
高分一号影像地物识别精度分析
2018-12-26 08:35张志勋常永青朱理想
地理空间信息 2018年12期
张志勋,常永青,王 春,朱理想
(1.如皋市勘测院,江苏 南通 226500;2南京市规划局,江苏 南京 210029;3滁州学院,安徽 滁州 239000;4.南京市测绘勘察研究院股份有限公司,江苏 南京 210019)
随着高分遥感技术的发展,国内外学者使用高分影像数据进行了广泛的研究[1-3]。目前国外主要的高分卫星影像数据主要有IKONOS、QuickBird、World View等。高分一号(GF-1)卫星是我国发射的第一颗高分辨率卫星,已经运行超过4 a时间,其获取的影像主要包括地面分辨率优于2 m的全色影像和地面分辨率优于8 m的多光谱影像,其中多光谱影像主要包括4个波段,分别为蓝光波段(0.45~0.52μm)、绿光波段(0.52~0.59μm)、红光波段(0.63~0.69μm)和近红外波段(0.77~0.89μm)。目前,高分一号数据被广泛应用于土地利用、城市发展及农业生产等多个领域[4-6],取得了较好的成果。
在影像数据应用过程中,常涉及到影像的分类问题,而分类精度决定分类结果是否可用。常用的传统分类方法主要是目视解译和基于统计分析的分类方法[7],其中基于统计分析的分类方法主要分为监督分类和非监督分类,采用不同的分类方法得到的结果精度也有所差别。目前,在监督分类中,最大似然法(maximum likelihood,ML)[8-9]和支持向量机法(support vector machine,SVM)[10-11]应用最为广泛。传统分类方法算法成熟,在软件中操作简便。将不同分类方法应用在我国高分影像的分类中,对我国高分影像的影像分类问题的研究具有参考价值。本文采用监督分类和非监督分类对GF-1影像数据进行分类,并对分类结果进行精度验证,以探讨各分类方法在GF-1影像分类中的适用性,寻找最佳分类方法。
1 数据来源
本研究采用的是国产高分卫星GF-1号遥感数据,影像获取时间为2014-04-27。影像中心坐标为115°55′47″E、40°30′52″N,主要包括北京西北部区域和河北部分区域,选取的实验区位于北京市延庆区西北部龙庆峡风景区东南部区域,该区域为温带季风气候,以暖温带落叶阔叶林为主,其中夹有部分针叶林,耕地主要是旱地。研究区域内影像云量为0,主要地类包括了林地、草地、耕地、水域和建设用地,土地类型相对齐全。

