
基于协同过滤的高校图书推荐系统
2019-03-02 02:35刘涛
现代计算机 2019年2期
刘涛
(南京工程学院计算机工程学院,南京 211167)
0 引言
近些年来,互联网技术蓬勃发展,即将进入5G时代的移动互联网、物联网、云计算等技术都是各个国家和公司的关注重点。与此同时,全球互联网能产生的信息量级也从TB发展为PB,甚至ZB。信息量的飞速增长,使人们能获取更多的信息资源,但也增加了人们获取所需信息的难度,这被成为“信息超载”。如何解决“信息超载”,节约人们的时间和精力,成为研究的重点。
搜索引擎是一种解决方案,但随着数据量的增加,仅仅通过搜索往往已经满足不了人们的需求,推荐系统成为一种更好的解决方案,相比搜索引擎的“一对多”,推荐系统实现了“一对一”的服务方式,它能够根据每个用户的个人爱好和习惯,做出个性化推荐。同时还能够及时跟踪用户需求的变化,做出的推荐也会跟着需求的变化而变化。
大学图书馆拥有着数十万甚至数百万的图书资源。向喜欢或需要的读者推荐相应的图书,实现图书的个性化推荐,具有十分重要的意义。
1 协同过滤技术
目前,推荐系统中的推荐技术主要有关联规则、基于内容的推荐、协同过滤和混合推荐方法。协同过滤根据其他用户的偏好向目标用户进行推荐。它首先找到与目标用户的偏好一致的一组邻居用户,然后分析邻居用户,并推荐邻居用户喜欢的目标。协同过滤具有以下优点:①不需要考虑推荐项目的内容;②可以为用户提供新的推荐;③访问网站时对用户的干扰较小;④技术易于实现。因此,它已经成为一种流行的推荐技术。
以下为协同过滤技术分类如图1所示。
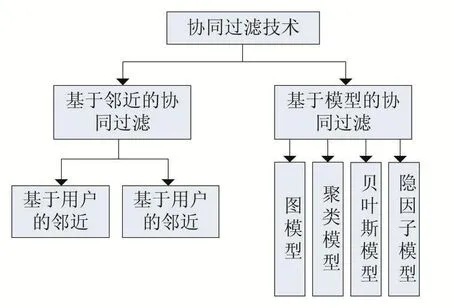
图1
2 研究内容
2.1 模型框架

图2
算法流程:
输入:用户数据
输出:用户感兴趣图书
(1)按照规则对用户借阅记录打分(1为最低,5为最高)。
(2)评分矩阵构建,使用一年的学生借阅数据,以用户集合U为行,以图书集合I为列,构建评分矩阵A。Aij为用户Ui对图书Ij的打分。
(3)特征提取,使用SVD分解评分矩阵,将稀疏高维度评分矩阵降维存储。获得用户特征矩阵和物品特征矩阵。
(4)寻找邻居,使用KNN算法,基于欧氏距离,寻找用户Ui的2k个邻居。
(5)优化邻居,利用修正关系后的距离公式,重新计算Ui与2k邻居的距离,找到最近的k个邻居。
(6)输出推荐结果,对k个邻居借阅书目使用SVD预测打分,按打分高低输出前m个推荐书目。
2.2 SVD(奇异值分解)
现实生活中大部分矩阵都不是方阵,方阵可以使用特征值分解来描述它的重要特征,对于普通矩阵,我们使用奇异值分解来描述其重要特征。

我们假设A是一个N×M的矩阵,分解后的U就是一个N×N的方阵(U里面的向量被称为左奇异向量),Σ是一个N×M的矩阵(除对角线元素以外的元素都是0,对角线上的元素称为奇异值),VT(V的转置)是一个N×N的矩阵,V里面的向量称为右奇异向量。
我们将一个矩阵A的转置乘A,将会得到一个方阵,我们用这个方阵求特征值可以得到:

