
核协同近邻表示的人脸识别算法
2018-10-18 02:18李昆仑李尚然巩春景
小型微型计算机系统 2018年10期
李昆仑,李尚然,王 琳,巩春景
(河北大学 电子信息工程学院,河北 保定 071000)
1 引 言
人脸识别作为一种代表性的模式识别问题[1],近几年在计算机视觉领域中受到了广泛关注,并且已应用到了诸多领域,例如基于人脸识别的门禁系统、视频监控[2]、行人追踪[3]等.
稀疏表示分类(Sparse Representation based Classification,SRC)[4]算法利用所有训练样本形成过完备字典,通过字典中少量元素的线性组合表示测试样本,最后利用这种稀疏的线性组合完成分类任务.但在寻找最佳线性组合时,稀疏表示分类(SRC)需要线性组合的系数满足L1-范数最小化的约束条件.文献[5]指出在表示未知样本时,训练样本的类间协同性有着更重要的作用,即实际改善人脸识别效果的并不是稀疏表示,而是协同表示,并且提出了协同表示分类(Collaborative Represention based Classification,CRC)算法.协同表示分类(CRC)利用L2-范数最小二乘法求解表示系数,不仅达到了与稀疏表示分类(SRC)近似的识别效果,而且还降低了时间复杂度.文献[6]在最近子空间(Nearest Subspace,NS)分类器中加入吉洪诺夫正则项,随后与协同表示分类(CRC)结合,提出最近正则子空间(Nearest Regularized Subspace,NRS)分类器.为了强化最近正则子空间(NRS)的分类能力,文献[6]又将样本投影到局部Fisher判别分析(Local Fisher Discriminant Analysis,LFDA)[7]的局部投影空间中,在局部投影空间中构造吉洪诺夫正则矩阵.文献[8]将协同表示分类(CRC)与局部线性嵌入(Locally Linear Embedding,LLE)[9]结合,提出协同近邻表示分类(Collaborative Neighbor Representation based Classification,CNRC)算法.协同近邻表示分类(CNRC)利用欧式距离作为度量准则,在训练样本中自动地选择最近邻点作为表示基,将选择的表示基和所有训练样本结合,利用正则最小二乘法求解线性表示系数,最后通过表示系数线性地重构未知样本,进一步强化表示能力,改善识别效果.
协同近邻表示分类(CNRC)利用样本间的相似性表示人脸特征,由于忽略了因相似性造成的非线性性,使得它主要面临以下两个问题:
1)在输入空间中利用欧式距离寻找未知样本的最近邻点,选择的表示基很难准确表示测试样本,导致识别误差增大;
2)由于忽略了样本间的非线性关系,使得协同近邻表示分类(CNRC)很难利用样本的非线性特征向量,从而限制了它的分类性能.
在解决非线性问题时,最常用的方法是引入核方法.核方法有诸多特点:
1)核方法定义的非线性映射将输入空间的数据投影到高维甚至是无限维的核空间[10],在一定程度上使输入空间中非线性可分的特征向量在投影到核空间后线性可分;
2)通过核方法的非线性映射,可以改变样本的分布,更容易聚集同类样本,并可达到分类间隔的最大化;
