
基于机器学习的互联网评论倾向性分析相关算法研究①
2019-02-15 03:52徐姗姗
佳木斯大学学报(自然科学版) 2019年1期
吴 菲, 徐姗姗
(1.南京工业大学浦江学院,江苏 南京 210000;2.南京林业大学信息科学与技术学院,江苏 南京 21000)
0 引 言
互联网在给人们带来信息获取便利性的同时,也出现了一些负面影响,如:网络上存在大量虚假信息。在当今的互联网+时代,目前大多数人们首先通过联网设备获取或发布信息。如何更好地了解群众的情绪或观点并精准地得到观点倾向性,就成了目前舆情分析领域最需要解决的主要问题。而目前政府等部门进行舆情监控的主要手段是观察情感的流向从而提供优秀的战略建议。根据此战略建议去安抚、疏导人们,防止部分人产生暴力行为从而导致人群的恐慌。
因此,针对评论获得情感的倾向性对于舆论的监督或商品评论的统计都有着至关重要的作用。以往的方法:通过人工统计分析,其效率极低。因此提出一种利用机器来自动分析情感倾向的方法是十分必要的。
1 相关研究介绍
1.1 传统的IG算法及改进
IG算法是一种有效的特征选择算法,目前已在文本分类研究领域中得到了广泛的应用。
传统的IG算法描述如下:

传统算法在信息增益上无法区分其特征,即情感词。即便原有算法能够择出一些特征,但是算法分析后得到的结果并不是非常理想。对于情感分析这一重要问题,不难看出得到评论的极性最有效率的方式是判断情感词。所以在提取特征词的时候,情感词所占的比例应当得到大量增加从而提高判定的准确度。
针对上述要求,对IG算法进行改进,改进后的算法命名为IG-S,其计算公式如下:


1.2 传统的TF-IDF算法及改进
TF-IDF是一种统计方法,某个字词对于一个文件集或一个文本库中的其中一份文件的重要程度可以用此方法来评估。随着字词在文件中出现的次数增加,字词的重要性逐渐变高,但同时也会随着它在文本库中出现的频率成反比下降。
传统的TF-IDF算法描述如下:
qi=TFi×IDF
其中,TFi表示特征i在数据集中出现的概率。IDF表示逆向文档频率,此变量在文本库或文件集合中包括了特征i的样本内容的比例。其中TF、IDF公式如下:
|D|代表所有数据的总数,ni,j表示在数据集中i出现的次数,∑knk,j代表数据集中的不同特征相加。
传统的TF-IDF算法存在的不足:①传统算法无法准确地辨别一个词是否为情感词,但在实际的情况下情感词汇和普通词往往存在着辨别样本所属样本类能力的差异,传统算法也没有把重要的因素:位置给考虑进来。不难看到,修饰词后面若加入情感词语,相应情感词语的分数也应该得到提升②同时传统算法极大几率将部分无用且有着稀疏性的词语的评论贡献度定的过于高,这样就导致了很难将不同类别之间的特征差异展现出来。
针对上述的不足,作者改进了特征权重的计算方式,提出了TF-IDF-S方法,算法公式如下:

经过此方法改进后的算法不仅能够提高程度副词与情感词间的权重,还额可以大大降低稀疏的特诊对判定准确度的恶劣影响。
1.3 融合分类器构建
1.3.1 情感倾向性分析方法
目前,在众多的文本分类的方法当中,情感倾向性分析的主要手段是将完整的评论信息根据不同情况进行分类,从情感的倾向角度分为正面评论、中性评论和负向评论。具体步骤为:
Step1:数据预处理:用预处理技术将数据集进行处理,将其形成向量空间;
Step2:训练模型;
Step3:测试阶段:将测试数据放入训练好的模型当中,得到预测分类。
1.3.2 融合分类器展示
融合分类器其结构图如下:
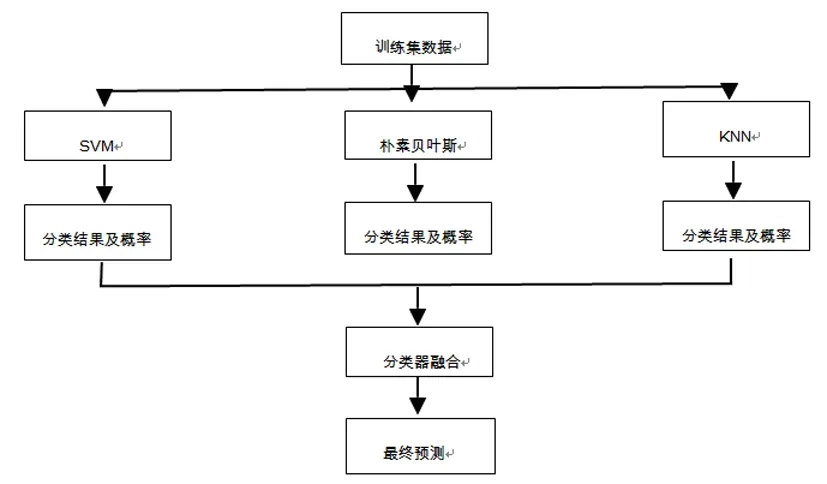
1.3.3 构建融合分类器
(1)朴素贝叶斯算法
输入:输入样本数据Y=(x1,y1)(x2,y2)…(xi,yi),其中Y为文本


