
“211工程”高校图书馆发现系统调研与思考
2019-01-15 11:12张毅
数字图书馆论坛 2018年12期
张毅
(华东师范大学图书馆,上海 200241)
随着互联网的迅速发展,大数据与人工智能技术的成熟,读者阅读行为的不断改变,需要图书馆在馆藏建设与资源揭示方面不断创新。近年来,电子馆藏的总量与增加量已经远远超过纸质馆藏[1],但是图书馆现在还只能通过OPAC对纸质馆藏进行简单管理,没有有效的手段对浩如烟海的电子馆藏进行管理揭示[2]。原因在于每种电子资源都有各自独立的平台,并且各种平台之间无法互操作,形成一个个“信息孤岛”。读者在使用图书馆资源时需要在多个不同平台之间切换,无法有效找到需要的资料[3]。由于缺少功能完备的电子资源管理工具,图书馆没有办法掌握所购买的各种资源是否符合读者需求,容易造成资源错配。
虽然图书馆很早就意识到这种问题的存在,也尝试使用各种手段去解决问题。如通过建立电子资源导航[4],为读者提供图书馆所购买的数据库列表,但是读者只有在明确知道自己所找的资源的具体位置时才有帮助,而且需要检索多个数据平台,并且对检索的结果进行去重排序等工作。当数据平台量比较少时,这种方式可以实现,但是现如今图书馆少则有几十个数据库与期刊,多则有几百个数据库与期刊,人工方式筛选数据会造成遗漏;第二种方式是建立联邦检索[5],这种方式是利用各种系统提供的接口,实时查询,并将查询记录返回给读者,虽然可以减少读者在不同平台之间搜索数据的麻烦,但是因为无法事先对不同平台数据进行清洗加工,导致返回数据质量差,而且同时检索多个平台,系统响应速度会非常慢。由于缺少管理电子资源的有效方法与工具,图书馆虽然拥有经过专家鉴定的高质量内容资源,但无法有效地揭示给读者,读者最终只能使用搜索引擎查找与甄别互联网上参差不齐的资料。图书馆与读者都亟需一种可以全面揭示图书馆资源的系统,在这种背景下,发现系统(discovery system)应运而生[6]。
1 发现系统概述
美国国家教育统计中心对发现系统的定义是:它独立于图书馆特定的资源平台,采取适当的机制对图书馆多种馆藏进行检索,对检索到的内容进行相关性排序,并呈现读者感兴趣的内容,可以根据类别、作者或者日期等来缩小检索结果,提供相关内容建议,改进检索方式[7]。美国国家信息标准组织指出了图书馆发现系统未来发展的方向[8],分析了发现系统从在线目录、元搜索到资源发现的发展过程。其中元搜索阶段已经基本具备发现系统的功能,限于技术环境的发展阶段,最初元搜索系统采取分布式检索方式获取资源,而很少采取集中式元数据汇聚模式[9]。
本文所阐述的发现系统指的是集中式元搜索模式,采用预先收割的方式存入统一的元数据标准体系中,对元数据进行去重、清洗、标注、索引等操作,形成一个庞大的元数据索引库,不断地对索引库进行更新与优化,并按照发现系统获取元数据的不同方式分为资源发现系统与学术搜索引擎两大类。资源发现系统的元数据是自有或者与数据库提供商合作,通过数据收割协议获取元数据,数据质量高、时效性好;学术搜索引擎的元数据来自其机器爬虫通过HTTP协议在互联网抓取的数据,虽然获取的数据范围广,但质量参差不齐。
1.1 资源发现系统
资源发现系统最早出现于2008年,联机计算机图书馆中心(Online Computer Library Center,OCLC)推出了全球第一款资源发现系统World cat Local,紧随其后的是Series Solution公司的Summon(2009年7月)、Ebsco公司的EDS(2010年1月)及Ex Libris公司的Primo(2010年6月),形成4种发现系统。根据供应商原有业务的不同,这4种发现系统各具特色。Ex Libris公司是图书馆集成系统提供商,没有数据库资源,需要与大多数数据库厂商合作获取元数据,所以Primo系统在元数据收集、处理及揭示方面比较中立。Summon与EDS都是由内容提供商开发的发现系统,由于其自身具有庞大的电子资源,而且在资源发现领域耕耘多年,所以数据内容更加丰富[10]。国内资源发现系统起步较晚,但由于对中文数据收集更加全面准确,本地化做得更好,移动互联网与社交网络功能丰富,所以在国内市场的表现并不输于国外产品,国内的资源发现系统有超星发现与维普智立方等。
