
基于对抗学习的跨模态检索方法研究进展
2019-03-02 02:35张璐
现代计算机 2019年2期
张璐
(四川大学计算机学院,成都 610065)
0 引言
近年来,由于多媒体数据的快速增长,跨模态检索这一研究领域吸引了学者们的广泛关注。跨模态检索的任务是用一种模态数据作为查询条件,检索相关语义的另一种模态的数据。该研究领域的核心问题和难点是如何去衡量不同模态数据的内容相似度,同时目前的研究致力于提高检索的精度。2017年,B.Wang等人第一次提出了将生成对抗网络(Generative Adversarial Networks)[1]应用到跨模态检索问题的方法ACMR(Adversarial Cross-Modal Retrieval)[2],该方法中使用对抗学习来使得文本和图像两种模态数据的特征分布趋于一致,可以有效地寻找不同模态的共同子空间。2018年,出现了更多使用对抗学习进行跨模态检索的研究方法,并在公开数据集上取得了优秀的效果,进一步证明了对抗学习在跨模态检索问题上的有效性和研究价值。
1 相关工作
1.1 跨模态检索
跨模态检索的一般步骤分为三步,如图1所示。第一步是对不同模态的数据进行特征提取,第二步是进行跨模态相关性建模,第三步是对检索结果进行排序。跨模态检索方法大致分为两类,一类是基于实值特征学习的方法,另一类是基于二值特征学习的方法[3]。先进的实值特征学习方法包括 CCA[4]、Corr-AE[5]、LCFS[6]、JRL[7],先进的二值特征学习方法包括 CMSSH[8]、SCM[9]、SePH[10]、DCMH[11]。虽然二值特征会损失部分信息,但是由于采用位运算,二值特征学习方法在检索速度上优于实值特征学习方法。
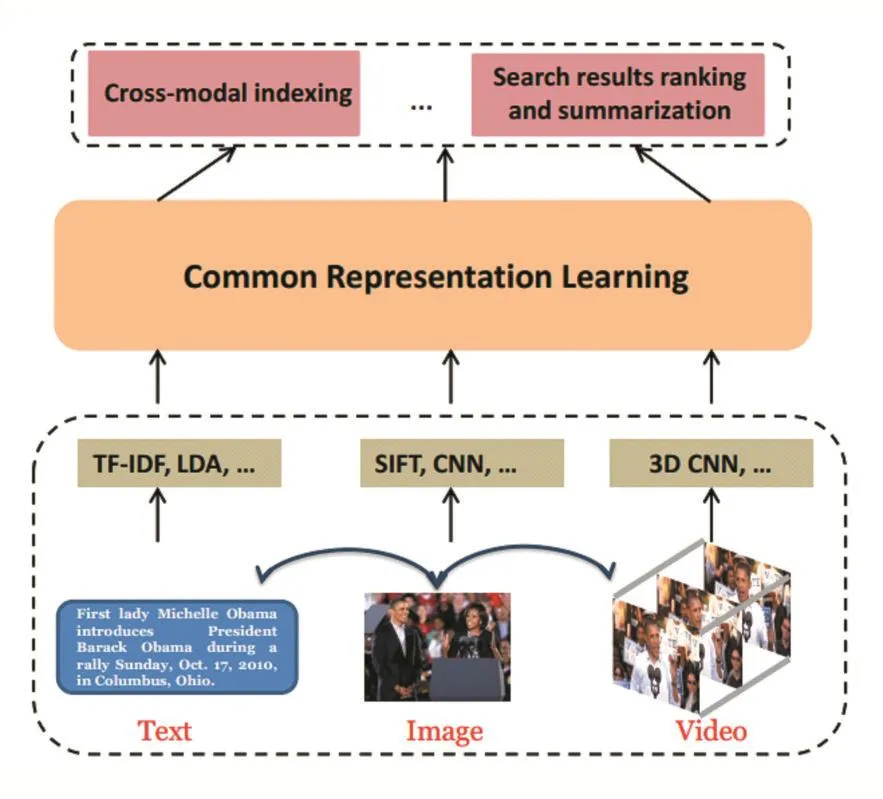
图1 跨模态检索的总体框架[3]
1.2 对抗学习
Ian J.Goodfellow等人在2014年提出了生成对抗网络(Generative Adversarial Networks),该网络的原理是利用零和博弈的思想,让网络结构中负责生成伪造数据的生成器(Generator)和负责鉴别真实数据与伪造数据的判别器(Discriminator)进行对抗训练,从而让生成器学习到正确的数据分布。GAN相比较于传统的模型,不同点在于它拥有两个不同的网络,训练的时候采用的是对抗训练,其中生成器的梯度更新信息来源于判别器而不是真实的数据样本。在跨模态检索领域,对抗学习中的判别器通常替换为一个进行二分类的分类器,判别生成的数据是文本模态或者图片模态,来使得生成器生成模态不变的共同特征。
2 研究进展
2.1 对抗跨模态检索
对抗跨模态检索是第一个将对抗学习应用到跨模态检索问题的论文。该方法是一个实值特征学习方法。该方法使用特征生成器和模态分类器组成的对抗网络生成具有模态间不变性和模态内判别性的共同特征。特征生成器由标签预测和结构保存两个模块组成。标签预测模块以图片和文本的特征匹配对为输入,输出该匹配对的语义类别概率分布,损失函数表示为:
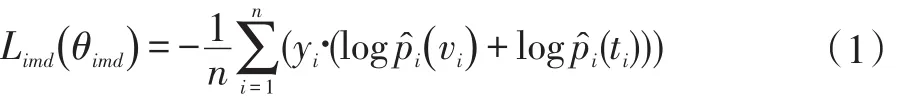
其中yi表示图片和文本匹配对的真实的类别标签向量,log和log分别表示图像和文本的多标签分类概率。优化该损失函数的目的是保存特征的模态内判别性。结构保存模块引入了三元组约束和模态间不变性损失。损失函数表示为:


其中mi表示输入的文本或者图片特征的模态标签,是一个one-hot向量。D(vi;θD)和 D(ti;θD)分别表示预测输入特征为文本或者图片模态的概率。对抗训练的过程是在一次迭代中固定特征生成器或者模态分类器的参数,最小化正在训练的模块的损失函数来进行优化的,这两个子进程可以表示为:

2.2 自监督对抗哈希网络
自监督对抗哈希网络跨模态检索[12]是一个二值特征学习方法。该方法使用自监督语义生成网络和对抗学习来保存生成的统一的哈希码的语义相关性和分布一致性。该方法利用自监督语义生成网络生成保存图像和文本语义信息的标签的语义特征,并使得图像和文本的生成网络学习到的特征对齐语义特征,以此建立文本和图像特征的语义关联。利用两个模态分类器对输入的语义特征或者文本和图像特征进行模态分类,以此在对抗学习中学习不同模态特征分布的一致性。自监督语义生成网络的损失函数表示为:



该损失函数表示模态分类器分类错误的个数。对抗学习的损失函数表示为:

对抗训练时固定生成网络或者判别网络的参数,优化另一个网络中的参数。
2.3 基于注意力机制的深度对抗哈希
基于注意力机制的深度对抗哈希跨模态检索[13]是一个二值特征学习方法。该方法引入注意力机制去检测多媒体数据中有益于不同模态数据进行相似度比较的信息量大的区域,即受关注区域。使用深度对抗哈希去学习有效的注意力掩码和哈希码,通过实验验证了注意力机制在跨模态哈希方法中的有效性。该方法包括三个模块,分别是特征学习模块,注意力模块和哈希模块。特征学习模块用于提取图像和文本的特征,注意力模块学习注意力掩码用于区分图像与文本的受关注区域和不受关注区域,哈希模块用于将图像和文本的受关注区域特征和不受关注区域特征分别转换成对应的哈希码。特征学习模块和注意力模块对应对抗学习中的生成器,哈希模块对应对抗学习中的判别器。该方法引入了跨模态检索损失和对抗检索损失对网络的参数进行优化。跨模态检索损失函数表示为:

其中A和B表示不同的模态,HiA和HjB是语义相同的不同模态的哈希码,HiA和HkB是不同语义不同模态的哈希码,优化该损失函数的目的是保存哈希码的语义相似性。对抗检索损失表示为:

哈希模块优化该损失函数的目的是尽量让同一语义不同模态的不受关注区域保存相似性,而注意力模块尽量区分出受关注区域和不受关注区域,让不受关注区域不保存相似性信息。整个框架的目标损失函数表示为:

训练的时候固定哈希模块,更新特征生成模块和注意力模块的参数:

固定特征生成模块和注意力模块的参数,更新哈希模块的参数:

3 结语
自监督对抗哈希网络与对抗跨模态检索的区别在于后者是一个实值特征学习方法,而前者是一个二值特征学习方法;后者是让图像和文本的特征在拟合真实语义标签的过程中进行共同决策来使得图像和文本预测标签分类的概率分布趋于一致,而前者是让图像和文本的特征对齐真实语义标签的特征分布来使得特征分布趋于一致。基于注意力机制的深度对抗哈希与对抗跨模态检索的区别在于前者是一个二值方法;后者使用对抗学习来寻找共同子空间,而前者使用对抗学习处理注意力网络的参数学习。从以上内容的介绍可以看出,基于对抗学习的跨模态检索方法受到了广泛的关注,且在已发表的文献中呈现的实验结果也充分证明了对抗学习应用到跨模态检索问题上的有效性和进一步的研究价值。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
昆明医科大学学报(2022年3期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
技术与创新管理(2020年5期)2020-10-09
科学与财富(2019年27期)2019-10-25
意林(图解作文)(2019年6期)2019-07-16
科学与财富(2017年28期)2017-10-14
电脑爱好者(2015年13期)2015-09-10
