
基于遗传算法的复杂绘制系统性能瓶颈识别
2019-03-02 02:35梁子
现代计算机 2019年2期
梁子
(四川大学计算机学院,成都 610065)
0 引言
计算机图形学在电子游戏、虚拟现实、视觉仿真等领域应用广泛,通过实时绘制系统的构建,完成不同领域的绘制需求。近年来,随着这些领域的不断发展,不同应用领域对真实感渲染提出了更高的要求,这使得实时绘制系统需要包含更为复杂的绘制算法以满足上述需求,如全局光照、物理仿真等绘制算法。每种绘制算法将通过若干算法参数控制实时绘制系统的渲染效果,同时这些绘制参数也直接影响实时绘制系统的绘制效率。
本文在基于文献[1]的基础上,重点关注全局最优划分解决方案的确定。即:利用遗传算法完成绘制特征空间的全局最优划分以及对应空间下性能瓶颈的识别。文献[1]提出从绘制系统提供的大量绘制性能数据中挖掘信息,以自动识别绘制系统中的性能瓶颈。绘制性能数据是指:绘制系统中所有与绘制算法相关的算法参数其有效取值与对应绘制时间构成的数据集;性能瓶颈是指:参与挖掘分析的若干算法参数中,参数数值的微小变化导致系统绘制效率急剧下降的参数。在完成上述工作的同时,针对在整体数据空间下无法确定性能瓶颈的情况,进一步提出基于子空间划分思想的方法,完成子空间下性能瓶颈的自动识别。
文献[1]采用局部最优的贪心算法完成子空间的划分,即:以当前所在数据空间为基准,尝试所有的划分策略并选择本次最优的划分方式。针对这种方式无法保证全局最优的空间划分,以及划分结果不稳定的缺点,本文提出基于遗传算法的划分方式以实现全局最优划分方式的确定,同时提高划分结果的稳定性。
1 算法实现
1.1 基本思想
空间划分方式仍然建立在文献[1]的基础上,完成设定次数的随机划分方案,根据不同的划分方案可以将数据空间进行不同的划分得到划分结果,某个划分结果称为“个体”,而将对应的划分方案进行编码得到该个体的“染色体”,染色体是唯一能够确定个体的属性,因此算法的操作都将关注于染色体,所有个体共同构成遗传算法的“种群”。本文的基本思想是:通过优胜劣汰的方式保留更适应生存的个体,同时,利用优质个体拥有的优质染色体,通过遗传的方式完成更优个体探索寻找,以此不断迭代直到种群趋于收敛。本算法提出“适应度函数”(具体参见1.3.3)以完成对个体(即:空间划分树)对环境的适应度评估。
1.2 算法实现
不失一般性,我们在绘制系统R中采集得到当前绘制场景的性能数据集s,我们将利用该性能数据集S完成对当前绘制场景中性能瓶颈的识别工作,具体算法如下:
(1)根据完整性能数据集S建立评估模型F(本文采用随机森林模型);
(2)不失一般性,我们称S集合的任意子集为Sk,利用F可以计算当前Sk数据空间中,参数集P中各个参数pi的变量重要性I(pi);
(3)根据瓶颈判定机制(具体参见1.3.1)确定当前数据空间Sk下是否存在性能瓶颈,如果存在,停止Sk的划分,输出识别到的瓶颈集合,即计算得到的瓶颈集合就是当前数据空间Sk下识别到的瓶颈,否则,执行步骤(4);
(4)判断Sk是否满足继续划分的条件,如果满足,执行步骤(5),否则,停止Sk的划分;
(5)针对当前数据空间Sk进行二分划分(参见文献[1]):利用数据空间划分机制(具体参见1.3.2)完成Sk的划分,生成新的子空间,遍历S分别执行步骤(2);
(6)遍历步骤(2-5)划分得到的数据空间二叉树,进行染色体的编码工作(具体参见1.3.4),并完成对该二叉树(划分结果)的个体适应度评估(具体参见1.3.3);
(7)按照预设种群规模重复执行步骤(2-6)得到N个个体共同构成遗传算法的初始种群G0;
(8)完成种群Gi的选择、交叉、变异算子(具体参见1.3.5),生成新的种群Gi+1,不断迭代该步骤直到Gi、Gi+1的种群适应度(具体参见1.3.5)差距小于判定阈值,结束整个算法。
1.3 实现细节
(1)瓶颈判定机制
在数据空间Sk下,计算参数集P所有参数pi的变量重要性I(pi),以其中的最大值为范围上界将参数的变量重要性范围进行三分,分为上中下三部分区域,如图1(a)(b)所示,如果变量重要性落在上部分区域的参数个数小于等于设定阈值(阈值为2),同时,其余参数的变量重要性均落在下部分区域,则我们称之为Sk数据空间下已经识别到瓶颈。为了更清晰地描述问题,参见图1(c)中落在上部区域的参数个数过多,(d)中落在中部区域的参数个数过多,因此(c)、(d)均没有识别到瓶颈。
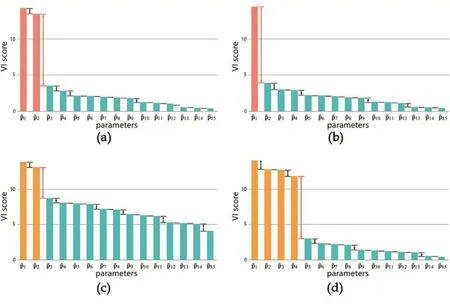
图1 瓶颈判定示意图
(2)数据空间划分机制
本文基于参数变量重要性的启发式方法完成种群的初始化工作。具体来说:I(pi)数值越高的参数 pi应该在数据划分过程中拥有更高的影响力,换言之,为了使得一个参数拥有更高的影响力,它就应该在被选择成为空间划分属性时拥有更高的概率。
基于上述思想,我们使用如下策略完成针对某划分空间二叉树的一个非叶节点n(节点深度为d)其划分属性(参数)和划分位置(参数数值)的确定:
①决定划分参数
在某数据空间Sk下,计算参数集P所有参数pi的变量重要性I(pi),之后,基于的轮盘赌策略将被采用以选择划分参数进行节点n的划分。从该策略中可以看出:拥有更高I(pi)的参数将更有机会被选为划分参数,但随着划分层数的加深,这种影响力将逐渐减弱,各个参数被选中的概率趋于一致。
②计算划分位置
一旦划分参数确定后,具体的划分位置应该被确定成为该空间的划分超平面(文献[1])。考虑到当数据空间的规模减小到一定程度时,通过随机森林计算得到的变量重要性I(pi)将变得不稳定,因此本文方法倾向于将数据空间进行更为均衡的划分,即:尽量不使两个子空间中任何一个子空间的数据量过少。假设参数p的有效取值范围是[pmin,pmax],Ns个候选划分位置由公式(1)生成,其中 i=1,2,...,N。s对于每个候选位置pican的划分超平面,假设和是划分后两个子节点中数据的个数,候选位置的选取基于的正态分布原则。