3)由于核方法是基于VC维理论的,因而具有优秀的泛化能力.考虑到核方法在解决非线性问题时的优势,文献[11]将输入空间的样本投影到核空间,在核空间中构造稀疏表示分类(SRC)算法,提出基于核方法的稀疏表示分类(Kernel based Sparse Representation Classification,KSRC)算法.由于引入核方法必定会增加算法的时间复杂度,并且核稀疏表示分类(KSRC)仍需要求解L1-范数的最小化问题,文献[12]将样本投影到核空间后,利用协同表示分类(CRC)的正则最小二乘法构造表示框架,在核空间中嵌入协同表示分类(CRC),提出核协同表示分类(Kernel Collaborative Representation Classification,KCRC)算法.文献[7]在局部Fisher判别分析(LFDA)的降维过程中进一步考虑到非线性问题,利用核方法构造局部Fisher判别分析(LFDA),提出核局部Fisher判别分析(Kernel Local Fisher Discriminant Analysis,KLFDA)算法.
针对协同近邻表示分类(CNRC)忽略了样本间非线性关系的问题,本文利用核函数能改变样本空间分布的性质,对协同近邻表示分类(CNRC)进行两点改进:
1)利用核局部Fisher判别分析(KLFDA)的核局部投影空间定义度量准则distKLFDA,提出基于核局部投影度量的协同近邻表示分类算法(CNRC_KLFDA).CNRC_KLFDA利用distKLFDA将样本向量投影到核局部投影空间中,改变样本的空间分布,在增大类间离散度和减小类内离散度的同时,使得协同近邻表示分类(CNRC)在寻找最近邻表示基时能利用一定程度的非线性关系,改善识别效果.
2)引入适当的核函数,将所有样本投影到核空间,在核空间中利用核近邻[13]算法寻找未知样本的最佳表示基,提出基于核方法的协同近邻表示分类(Kernel based Collaborative Neighbor Representation based Classification,KCNRC)算法,核协同近邻表示分类(KCNRC)不仅能强化训练样本的表示能力,而且通过核方法的非线性映射,在一定程度上使一些线性不可分的样本特征向量在核空间中线性可分,能进一步提高识别性能.
2 核方法和核局部Fisher判别分析
2.1 核方法
文献[14]指出,利用核方法的非线性映射,几乎所有的线性方法都可以找到对应的非线性方法.假设非线性映射为φ,φ将原始空间m中的样本x投影到核空间H中:
m→H,x→φ(x)
(1)
通常情况下,由于我们不知道非线性映射φ的具体形式,样本数据通过核方法投影到核空间后是无法计算的.但是利用核函数,使数据在核空间中的内积可以通过核函数求得[25],这样既使在不知道映射函数具体表达式的情况下,依然可以得到数据在核空间的解,即:
k(x,y)=〈φ(x),φ(y)〉
(2)
这里〈φ(x),φ(y)〉为φ(x)和φ(y)在高维空间的内积,k(x,y)是x和y的核函数.
2.2 协同近邻表示分类(CNRC)
定义D=[D1,D2,…,Dc]∈m×n为所有样本组成的训练集,Di=[di,1,di,2,…,di,ni]∈m×ni表示第i类训练样本,这里i=1,2,…,c,n1+n2+…+nc=n,其中Di中的每个列向量表示一个样本,共c类.CNRC从训练样本中寻找最佳的表示基,这些表示基张成的线性子空间和未知样本y∈m×1所在的子空间近似相等,且它们能线性地重构y,最后利用最小二乘法构造协同近邻表示函数:
(3)
求解式(3)可得:
x=(DTD+λI+σDNH)-1DTy
(4)