图1 研究区融合影像
由于多光谱影像与全色波段影像存在空间位置误差,因此需要对影像进行几何校正,参照多光谱影像,对全色波段影像进行校准。采用高斯-克吕格投影和二项式校正方式,校准精度小于0.5 个像元。裁剪实验区域影像数据,采用Gram-Schmidt Spectral Sharpening(GS)融合方法进行影像融合[12],使用标准假彩色(Band4 Band 3 Band 2)显示(图1)。
2 研究方法
2.1 分类方法
为寻找到较好的影像分类方法,选取ENVI软件监督分类方法中的Maximum Likelihood(ML)、Mahalanobis Distance(MsD)、Minimum Distance(MD)和Support Vector Machine(SVM)以及非监督分类方法中的ISODATA和K-Means等分类方法进行影像分类。
2.1.1 ML法
最大似然法是根据像元归属概率进行类别划分的分类方法,其使用的是一个概率模型,分类时假定各类分布函数呈正态分布,因此对选择的训练样本要求较高。分类器公式如下[13]:
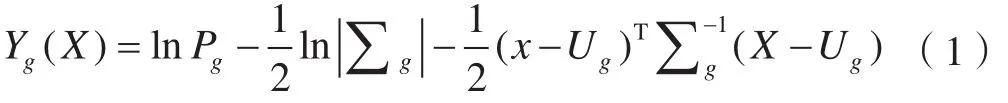
式中,Pg表示第g类样本的概率;Ug表示第g类样本的总体均值向量(下同);∑g表示第g类总体协方差矩阵(下同);表示∑g的逆矩阵(下同);X表示像元特征向量,T表示向量转置(下同)。
2.1.2 MsD法
马氏距离法根据数据协方差距离,判别影像像元与各地类训练样本之间的相似度,进而进行影像分类。马氏距离公式为[14]:
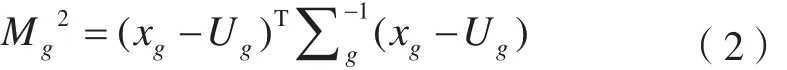
式中,xg表示第g类样本的m维向量;xg=(x1,x2,……,xm)T。
2.1.3 MD法
最小距离法根据各地类均值向量和标准差向量计算像元到各地类中心的距离,以最小距离为依据进行类别划分,常采用欧几里得距离公式[15]:
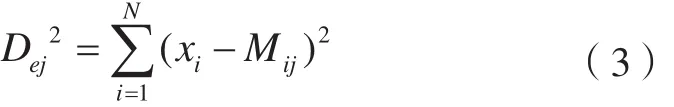
式中,N表示波段数;xi表示像元的第i个波段像元值;Mij表示在第i个波段第j类的像元均值。越小说明该像元越接近第j类地类,归为值最小的那一地类。
2.1.4 SVM法
支持向量机是能够基于有限样本进行统计学习的算法,应用范围非常广泛。支持向量机包括了线性和非线性两种,在图像分类中对训练样本的要求较低。支持向量机分类训练形式如下[16]:
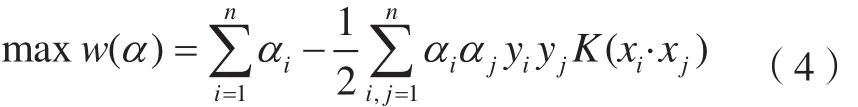
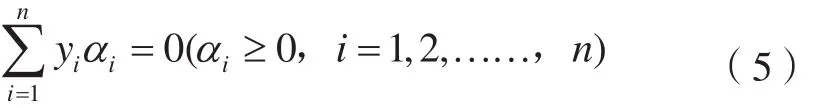
式中,K(xi·xj)=Φ(xi)TΦ(xj)是核函数;一般有线性核、多项式核、RBF核和Sigmoid核等形式。
2.1.5 ISODATA法
迭代自组织数据分析算法是一种典型的非监督分类方法,是一种应用聚类分析思想对像元进行类别划分的方法。根据不同类别聚类中心的距离判断进行多次合并与分类,最终得到相对优化的聚类结果。ISODATA算法的详细步骤参见参考文献[17]。
2.1.6 K-Means法
K-Means算法也是一种常见的非监督分类方法,采用的是聚类思想,其分类标准是误差平方和的大小,具体形式如下[18]:
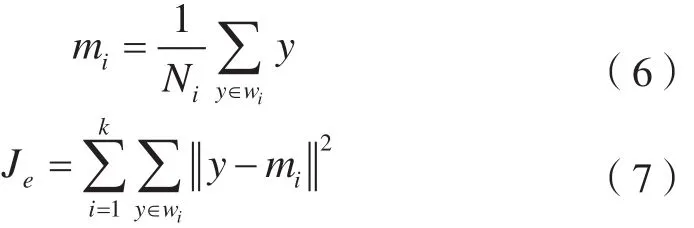
式中,mi表示样本像元均值;Ni表示第i个聚类wi中的样本数;Je表示样本集y和类别集Ω的误差平方和准则函数。然后进行聚类中心修改,并重新计算Je值,直到其不再发生新值变化。
监督分类需要选择合适的训练样本,一般在样本选择时应尽量保证各地类样本均呈正态分布,同时不同样本之间应避免重复像元。因此参照Google Earth卫星地图选择训练样本,在实验影像上根据研究区实际情况,共分为林草地、耕地、水域和建设用地四大类,每个地类的训练样本都不少于100个像元,并对训练样本进行可分离性检验,可分离系数大于1.9的表示可分离性较好,小于1. 8的需要重新选择训练样本或者进行地类合并。本研究中,除耕地–建设用地可分离系数为1.899外,其他各地类组合类型的可分离系数均大于1.99,训练样本满足要求。非监督分类ISODATA分类中,分类数设置为5~10,最大迭代次数设置为20次,非监督分类K-Means分类中分类数设置为10。
2.2 验证方法
分类精度验证主要包括分类面积精度验证和分类结果空间位置精度(即像元精度)验证。本研究采用面积统计对分类结果进行面积精度验证,分别采用基于真实地表感兴趣区和目视解译影像的混淆矩阵,对分类结果进行像元精度验证。真实地表感兴趣区参照Google Earth卫星地图在研究区影像上进行选择,由于研究区域范围较小,因此采用点选式,各地类分别均匀地选取了120个点。