
一种基于词加权LDA模型的专利文献分类方法
2019-03-21 11:35刘文静葛丽阁
计算机技术与发展 2019年3期
孙 伟,刘文静,葛丽阁,余 璇
(上海海事大学 信息工程学院,上海 201306)
0 引 言
每年公布的专利说明书约100万件,并以每年9万件的速度递增。目前专利文献分类主要以国际专利分类法(IPC)作为分类标准,而使用IPC进行检索时需了解IPC分类号对应的位置和内容。而面对数量如此庞大的专利文献,仅仅依靠人工方式对专利文献进行分类已经不能满足文献数量快速增长的需求。因此,利用计算机对大量专利文献进行自动分类就显得愈加重要。
近年来,由于主题模型在文本分类方面取得了极好的应用效果,学者们结合专利文献的特点开展了主题模型在专利文献分类领域的研究工作。这些研究工作主要分为两大类,一类是利用专利关键词、作者或单位等辅助信息的专利文献分类。黎楠等[1]在文档-主题-词模型的基础上,利用每位发明人的专利数据,提出了一种发明人兴趣主题模型的方法,将标准三层LDA模型变为专利数据中的发明人-主题-词的发明人兴趣模型,实现发明人的主题发现。王博等[2]将主题模型应用于专利文献时,利用专利机构信息构建LDA机构-主题模型,对专利知识主体和客体联合建模,实现专利主题和机构之间的内在关系分析。另一类是基于专利内容的专利文献分类。蒋健安等[3]改进了无词典分词和权重计算,提出一种层次分类方法,面向专利文献数据的文本自动分类系统做框架模型。专利文献中出现的专业词汇具有更优的主题区分能力,学者们针对LDA模型的词对主题分类中的影响也开展了相关研究。董元元等[4]提出LDA-σ方法,将“词—主题”间互信息的标准差作为特征评估函数。张小平等[5]从LDA中代表主题的多数词会被少量的高频词淹没的问题出发,提出一种高斯函数对特征词加权的改进LDA模型。Ramage等[6]提出一种有监督LDA模型,通过将文档的所属主题直接添加映射标记来实现文档主题的多标记判定,但是其泛化能力较差。李湘东等[7]在点互信息(PMI)模型的基础上,结合词性、位置等要素修正特征词的权重,并改进LDA模型,以提高模型的分类准确率。
对于专利文献,专业词汇相对普通词具有更好的主题表达能力。文中将从专业文献中词的共现关系出发,对专业词汇进行加权处理,提出一种新的有监督LDA模型,以期在迭代效率和分类准确率方面有更优的表现。
1 主题模型
主题模型具有良好的文档分类能力,传统的主题模型有LSA、PLSA和LDA[8]等。LDA模型采用词袋(BOW)模型,原始语料库通过分词、去停用词处理后,可以表示为三层生成式贝叶斯网,依次为文献集合层、主题层和词层。
LDA模型是一种有向概率图模型,如图1所示。其中,θm表示文献主题的概率分布,φk表示主题词的概率分布,M表示专利文献集的文献个数,K表示文献集的主题数,N表示每篇文献的特征词数。模型中含有超参数(α,β),其中α为每个文档下主题的多项分布的狄利克雷先验参数,β为每个主题下词的多项分布的狄利克雷先验参数。
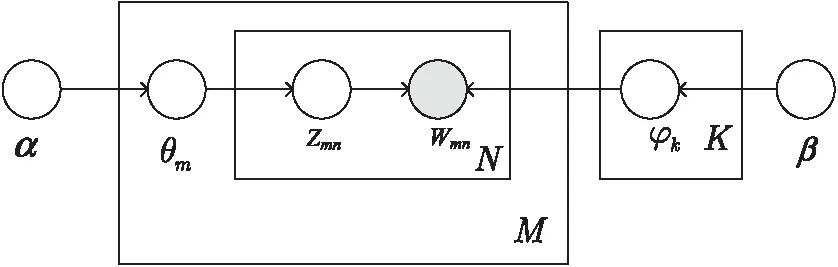
图1 LDA模型有向概率图
LDA模型隐含参数求解公式如下:
其中,i=(m,n)是一个二维下标,对应第m篇文献的第n个词;i表示去除下标为i的词;表示第k个主题产生的词中位置t的词个数;表示第m篇文档中第k个主题产生的词个数。
2 基于词加权LDA模型的专利文献分类方法
基于词加权LDA模型的专利文献分类流程如下:
(1)对专利文本集进行分词、去停用词等处理。
(2)针对专利文献中专业词汇与高频词对主题贡献度的不同,利用KeyGraph算法抽取文献中的关键词,利用互信息函数计算关键词的权重,建立专业词字典存放关键词及其对应的权重值。
(3)构造词加权有监督LDA主题模型,对专利文本进行主题分类。
2.1 专利文本预处理
文中采用向量空间模型,在专利文本预处理阶段,首先使用python中的jieba库实现文本分词,该库在全模式下对句子切分的精确度高,适合做文本分析。接下来删除停用词表(包括连词、形容词等与主题关系不大的高频词)中的词,进行粗降维。
2.2 词权重计算方法
由于LDA模型在进行分类时,得到的主题词分布会向高频词倾斜,使得主题表达能力强的低频词分配到各主题中的概率较低,而主题表达能力弱的高频词分配到各主题中的概率较高,降低了模型的主题分类效果。因此文中先利用KeyGraph算法提取主题表达能力更好的关键词,再根据互信息计算关键词与文献间的相关性值作为权重值。
2.2.1 基于KeyGraph的Key词抽取
KeyGraph算法是日本学者Y.Oshawa[9]于1998年提出的,主旨基于建筑物结构隐喻的索引思想,把图分割成群,其中图描述了一篇文档中词之间同时出现的关系,每个群集对应一个思想基础的概念,根据每个词和它们群集之间的关系,采用统计方法得出排序最高的词作为关键词。这些关键词并不都是高频词,还包含有与高频词共现的部分低频词。在专利文献中,它们具有专业词的特征。
KeyGraph算法抽取关键词的过程如下:
(1)提取高频词。用统计方法提取出文献中词频高于指定阈值(HF)的词作为高频词,将选中的高频词作为图中的顶点,高频词集合用V表示:
V={w|w∈W∩w.times>HF}
(3)
(2)计算高频词间的关联度。用统计方法计算两个高频词在同一句子中的共现度,连接共现度高于指定阈值的两个高频词,形成边集合,此时图中形成一个或多个岛屿。高频词间的共现度计算公式为:
(4)
(3)获取关键词。为了表明各个单词对主题的影响大小,KeyGraph算法定义了一个计算函数key(w),其值在0到1之间。而为了计算该函数,还定义了两个辅助函数:
(5)
(6)
(7)
其中,based(w,g)表示词w和群g之间的同时出现关系,即w作为g中词出现在同一句子中的次数;neighbors(g)表示包含g中词的句子中的词个数。
基于此,函数key(w)的计算公式为:
(8)
依据key函数,取W中最大的r个key值最高的词形成高关键度词集KF,r取经验值。将高关键度词集中未出现在图中的词作为新节点加入图中。
(4)计算高key词和高频词间的关联度。

wj∈V
(9)
若base(wiwj)!=0,且图中节点wi和wj间无边,则将节点用虚线连接,得到文献的KeyGraph图。计算图中与群相关的各节点base值,若该base值超过指定阈值,则该节点对应的词即为关键词。
举例:一篇专利文献经过分词、去停用词处理后形成的5个句子如下:
S1:{外科,器械}