2.3 核局部Fisher判别分析

(5)
(6)
式(5)和式(6)中的Ai,j∈[0,1]为n维的度量矩阵,Ai,j表示A的第个(i,j)元素,di与dj的距离越小,对应的Ai,j越大,一般采用欧式距离作为度量方法.给定核函数k(x,y),核局部投影空间定义为求解广义特征值问题:
KL(m)Kφ=λKL(w)Kφ
(7)

Ki,j=〈φ(di),φ(dj)〉=k(di,dj)
(8)
令式(7)解得的特征值λ1≥λ2≥…≥λr,则前P≤r个特征值所对应的特征向量构成核局部投影空间TKLFDA=(φ1,φ2,…,φp)∈m×p.
3 基于核方法的协同近邻表示分类框架
3.1 基于核局部投影度量的协同近邻表示分类算法(CNRC_KLFDA)
给定属于第i类的测试样本y,CNRC认为在局部流形域内的近邻样本,比流形域外的其它样本能更好的表示y,所以在寻找表示系数的过程中,CNRC利用欧式距离优先选择y的最近邻点作为表示基.
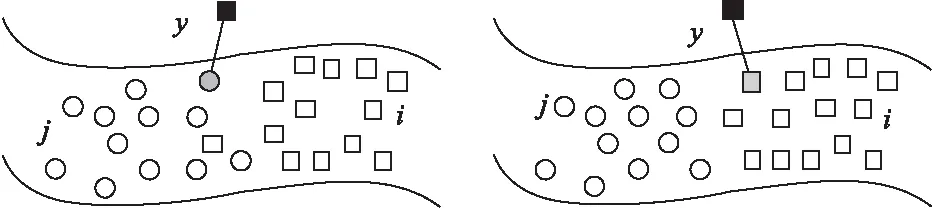

图1 CNRC表示基选择Fig.1 Representation bases selection of CNRC图2 核局部投影度量示意图Fig.2 Diagram of kernel local projection metric
由于一些特征向量在输入空间中存在着非线性关系,欧式距离很难准确选择未知样本的最佳表示基,如图1所示,小圆表示第j类,方块表示第i类,黑色实心方块表示y,灰色实心圆表示利用欧式距离选择的最近邻表示基,而在输入空间中利用欧式距离选择的最近邻表示基属于第j类,此时利用它和所有训练样本重构y,会使y与第j类最相似,最终导致误分类.KLFDA在确保样本类内散度最小,类间散度最大的基础上引入核方法,生成核局部投影空间,通过核局部投影空间的投影后,一部分线性不可分特征向量变得线性可分.本文利用KLFDA的核局部投影空间对输入样本进行非线性投影,定义非线性度量准则:
(9)
经过TKLFDA投影后,投影样本的空间分布被改变,样本类间距离增大,类内间距减小,如图2所示,此时利用distKLFDA所选择的最近邻表示基属于第i类,所以重构的样本与第i类最相似,这样便使得识别性能改善.
针对CNRC在寻找最佳表示基时无法利用样本间非线性特征向量的问题,本文在KLFDA的核投影空间中寻找能够表示未知样本的最佳近邻点,提出基于核局部投影度量的协同近邻表示分类(CNRC_KLFDA)算法.如图2所示,在KLFDA的核投影空间中通过非线性映射使得同类样本更容易聚集,在此基础上CNRC_KLFDA利用式(9)定义的非线性度量准则distKLFDA选择能够更加准确重构y的表示基,从而提高识别率.CNRC_KLFDA在CRC的框架中利用distKLFDA选择表示基,为了使距离y越近的表示基获得的权值越大,同时使得求解的表示系数中距离y越近的表示基系数权值越大,本文定义CNRC_KLFDA的目标函数为:
(10)

(11)
此时,
(12)
求得x后,可得每类样本的重残差:
(13)
CNRC_KLFDA算法描述如下:
算法1.CNRC_KLFDA
输入:字典D,未知样本y,平衡参数σ>0和λ>0,核函数k(x,y).
1.字典和未知样本归一化.
2.利用式(7)解得核局部投影空间TKLFDA.
3.通过式(9),(11),(12)求解表示系数.
4.通过式(13)计算各类重构残差ri(i=1,2,…,c).
输出:y所属类别,identity(y)=argminiri(y).
3.2 基于核方法的协同近邻表示分类算法
CNRC_KLFDA在寻找最近邻表示基时,通过核局部投影空间改变样本的空间分布,利用distKLFDA寻找y的最近邻表示基完成识别任务.本文提出第二种改进方法,将所有样本投影到核空间,在核空间中嵌入CNRC,提出基于核方法的协同近邻表示分类 (KCNRC)算法.首先,KCNRC利用非线性映射φ,将所有样本投影到核空间H:
Di∈m→Φi∈H
D∈m→Φ∈H
y∈m→φ(y)∈H
(14)
公式(14)中Φ=[Φ1,Φ2,…,Φc]=[φ(D1),φ(D2),…,φ(Dc)]为训练集在核空间的表达形式,第i类的训练集为Φi=[φ(di),φ(di),…,φ(di)],i=1,2,…,c,φ(y)代表核空间中的未知样本.核空间中样本φ(x)和φ(y)之间距离的平方为:
d2(φ(x),φ(y))=k(x,x)-2k(x,y)+k(y,y)
(15)
则,定义KCNRC的目标函数为:
(16)
求解公式(16)可得:
x=(ΦTΦ+λI+σΓTΓ)-1ΦTφ(y)
(17)
是公式(17)中ΓTΓ表示在核空间中和φ(y)每个训练样本的距离所组成的对角矩阵:
(18)