(3)适应度评估
适应度函数在遗传算法中起到至关重要的作用,它指导着种群的进化方向,如公式(2)所示,适应度函数F(·)描述数据空间S被划分成n个子集S1,S2,...,Sn的好坏,即:某个空间划分树的适应程度。
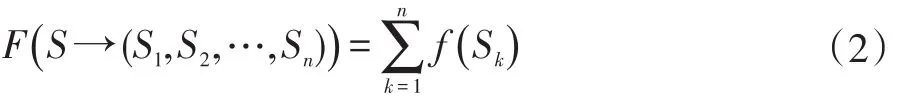
其中f(Sk)是某个子空间的适应度函数,F(·)称为划分适应度函数。
本文遵循如下原则用来设计 f(Sk):
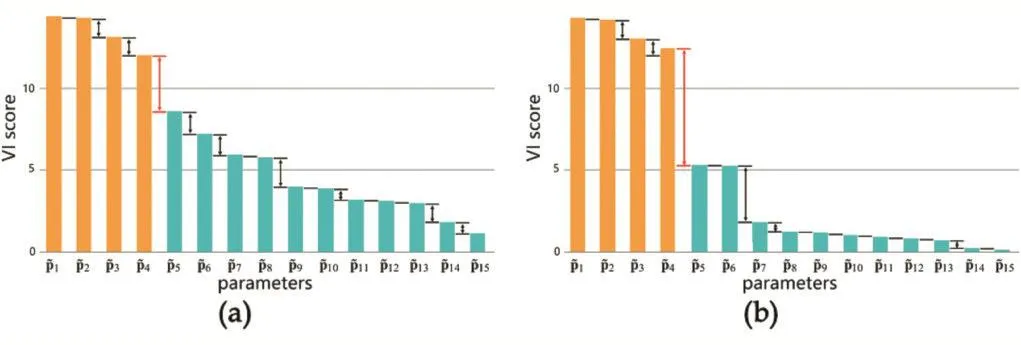
图2
图2即使(a)(b)中没有识别到瓶颈,我们认为情况(b)要优于情况(a),因为(b)中红色区域所标注的最大落差大于(a)中最大落差。

