
融合“S”型相似度和关联度的协同过滤算法
2019-03-21 11:35胡亚兰
计算机技术与发展 2019年3期
余 相,陈 亮,胡亚兰,王 丹
(东华大学 信息科学与技术学院,上海 201620)
0 引 言
随着互联网的飞速发展和移动端智能手机的普及,人类进入信息时代。据中国互联网信息中心2017年1月份发布的互联网络状况统计报告显示,截至2016年12月,中国网页数量约为2 360亿个,比上一年增长11.2%[1]。从巨大的信息量中挑选出人们满意的项目已经越来越难,从数字化图书、新闻、音乐、影视作品到电商平台都存在这样的问题,用户选择的时间成本越来越高,因此推荐系统应运而生。
目前,主流的推荐系统主要分为4类:基于内容的推荐、协同过滤推荐、基于知识的推荐和组合推荐[2]。作为推荐系统中应用最广泛的算法,协同过滤技术已经在研究上和应用上取得了巨大的成功。然而,其依然有很多问题需要解决[3]。其中之一便是推荐准确性。
为了使推荐的结果更加符合用户实际需求,学者一直在尝试改进经典协同过滤算法,但是随着用户和产品数量的日益增长,由于用户并不能对所有商品产生记录,而是其中很小的一部分,从而导致用户-项目矩阵十分稀疏,甚至99%以上,用户-项目矩阵的极度稀疏制约着推荐系统的准确性。稀疏性也是协同过滤技术的核心问题,同时用户、项目的高维增长,对算法的效率也提出了挑战,需要实时生成推荐,直接影响着推荐系统的可扩展性。
1 问题分析
1.1 稀疏性问题
协同过滤算法主要是依据用户过往的使用记录来形成推荐,最常见的表现形式是用户-项目评分矩阵。绝大多数用户通过评分操作访问的信息项目数量相对于系统中信息项目的总量十分有限,一般都达不到信息项目总数的1%[3-4],这就导致了评分矩阵的严重稀疏性。稀疏性问题的存在是协同过滤算法中固有的悖论的表现,即CF推荐系统本身是用于帮助用户从海量信息空间中选择最符合用户兴趣的信息,而这种需求将导致信息空间的稀疏,进而稀疏性又反过来影响推荐的生成[5]。
1.2 影响分析
协同过滤算法的唯一数据来源就是评分矩阵,因此算法各不同步骤都是以评分矩阵为基础执行的。稀疏性问题带来的影响会沿着算法步骤一步步扩散到最终的推荐效果中,下面根据图1描述这一过程。

图1 协同过滤算法流程