S2:{外科,器械,位置,传感器,系统}
S3:{位置,传感器2,系统,操作,联接,外科,器械,可动,驱动,构件,传感器,元件}
S4:{位置2,传感器3,操作,联接,传感器,元件2,构造,感测,传感器,元件,位置}
S5:{外科2,器械2,位置6,传感器9,系统1,位置,传感器,传感器,元件4,传感器,元件,操作2,联接2,外科,器械,可动,驱动,构件,位置,传感器,位置,传感器,操作,联接,传感器,元件,位置,传感器,构造,感测,传感器,元件,位置}
文献中单词集对应的编号及词频如下:

根据得到的词频,取阈值为2,则得到高频词集HF={1,2,3,4,5,6,7,8}。计算高频词间的关联度,形成边:

接下来将关联度排序,取阈值为3,将高频词对应的节点用实线连接起来形成边,得到两个群组,即g(1)={1,2,3,4,5,6,8},g(2)={7}。目标是找出文献中能表达文献主题的专业词汇,而非高频词,因此只需要计算非频繁词的key值。由式5可知,要计算非频繁词与高频词群间的关联度,可以先求非频繁词与高频群组中的每个高频词的关联度,再对每个值累加求和。非频繁词与高频群组中的每个高频词的关联度如下:

最后,取阈值0.3,则{9,11,13}∈KF。如果base(wi,wj)!=0,则在wi和wj之间用虚线连接。至此,KeyGraph图形成。
2.2.2 关键词的权重值计算
为了表示专利中词和文献间的关系程度,文中使用点互信息[10](PMI)作为评价函数处理专利中关键词的权重值。点互信息在信息论中用来衡量两个随机变量之间的相关性。关键词t和文献pi的点互信息体现了关键词和文献相关联的程度。若关键词t在某些文献中出现的概率很高,而在其他文献中出现的概率偏低,那么它将获得较高的点互信息值,计算公式为:
(10)
其中,p(t)表示关键词t在整个训练文献集中出现的词频概率;p(pi)表示训练文献集中第pi篇专利与整个训练集文献的词频比值;p(t,pi)表示第pi篇专利中含有关键词t的概率。
在式10的基础上关键词的权重值计算公式为:
(11)
通过点互信息计算出关键词的权重值,将关键词对应的文献编号和权重值保存在专利词字典中。
2.3 基于词加权的有监督LDA模型
2.3.1 词加权LDA模型
文中将KeyGraph算法与LDA模型相结合,提出一种新的词加权有监督LDA模型(简称KG-PMI-LDA模型)。该模型通过KeyGraph算法选取文献中的关键词作为特征词,并建立专业词字典记录各关键词在各文档中的权重值。进而,利用该字典对特征词加权和归一化,实现对LDA模型的改进。
提出的新模型与传统LDA的不同之处在于,模型中word层根据KeyGraph算法标记出了key词与非key词,设key词与非key词都是由相同的狄利克雷分布产生,但对应产生的概率分布区别表示,从而有助于提高主题学习的正确性。KG-PMI-LDA模型的概率图模型如图2所示。
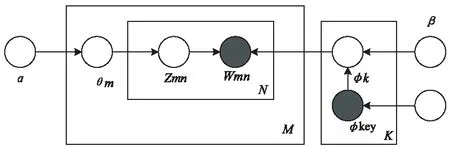
图2 改进后的LDA模型有向概率图
假设每个主题k由一些特征词构成,w(k)=(w1,w2,…,ws),其中每个词wi(i∈[1,s])的权重值由专业词字典获得。如果该词为关键词,权重值为字典中关键词的权重值;否则,权重值为零。由此,可得权重向量:
各主题的词概率分布的狄利克雷先验概率分布β修改为:β(k)=L(k)×β=(βl1(k),…,βls(k))T。
KG-PMI-LDA模型是一个生成式概率图模型,其文本语料库生成过程如下:
(1)对整个专利文献集根据概率生成文献主题分布:θm~Dir(α);
(2)对于每个主题z,根据概率生成主题特定的词分布:φk|key~Dir(β),其中若为key词,多项式分布向量表示为φkey,若为非key词,多项式分布向量表示为φk;
(3)根据文献中专利词对照表得到文献d的词数目Nd,Nd服从泊松分布;
(4)对于文献d中每一个词wn的生成过程,即如4.1、4.2,迭代T次:
(4.1)对词wn根据Multinomial(θm)确定主题z,若为非key词,从θm的多项式分布Multinomial(θm)随机选择一个主题z,若为key词,在θm的多项式分布Multinomial(θm)中,根据专利数据字典对key词进行权重处理后再随机选择一个主题z;
(4.2)从主题z的多项式条件概率分布Multinomial(φ)中选择一个词w。
上述过程迭代完成后,含有Nd个词的文献就相应产生了。
2.3.2 模型的学习过程
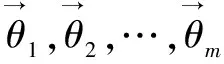
假设模型中文档d的第i个位置的词的主题概率分布的Gibbs Sampling公式为:
其中,zi=k,k表示主题数,Gibbs Sampling过程是一个从文档到主题,再到词的过程,其含义就是从文档到词,经过主题zi(zi∈[1,k])的k条路径中进行采样。
至此,基于专业词字典得到该词的权重weight(w)后,将其与LDA中主题的概率θm和词的主题概率φz相结合,给不同的特征词在不同主题下分配不同的权重,改变模型生成特征词的概率,更新式1和式2:
(14)
再结合式13和式14提出一个新的吉布斯采样公式进行参数推导,如下:
p(zi=k|z,weight(w))∞
(15)
这里,根据式13~15,将模型的学习过程描述如下:
输入:专利文献集、主题个数K、超参数
输出:各词所属主题编号z
(1)随机初始化:对专利文献语料库中的每个词随机地赋予一个主题编号z;
(2)重新扫描专利文献语料库,对每个词w:若w为key词,则按照式15重新采样它的topic,在语料中进行更新;若w为非key词,则按照式12重新采样它的topic,在语料中进行更新;
(3)重复语料库的重新采样过程直到Gibbs Sampling收敛,最后统计语料库的topic-word频率矩阵,该矩阵就是改进后的LDA模型;
(4)根据式13和式14估计模型中的参数。
3 实验及结果分析
3.1 实验材料
文中采用中国知网(www.cnki.net)上真实专利文献作为实验材料。从某大学图书馆的中国知网的电子专利数据库中,选取信息科技类的9个专业类别,分别为无线电子学、电信技术、计算机硬件技术、计算机软件、互联网技术、自动化技术、广播电视、机器学习、信息管理,采集的内容为专利摘要和主权项。从9个专业中共采集7 023篇专利作为数据集。采用三折交叉实验法,平均从9个专业类别中取4 682篇作为训练数据,2 341篇作为测试数据。