(19)
为了进一步减小计算复杂度,本文引入定理1,重新定义残差函数:
(20)

证明:
令
(21)
则式(19)的残差方程可重新定义:
(22)

(23)

显然,公式(20)在核空间中可以利用核函数求得,最终将未知样本y分到残差最小的类别中.KCNRC算法的具体识别步骤如算法2.
算法2.KCNRC
输入:字典D,未知样本y,平衡参数σ>0和λ>0,核函数k(x,y).
1. 字典和未知样本归一化.
2. 通过式(15),(17),(18)求解表示系数.
3. 通过式(20)计算各类重构残差ri(i=1,2,…,c).
输出:y所属类别,identity(y)=argminiri(y).
4 实验结果与分析
为了验证CNRC_KLFDA和KCNRC算法对光照、姿态、面部表情变化的鲁棒性,用ORL人脸库、AR人脸库[15]、Extended Yale B人脸库[16]3个不同的人脸数据库验证它们的有效性.对于核函数的选择,本文对提出的两种算法都采用高斯核函数k(x,y)=exp(-‖x-y‖2/t).所有的实验在CPU为i5-4200U,2.30GHZ,内存为4G的计算机上运行,实验软件为MATLAB- 2016a.
4.1 人脸库
ORL人脸库包括40类,每类10副图像,图像大小为92×112,包括姿态和面部表情变化,部分人脸图像如图3所示.
AR人脸库包括4000副图像,共126人,每幅图像的大小为120×165,包括面部表情变化,光照变化和人脸遮掩图像.我们采用文献[4]和文献[5]的实验方法,选取人脸库的一个子集,这个子集包括光照变化和面部表情变化,由50名男性和50名女性组成,每人14副图像.部分人脸图像如图4所示.

图3 ORL数据库中的部分人脸图像Fig.3 Part of the face image on ORL database

图4 AR数据库中的部分人脸图像Fig.4 Part of the face image on AR database
Extended Yale B 由38个人的2414副人脸图像组成,每人64副图像,该数据库为光照变化数据库,且光照变化范围较广,主要用来验证算法对光照的鲁棒性,部分人脸图像如图5所示.

图5 Extended Yale B数据库中的部分人脸图像Fig.5 Part of the face image on Extended Yale B database
4.2 参数设置
合适的参数可以让实验结果达到更好的效果,此部分采用PCA[17]提取图像特征.
1)ORL数据库:随机选取每类的5副图像共200副作为训练集,剩下的为测试集,人脸图像降到80维,取0<σ<1,0<λ<1,采用格点搜索法,改变一个参数,固定剩下的参数.核函数的参数设置采用整体到局部的搜索策略,t的搜索为范围从1到15,每个参数的改变都取20次实验的最大平均识别率,表1为ORL人脸库上最佳参数和对应的识别率.

表1 ORL人脸库上的最佳参数和对应的识别率Table 1 Best parameters and the corresponding recognition rate on ORL face database
2)AR人脸库:每次实验都随机选取每人的7副图像作为训练集,剩下的为测试集.将所有样本降维到300维进行参数设置,t的搜索为范围从1到20,每次改变参数都重复20次实验,表2为AR人脸库中最佳参数和对应的最大平均识别率.