(1)相似度计算:相似度将直接作为后续邻居选择和评分预测的重要依据。根据相似度的计算方法可知,用户的相似性是对两者评分的交集实现的,当矩阵稀疏率很高时,用户已有的评分数据很少,造成用户间已评分项目的重合率明显下降,导致公共参考评分项目集合规模过小,相似性只能依赖极少数评分进行度量,造成用户间的相似度计算结果非常片面,不能准确反映用户间的真实相关性[6]。兴趣爱好上原本比较相似的用户,因为少数几个共有项目评分差别较大而变成了非相似用户;事实上,基于小规模共有评分的相似度计算无法体现用户间的真实相似度,继而影响后续推荐步骤。
(2)候选集生成、邻居选择:选择目标项目的同类(即邻居)是评分预测的基础,虽然稀疏问题不会直接作用于邻居,但是通过相似度计算间接对邻居选择产生影响,项目的相似度不同选出的邻居集也是不同的,导致真实的邻居集质量下降了,进一步扩散到评分预测中。
(3)评分预测:实现推荐依赖于评分预测,实际上是将邻居中对目标项目有评分的用户按相似度加权求和得出预测评分。数据稀疏可能导致相似用户中很多未对目标项目进行过评分,导致只能依赖少数邻居评分实现预测,难以保证评分预测的准确性[6]。
从上述分析可以看出,在稀疏性问题的影响下,相似用户的评估将大面积失真,相似度计算在评分预测和邻居选择中都扮演着重要角色,前述在相似度误差较大时造成推荐效果差甚至推荐失败。
1.3 扩展性问题
IBCF算法是以项目相似度为依据筛选候选集,通过相似度加权预测用户对候选集中的项目的评分,根据预测评分高低确定推荐项目。候选集大小、相似度准确程度都将影响推荐精度。此阶段候选集需要对用户u的n个已评分项目进行操作,每个评分项目平均取m个最相似的邻居,这样每个用户的平均候选集大小为nm,并从中剔除常数个用户u已评分的项目,得到项目候选集C。
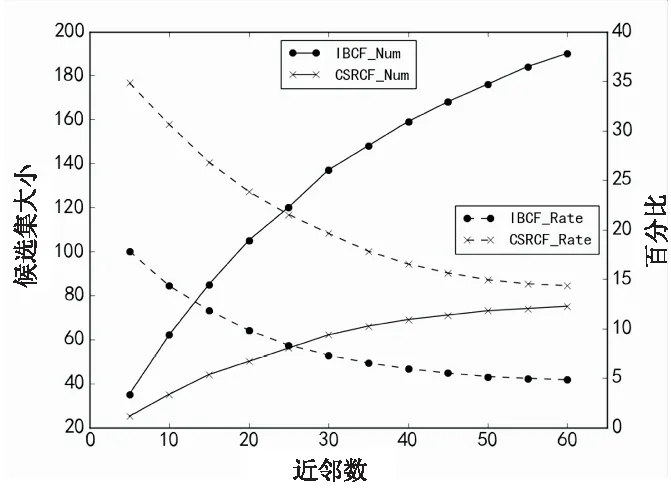
在MovieLens数据集上,当项目的近邻数m增加时,IBCF算法候选集变化曲线如图2所示。曲线大致呈线性增长,当近邻数为60时,用户的候选集大小约为200。同样的条件下,观察到候选集大小k在急剧上升时,候选集中用户感兴趣的项目占比却没有增长或维持不变,相反用户感兴趣占比在下降,当近邻数k=
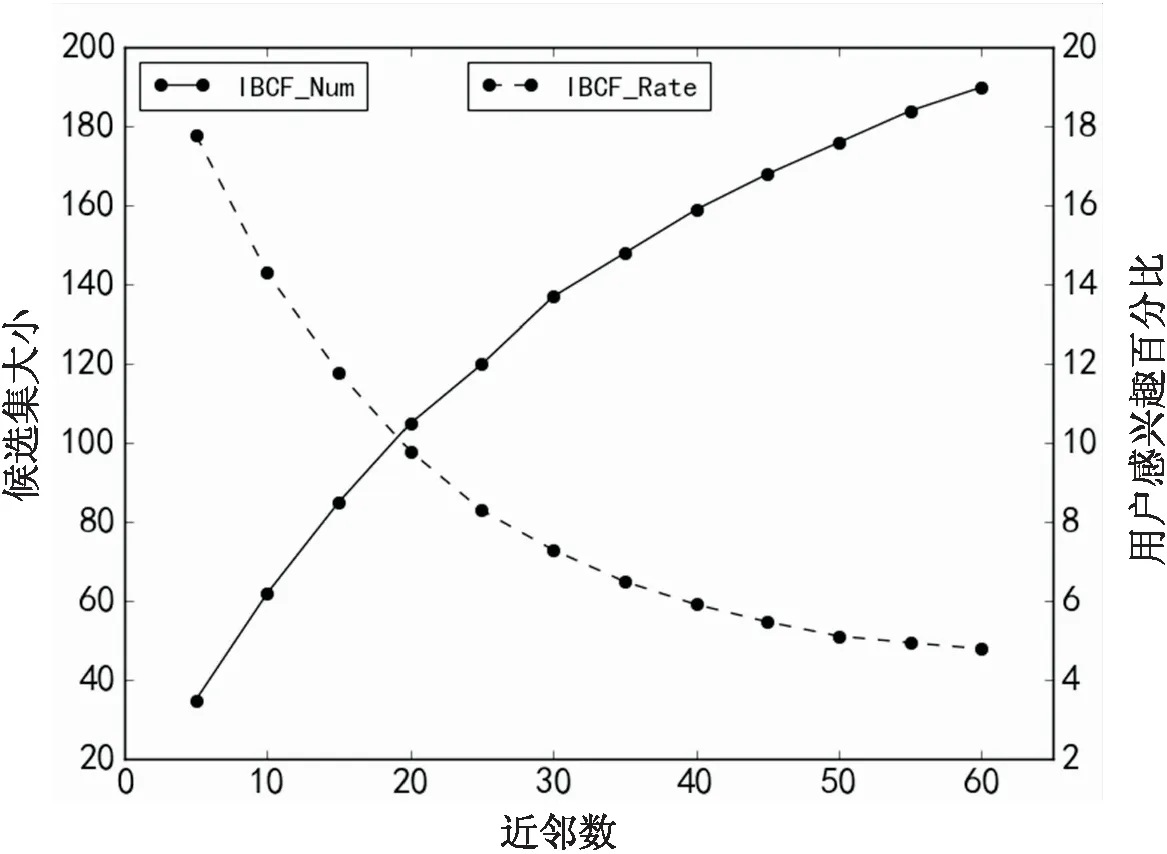
图2 候选集大小及感兴趣项目比例