Vi就是右奇异向量,此外:
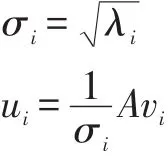
σ是奇异值,u是左奇异向量。奇异值σ跟特征值类似,在矩阵Σ中从大到小排列,而且σ的减少特别的快,在多数情况下,前10%甚至更少的奇异值的平方和就占了全部奇异值平方和的90%以上了。也就是说,我们也可以用前r个奇异值来近似描述矩阵:

右边的三个矩阵相乘的结果将会是一个接近于A的矩阵,r越接近于n,则相乘的结果越接近于A。而需要保存这三个矩阵的存储空间,要远远小于原始矩阵A的存储空间。
2.3 KNN回归算法
KNN算法:对于任意的n维输入向量,其对应于特征空间一个点,输出为该特征向量所对应的类别标签或者预测值。它实际上的工作原理是利用训练数据对特征向量空间进行划分,并将其划分的结果作为其最终的算法模型。
对新来的预测实例寻找K近邻,然后对这K个样本的目标值去均值即可作为新样本的预测值。

2.4 基于关系的修正距离
对于用户特征矩阵Um*n,m为用户数量,n位特征维度。可以使用KNN获得用户u和v是相似用户,但这样不能很好地挖掘出用户之间的兴趣关系。向量g=u-v可以表示两个用户之间的兴趣差异关系,g⊥表示g在其余(n-1)个特征维度上差异向量(为可视化方便,将(n-1)维看做1个轴,见图3)。可见,两个用户只应该在g上存在差异,而与g⊥的距离应该相同。通过以下方程可以变换:

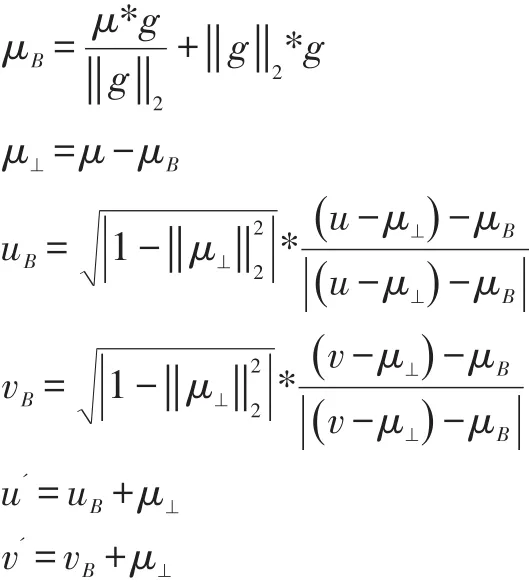

图3

图4
经过变化后的u'和v'在g⊥上具有了相同距离(图4),而只在g上存在差距。使用余弦相似度计算用户与关系g的差距:

3 实验
随机从用户中抽取一名,编号为6334。对其进行图书推荐。首先使用KNN模型获得其10个邻居,编号分别为:
[11,104,164,195,228,245,256,291,352,373]
这里设定关系为用户6334与其10个邻居差值的平均值,即:

使用关系距离修正模型重新计算相邻用户,其前5个邻居编号为:
[291,104,164,373,245]
待评分书目集合是这5个邻居的借阅书目集合与该用户借阅书目集合的差集。
最后使用SVD模型对待评分书目集合打分,按高分排序,如表1所示。

表1
4 结语
在如今信息超载的时代里,推荐系统已经成为现代信息社会人们获取信息的重要技术手段,可以帮助人们获取到真正感兴趣的信息,本文提出了在奇异值分解和KNN基础上修正关系的综合推荐方法,提高了基于协同过滤推荐的推荐精度,能更深挖掘出读者潜在的阅读需求。
本文选取了本校1年的借阅数据,随着数据规模的扩大,推荐准确率也会相应提高,但对于更大规模数据的处理,如何增加更多用户行为,就成为了我们接下去的研究工作。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
都市人(2022年3期)2022-04-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
环球时报(2020-09-18)2020-09-18
学生导报·东方少年(2019年24期)2019-12-30
环球人物(2018年19期)2018-10-17
散文诗世界(2016年5期)2016-06-18
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
全国新书目(2009年1期)2009-04-13
