
基于改进模板匹配与深度稀疏编码网络的文档编号自动识别
2019-03-02 02:35段磊刘涛李伟鹏张宁咸日常邹国锋
现代计算机 2019年2期
段磊,刘涛,李伟鹏,张宁,咸日常,邹国锋
(1.国网山东省电力公司淄博供电公司,淄博 255000;2.山东理工大学电气与电子工程学院,淄博 255049)
0 引言
随着信息技术和网络技术的不断发展,电力部门涉密文件档案的信息化建设和智能化管理在档案事业发展中扮演着越来越重要的角色[1]。因涉密文档材料的特殊性,在一定程度上影响了其数字化的进程,例如,目前实体涉密文件收发登记方式仍然需要通过人工录入等手段,将相关信息在数据库中进行归集、汇总和索引,以便于信息的检索和查询。显然,现有的涉密文档收发文登记方式已不能够满足智能化管理的需要,因此亟需通过一套先进的管理系统对各类收发文件进行归类登记和汇总,在减少人员投入的同时,确保重要文件数量及传阅路径的全过程管控,利用信息化手段提高工作效率。
在文档资料管理过程中,通常需要为每一份文档分配一组唯一的文档编号,作为该文档的识别码,这不仅方便于文档的分类存放,也便于文档查询。因此,在实体涉密文件的收发登记时,可以通过图像采集的方式获取文档编号,然后基于文档编号自动识别技术实现涉密文件的自动收发登记。因此,文档编号的自动识别成为涉密文件收发信息准确登记的关键影响因素。按照书写形式不同,电力部门文档编号分为机打编号和手写编号两种,且文档编号通常由省份简称、英文字母、数字、连接线混合编写组成。正是由于文档编号书写形式不同和复杂的组编方式,导致文档编号识别的准确度与实际需求产生较大差距。
秦守鹏[2]采用工业相机采集轨道喷绘区域图像,经过图像预处理后获取图像目标区域,然后采用Tesseract-OCR技术实现轨道板编号识别。赵丽科等[3]提出基于BP神经网络实现田径运动员号码牌图像的号码识别。该算法采用可形变部件模型进行人体检测,并基于先验知识实现运动员号码牌定位,然后通过字符分割和BP网络识别了号码牌识别。陈哲[4]通过阈值分割获取印章编号区域,并进一步基于卷积神经网络的实现了印章编号识别。显然,目前已有编号自动识别算法主要针对纯数字序号或机打印书体编号,编号模式比较简单,数据量较小。李少辉[5]采用改进的BP网路实现了低质量文本识别,在含有噪声和缺陷的低质量文本图片中保持了较高的识别准确率。陈英[6]等人采用了自适应阈值分割和模板匹配算法实现了水表字符的识别。这些编号自动识别算法无法直接应用于文档编号的自动识别中,但为文档编号的自动识别提供了可借鉴的思路。
鉴于山东省电力部门涉密文档信息化建设的迫切需求,及其当前文档编号自动识别技术的不足,本文提出融合特征匹配和稀疏编码器的文档编号自动识别方法。首先,通过图像采集装置扫描文档编号,然后对文档编号图像进行预处理,主要实现图像灰度化、二值化和字符分割。对于机打编号,本文提出结合欧拉数粗分类与特征匹配再识别的字符识别方法,在一定程度上克服了相似字符之间的干扰。对于手写编号,本文提出一种自适应稀疏编码网络进行编号识别,能够有效地控制网络规模,达到了较高的手写编号识别精度。
1 文档编号的预处理
图像采集装置捕获的图像为彩色图像,需要经过灰度化、二值化处理,并采用相应的字符分割和归一化算法获得标准字符图像。
1.1 字符图像的灰度化与二值化
彩色图像信息量丰富,但参与识别运算,计算量较大,而对于文档编号的识别无需过多的颜色信息参与运算。因此为了减少运算量,采用加权平均法需将彩色图像转换为灰度图像:
灰度化处理后,本文采用了基于阈值的二值化方法:

其中,阈值T的选取采用了基于OTSU的方法。经过图像分割后的结果如图1。

图1 二值化后的文档编号
1.2 字符的分割
字符分割是文档编号识别的重要环节。本文采用了投影法实现字符的分割,由于文档编号通常只有一行,所以只采用垂直方向的投影即可实现字符之间的分割。垂直投影公式:
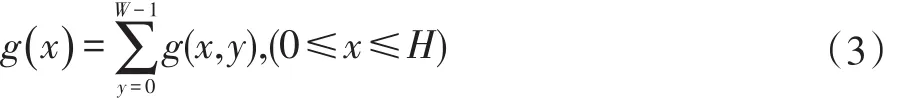
其中,W为图像宽度,H为图像高度。字符分割的部分结果如图2所示。