目视解译结果由于可以参考的信息较多,一般与实际地物分布十分接近,可以看成是实际地物分布结果,特别是高分影像,由于地面分辨率较高,其目视解译的结果与实际地物分布能够有较高的吻合度。因此参考Google Earth卫星地图,使用ArcGIS软件对研究区处理后的影像进行目视解译,解译地类与分类地类相同,并在ENVI软件中将矢量文件转换为分类影像文件,以目视解译结果作为真实地类分布。
3 结果分析
3.1 分类结果
分别采用监督分类和非监督分类共6种分类方法进行影像分类,并对研究区影像进行目视解译,最终结果见图2。由图2可以看出,6种分类结果差异较为明显,尤其是建设用地和耕地的结果,ML、MsD和SVM3种方法的分类结果一致性较好,与目视解译结果吻合度较高,MD和K-Means分类结果的斑块完整性较差,斑块明显破碎。除K-Means分类外,各分类结果的水域分布总体一致。从目视解译结果可以看出,研究区内,林地和耕地面积分布最广,林地、耕地和建设用地之间的交叉区域较多,水域较为集中且与其他地类之间分割明显。
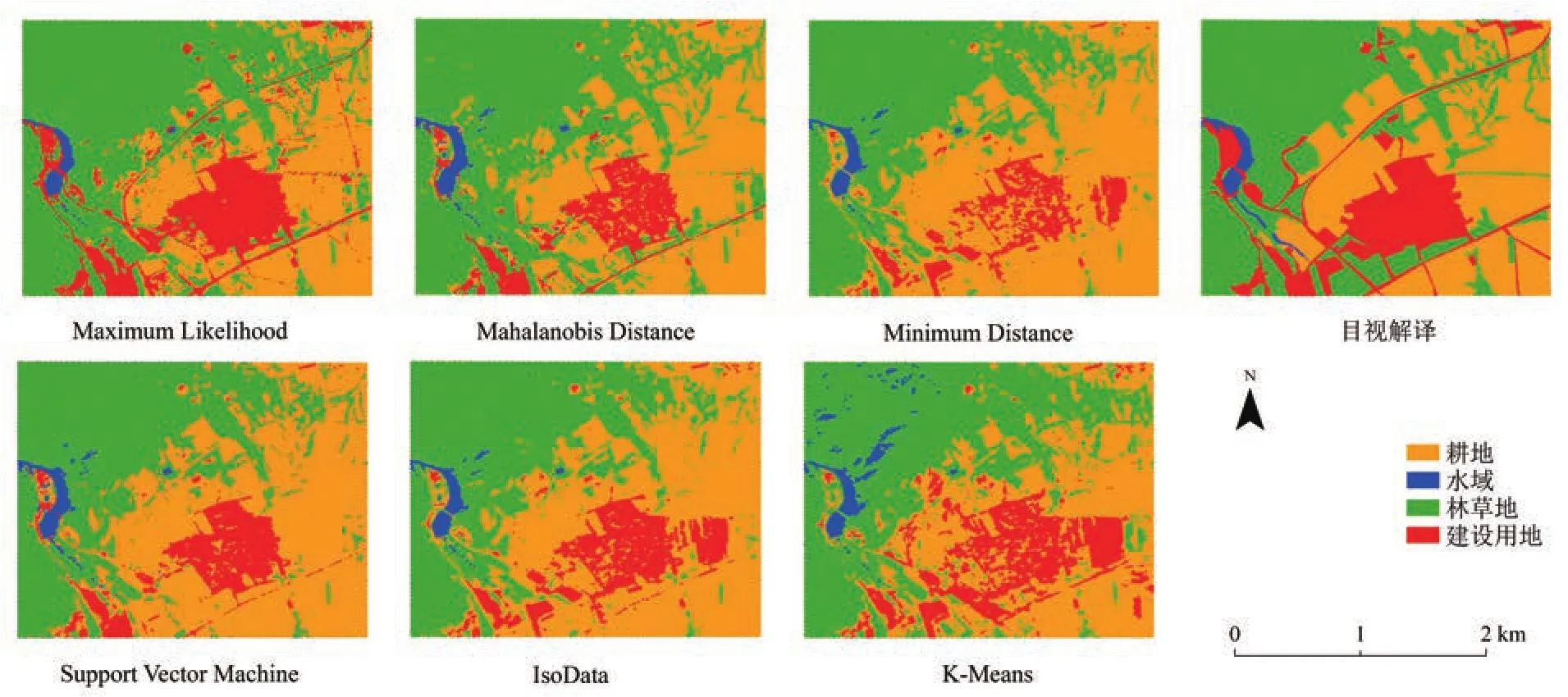
图2 分类结果
3.2 精度验证
3.2.1 面积精度
在ENVI软件中使用统计工具,对各地类的像元数进行统计;在Excel表格中计算各地类的面积,统计面积占比,并计算其相对于目视解译结果的分类方法的标准误差和地类标准误差(表1)。
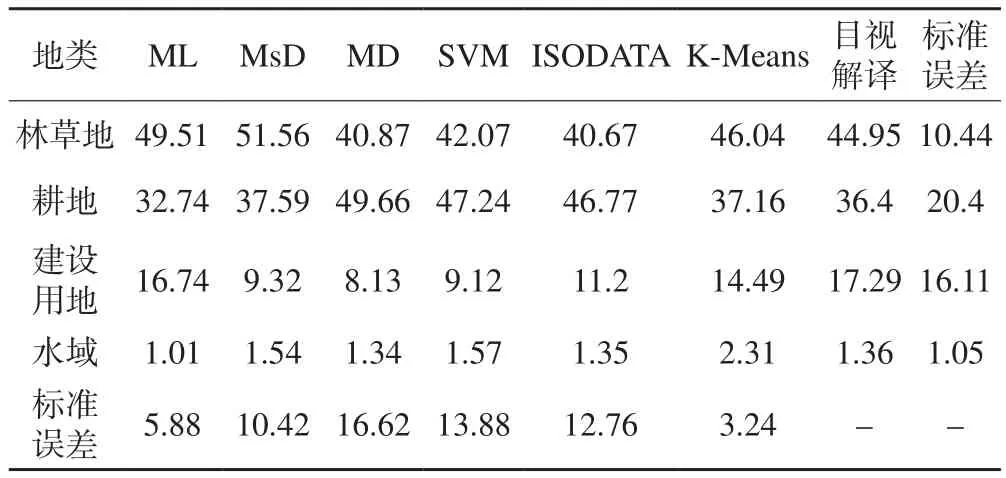
表1 分类结果面积占比统计及标准误差/%
由表1可知,ML 和MsD分类结果中林草地面积占比明显多于其他分类方法的分类结果,MD、 SVM和ISODATA分类结果中耕地面积占比最大。从面积占比上看,K-Means分类结果与目视解译结果最为接近,标准误差最小,为3.24%,精度最高,其次是ML分类方法,MD和SVM分类结果的面积精度较低。各地类中,水域面积占比标准误差为1.05,分类精度最高,说明各种分类方法都能够很好地将水域与其他地类区分开;误差最大的是耕地,由于耕地类型具有较为复杂的光谱信息,与其他地类存在较多异物同谱的现象,其中作物生长较好的耕地易与林地同谱,土质较硬或沙石较多且处于休耕期的耕地易被分为裸地或建设用地;北方耕地多为旱地,因此与水域不会存在异物同谱现象。
3.2.2 基于地表真实感兴趣区的像元精度