60时,占比只有4.9%左右,总体比例非常小。用户的平均候选集大小是nm,此时的时间复杂度为O(n2),当用户的评分记录增多时,候选集大小呈二次函数增长,候选集中引入了大量与用户弱相关或不相关的项目,导致推荐准确率下降,评分预测阶段对大量不感兴趣的项目进行计算,算法执行中浪费了大量的CPU和内存资源,极大增加了为候选集项目预测评分的时间,当用户和项目呈高维增长时,将大幅度影响算法性能,直接制约着推荐的横向扩展性。
2 相似度和关联度
2.1 现有相似度
传统的皮尔逊相关系数只考虑用户间共有评分的作用,而忽视了非公共评分数量的作用,导致计算用户相似性及其具有片面性[7]。如表1所示,按传统相似度计算,用户U1与U2的相似度为1,U2与U3的相似度要小于1,这就造成了U1比U3更接近U2的邻居,然而从相似性的可信度来看,U3应该比U1更接近于U2的邻居。
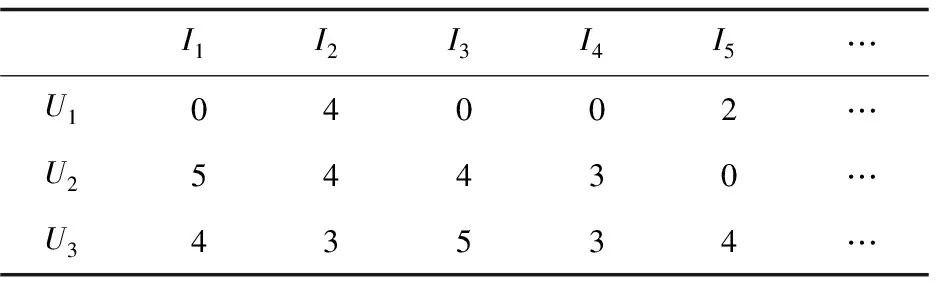
表1 评分矩阵示例
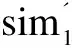
(1)
(2)
相似度sim(i,j)采用的是Pearson相关系数[9]。其中,Iij为用户i和j共同评分的项目集合;Ri,c和Rj,c分别表示用户i和j对项目c的评分;Ri和Rj分别表示用户i和j的平均评分;|Ii∩Ij|是两用户共有评分的数量;α是控制共有评分项数量的阈值,用户间共有评分数量小于阈值时对传统相似度进行线性衰减修正。根据文献[8]的实验结果表明对推荐效果有所提高但并不显著,文中分析认为不同的用户的评分分布不一样,采用全局统一的固定阈值无法适用于所有用户,这种修正只对少数用户起作用。
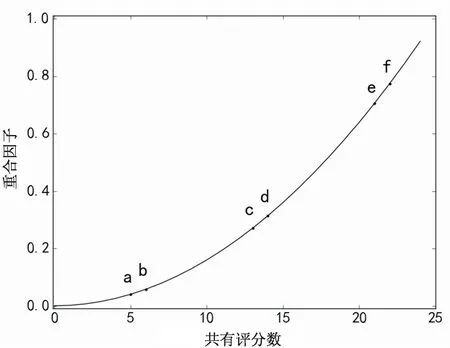
任磊[10]针对该问题提出了适用不同项目评分数量分布的重合因子,刻画了项目间公共评分的重合程度,强调了共有评分重合度的重要性。其加权相似度表示为:

(3)
(4)
其中,重合因子c(i,j)中的Ii和Ij分别是项目i和j的评分项目数量。与文献[8]的绝对全局阈值不同,式3中的相似度不仅与共有评分数目有关,还反比于两用户单独评分数量,这种度量方式是一种全局动态修正,适用于每一个用户。
2.2 “S”型改进相似度
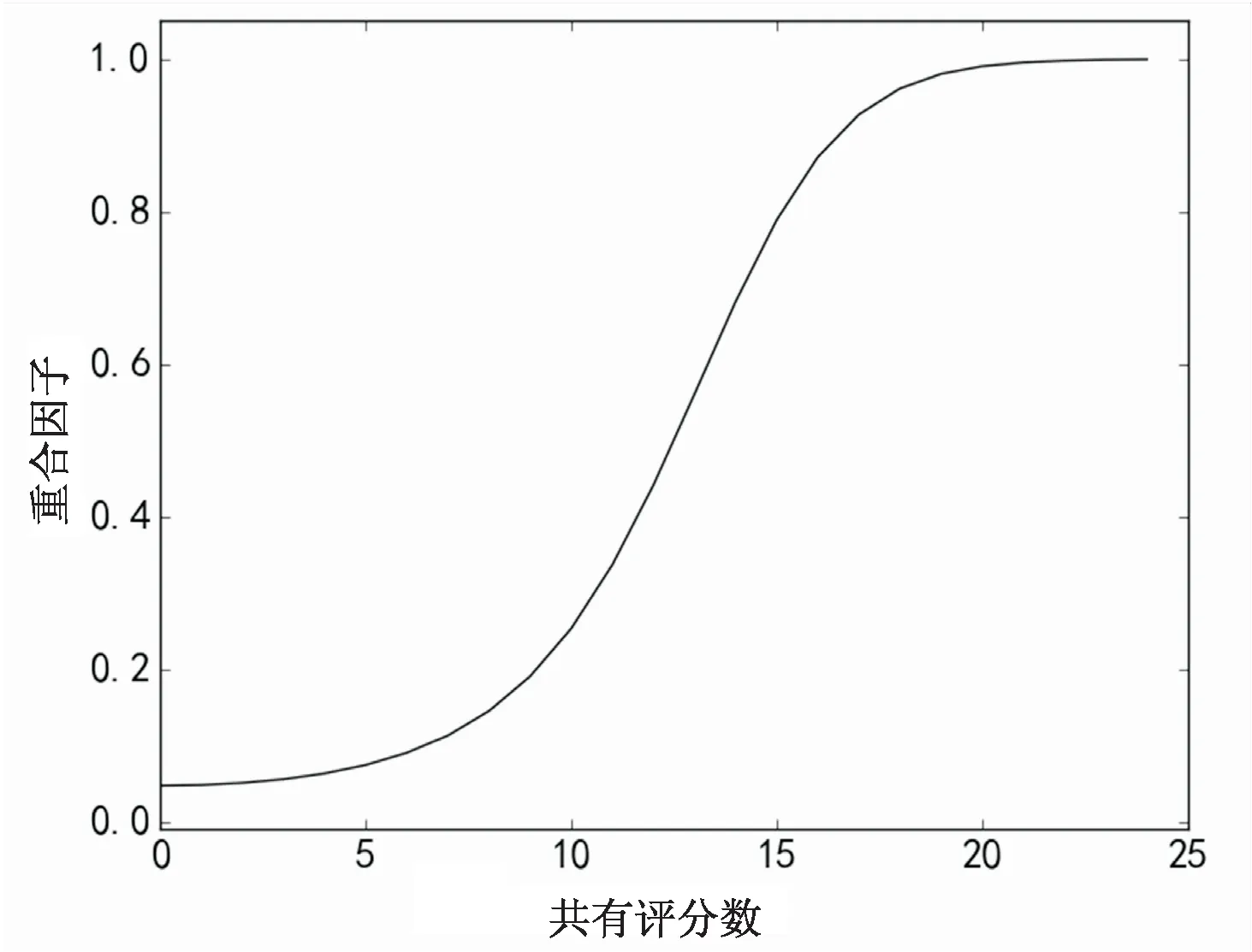