实验所用PC机为Thinkpad A6-3400M,主频为1.4 GHz。采用Python2.7基于提出的KeyGraph算法实现关键词提取,具体的评估函数计算key词对文献的贡献度建立数据字典,通过Python实现改进后的专利文献主题模型,利用WEKA工具对分类的效果进行评价。
3.2 特征选择效果对比
将提出的基于KeyGraph算法的关键词抽取方法抽取的关键词、专利文献中的高频词和基于TF-IDF方法进行特征选择进行对比。实验采用的7 023篇专利中,KG-PMI-LDA模型选取出关键词共80 545个,利用互信息函数计算出的关键词权重值中,有12 993个为负值,去除这部分关键词,共计得到67 552个关键词。其中,以郑水钦等发表的文献《一种测量高强度太赫兹时域光谱的装置和方法》为例,对专利的摘要和主权项内容做预处理后,根据词频、TF-IDF特征选择和文中方法选取出的关键词作对比,结果如表1所示。
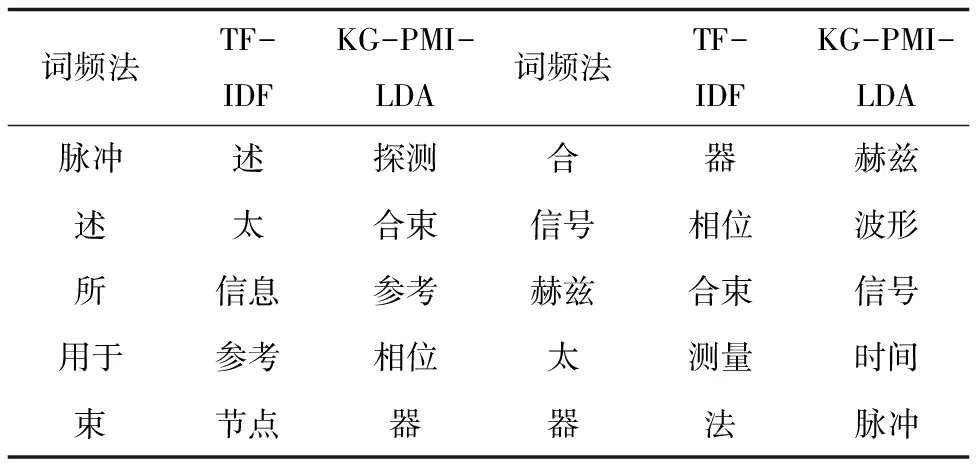
表1 关键词比较
从表1可以看出,仅仅根据词频得到的高频词如“述”、“所”、“用于”、“合”,与专利主题测量高强度太赫兹时域光谱关联度很低,根据TF-IDF方法得到的关键词中也有“述”、“太”、“参考”、“器”、“法”等对专利主题区分度不高的词,而KG-PMI-LDA方法提取的关键词,其中的“探测”、“合束”、“相位”、“赫兹”、“波形”、“信号”等更能代表该篇专利,可以作为代表该篇专利文献的专业词。
3.3 专利文献分类效果对比
为验证KG-PMI-LDA模型在专利文献分类的有效性,将KG-PMI-LDA模型与传统LDA模型、文献[3]提出的LDA-k-optics模型和文献[5]提出的LDA-σ模型进行对比实验。分类效果评估指标使用文本分类中常用的准确率P(Precision)、F1值(F-measure)和召回率R(Recall)。KG-PMI-LDA模型采用Gibbs Sampling推理方法进行参数估计,模型中的参数设定为:K=9,α=0.01,β=0.01。实验选取迭代次数70至110次。KG-PMI-LDA模型、LDA模型、LDA-k-optics模型以及LDA-σ模型在相同迭代次数下,准确率、F1值、召回率的对比如图3所示。
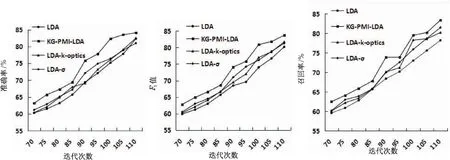
(a)准确率 (b)F1(c)召回率
图3 实验结果比较
可以看出,针对专利文献此类专业性的文献语料库,KG-PMI-LDA模型在准确率、F1值与召回率三个指标上都要好于其他三个模型。在分类准确率方面,KG-PMI-LDA模型较LDA模型、LDA-k-optics模型和LDA-σ模型平均提高了4.62%、3.74%和3.26%。在F1值方面,KG-PMI-LDA模型较LDA模型、LDA-k-optics模型和LDA-σ模型平均提高了4.48%、3.02%和2.18%。在召回率方面,KG-PMI-LDA模型较LDA模型、LDA-k-optic模型和LDA-σ模型平均提高了4.09%、2.38%和2.18%。