使用ENVI软件,依据实际地类新建一组感兴趣区文件,与各分类方法的分类结果进行混淆矩阵分析,统计各分类结果的总体精度、Kappa系数,并计算各地类用户精度的平均值。计算平均用户精度是为了避免因某一地类占比过大而导致总体精度和Kappa系数失真的问题,统计结果见表2。
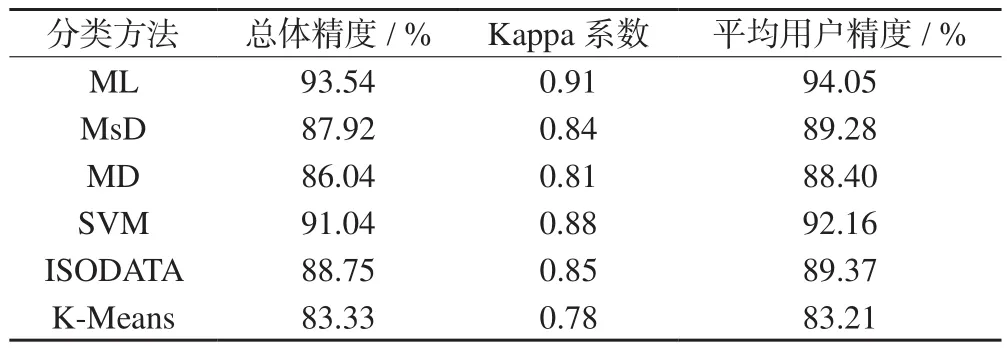
表2 分类精度结果
由表2可知,各分类方法中基于地表真实感兴趣区的总体像元精度均高于80%,分类结果较好。其中ML的分类结果总体精度最高,为93.54%,Kappa系数为0.91;其次是SVM分类,总体精度为91.04%,Kappa系数为0.88。监督分类结果明显好于非监督分类,非监督分类中ISODATA分类结果的精度较好,分类总体精度仅次于ML分类和SVM分类,而K-Means分类结果较差,整体精度在各分类方法中最小。平均用户精度与总体精度接近,且整体上略高于总体精度,与总体精度相差较小;其中,相差最大的是MD分类,差值为2.36%,说明本研究结果的总体精度受较大地类的影响不明显,总体精度的结果较为可靠。
3.2.3 基于目视解译的像元精度
将目视解译结果作为真实地类影像结果,与各分类方法的分类结果进行混淆矩阵分析,统计各分类结果的总体精度、Kappa系数,并计算各地类用户精度的平均值,结果见表3。
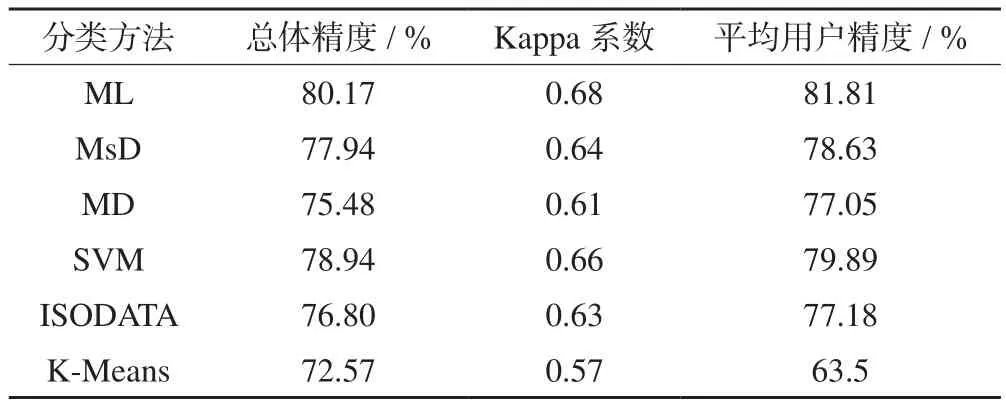
表3 分类精度结果
由表3可知,各分类方法中基于目视解译的总体像元精度在72.57~80.17%之间,与基于地表真实感兴趣区的像元精度相比较低。其中,总体精度最高的是ML分类,为80.17%,其Kappa系数为0.68;其次是SVM分类,总体精度为78.94%,Kappa系数为0.66。与基于地表真实感兴趣区的像元精度验证结果类似,基于目视解译像元精度验证中用户平均精度整体略高于总体精度,总体精度的结果较为可靠,监督分类结果优于非监督分类。
4 结论与讨论
本研究基于GF-1号影像数据,通过比较监督分类和非监督分类共6种分类方法的分类精度,得到如下结论:6种分类结果差异较为明显,但是ML、MsD和SVM 3种方法的分类结果一致性较好;与目视解译结果相对比,各类分类方法中K-Means分类面积误差最小,精度最高,其次是ML分类方法;基于地表真实感兴趣区和基于目视解译的像元精度结果趋同,总体精度最高的均为ML分类,监督分类结果整体上优于非监督分类,非监督分类中ISODATA分类结果最好,甚至优于部分监督分类的分类结果。