根据上述问题的分析,用户间相似性在共有评分数量达到一定数量时接近饱和,而文献[10]中提出的相似度计算方法与这一现象相悖。从实际出发,当两用户各自的独立评分数确定时,随着共有评分数量的增加,相似度的变化率(即增量的导数)应该是先变大后变小,呈“S”型曲线。实际含义即在共有评分数量较少时,两用户相似度比较小,随着共有数量的增加,相似度迅速上升,最后达到饱和,几乎不再发生变化,即两用户已经非常相似,这样才能体现用户间相似度的真实变化过程。
数学中常用“Sigmod”函数来表示S型曲线,其函数特性完全符合相似度的理想增长过程,体现共有评分项增长中相似度变化的特性。其函数表示为:
(5)
截取标准Sigmod函数某段区间再经过伸缩变换得到变换后的Sigmod函数。将其引入重合因子中,则改进的相似度计算表示为:
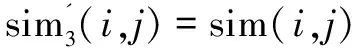
(6)
(7)
其中,a和b分别为两用户的单独评分数量;c为共有评分数量;m为变换的平移系数;k为伸缩系数,控制着函数的陡峭程度。
相似度关于共有评分项的函数见图3(b)。共有评分项数小于10时,相似度增长缓慢,继而迅速增长,当达到20时,用户间再增加相同评分数量相似度饱和,此种情况与相似度理想增长曲线的总体趋势相符。在此基础上,将上述相似度计算集成到协同过滤算法中,相似度计算是后续评分预测的基础,因此将直接提升推荐算法的效果。
(a)
(b)
2.3 关联度
从可扩展性问题可知,未考虑到用户间的差异,将用户不感兴趣的项目加入到候选集,导致候选项目集中大部分项目是无用的,感兴趣项目占比很低,故提高感兴趣项目的占比是优化算法效率的关键。在IBCF算法中,寻找项目的近邻项目使用的是项目间的相似度信息,相似度信息在很大程度上反映了用户对该项目的评价是否一致,而较少地考虑项目间依赖或者是顺序关系,这种依赖的关系是寻找近邻项目的重要因素[11]。
项目之间的关联关系在实际中大量存在,这种关系很大程度上左右着用户的选择,而根据相似度生成候选集无法描述此种关系。如图4(a)所示,用户1浏览了项目A、B、C,用户2的浏览记录有项目B、C、D,后面的用户3在浏览了项目B之后是否想着去浏览C。肯定的,当大量用户在浏览了项目B之后去浏览项目C,可以认为项目B和项目C之间存在某种意义上的关联关系。文中从该现象出发,引入1-频繁项集的思想,计算项目间的关联度矩阵,并依据项目的关联度大小来生成候选集。