这说明KG-PMI-LDA模型通过KeyGraph算法选取出的关键词多数并不是高频的特征词,但却对专利文献特征有更强的描述能力,其对分类贡献度较高,在Gibbs Sampling中对关键词的加权和归一化,避免了专业词被高频词所淹没,使得该模型较传统LDA模型、LDA-k-optics模型和LDA-σ模型有更高的分类准确性。同时,从实验结果还可以看出,在达到相同分类准确率的前提下,KG-PMI-LDA模型较其他模型的迭代次数更少,即KG-PMI-LDA模型的迭代效率更高,可以更快地达到稳定状态并得到分类的结果。以图3(a)为例,KG-PMI-LDA模型与传统LDA对比,准确率达到69.4时,传统LDA需要进行97次迭代过程,而KG-PMI-LDA模型只需迭代85次,较传统LDA模型少12次;以图3(b)为例,当F1值达到68.5时,传统LDA需要进行90次迭代,而KG-PMI-LDA模型只需迭代82次,迭代的次数少了8次。
KG-PMI-LDA模型通过关键词权重的计算,提高了专利文献特征词的选取效果。选取迭代次数为90时,比较传统LDA模型和KG-PMI-LDA模型的准确率、召回率、F1值,如表2所示。
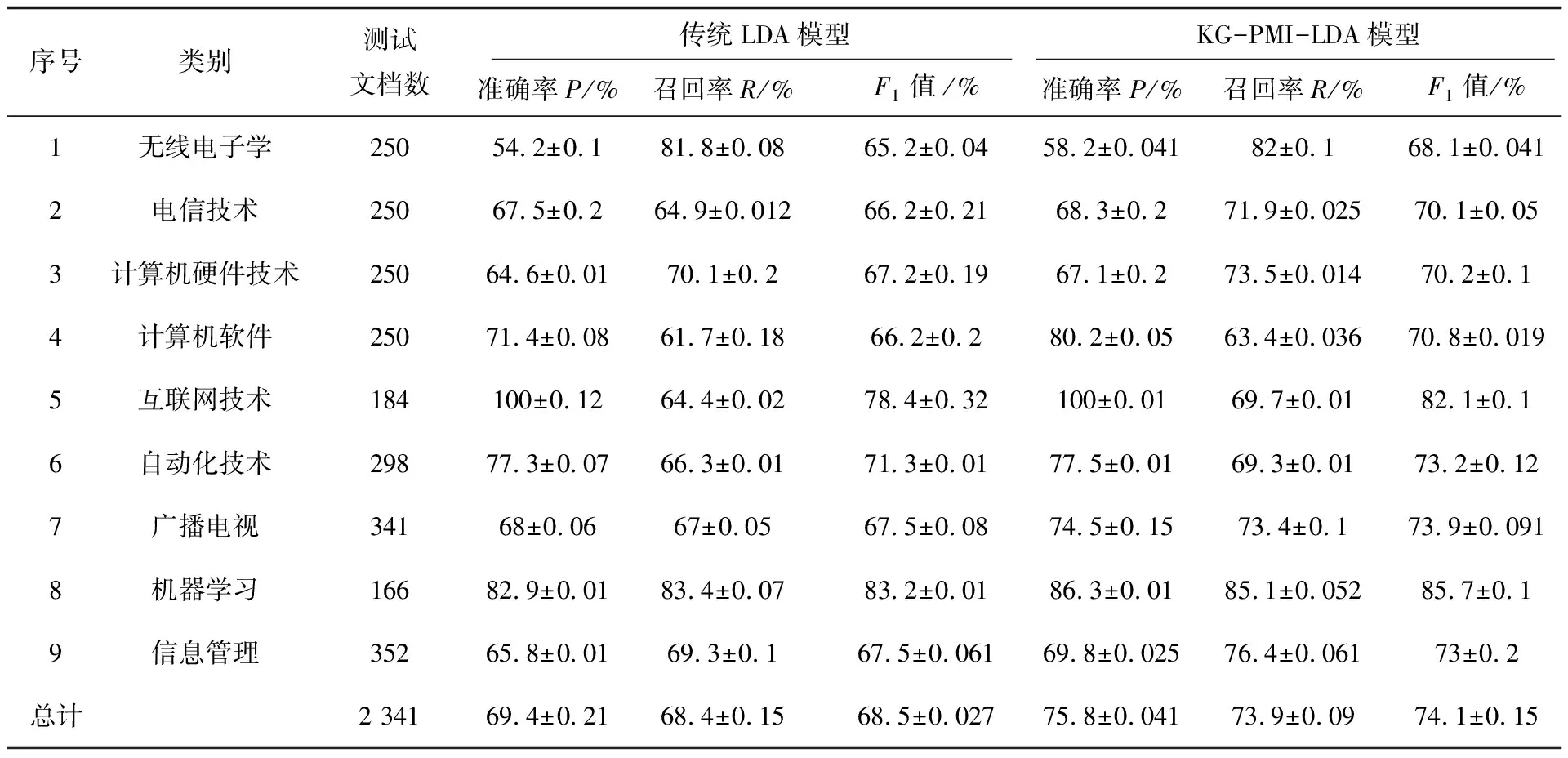
表2 迭代90次的准确率、召回率、F1值对比
从观察分类后的主题词可见,传统LDA模型下的电信技术类主题词有“输出、发送、通信、生成、本发明、获取、相关、成、时间”等,其中“本发明、相关事件、目标、成、时间”这些词与主题类关联度并不大,说明传统LDA模型分类中噪声较大。KG-PMI-LDA模型下的电信技术类主题词有“赫兹、电极、沟、傅里叶、平方根、前缀、FFT、复数、尺寸、波导”等,上述所得到的词更适合代表电信技术类别的主题词。这也体现了KeyGraph算法在特征词选择过程中,充分利用了专业词与高频词的共现关系,通过对词权重的调整,使得对主题类贡献度大的词具有相对大的权重值。这样,这些关键词在主题模型迭代过程中能够更快地涌现出来,成为主题类中的主题词。词权重的调整一定程度上增加了特征词对主题的表述能力,从而提高文本的分类准确率。
4 结束语
根据专利文献中专业词汇更能表达文献主题的特点,通过KeyGraph算法和LDA主题模型的结合,提出一种适用于专利文献主题分类的改进LDA模型。该模型通过提取出专利文献中对主题贡献度高的词,作为“关键词”,再利用点互信息函数计算出关键词与对应文献的Key值,将其作为关键词的权重值来影响采样中的词分布概率。将关键词加权扩展至LDA模型,定义有监督LDA模型的概率图模型,并改进Gibbs Sampling公式。通过与传统LDA模型和其他改进LDA模型在真实专利语料库上的对比实验,验证了该方法在专利分类中的有效性和准确性。下一步将针对词加权计算中的归一化问题进行研究,实现模型迭代过程中的并行化,以提高模型的效率。
猜你喜欢
心理学报(2022年5期)2022-05-16
小康(2022年7期)2022-03-10
小康(2022年7期)2022-03-10
小康(2021年7期)2021-03-15
小康(2021年7期)2021-03-15
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
计算机应用(2016年10期)2017-05-12
电脑知识与技术(2016年25期)2016-11-16