表2 AR人脸库上的最佳参数和对应的识别率Table 2 Best parameters and the corresponding recognition rate on AR face database
3)Extended Yale B数据库:随机选取每类的32副图像作为训练集,剩下的为测试集,将所有样本降维到500维进行参数设置,t的搜索为范围从1到25,每次改变参数都重复20次实验,表3为Extended Yale B人脸库上最佳参数和对应的最大平均识别率.

表3 Extended Yale B人脸库上的最佳参数和对应的识别率Table 3 Best parameters and the corresponding recognition rate on Extended Yale B face database
4.3 特征向量维数对识别效果的影响
特征向量维数的大小将直接影响算法的识别效果,特征向量维数越大,保留原图像的特征信息也就越多,识别的效果也就越好.为了验证本文所提算法的识别效果,训练样本的选择方式与4.2节一样,对比的算法有KSRC,KCRC,CNRC.算法的参数采用4.2节的最佳参数,最终取20次实验的平均识别率,实验结果如图6~图8所示,对比实验结果可以发现:

图6 ORL数据库中不同特征向量维数和对应的识别率Fig.6 Different feature dimension and corresponding recognition rate in ORLdatabase

图7 AR数据库中不同特征向量维数和对应的识别率Fig.7 Different feature dimension and corresponding recognition rate in AR database
1)在CNRC中引入核方法后,能到达更好的识别效率,特别是在低维时,比如在ORL数据库中,当人脸特征为10维时,CNRC_KLFDA和KCNRC比CNRC的识别率要高10%~15%,这是由于在低维时,样本间线性不可分的特征较多,此时能充分发挥核方法的优势,将一部分线性不可分的特征变得线性可分,能明显改善识别效果.

图8 Extended Yale B数据库中不同特征向量维数和对应的识别率Fig.8 Different feature dimension and corresponding recognition rate in Extended Yale B database
2)当特征向量维数较低时,CNRC_KLFDA和KCNRC比CNRC都有较高的识别率,但随着特征维数的增加,CNRC_KLFDA的识别效果与KSRC和KCRC基本相同.而KCNRC并没有这种局限性,因为它将所有样本投影到核空间,在核空间中样本的分布被改变,样本类内距离减小,类间距离增大,所以将原始算法嵌入到核空间后能达到更好的识别效果.从实验结果中也可以看出,KCNRC的识别率要比CNRC_KLFDA高出1%~2%.
5 总 结
核方法在解决模式识别的非线性问题时所表现的高效性,使得很多算法在引入核方法后能取得更好的效果.在人脸识别任务中CNRC属于线性算法,无法利用人脸图像的非线性关系,针对此问题,本文引入核方法,提出两种改进算法:
1)在CNRC选择最佳表示基时,在KLFDA的核局部投影空间中定义新的度量方法distKLFDA代替输入空间中的欧式距离,distKLFDA在核局部投影空间中度量样本特征向量之间的距离,寻找能表示未知样本的最佳表示基.
2)将所有样本投影到核空间,将CNRC嵌入到核空间中,一定程度上解决了原始算法的非线性问题,提高识别效果.最终的实验结果证明了本文所提算法对人脸的光照,姿态,表情变化的鲁棒性.
CNRC_KLFDA仅仅在核局部投影空间中选择样本的最佳表示基,只是利用到样本的局部非线性特征,很难达到更高的识别效果.KCNRC虽然能进一步利用到所有样本的非线性特征,改善识别效果,但由于引入了核方法,并且需要设置较多的参数,当训练样本增加时,会进一步增加算法的时间复杂度.受字典学习[18-20]的启发,本文的下一步工作是对训练样本进行学习,去除训练样本中的冗余元素,使在增加训练样本的情况下,尽可能地减小计算复杂度.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
数学学习与研究(2018年15期)2018-11-12
动漫星空(2018年9期)2018-10-26
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