1.2 学术搜索引擎
搜索引擎天然地在资源收集方面拥有优势,可以通过机器爬虫在整个互联网中搜集资料,然后通过索引提供给用户使用[11]。学术搜索引擎的出现远早于发现系统,2004年11月谷歌公司推出第一款学术搜索引擎——谷歌学术。2006年1月扩展到中文学术资源,随后在2009年11月微软学术推出微软学术搜索,但目前仍不支持中文。2014年是国内学术搜索引擎爆发的一年,百度学术和360好搜纷纷问世。学术搜索引擎由于其背后强大的技术支持,完全免费开放使用,受到读者和图书馆的欢迎。谷歌学术和微软学术在英文文献覆盖方面有优势;百度学术和360好搜更加擅长中文知识的发现;百度学术专门为图书馆提供数据整合接口,图书馆可以将本馆购买的电子资源与纸质资源元数据上传到百度学术,实现数据的深度融合[12]。
2 “211工程”高校图书馆发现系统现状调查
2.1 发现系统的类型调查
本研究调查时间段为2018年10—12月,调查了113所“211工程”高校图书馆[13],通过图书馆的主页获取其采用的发现系统情况,有4所高校图书馆的官网无法打开,可获得数据的高校图书馆有109所,详细调查信息如表1所示。本文的数据分析以这109所可获取数据的高校图书馆为依据。
可以看到,109所“211工程”高校中,引进发现系统的有94所,其中使用资源发现系统的有88所,使用学术搜索引擎的有37所。引进中文资源发现系统的有66所(中文资源发现系统只有超星发现),引进外文资源发现系统的有68所(外文资源发现系统分别是Primo、Summon、Find+、EDS),中英文发现系统都采用的有46所。既引进资源发现系统又采用学术搜索引擎的高校有31所,占引进学术搜索引擎高校的84%,其中有6所高校只引进了学术搜索引擎。采用的学术搜索引擎有3种,分别是百度学术、谷歌学术及微软学术。从使用的比例来看,百度学术占了绝大多数,113所“211工程”高校中有32%的高校图书馆采用百度学术,使用率占学术搜索引擎的95%。谷歌学术使用量少的原因是国内不能直接访问谷歌学术网站,只能通过谷歌学术镜像访问,而镜像的稳定性比较差。微软学术使用率低的原因是其产品存在问题,它不支持图书馆本地资源整合且没有中文数据等缺陷。各种发现系统的具体采用比例如图1所示,可以发现,学术搜索引擎的使用比例并不低,百度学术比资源发现系统超星使用量少,但是高于其他4种外文资源发现系统。
2.2 发现系统的建设方式
资源发现系统的建设方式一般有3种,最常用的方式是直接采购成熟的产品,配上本馆的电子数据库与纸质馆藏元数据,这种方式最为简单方便。发现系统产品已经比较成熟,图书馆不需要耗费过多的人力物力去建设,而且均为云平台,不需要在图书馆本地搭建服务器,无须图书馆投入人力去维护。采用这种方式的有华东师范大学图书馆的超星发现与Summon系统、清华大学的Primo系统及南开大学的EDS系统等。第二种是联合研发模式,这种方式的优点非常明显,可以做到一站式检索,深入与图书馆的OPAC整合,用户体验最好。采用这种建设方式的图书馆有重庆大学“弘深搜索”,是对传统OPAC的升级,读者可以一站式检索电子资源与纸质图书(“弘深搜索”底层的元数据由超星公司提供)。第三种是采用开源软件方式建设发现系统,常见的发现系统开源软件有vufind、endeca、blacklight、scriblio等。如北京大学、西安交通大学利用scriblio构建的新一代OPAC系统。