图3
图3即使(a)(b)中均识别到瓶颈,我们认为情况(b)要优于情况(a),因为(b)中瓶颈个数小于(a)中瓶颈个数。
因此我们需要设计出满足如下条件的函数:
①F(·)应该是一个连续性的函数以保证可以用来比较任何两种划分结果的好坏;
②变量重要性I(pi)的值应该影响 f(Sk)。具体包括两个方面:(a)重要的参数(位于I(pi)上部分区域的参数)个数越少,f(Sk)值越高;(b)不重要参数(位于I(pi)下部分区域的参数)个数越多,f(Sk)值越高;
③划分出的子空间总个数也应该被考虑,以保证不会将原始数据空间S划分成过多的子区域;
基于上述三方面的考虑,f(Sk)可以由公式(3)表示:

其中f1(Sk),f2(Sk),f3(Sk)是影响f的三个不同的因子,公式(4)具体阐述了其具体计算公式:

其中,Nsig是落在上部区域的参数个数,Nmid表示中部区域的,Ntri表示下部区域的;Isaigvg是落在上部区域的参数其变量重要性的平均值,Itarvig表示下部区域的;|*|表示数据空间中数据量;而w1,w1,w1是控制三个分量的比重因子,由用户指定。
(4)染色体编码
遗传算法要求所有的个体拥有一个统一格式的染色体编码方式使得遗传算子能够顺利地操作于不同的个体上。但由于我们有数量庞大的不同划分方式来实现原始数据空间的划分,同时,不同划分结果所包含的子空间个数也不尽相同,这使得对空间划分结果进行染色体编码成为一件极富挑战的工作。
受计算机图形学领域广泛应用的分层数据结构(如光线跟踪技术中的KD-Tree[2])的启发,我们提出使用伪满二叉树表示任意维度的划分过程以及划分结果。其关键思想如下:
①采用二叉树表示空间划分的过程和结果;
②每个非叶节点n可以被认为隐式地生成分裂超平面,将数据集划分为两部分。节点n与参数pi∈P关联并且生成的超平面与 pi对应的轴垂直。如图4所示,节点n记录一个信息对(pi,piv),其中 piv是参数 pi轴上的一个有效取值;
③我们在该二叉树中引入空节点进而将其转化为伪满二叉树。如果所有的伪满二叉树被要求拥有相同的深度,则所有的划分结果均可以被表示为一个统一的形式;

