1400轮次左右的时候,网络剩余能量几乎耗尽,当使用GEC算法时,网络进行到2000次左右的时候,网络剩余能量几乎耗尽.网络剩余能量耗尽的时间相较于LEACH算法相近,相较于LEACH-C算法提升了11%左右,相较于SEP算法43%左右.综上两者分析,使用本文的GEC算法延长了整个网络的生命周期,使得网络系统更加稳定.

图2 LEACH算法示意图
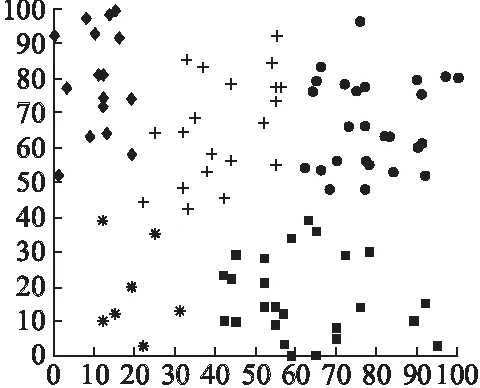
图3 K-means聚类算法示意图Fig.3 K-means clustering algorithm

图4 簇内节点分层Fig.4 Hierarchical nodes in cluster


图5 存活节点Fig.5 Surviving nodes 图6 网络剩余能量Fig.6 Residual energy of network
5 结语及展望
本文较其他改进LEACH算法的不同点在于,通过K-means算法可以较好地实现聚类效果,通过簇内分层技术,可以较快地选择靠近汇聚节点并且剩余能量较大的节点作为簇头节点,延长了网络的生命周期.同时通过分层功率控制技术,使得节点可以顺利通信,保证了不必要的能量浪费.基于粗糙集的数据融合可以很好地去除冗余信息,得出决策规则.本文提出的GEC算法较LEACH算法以及其他改进算法有了较大的提升,延长了系统的生命周期.
针对本文提出的方案,接下来的工作可以从两方面进行加强:首先,本文提出的实验环境没有考虑异构性,如何保证节点在不受其他通信方式影响下顺利工作,是将来工作的研究重点.此外,本文提出的GEC算法只是在MATLAB上进行了仿真,在实际环境中可能受到电磁、环境、硬件本身等影响,稍微影响实验结果.
猜你喜欢
甘肃教育(2021年12期)2021-11-02
军事文摘(2020年18期)2020-10-27
中国航海(2019年2期)2019-07-24
软件导刊(2018年11期)2018-11-19
动漫星空(兴趣百科)(2018年4期)2018-10-26
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
中学生数理化·八年级物理人教版(2016年5期)2016-08-26
中学生数理化·八年级物理人教版(2016年5期)2016-08-26
互联网天地(2016年1期)2016-05-04