表1 “211工程”高校图书馆发现系统调查结果

图1 “211”工程高校各种发现系统的采用情况
采用学术搜索引擎实现图书馆资源发现的方式比较单一,微软学术没有中文学术数据,只有外文数据,而且不能与图书馆资源整合。谷歌学术需要在图书馆本地构建链接解析器(link resolver)[14],将图书馆本地数据提交给谷歌学术,由于国内只能通过镜像网站访问谷歌学术,并不稳定。国内图书馆采用的学术搜索引擎主要是百度学术,图书馆可以将购买的电子数据库、本馆馆藏等提交给百度学术,由百度学术对这些数据进行解析,通过IP控制实现针对本馆的资源揭示;图书馆还可以对百度学术的界面进行修改,使其更加本地化。将本馆电子资源整合到百度学术的高校有浙江大学、南京大学、中国科学技术大学等;将本馆纸质馆藏与百度学术融合的高校比较少,如中南大学。
3 “211工程”高校图书馆常用发现系统分析
3.1 发现系统的特征分析
为挖掘发现系统特点对高校图书馆发现系统选择的影响,本文对国内关注度比较高的4种资源发系统和3种学术搜索引擎进行调查分析,具体调查结果见表2。

表2 发现系统特征调查
分别从元数据特征、系统特征、整合本馆资源、在线科研等方面进行分析,可知发现系统有以下特征。
(1)元数据特征。除谷歌学术和微软学术外,其他5种系统的元数据总量都可以查到。从查到的结果看,Summon的数据量最大,有9亿条记录;其次是超星发现有5.5亿条记录。3种国外的发现系统主要收录英文数据,而超星发现以中文为主。数据的来源方面,资源发现系统的数据基本上来自数据库商,没有收录万维网的数据,Summon和EDS数据主要是自有数据,而Primo的数据来自合作的数据库商,超星电子书是自有数据,期刊主要来自合作的数据库商。学术搜索引擎的数据主要来自爬虫机器人从万维网中抓取的数据,经过清洗索引后形成,其中微软学术没有中文数据。由此可见,资源发现系统的数据质量更高,而学术搜索引擎的数据面更广。
(2)系统特征。系统的响应速度极大地影响用户体验的好坏,从调查的结果中发现,国外资源发现系统的响应速度很慢,主要是因为发现系统基本上都是云端部署,在国内没有数据中心,每次访问都要从国外服务器返回数据,所以速度很慢,而且不稳定。从调查的结果看,学术搜索引擎的响应非常迅速,百度学术只需16毫秒,瞬间就可以返回查询结果,用户体验极好。相较于资源发现系统,学术搜索引擎会提供一些免费的原文,并且学术搜索引擎全部是免费使用,基于搜索引擎的强大技术,大多数学术搜索引擎都可以实现读者检索行为学习,帮助读者更好地发现自己需要的资料。
(3)与本馆资源整合情况。整体上来说资源发现系统与本馆资源整合较好,都可以做到发现系统查询结果跳转到馆藏OPAC。其中Primo几乎可以取代本馆的OPAC,不仅可以查看本馆的馆藏位置,而且有预约续借等功能。学术搜索引擎与本馆的整合度较低,没有一个学术搜索引擎可以显示本馆馆藏的位置,但基本上可以实现纸质资源与电子资源的一站式发现。
(4)在线科研情况。在线科研方面,学术搜索引擎功能强大,其中百度学术和谷歌学术都有学者主页,学者可以订阅、收藏所需要的资料,但是资源发现系统没有这些功能。在移动科研方面,所有的发现系统都提供移动网站,但是与微信对接的只有百度学术,读者关注百度学术的微信公众账号,可以获取自己订阅的资料,使用过程比较方便。
3.2 图书馆资源与发现系统结合能力分析