(2)KNN算法
输入:输入文本Y=(x1,y1),(x2,y2),…,(xi,yi)

Step1:fort=1,…,M, 算法根据预先设定的比率,进行随机生成向量空间Vt,其中对于每个生成的向量空间其维度为K,同时将根据其原有的向量空间来标志它的位置Vt=RS(v,k);
Step2:根据所有在Step1种得到的特征子空间V1,V2,…,Vm, 数据集Y通过不同的特征子空间V1,V2,…,Vm得到子数据集Y1,Y2,…,Ym;
Step3:将KNN分类器作用于数据集合Y1,Y2,…,Ym,最终形成了M个KNN分类器hi:h(i)=KNN(Yi)
Step4:对于测试样本集合X将通过其特征子空间V1,V2,…,Vm,划分为相同格式的输入数据集合X1,X2,…,Xm;

(3)SVM分类算法
输入:输入文本Y=(x1,y1),(x2,y2),…,(xi,yi)
输出:每个样本数据的类别标号和每个样本数据所属类别的贡献值
Step1:数据预处理阶段:利用数据清洗技术将训练数据进行处理优化Step2:构建向量空间:利用上文中的构建向量空间的方法将文本表示成向量空间(空间内的数据格式应如输入数据一样);
Step3:参数优化阶段:算法开始改善 分类器的参数 c和g(从而使得分类器的效果最好),最终调出最优的分类器;
Step4:模型的生成阶段:调节参数 c、g后 生成的分类器模型将用来训练训练样本数据,使得模型效果达到最优。
Step5:测试阶段:将预处理好的测试样本输入模型形成向量空间。
Step6:查看结果: 测试数据在被训练好的模型预测得到样本分类之后,采用格式化输出其标号和贡献值并保存。
(4)分类器融合
文章结合SVM、KNN和朴素贝叶斯机器学习等方法,构建一个分类器结合的模型。提出的模型不仅考虑到各种算法的优缺点,还将每种算法的优势相结合,最终形成一个能够良好解决情感分析问题的模型,此模型的适应性也较好。
提出的融合分类器算法如下:
输入:输入文本Y=(x1,y1),(x2,y2),…,(xi,yi)

Step2:通过分类器1预测结果,F1=
分类器2预测结果,F2=
分类器M预测结果,Fm=
根据每个分类器得分更新分类器的权值
2 实验方案与实验结果
2.1 实验方案
(1)实验数据
文章实验数据集合采集:考虑到现在还没有第三方公布优质的数据集合获取接口,提出利用python的网络爬虫来获得抓取互联网上的热点评论数据。
(2)训练数据集
从最近的互联网评论中爬取热点新闻的评论信息,并利用数据预处理技术将垃圾数据与有效数据进行分离。数据集合分布如下:5000条主观评论。5000条客观评论。因此训练集合的大小为10000。(3)测试数据集
从训练数据集中选取三个主题,在删除了大量垃圾评论后,剩下5000条左右主观评论、400条左右客观评论。为了避免客观评论和主观评论的不平衡性,查找了4500条左右表示客观性的评论(同一话题),根据此方法选取的测试数据分布良好。
(4)形成预测分类器
利用特征组合将文本表示为向量,放入所构建的融合分类器,形成一个更有效的分类模型。
2.2 实验结果
利用提出方法进行准确实验,并记录了准确率。方法的实验结果如下:

分类器方法准确率朴素贝叶斯79.13%KNN75.41%SVM83.72%融合分类器87.96%
通过实验结果可以发现,融合分类器的性能均要优于其他三种分类器。
3 结 语
主要研究评论的情感倾向性判断的方法,提出了改进的IG算法和TF-IDF算法。其中改进的IG算法对于传统的基于信息增益的特征提取方法进行了改进,能够挑选出更多有效的情感词。改进的TF-IDF算法相比于传统的算法优点在于,提出的优化算法能够在情感词语和程度副词于样本集合中一起存在的时候,将具有重要意义的情感词的权重提高,如此一来模型分析情感和导出其正确的分类的准确率大大提高。文章也针对于朴素贝叶斯方法、KNN算法以及SVM分类等算法的不足,提出了融合分类器,通过实验表明,该融合分类器取得了一定的效果,能有效的提高分类准确率。
但由于文章的研究方式的束缚,现有的基于监督学习的方法虽然能够解决同一领域的情感分析问题。但是一旦样本集合的样本来自于不同话题或者样本之间的相似度不能够达到一定高度,模型的分类效果将变得极为糟糕。这一问题很重要,将在接下来的研究工作中解决。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
知识经济·中国直销(2018年8期)2018-08-23
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
数学学习与研究(2017年3期)2017-03-09
高中生学习·高三版(2016年9期)2016-05-14
中国老区建设(2016年1期)2016-02-28
新高考·高二数学(2015年11期)2015-12-23