面积精度最高的K-Means分类的两种基于像元精度验证的总体精度分别为83.33%和72.57%,均为精度最低。说明面积精度并不能真实反映分类结果的精度情况,因为分类中存在错分地物面积相互抵消的情况,这就使得像元精度较低的分类结果可能会有较高的面积精度。因此,在验证分类结果时,不宜采用面积精度,而应该使用像元精度。
结合两种基于像元分类精度结果来看,基于地表真实感兴趣区的各种分类的总体精度普遍比基于目视解译的高出11个百分点左右。为验证地表真实感兴趣区与目视解译结果的一致性,将地表真实感兴趣区与目视解译数据进行混淆矩阵分析,结果显示,二者的总体精度为98.33%,说明地表真实感兴趣区的选择与目视解译结果基本一致,二者可以相互验证。在实际工作中,我们大多数情况下无法使用目视解译数据进行精度验证,更多的是采用基于地表真实感兴趣区的混淆矩阵来验证分类结果。通过本研究发现,基于地表真实感兴趣区和基于目视解译的验证结果趋势相同,因此基于地表真实感兴趣区的混淆矩阵可以很好地代替目视解译结果来进行精度验证。但是在验证时,应该扣除一个经验值以更加接近实际的精度值,本研究中,这个经验值约为11%。
本研究中采用的分类方法是常用的监督分类和非监督分类方法,主要存在同物异谱和异物同谱的问题,影响分类精度,而目前面向对象的分类方法较好地解决了这一问题,在影像分类中得到了广泛的应用。因此,比较面向对象的分类方法与传统监督和非监督分类方法的分类精度将是下一步研究的重点。本文中选取的研究区域较小,而且仅基于一个时期的一景影像中的部分区域进行研究,数据丰富度较低,在后续的研究中将增加不同时期、不同区域的数据进行比较研究,以提高数据丰富度,增加研究结果的可信度。
猜你喜欢
少林与太极(2021年1期)2021-06-20
中学生数理化·高一版(2021年2期)2021-03-19
今日农业(2020年23期)2020-12-15
中国外汇(2019年6期)2019-07-13
健身气功(2019年2期)2019-04-18
知识经济·中国直销(2018年2期)2018-04-10
网络文学评论(2017年1期)2017-07-22
中学生数理化·高一版(2017年2期)2017-04-25
戏剧之家(2016年20期)2016-11-09
电脑知识与技术(2015年30期)2016-01-09