发现系统与图书馆资源整合能力体现了发现系统资源覆盖能力。除学术搜索引擎外,一般的资源发现系统都可以覆盖图书馆的电子期刊与纸质馆藏,但是图书馆还有很多自建数据库,这些数据库之间存在非常巨大的差异,在图书馆内以一个个“信息孤岛”的形式存在,由于“211工程”高校数量太多,本文仅对师范类“211”工程高校图书馆特藏资源的特征进行调查。调查时间为2018年11月,调查方法是通过图书馆的主页及电话咨询,并且参考2015年全国师范院校图书馆联盟文献资源建设调查问卷[15],调查结果见表3。可以看出特藏资源的类型、平台,以及数据库管理软件存在巨大的差异,发现系统要整合这些资源存在不小的挑战。但是它们的数据管理软件都具有导出数据与对外提供访问接口的能力,这就为特藏资源整合到资源发现系统提供了方法。发现系统只需要提供特藏资源导入格式标准,图书馆将特藏资源按照一定标准提交给发现系统,发现系统即可以实现对图书馆特藏资源的统一发现。
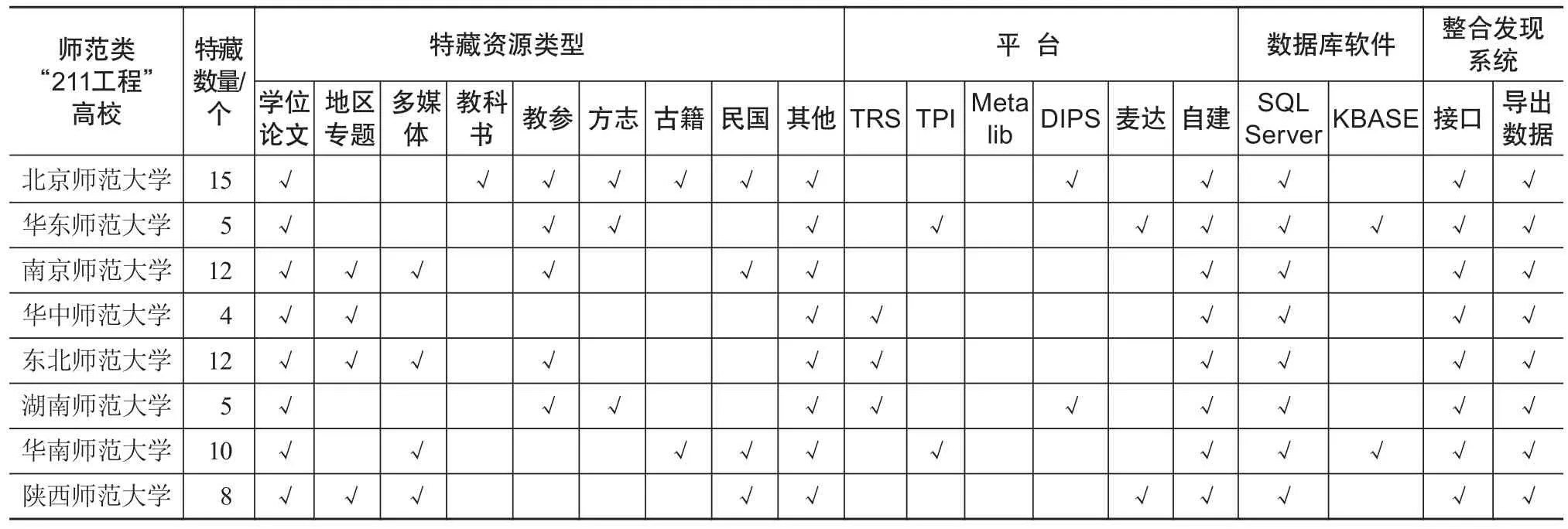
表3 师范类“211工程”高校图书馆特藏资源特征
3.3 发现系统读者使用率分析
发现系统的使用率是衡量发现系统好坏的重要指标之一。谷歌趋势可以反映某一区域内关键词检索频次,文本通过谷歌趋势查询了2015年12月—2018年12月Primo、EDS、Summon、百度学术、超星发现的热度变化[16],调查范围是中国(见图2)。由于采用“超星发现”作为关键词没有记录,所以改为“超星”进行比对。从图2可以看出,2017年1月之前资源发现系统的热度比百度学术高,尤其是Primo系统,但之后百度学术热度迅速升高,而且远高于资源发现系统。此外,国外发现系统的热度在降低,而国内的超星发现热度在上升,这也与笔者所在华东师范大学采用的超星发现和Summon两种系统的使用情况相符,根据发现系统供应商提供的访问数据,2017年超星发现访问量是95.43万次,Summon访问量是4.23万次,使用中文发现系统是外文发现系统的20倍。

图2 5种发现系统热度随时间变化的趋势
4 发现系统选型思考
通过对“211工程”高校采用的发现系统调查,发现系统之间的优势区别很大,这与发现系统提供商自身的主营业务有关,Summon与Primo在数据库方面有优势,而EDS和超星发现在电子图书方面做得更好。学术搜索引擎在万维网数据获取方面更有优势。发现系统与区位也有巨大的关系,国内发现系统擅长中文数据揭示,外文发现在中文揭示方面比较弱,根据发现系统的特点与“211工程”高校对发现系统的选择分析,本文给出系统选型的一些建议。
4.1 根据学校类型选择
调查中可以看出113所“211工程”高校中有86%的高校都已经采用发现系统,这些高校中有师范类、工科类、艺术类等,在选择发现系统上,图书馆可以根据学校的类型挑选。如师范类院校,北京师范大学图书馆选择了Primo、超星发现与百度学术3种发现系统,华东师范大学的发现系统是Summon与超星发现,南京师范大学是Primo与超星发现。从这3所师范高校图书馆所选择的发现系统中可以得到,每家图书馆都引进了中英文两种资源发现系统,中文发现系统都是超星发现,而外文发现系统是Summon与Primo,其中北京师范大学还采用了学术搜索引擎(百度学术)。可见,师范类高校在选择发现系统时,可以考虑从上述发现系统中选择。
4.2 根据读者特征选择
读者是发现系统的最终使用者,所以引进发现系统要尽量考虑到读者的需求,不同类型的读者对发现系统的需求差别很大。如高校学生会比较喜欢使用百度学术这样的学术搜索引擎,一是由于学生接触的百度的产品比较多;二是本科阶段学生对资源的要求不高,百度学术一般可以满足读者的需求;三是百度学术还有帮助读者撰写学位论文的功能,更加适合学生使用。而从事专业学术研究的科研人员更愿意选择Summon与超星发现这样的资源发现系统,因为这类用户的研究内容更加专业,学术搜索引擎从互联网上抓取的数据质量无法达到用户的要求。
移动互联网时代,移动设备成为读者科研活动的重要工具,在众多的资源发现系统中,只有超星公司有移动客户端,并且使用方便,如果读者的移动学习活动比较多,那么超星发现是一个好的选择。学术搜索引擎方面,百度学术移动化功能较好,百度学术开通了微信公众账号,读者关注百度学术微信公众账号,就可以在微信中查看自己订阅的内容。