图4 二叉树表示数据划分过程,与光线跟踪技术中的KD-Tree相似

图5 编码后的染色体
所有位于伪满二叉树中的节点通过上述方式可被储存在一维数组中。根节点的索引下标为0,节点索引下标为i时,其左右孩子节点将分别被储存在下标为2i+1和2i+2,如图5所示。最终该一维数组即为本文所述的染色体。
(5)遗传算子
①选择算子
该算子的目标是从本代种群中选择优质个体以生成新子代个体。我们采用轮盘赌策略来完成选择任务。具有较高适应性的候选个体具有更高被选择的可能性用来培育新一代。
②交叉算子
为了产生新的子代个体,通过交叉算子,本代种群中的一对个体将作为父代进行交叉以产生新的子代个体,为了加速收敛,我们通过公式(5)计算交叉发生的概率 Pc,同时,一个随机数 t∈[0,1]生成,当 t>Pc时,交叉操作应用于两个选定的父代。

其中Fmax,Fmin分别是当前一代的最大和最小适应度,Icur和Imax分别是当前一代和最大一代的数量,是当前一代的适应度方差,Fmore是来自两个选定的父候选解决方案的较大适应值,而Fless是另一个父亲的适应值。公式(5)表明交叉的可能性受以下三个因素的影响:第一个因素是Pc在进化的早期阶段会更大;第二,它与当前一代的适应度方差正相关;最后,Pc会随着两个父母之间的适应度差异的增加而增加。所有这些策略都旨在提高GA(遗传算法种群)的收敛速度。
③变异算子
变异算子的目的是避免GA收敛到某些局部最优解。它有助于维持人口的遗传多样性。在我们的工作中,我们将随机选择一些候选解决方案,并在一些随机位置改变它们的染色体。
2 实验结果
2.1 实验环境
PC配置:Intel Core i7-6900k3.2GHz CPU,32G 内存,NVIDIA GeForce GTX-1080显卡;
场景配置:54011个三角面片的DiningRoom模型,分布有300个动态光源,25个透明物体。
参数空间说明:绘制系统基于延迟渲染框架,执行Light-Linked-List(LLL)算法[3]产生大规模动态光源光照效果,执行 Order-Independent-Transparency(OIT)算法[4]实现场景透明物体,执行SSAO算法[5]基于屏幕空间优化绘制效果。
本文算法中参数集P采用的参数列表:

表1
为了采集场景性能数据集,我们在场景中随机漫游采集到150,000条数据构成整个性能数据集。
2.2 实验结果
第一个实验用来验证使用本文提出的方法生成初始种群的有效性,种群规模为200个个体。图6展示了随着种群的不断迭代,种群平均适应度的变化情况,其中蓝色折线表示采用我们提出的方法进行初始种群的生成,橙色折线表示完全随机的生成初始种群个体。图中可以看出,利用本文的方法确实能够提高初始准群的质量进而进一步加速迭代的收敛;同时也证明了本文遗传算法策略对于提高种群的适应度是有效的。

图6
实验二中,我们比较了本文方法与BAT方法[1]的结果。图7(a)(b)分别展示了本文方法和BAT方法对于同一个场景处理的结果,由图可知,由于我们的方法可以在任一局部数据空间中确定单个的瓶颈,因此具有更好的处理结果。同时,再次考虑划分结果的适应度,本文方法所得到的最终结果其适应度分数为0.86262,要高于BAT方法得到的得分0.771819。

图7
3 结语
本文提出一种复杂绘制系统算法级别的性能瓶颈识别方法,针对复杂性更高的绘制系统越有可能出现不存在全局瓶颈的情况,进一步改进了绘制数据空间划分的算法,提出利用遗传算法进行全剧最优的数据空间划分算法,旨在合理划分全局数据空间到不同子空间,使得在各个子空间中识别到局部性能瓶颈。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
今日农业(2022年15期)2022-09-20
英语文摘(2021年10期)2021-11-22
作文周刊·高二版(2019年43期)2019-01-06
生物学教学(2018年3期)2018-08-08
中学生物学(2018年8期)2018-03-01
当代旅游(2016年10期)2017-04-17
财经理论与实践(2015年2期)2015-04-16
现代企业(2015年9期)2015-02-28
中学生物学(2008年6期)2008-08-29