定义关联度:关联度用来衡量两项目有联系的强弱程度,即用户在浏览了某商品后又浏览某一商品的可能性,大小用r表示,rmn的含义是项目m对项目n的关联度,定义为项目m与n的共同用户数与项目n的用户数之比,实际含义是用户在浏览了项目n后转而去浏览m的比例,计算如下:
(8)
其中,Cm、Cn分别是项目m和n的用户数。
根据关联度的定义,可以计算所有项目间的关联度并存储为关联矩阵Rk*k,如图4(b)所示。rmn表示项目m对项目n的关联,主对角线全为0,矩阵不是对称的,即rmn≠rnm,两项目按照出现顺序的不同对用户产生的影响不同,因此项目带给用户的关联度也就不同。
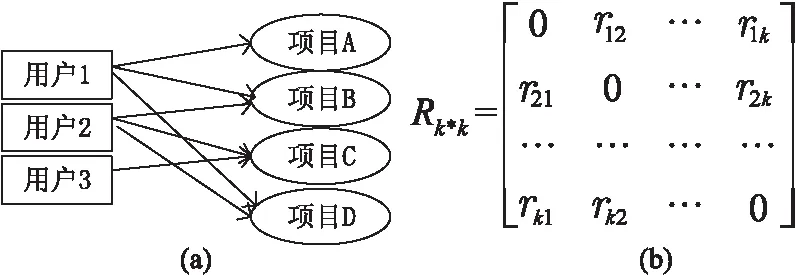
图4 关联关系(a)和关联矩阵(b)
针对IBCF依据相似度生成的项目候选集中感兴趣占比太小的问题,在候选集选取过程中引入关联度,使用关联矩阵代替相似度产生候选集。根据用户u的已有记录项目集合i∈Iu,对其中的每一项目计算关联度,以关联度大小排序得到项目的k近邻居集Nu={i1,i2,…,ik},从中删除所有Iu已存在的项目,得到候选集C。这样候选集中的项目很大程度上与已有项目有强关联,这种关系能够大概率击中用户在未来的需求或兴趣。另一方面,在评分预测的过程中,继续使用相似度作为加权评分中的比重,这样可以保留传统协同过滤的高准确率,又可以避免出现在候选集中引入太多弱相关的项目而导致的低占比问题。
3 算法评估
3.1 算法流程
如上文所述,文中采用关联度生成项目候选集,对其中的项目使用相似度按式9计算加权平均预测分,然后根据预测的评分按高低排序,最后将top-N项目推荐给用户。
(9)
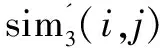
算法流程如下:
步骤1:在评分矩阵上根据提出的“S”型相似度计算方法和关联度计算方法,得到项目间的相似度矩阵S和关联矩阵R;
步骤2:在关联矩阵R中,对用户u的每一项目Iu获取k最邻居集Nu={i1,i2,…,ik},合并所有Nu得到预选集合C';
步骤3:剔除集合C'中用户u已有记录的部分,得到项目候选集C;
步骤4:对候选集中的所有项目e∈C,依据相似度和式9计算项目e的加权平均预测评分;
步骤5:对步骤4中所有项目的预测分由高到低排序,将每一用户u的top-N项目作为用户u的推荐对象。
3.2 实验结果及分析