图2 文档编号字符分割的部分结果
2 基于特征匹配的机打编号识别
由于机打编号字体格式统一,共包含1个“鲁”字、26个大写英文字母、26个小写英文字母、10个数字和连接线“—”,即64种模式。模式简单,数据量较少,适合采用特征匹配方式实现快速识别。
模板匹配[7]是经典的图像识别方法之一,其基本原理是从待识别图像或图像区域中提取若干特征量与已有模板相应的特征量逐个进行比较,计算它们之间规格化的相关量,其中相关量最大的一个就表示其间相似程度最高,可将图像归于该类。模板匹配需要事先构建样本标准模板库,标准样本是经过二值化处理的数字模板,且模板大小相同。而待识别字符匹配识别前,通常也需要标准化为模板样本的大小。本文构建的机打文档编号模板库如图3所示。

图3 部分机打文档编号模板
目前,机打文档编号字符匹配通常采用简单模板匹配法。简单模板匹配是将标准化后的待识别字符图像与字符模板逐个匹配,求出其相似度。本文采用的模板匹配相似度计算公式如下:

其中,f表示二值模板图像,g表示待识别的二值图像,两幅图像的大小一致,均为M×N,Tf和Tg分别表示对应于二值图像中值为1的像素个数,∧表示与运算。
简单模板匹配能够实现基本的文档编号识别功能,但是对于相似性较强的字符,也容易产生误识,例如字符G和Q、C和O、B和8。为了克服误识情况的发生,提高文档编号识别准确度,本文提出通过计算字符图像欧拉数进行前期粗分类,然后进行模板匹配识别的思路,对于未正确识别的字符,则采用人工更正方式保证录入文档收发系统的编号正确。
欧拉数[8]定义为E,它表示一幅图像区域中的孔数H和连接部分数C的差,即:

其中,连接部分数C是指图像中的有多少个单独连接的部分,而其中的每一个部分都是连接在一块的,例如字母A,连接数C为1,孔洞数H为1,则欧拉数为0。
3 基于稀疏自动编码网络的手写编号识别
手写编号因不同人的书写习惯不同,即使相同编号,不同人书写也可能会产生较大差异,给准确识别带来困难。因此,针对不同的手写体文档编号需要构建规模较大的手写字符数据集,本文采用稀疏自动编码器网络进行训练学习,获得丰富的手写编号特征,构建鲁棒性更强的分类模型,能有效提升手写编号的识别准确度。
3.1 自动编码器
深度网络[9,10]是一种具有多层结构的神经网络,通过逐层的自动学习实现输入数据的深层次特征表达和分类。自动编码器[11](AutoEncoder,AE)是一种包含输入层、隐层和输出层的3层神经网络,其中,隐含层实现了对数据的特征提取,输出层则实现了对特征数据的重构。自动编码器的训练目标是使网络输出与输入数据的重构误差最小,其结构框图如图4所示。

图4自动编码器原理结构框图
编码过程如下式:

其中,sf表示隐含层激活函数,通常为sigmoid函数sf(t)=1(1+exp(-t)),Wd×n是权重矩阵,p∈Rn×1表示输入层神经元偏执向量,输入向量为x∈Rn×1,编码输出为h∈Rd×1,h是输入向量x的特征表达形式。
解码过程如下式:

其中,sg表示输出层激活函数,W′是输出层权重矩阵,其数值与权重矩阵 Wd×n的转置相同,q∈Rd×1是隐层神经元偏执项,解码结果 x′∈Rn×1作为重构数据输出。
自动编码器权重矩阵和偏置向量参数为θ={W ,W′,p,q},基于重构误差最小的原则,实现网络模型的训练学习可实现参数的自动调整,重构误差定义如下:

其中,m为训练样本数,xi为输入,x′i为输出,θ为全体参数集合。
3.2 稀疏自动编码网络
一般情况下,自动编码器中隐层神经元数量少于输入层神经元数量,但如果网络结构设计时,将隐层神经元数量设置较多,甚至超过输入层节点数量时,自动编码器仍然能够实现输入样本的特征提取,但这样的网络结构所得特征往往存在较多的冗余信息,且增加了参数数量,训练复杂程度显著增加。因此,研究者提出稀疏自动编码器(Sparse AutoEncoder,SAE),通过加入稀疏性限制对隐层进行约束,使其变得稀疏。
自动编码器中添加的稀疏性限制使用的KL散度为:


稀疏自动编码器的总重构误差如下:

其中,β是控制稀疏限制的权重因子。
本文采用的深度稀疏自动编码器由多层稀疏自动编码器级联而成,如图5所示,前一级网络隐层输出作为后一级网络的输入,并通过贪婪训练方法逐层训练每一级稀疏自动编码器,最终整完成个网络的训练。

图5 深度稀疏自动编码器结构图
4 实验与分析
为了验证本文所提文档编号自动识别算法的有效性,实验采用MATLAB R2014a软件实现,实验分为机打编号自动识别和手写编号自动识别。
4.1 机打编号识别实验
本文实验中采用了50组机打档案编号作为测试样本,档案编号长度不少于6个字符。机打字符模板构建已在第2节中介绍,本文构建的标准模板样本共63个模式,分别为26个大写英文字母、26个小写英文字母、10个数字、1个连接线字符。由于机打编号格式较为规范,所以前期的图像预处理工作较少,字符分割过程中,本文利用图像灰度值垂直投影形成的空白间隙将单个字符分割出来,然后将分割得到的字符进行标准化处理,进一步用于计算欧拉数和模板匹配。
为了说明本文所采用的基于欧拉数的前期粗分类和模板匹配相结合的识别方法的有效性,实验中与经典的模板匹配方法进行了实验对比,实验结果如表1所示。

表1 机打编号自动识别实验数据
实验数据表明了本文所提方法的有效性,经过基于欧拉数的前期粗分类,不仅有效避免了不同字符之间的干扰作用,提升了识别准确率,而且缩小了模板匹配过程中的搜索范围,有效缩短了模板匹配时间,平均识别时间得到大幅降低。
4.2 手写编号识别实验
手写编号识别实验中采用了50组随机手写的档案编号作为测试样本,档案编号长度不少于6个字符。稀疏自动编码器训练过程中,采用了3900幅大写手写英文字母图像、3900幅小写英文字母图像、5000幅手写数字和连接线图像用于网络训练,由于“鲁”字字符的唯一性,所以无需参与网路训练。另外,由于手写编号差异较大,容易存在多种干扰因素,例如墨迹污染、字体倾斜等。因此,在使用测试样本进行识别前,需要对测试样本图像进行必要的图像去噪增强预处理,并对倾斜角度较大的字体进行校正,经过字符分割后将所有手写字符大小归一化为20×25像素,用做网络输入。网络初始参数如表2所示。

表2 聚合网络初始参数设置
在初始网络参数设置下,手写档案编号的识别准确度仅能达到28%,误差巨大,因此需对网络参数进行调试。本文实验中分别对表2中的参数进行了优化和调整,确定的网络最优参数如表3所示。

表3 最优网络参数配置
经过网络参数的逐步调整,基于稀疏自动编码器的手写档案号识别性能得到大幅提升,在50组随机手写的测试档案号中识别率达到98%。
5 结语
本文针对当前涉密文档信息化建设中的文档编号自动识别方法开展研究,通过提出融合欧拉数和模板匹配的机打编号自动识别算法,有效改善了传统模板匹配算法在相似字符识别中错误率较高的不足,而且较大幅度的提升了自动识别的速率。另外,针对不同人手写编号差距较大,难以采用传统识别方法实现编号识别的困难,本文构建了大规模数据集,训练了深度稀疏自动编码器网络模型,实现了手写编号的高准确度自动识别。本文研究的文档编号自动识别理论,可以在多种场合的编号识别中进行应用。如何将机打编号和手写编号识别方法进行融合,形成统一的识别理论是我们未来的研究工作。
猜你喜欢
农业工程学报(2022年5期)2022-06-22
舰船科学技术(2022年10期)2022-06-17
计算技术与自动化(2022年1期)2022-04-15
故事作文·低年级(2021年12期)2021-12-21
电脑知识与技术(2019年29期)2019-12-16
小学生学习指导(低年级)(2019年12期)2019-12-04
电脑爱好者(2019年8期)2019-10-30
水上消防(2019年3期)2019-08-20
文苑·经典美文(2019年8期)2019-08-06
前卫文学(2016年3期)2016-07-01