4.3 根据经费选择
资源发现系统需要支付费用才可以使用,而学术搜索引擎都是免费开放的,所以图书馆也可以根据自身经费选择发现系统。虽然资源发现系统数据质量高,可以更好地与图书馆自有资源整合,但是需要经费支持才可以使用,所以对于暂时经费不足的图书馆,也可以使用学术搜索引擎。百度学术可以将纸质馆藏与电子馆藏融合到百度学术中,并且通过IP控制,对本校读者开放自有资源。使用百度学术揭示资源的图书馆有中国农业大学、北京林业大学、中国矿业大学等高校,而且上述高校只采用了学术搜索引擎,没有购买资源发现系统。
4.4 根据与图书馆OPAC融合度选择
在调查的“211工程”高校中,与本馆OPAC融合中比较有特色的是重庆大学图书馆的发现系统,它不是将本馆OPAC数据整合到发现系统中,而是将超星发现系统的数据整合到本馆的图书馆主页,读者可以在图书馆主页实现OPAC数据与发现系统数据的统一检索,而无须跳转到发现系统商的网站。清华大学图书馆的OPAC与Primo系统深度融合,可以在Primo发现系统中登录读者借阅账号,实现本馆纸质馆藏的续借及预约等功能。在与本馆OPAC整合方面,学术搜索引擎功能比较差,基本上资源发现系统都可以做到查看本馆纸质图书馆馆藏地,而学术搜索引擎目前无法实现。
4.5 根据发现系统语种选择
现阶段发现系统还无法在中英文资源方面同时并重,国外的发现系统对外文资源收录较好,而国内的发现系统在中文资源收录方面较好,所以在资源发现系统选择时需要考虑到本馆资源的语种类型。从调查的结果看,同时采用中英文两种发现系统的高校有46所,占88所采用资源发现系统高校的52%,如中国人民大学、北京航空航天大学、上海交通大学等高校都是采用中英文两种发现系统。
学术搜索引擎方面,百度学术与谷歌学术都同时支持中英文资源发现,国内的百度学术中文资源丰富,而谷歌学术在英文方面支持较好,而微软学术只支持英文数据。对于学术搜索引擎,由于其免费的特点,图书馆都可以采用,给读者多一个选择。
5 结语
本文通过对113所“211工程”高校图书馆发现系统使用的调查,分析国内高校主要采用的发现系统类型、建设方式,以及每种系统的功能特点,得出发现系统已经成为图书馆必备的资源统一揭示工具,无论是图书馆对电子资源的管理需求,还是读者对纸电资源统一发现的需要,发现系统都不可或缺。现阶段发现系统进展非常巨大,有一些发现系统已经可以整合本馆OPAC的所有功能,但是整体上发现系统还处于成长阶段,有很多不完善的地方。如还没有一种发现系统可以满足中英文资料的统一发现,在与图书馆OPAC系统融合方面也存在诸多障碍,这需要图书馆与资源发现系统供应商共同努力,提升发现系统的功能。虽然资源发现系统优势在于元数据质量及整合图书馆本地资源方面,但是学术搜索引擎也有很多方面值得资源发现系统学习,如系统响应速度、在线科研及机器学习等。希望通过本研究能给图书馆采用发现系统提供一些建议,为读者提供更加优质的知识服务体验。
猜你喜欢
畜牧兽医杂志(2022年6期)2023-01-05
石家庄学院学报(2022年2期)2022-04-19
Plasma Science and Technology(2020年3期)2020-04-24
小猕猴智力画刊(2018年7期)2018-08-08
图书馆(2016年10期)2016-10-27
中国卫生(2015年12期)2015-11-10
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
出版广角(2014年12期)2014-08-11
科学导报·学术论坛(2013年5期)2013-06-26
读者·校园版(2013年12期)2013-05-14