为了验证文中算法的效果,选用MovieLens[12]中1M数据集,包括了6 040个用户对3 952部电影的评分。文中采用10折交叉验证[13]的方法,将数据集随机划分为10个子集,每次选用其中9份用作训练、1份作为测试,重复10次,取10次结果的平均值作为实验结果。
实验一:比较提出的融合“S”型相似度和关联度的协同过滤算法(CSRCF)和经典的协同过滤(IBCF)的候选集的大小。图5(a)展示的是在MovieLens数据集得到的上述两种算法生成的平均候选集大小。开始阶段,两种算法的候选集基本相同,随着近邻数的增长,IBCF算法候选集会迅速增大,当近邻数达到60时,候选集将达到200左右;而CSRCF算法则增长十分缓慢,当近邻数增加到50后,候选集大小几乎收敛在75左右,仅为前者的1/3。两者对比之下,发现文中提出的依据关联矩阵生成的候选集效果十分显著,大幅降低了候选集的规模,避免在评分阶段计算过多无效的项目。
实验二:上述讨论了两种算法在候选集规模上的区别,接下来讨论在减小候选集规模时,候选集中感兴趣占比会如何变化。由图5(a)可以看出,初始阶段CSRCF比IBCF有着明显优势,随着近邻数的增加,两者的用户感兴趣占比都在下降,且保持着较大差距,IBCF仅为不到5%,最后CSRCF的用户感兴趣占比稳定在15%左右,比前者高出10%。
综合上述两个实验,可以认为IBCF算法根据相似度选取项目候选集时引入了不相关或弱相关的项目,导致候选集规模过大且用户感兴趣比例较小;而文中提出的CSRCF算法,从项目间的关联性出发选取候选集,保证了候选集中的强相关性,在保证不减少用户感兴趣项目数量的前提下,大幅减小了候选集的规模且提升了用户的感兴趣比例,为后续预测阶段减少了不必要的项目评分预测计算。
(a)
(b)
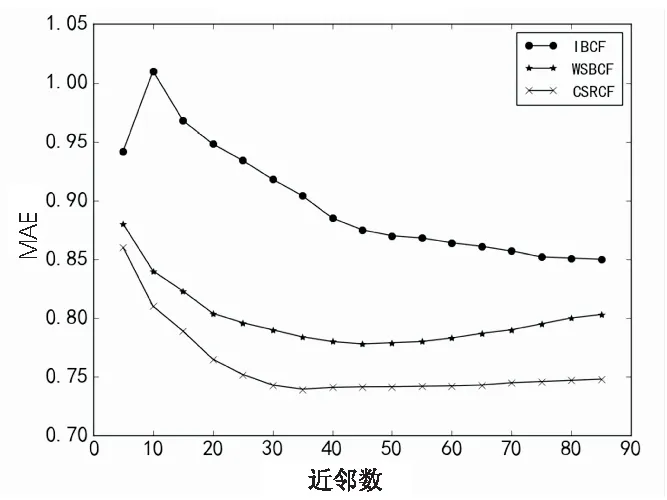
实验三:为了验证CSRCF算法的推荐效果,将其与文献[10]提出的加权相似度协同过滤算法(WSBCF)以及传统的协同过滤算法(IBCF)进行比较。在离线环境下,文中采用MAE(平均绝对误差)[14]作为评估度量,三种算法MAE准确性结果如图5(b)所示。可以看出,随着邻居规模的增长,三种推荐算法的MAE都在减小,说明邻居规模的增大一定程度上提高了准确性。传统的IBCF随着邻居规模增大MAE缓慢减小,最后MAE基本稳定在0.85左右;WSBCF算法在开始时推荐准确性显著长,在邻居规模为[45,55]内达到推荐准确峰值,CSRCF算法在开始阶段与WSBCF类似,MAE迅速下降,下降的速率较前者要快,然后在邻居规模为35时到达最优推荐效果,两种算法都在邻居规模继续增大时MAE反而会增大,表明过多的邻居规模会导致并不相似的用户参与评分预测,引入不相关的评分噪声导致推荐效果下降。
注意到CSRCF不论是在最优推荐效果(MAE约为0.74)还是达到最优推荐效果时用户的邻居规模较上述算法都有显著提升,更小规模的邻居用户在大数据量推荐时减少计算负担;较之前两种算法,CSRCF算法的MAE值更小且收敛过程中下降得更快,证明提出的CSRCF算法能通过“S”型重合因子准确地描述用户间相似度与共有评分项的真实关系,从而提高后续评分预测的准确性。
4 结束语
大多数推荐系统中,相似度是生成候选集和评分预测的基础,决定着推荐的质量。文中以推荐步骤为出发点,创造性地分离候选集生成和评分预测。针对候选集中存在大量弱或不相关的项目和用户感兴趣比例较低的问题,引入关联度的概念,使用关联矩阵代替相似度矩阵生成候选集来减小候选集规模;评分预测阶段分析相似度对推荐效果的影响,对传统相似度和基于加权相似度无法准确描述相似度的问题进行总结,详细阐述了项目间相似度增长的理想曲线,提出了一种细粒度“S”型相似度来刻画理想相似项目,最后在算法流程中融合关联度和“S”型相似度。实验结果表明,关联度的引入减小了候选集规模,仅为前者的1/3,避免了预测阶段对无效的项目进行评分,加快了推荐速度,从算法层面提高了可扩展性,改进的“S”型相似度在推荐准确率上较前者提高了4%。但未考虑在大数据环境下改进算法的时间复杂度,因此下一步将研究如何在分布式环境下提升该推荐算法的可扩展性。
猜你喜欢
体育科技文献通报(2022年4期)2022-10-21
中草药(2022年17期)2022-09-05
思维与智慧·上半月(2021年8期)2021-08-06
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
读与写·教育教学版(2017年10期)2017-11-10
体育科研(2016年5期)2016-07-31
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
